[Перевод] Как программы общаются между собой

Уже очень давно программное обеспечение стало настолько масштабным, что его приходится разбивать на части. Каждая часть выполняет свою задачу, но как они общаются между собой? Как разные части системы получают сообщения друг от друга?
С развитием технологий, прошествием времени и увеличением масштабов ответить на этот вопрос становится всё сложнее.
Давайте совершим экскурс в историю и узнаем, как много было сделано и как мало изменилось.
Предупреждение: в статье я буду упрощать и жертвовать точностью ради понятности.
Простейший способ передачи сообщений между модулями программы, активно используемый сегодня — это передача аргументов. Давайте узнаем, что это такое.
Начнём с корней
Первые программы в 40-х и 50-х годах могли состоять из различных модулей, но после сборки они всё равно оставались единой программой, использовавшей оборудование целиком: всю память, все устройства ввода-вывода и CPU.

Да, корпус деревянный. Компьютер был не таким быстрым, чтобы рассеивание тепла стало какой-то проблемой… (фотография взята отсюда)
Ядро CPU имело набор регистров — ближайший физический аналог переменных: они имели имена, размер и были пронумерованы.
Для CPU всё представлялось в виде чисел, и именно их хранили все эти регистры. Каждое вычисление CPU могло выполнять считывание из одного или нескольких регистров, производить арифметические действия и выводить результат в один или несколько регистров.
Также CPU имели доступ к шине данных и адресной шине (это врата процессора в мир, в котором он живёт), а также могли копировать числа между регистрами и этими шинами. Именно так они и общались с остальными частями компьютера.

Абак (счёты) — прапрадедушка регистров
На этом уровне модули программы не имели роскоши использования параметров и методов. Их общение было основано на договорённости о том, чтобы помещать аргументы в определённый набор регистров, а потом передавать контроль над ними вызываемому модулю и ожидать, что он сохранит свой результат в некие регистры, откуда его можно получить.
Иногда, когда данные были слишком большими для регистров, в них сохранялся адрес памяти, где находились сами данные, но на этом функциональность машинного кода заканчивалась.
Проще говоря, CPU использовал (и всё ещё использует) самую простую форму общей памяти — глобальные значения.
Когда программист вызывает функцию или метод в современном языке программирования, формируется машинный код, упорядочивающий аргументы в вышеупомянутые регистры и соединяющий регистры результата с возвращаемым значением.
А, ну и ещё есть много возни с областями видимости, чтобы модули не наступали друг другу на пятки на этой вечеринке глобального доступа, но это уже к обсуждаемой нами теме не относится.
Относится к ней следующее:
Это работает так хорошо потому, что вся эта повторяющаяся низкоуровневая механика упорядочена компилятором многократно проверенным годами способом.
Разбиваем на этапы
Когда процессы становятся слишком большими для одной программы, их разбивают на отдельные программы. Каждая программа владеет одним этапом потока: программы-этапы могут считывать входные данные из хранилища и сохранять свои результаты в хранилище, чтобы их можно было использовать как входные данные для следующей программы в потоке. Так выглядела первая разновидность пакетной обработки.
Каждая программа похожа на манипулятор производственной линии
Однако такая система очень неуклюжа, подвержена ошибкам и включает в себя множество временных файлов, которыми нужно как-то управлять. Поэтому программной отрасли достаточно быстро пришлось двигаться дальше.
Также стоит заметить, что такая разновидность общения асинхронна. Когда программа на одном этапе подготавливала сообщение и оставляла его для следующего этапа, у неё не было гарантий (да её это и не волновало), когда будет получено сообщение, и будет ли оно получено вообще.
Необходима была более высокоуровневая организация всего потока, включающая в себя все эти программы (можно назвать её контроллером), сообщающая каждой программе, когда запускаться, передавать входные и выходные данные, наблюдать за тем, как они выполняются до завершения и обрабатывать ошибки.
Стоит отметить, что когда-то давно всем этим занимались живые операторы.

А ещё все операторы были молодыми девушками! Куда они все подевались?
Процесс и многозадачность
В конце 50-х компьютеры постепенно начали превращаться в коммерческий продукт, однако они всё ещё были огромными дорогими машинами, принадлежащими организациям и государствам, поэтому их экономическая целесообразность определялась тем, умеют ли они работать со множеством программ одновременно, то есть многозадачностью.
Раньше программа запускалась (возможно, с какими-то аргументами), выполняла некие вычисления, выдавала результаты и завершалась, но теперь несколько программ должно было выполняться на одном оборудовании и, что самое важное, на одном CPU.
В результате возникла система разделения времени: каждая из запущенных программ по очереди получала в своё распоряжение ядро CPU, и этим процессом многозадачности управляла операционная система.

Рук может быть и много, но мозг всё равно один
Многозадачность (или параллелизм) позволила компьютеру выполнять несколько задач параллельно. Это создаёт иллюзию того, что всё происходит одновременно, однако в любой конкретный момент времени ядро CPU обрабатывает одну задачу, непрерывно переключаясь между ними.
Когда происходит такое переключение, ОС сохраняет значения из всех регистров, которые использует поставленный на паузу процесс, и загружает в них значения, сохранённые тогда, когда был поставлен на паузу следующий процесс. Это называется переключением контекста (context switching). Чем больше регистров используют процессы, тем более затратна эта операция.
Первые модели были кооперативными, то есть программы использовали время CPU ответственно: когда программы ожидали данные, они пропускали свой ход. Так как устройства ввода-вывода всегда были медленнее CPU, такое происходило часто.
Также программы распределяли свою работу тонким слоем и делали по одному шагу за раз, чтобы дать другим программам шанс поработать с CPU между своими блоками данных, ожидая от других процессов такого же поведения.
Очевидная слабость такой модели заключается в том, что если процесс по какой-то причине не освобождает CPU, то вся система может стать нестабильной.
Сигнал
Для решения этой проблемы в 70-х придумали сигналы, которые со временем развивались и становились совершеннее. К 80-м появилась вытесняющая модель разделения времени, делавшая распределение времени CPU более эффективным и справедливым.
Она требовала от процессов реагировать на сигналы, имевшие больший приоритет, чем их обычная работа. Использовались такие сигналы: pause, resume, abort, terminate, break и так далее, а также сигналы ошибок, например, недопустимого доступа или деления на ноль. Эти операционные сигналы означали одно и то же для всех процессов, позволяя ОС и процессу взаимодействовать.
Стоит отметить, что процесс — это не программа: его частью является операционная система с механизмами наподобие механизма принятия сигналов. Процесс всегда получает сообщение, а программа внутри него иногда знает о сигнале (например, SIGINT), а иногда нет (например, SIGKILL).
IPC — межпроцессный обмен сообщениями (локальный)
Большой недостаток потока, обёрнутого вокруг отдельных программ, — это затраты на процессы. Процесс обёртывает программу дополнительными механизмами, требует времени на создание, обменивается информацией с ОС, требует времени на подчистку после завершения.
Если бы можно было поддерживать функционирование и готовность процессов, то это сэкономило время, которое тратится на создание нового процесса и ожидание его готовности. Ценой этого будет занимаемая им память и переключение контекста, чтобы хранить его в ротации разделения времени даже в случае простоя. Когда нам нужен быстрый результат, чем больше и медленнее программа при инициализации, тем это оправданнее.
Чтобы эта модель работала, нам нужно как-то сообщить процессу, что есть работа, которую он должен выполнить.
▍ Опросы общей файловой системы
Опрос (polling) — это когда получатель регулярно проверяет наличие новых сообщений для себя.
Если программы договорились, что в какой-то папке общей файловой системы будет организована «доска объявлений», то они могут регулярно сканировать это место и обрабатывать новые сообщения. Если каждый процесс получает собственную папку, то эта папка может использоваться как папка входящих сообщений. А если программы закодированы так, чтобы обрабатывать сообщения в порядке их получения, то мы получаем самую простую форму компьютеризированной очереди.
Однако для этого требуется, чтобы программа обрабатывала эти папки входящих сообщений не только в логическом смысле, но и вплоть до предоставляемых файловой системой возможностей. Например, логику запоминания того, какие сообщения уже были просмотрены, можно реализовать так: помечать файлы как просмотренные, удалять их или перемещать в другую папку.
Стоит учитывать, что, по сути, это всё ещё разновидность глобальных значений.Переместив модули программы в процессы, мы также перешли от общих регистров к совместно используемой файловой системе.
Это значит, что критически важным становится координирование таких файлов, поэтому операционные системы начали предоставлять возможности управления ими.
Также стоит заметить, что такая разновидность обмена информацией столь же асинхронна, что и при пакетной обработке.
▍ Семафоры

Учитывая, что папка используется как пробковая доска и что к этой папке должно получать доступ множество процессов, может получиться так, что процесс попытается прочитать сообщение, которое всё ещё записывает другой процесс, или хуже того — два процесса попытаются выполнить запись в одно место, перезаписывая работу друг друга.
Семафоры решают эту проблему. Этот механизм позволяет процессам просить ОС будить их только тогда, когда ресурс, который они ожидают, доступен исключительно им, и когда ни один процесс не использует его, управляя очередью между ними.
Также это помогает разделить процессы на те, которые готовы использовать CPU, и те, которые ждут ресурсов и могут быть пропущены в цикле разделения времени.
▍ Использование сигналов между процессами

Механизм операционных сигналов был расширен, включив в себя несколько
сигналов, которые приложения могут использовать для собственной логики (например, SIGUSR1, SIGUSR2).
В большинстве ОС все сигналы внутри устроены как числовые коды, которые программы могут сопоставлять с определёнными функциями. То есть сигнал можно использовать для вызова конкретной части кода, но с ним нельзя передать никаких параметров.
Благодаря своей изобретательности некоторые команды разработчиков догадались, что перед отправкой сигнала можно подготовить в заранее заданной папке сообщение для целевого процесса. Когда целевой процесс получит этот сигнал, программа считает сообщение из файловой системы, благодаря чему программа при помощи того же механизма сигналов может получать сообщения с любыми типами полезных нагрузок.
▍ Перехват событий файловой системы
События (или push) — это более эффективный и новый механизм (2001 год), делегирующий работу по управлению наблюдением ОС, сохраняя в приложении только логику того, что должно происходить в случае возникновения изменений в папке или файле.
Это переворачивает асинхронность исполнения. С одной стороны, процессы теперь могут отвечать на события по мере их поступления, если они готовы и прослушивают события.
С другой стороны, использующее события приложение всё равно должно выполнять большую часть того, что выполняет приложение, использующее опросы (polling). Если процесс какое-то время был отключен, то после своего пробуждения он должен проверить, что есть нового в файловой системе и реагировать так же, как это сделало бы приложение с опросами.
▍ Сокеты

Подключи, чтобы принять сигнал
Со временем для передачи сообщения в ОС появились сокеты, позволяющие избавиться от возни с файлами.
Их использование уже граничит с распределёнными системами, потому что если мы можем передавать сообщения между независимыми процессами на одной машине, то всего один шаг отделяет нас от возможности передачи сообщений между двумя процессами в сети.
То, что мы рассмотрим далее, крайне важно для локальной работы:
Архитектура каналов и STDIO
Эволюция — это всегда многократное использование: она вдохновила создавать программы, специализированные в своей узкой нише, и позволила конечным пользователям применять их как стандартные строительные блоки для выражения конкретных потоков.
В результате появились каналы (pipe).
Архитектура каналов подразумевает, что поверх аргументов командной строки и механизма сигналов программы получают три основных канала коммуникации:
- для входа,
- для выхода,
- для уведомлений.
Когда многократно используемые программы соединяются в каналы, выходные данные каждого звена канала служат входными данными следующего, избавляя от необходимости обработки всех временных файлов, передаваемых между ними. Это стандартные вход и выход, называемые stdin и stdout.
А как же третий?
Когда программе нужно создать уведомление, которое не должно быть частью выходных данных, оно передаёт его по третьему каналу. Так как большинство уведомлений связано с ошибками, этот канал имеет неприятное имя stderr, даже когда используется для предупреждений, уведомлений и всего того, что процесс должен сообщить операторам, а не следующей программе в канале.
Прочие преимущества каналов: в основном они расположены в памяти, что экономит большой объём ввода-вывода, а звенья могут работать одновременно, передавая блоки данных по мере их готовности.
▍ Мощь каналов
Если программы достаточно обобщены и поддерживают чётко сформулированные параметры, можно строить очень выразительные потоки даже без необходимости писать программный код.
Этот скрипт оболочки выводит markdown-список десяти самых популярных тегов, найденных в статьях:
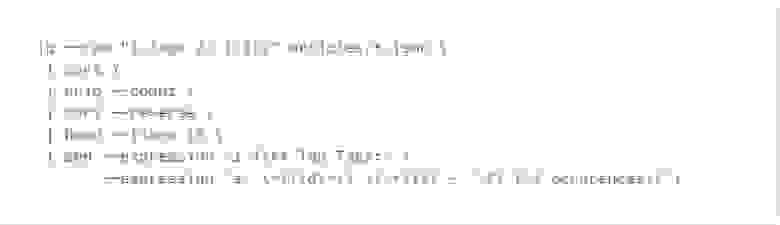
Этот пример предполагает, что папка articles содержит документы JSON в виде файлов, и каждый документ может иметь свойство tags в виде списка строк. Скрипт использует jq для их извлечения, uniq подсчёта, sort сортировки в обратном порядке, head вырезания десяти верхних результатов и sed форматирования их в виде markdown-списка с заголовком.
Если вы программист, то какой объём кода вам бы понадобился, чтобы выразить эти действия на вашем языке программирования?
Заключение
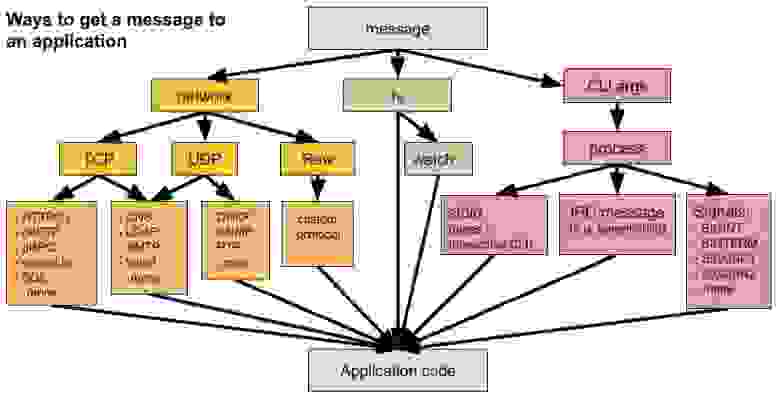
Мы узнали, как отдельные модули ПО могут передавать друг другу сообщения. В первую очередь мы рассмотрели коммуникации внутри локальной машины, оставив распределённые системы для новых постов.
Мы увидели, что всё это локально внутри устроено как глобальные значения — общие регистры, общая память и общая файловая система. Несмотря на это, мы не работаем с ними как с глобальными значениями, поскольку доступ к ним в основном выполняется через проверенные временем механизмы и встроенные защитные меры. Однако иногда ПО приходится явным образом использовать специальные механизмы для защиты от коллизий с другими процессами.
И, наконец, мы увидели мощь архитектуры каналов (pipe).
Играй в наш скролл-шутер прямо в Telegram и получай призы!
