[Перевод] Как мы провели пару дней, работая над ускорением Perl
Это история о значительной оптимизации интерпретатора Perl, о борьбе со сложностями кода, и о том, как мы хотели «съесть торт так, чтобы он у нас остался» [английская поговорка «You can’t have your cake and eat it», означающая невозможность достижения двух противоположных целей].
На недавнем хакатоне Booking.com у нас появилась возможность поработать над ускорением функции размещения целых чисел в интерпретаторе Perl. В случае успеха это поможет ускорить практически все программы, которые работают в нашем проекте. Оказалось, что банальная реализация идеи могла бы сработать, но это привело бы к увеличению сложности поддержки кода. Наше исследование привело нас к тому, чтобы заставить препроцессор С улучшать качество кода, одновременно давая возможность ускорить выполнение программ.
Предыстория
В perlguts и PerlGuts Illustrated написано, что представление переменных в Perl обычно состоит из двух частей — заголовка и тела (представляемых как struct). Заголовок содержит необходимые для обработки переменных данные, которые не зависят от её типа, включая указатель на возможное тело.
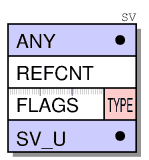
Структура тела может сильно отличаться, в зависимости от типа переменной. Простейшая переменная — SvNULL, которая представляет undef и которой не требуется тело.
У строки (PV — «pointer value») тело имеет тип XPV:
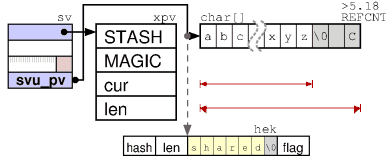
Структура тела PV отличается от тела PVNV. PVNV может содержать число с плавающей точкой и строковое представление того же значения.
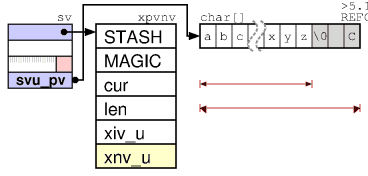
Преимущество такого дизайна в том, что все ссылки на переменную ведут на заголовок. Perl свободно может изменять то место, где хранится тело, и для этого не требуется обновлять все остальные указатели.
Меняя типы
У Perl есть внутренняя функция для преобразования типов — это sv_upgrade («scalar value upgrade»). Если у нас есть переменная, — допустим, целое число,- и нам надо обратиться к ней как к переменной другого типа (допустим, как к строке), sv_upgrade преобразовывает тип переменной (допустим, в тип, содержащий как целочисленное, так и строковое представление значения). Это может потребовать замены текущего тела большим по объёму.
Чтобы узнать, как реализована sv_upgrade, заглянем в функцию Perl_sv_upgrade в sv.c. Видно, что функция достаточно сложная, в коде много комментариев, описывающих разные особенности реализации. Это неудивительно — ведь она может принимать скалярное значение любого типа и преобразовывать его в вид, который может представлять любой другой тип.
В начале функции присутствует switch, работающий в зависимости от текущего типа переменной, который определяет, что необходимо сделать для нового типа. Вскоре после него есть второй switch, который разбирается с новым типом. В его втором блоке присутствует множество блоков if {}, делающих разные вещи в зависимости от старого типа. И в конце, после определения struct для нового тела и заполнения struct для заголовка правильными флагами, освобождается память, которую занимало старое тело.
Не заснули пока?
Наивный подход
Функция sv_upgrade вызывается из множества мест — не только из вывода целых чисел в виде строк, но и при присваивании целого числа переменной, которая до этого была обнулена.
Обнулённая переменная — это всегда undef, у которого нет тела. sv_upgrade в этом случае вызывается для корректной настройки тела новой переменной. Это правильное решение, которое сводит определённую работу с переменными в одном месте, и не множит сущности. Но это решение сказывается на производительности из-за выполнения некоего общего, и в данном случае, избыточного кода.
Присвоение обнулённой переменной целого числа происходит настолько часто, что вроде бы можно и продублировать часть кода, чтобы получить улучшение производительности. Мы решили подсчитать, чего это будет стоить. Оказалось, что в данном случае можно вообще избавиться от вызова sv_upgrade, если продублировать всего лишь две строчки кода из неё. Но их не зря не дублировали в коде. Вот эти две строки.
Первая, поскольку мы знаем, что это новый тип, будет простой:
SvFLAGS(sv) |= new_type;
Вторая — сложнее:
SvANY(sv) = (XPVIV*)((char*)&(sv->sv_u.svu_iv) - STRUCT_OFFSET(XPVIV, xiv_iv));
Описывается она в Illustrated perlguts так:
Начиная с версии 5.10, для чистого IV (без PV) слот IVX находится внутри HEAD, и не выделяется память для xpviv struct («body»). Макрос SvIVX использует арифметику указателя SvANY, чтобы указать на отрицательное смещение, которое подсчитывается во время компиляции, от HEAD-1 к sv_u.svu_iv, таким образом, чтобы PVIV и IV могли использовать тот же самый макрос SvIVX.
После 15 минут с карандашом и бумагой я убедился в том, что эта строка делает именно то, что описано в комментарии. После этого диаграмма из Illustrated Perl Guts стала более понятной:
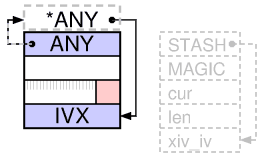
Кроме того, я сообразил, что вся эта сложность существует для того, чтобы избежать вызова if, которое в ином случае происходило бы каждый раз при извлечении значения.
Получалось, что мы можем кое-что ускорить, но путём вынесения сложных выражений в другую часть кода. Сложность поддержки такого кода в результате увеличилась бы.
Как съесть торт так, чтобы он у вас остался
Нам хотелось инкапсулировать этот сложный кусок кода, но без ухудшения быстродействия. Имея дело с С, мы обратились к препроцессору, чтобы запихнуть всё это в макрос — в других языках это выглядело бы, как сокрытие сложного кода за хорошо названной функцией или методом:
#define SET_SVANY_FOR_BODYLESS_IV(sv) \
SvANY(sv) = (XPVIV*)((char*)&(sv->sv_u.svu_iv) - STRUCT_OFFSET(XPVIV, xiv_iv))
Преимущество использования макроса в том, что плата за быстродействие взимается лишь при компиляции, и при выполнении ничего не страдает.
И как это изменило нашу ситуацию? При использовании макроса две вынесенные строки стали более простыми. В результате в патче нужно было только заменить вызов
sv_upgrade(dstr, SVt_IV);
на эти две строчки:
SET_SVANY_FOR_BODYLESS_IV(dstr);
SvFLAGS(dstr) |= SVt_IV;
В результате, за счёт выноса сравнительно несложного кода мы должны получить прибавку к быстродействию. Но получим ли? Какой будет от этого реальный выигрыш?
Измерение выгоды
Наша бенчмарка достаточно конкретная, но при этом представляет собою довольно частый случай.
$ dumbbench -i50 --pin-frequency -- \
./perl -Ilib -e \
'for my $x (1..1000){my @a = (1..2000);}'
А вот и результаты работы. До оптимизации:
Rounded run time per iteration: 2.4311e-01 +/- 1.4e-04
После оптимизации:
Rounded run time per iteration: 1.99354e-01 +/- 5.5e-05
Прирост в 18%. Успех.
Мы продемонстрировали нужность этой оптимизации, сложность которой стремится к нулю. В некоторых местах код Perl стал чуть более сложным, но внутренности функции sv_upgrade упростились. Действуя подобным образом, мы нашли ещё несколько мест, где можно было достичь оптимизации схожими методами. В результате мы сделали пять патчей в код Perl:
С выходом Perl 5.22, в том числе, благодаря этой работе, многие программы станут работать быстрее.
