[Перевод] Как использовать Python для «выпаса» ваших неструктурированных данных
Здравствуйте, уважаемые читатели.
В последнее время мы прорабатываем самые разные темы, связанные с языком Python, в том числе, проблемы извлечения и анализа данных. Например, нас заинтересовала книга «Data Wrangling with Python: Tips and Tools to Make Your Life Easier»:

Поэтому если вы еще не знаете, что такое скрепинг, извлечение неструктурированных данных, и как привести хаос в порядок, предлагаем почитать перевод интересной статьи Пита Тамисина (Pete Tamisin), рассказывающего, как это делается на Python. Поскольку статья открывает целую серию постов автора, а мы решили пока ограничиться только ею, текст немного сокращен.
Если кто-то сам мечтает подготовить и издать книгу на эту тему — пишите, обсудим.
Я — продакт-менеджер в компании Rittman Mead, но при этом я еще считаю себя фриком 80 лвл. Я полюбил комиксы, фэнтези, научную фантастику и прочее подобное чтиво в те времена, когда слово «Старк» еще отнюдь не ассоциировалось с Робертом Дауни-младшим или с мемами о надвигающейся зиме. Поэтому мне очень понравилась перспектива объединить приятное с полезным, то есть, хобби с работой. Я решил написать у себя в блоге несколько статей о построении прогностической модели на основании данных, связанных с продажами комиксов. Конечная цель — предложить такую модель, которая позволяла бы достоверно судить, будут ли читатели сметать новый комикс с полок как горячие пирожки, либо он заляжет на складе. В этой публикации я расскажу о некоторых подводных камнях, которые могут подстерегать вас при подготовке данных к анализу. Подготовка данных, также именуемая «выпасом» (wrangling) — это несовершенный процесс, обычно выполняемый в несколько итераций и включающий преобразование, интерпретацию и рефакторинг — после чего данные можно будет анализировать.
Хотя этапы выпаса данных могут отличаться в зависимости от состояния и доступности «сырых» данных, в этой статье я решил сосредоточиться на сборе информации из разрозненных источников, обогащении данных путем слияния их атрибутов и реструктурировании данных для упрощения анализа. Серии книг с комиксами легко найти в Интернете, однако оказалось, что не так просто добыть их в удобоваримом формате. В итоге я решил поступить дешево и сердито — занялся экранным скрепингом информации с сайта, посвященного исследованию комиксов. Для тех счастливчиков, которым пока не довелось иметь дело с экранным скрепингом, объясняю: при скрепинге вы программно скачиваете HTML-данные и удаляете из них всякое форматирование, чтобы эти данные можно было использовать. Как правило, этот прием используется, когда ничего другого не остается, поскольку сайт — штука непостоянная, контент на нем меняется не реже, чем дитя-подросток намыливается сбежать из дома.

Итак, вот первая проблема, с которой можно столкнуться при выпасе данных. У вас есть доступ к массе данных, но они неаккуратные. Надо их причесать. Работа с сырыми данными напоминает работу резчика по дереву. Ваша задача — не изменить структуру данных таким образом, чтобы подогнать их под свои цели, а отсечь все лишнее, чтобы от чурки осталась красивая лошадка… я имею в виду, чтобы вы могли сделать выводы. Извините, увлекся метафорами. Кстати, продолжая эту аналогию: для работы над этим проектом я первым делом извлек из столярного ящика Python. Для программиста Python — реальный мультитул. Он быстр, хорошо сочетается с другими технологиями и, что наиболее важно в данном случае, он повсеместно распространен. Python используется для решения всевозможных задач — от автоматизации процессов и ETL до программирования игр и академических исследований. Python — по-настоящему многоцелевой язык. Таким образом, столкнувшись с конкретной задачей, вы вполне можете найти в Python специально предназначенный для нее нативный модуль, либо кто-то уже мог написать общедоступную библиотеку, обладающую нужным функционалом. Мне были нужны определенные скрипты для «скрепинга» HTML-таблиц с данными о продажах комиксов. Далее мне требовалось скомбинировать эту информацию с другими данными по комиксам, добытыми в ином месте. «Другая» информация представляла собой метаданные о каждом из выпусков. Метаданные — это просто информация, описывающая другие данные. В данном случае к метаданным относилась информация об авторе, о продажах, о времени публикации и т.д…. Подробнее об этом ниже.
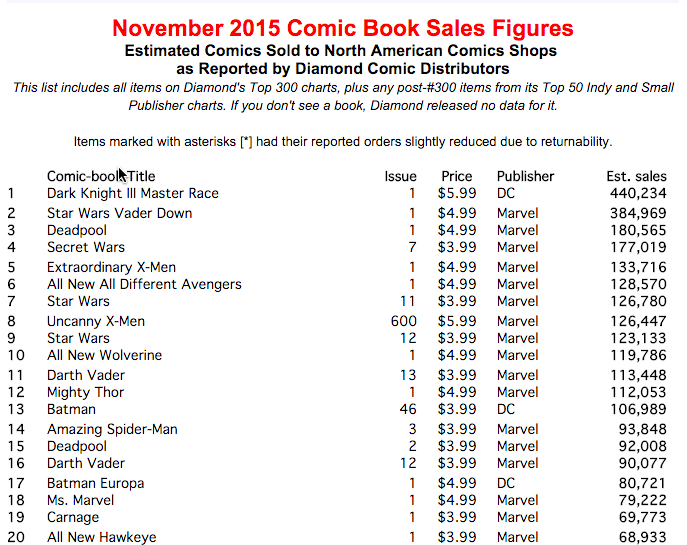
К счастью, те данные, которые я скрепил, были в табличном формате, поэтому извлекать их и преобразовывать в объекты Python было относительно просто — требовалось лишь перебрать строки таблицы и связать каждый столбец таблицы со специально предназначенным для этого полем объекта Python. На странице все-таки оставалось достаточно много ненужного контента, который приходилось игнорировать — например, теги title и другие структурные элементы. Но, как только я нашел нужную таблицу с данными, мне удалось ее изолировать. На данном этапе я записал объекты в CSV-файл, чтобы данные было легко передавать, а также чтобы их было проще использовать с применением других языков и/или процессов.
Вся сложная работа в данном случае выполнялась при помощи трех модулей Python: urllib2, bs4 and csv. Urllib2, как понятно из названия, содержит функции для открытия URL. Работая над этим проектом, я нашел сайт, где была такая страница: на ней содержалась информация с примерными продажами выпусков за каждый месяц вплоть до начала 90-х. Чтобы извлечь данные за каждый месяц, не обновляя вручную жестко закодированные URL снова и снова, я написал скрипт, принимавший в качестве аргументов MONTH и YEAR — month_sales_scraper.py
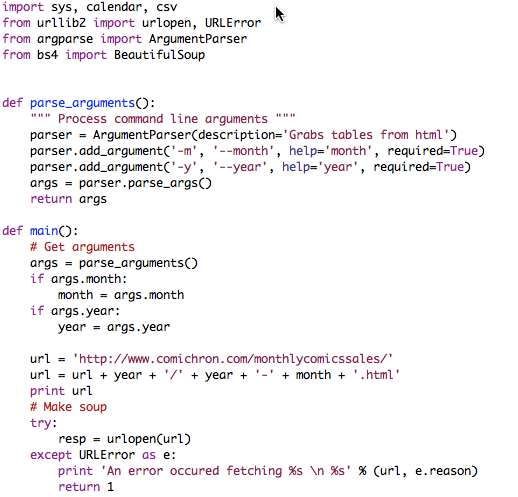
Отклик на вызов функции urlopen(url) содержал полный HTML-код в таком виде, как он обычно отображается в браузере. Такой формат был для меня практически бесполезен, поэтому пришлось задействовать парсер, чтобы извлечь данные из HTML. Парсер в данном случае — это программа, которая считывает документ в конкретном формате, разбивает его на составляющие, не нарушая при этом тех взаимосвязей, что имелись между этими составляющими; наконец, парсер позволяет избирательно обращаться к вышеупомянутым составляющим. Итак, HTML-парсер открывал мне легкий доступ ко всем тегам столбцов в конкретной таблице внутри HTML-документа. Я воспользовался программой BeautifulSoup, она же bs4.
В BeautifulSoup есть поисковые функции, позволяющие найти конкретную HTML-таблицу с данными о продажах и циклически перебрать все ее строки, заполняя при этом объект Python значениями из столбцов таблицы.
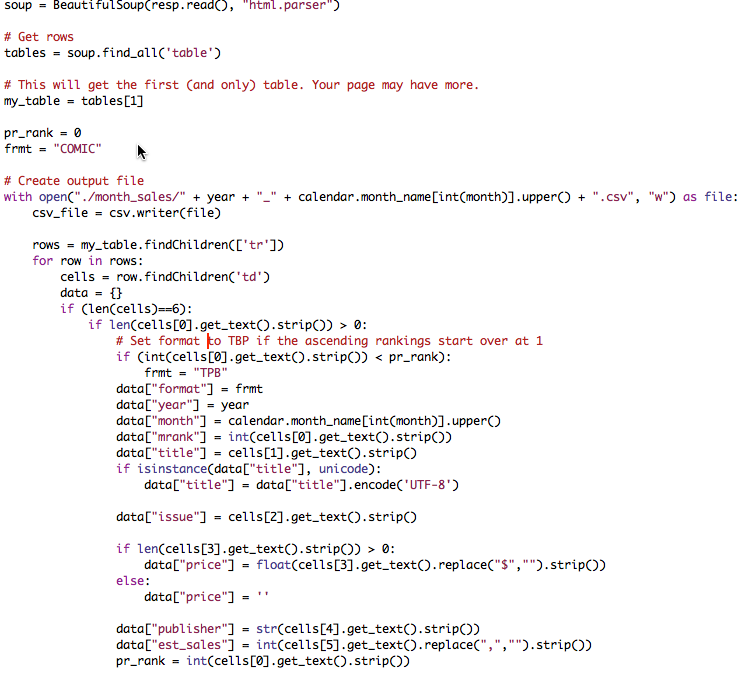
Этот объект Python под названием data содержит поля, заполненные данными из различных источников. Информация о годе и месяце заполняется на основе аргументов, переданных модулю. Поле формата устанавливается динамически, исходя из логики, по которой строятся рейтинги, а остальные поля заполняются в зависимости от того, где именно их источники расположены в HTML-таблице. Как видите, здесь много жестко закодированной логики, которую пришлось бы обновлять вручную, если бы изменился формат того сайта, с которого мы извлекаем данные. Однако, пока мы справляемся с задачей, пользуясь описанной здесь логикой.
Последний этап решения задачи — записать эти объекты Python в CSV-файл. В модуле Python CSV есть функция writerow(), принимающая в качестве параметра массив и записывающая все элементы массива как столбцы в формате CSV.
При первом прогоне программа выдала исключение, поскольку в поле title содержались символы unicode, которые не мог обработать механизм записи в CSV.

Чтобы справиться с этим, пришлось добавить проверку на unicode и закодировать все содержимое как UTF-8. Unicode и UTF-8 — это символьные кодировки, то есть, они служат словарями, при помощи которых компьютеры идентифицируют символы. В кодировках содержатся алфавитные и логографические символы из различных языков, а также другие распространенные символы, например,.
Кроме того, требовалось переформатировать значения в некоторых числовых полях (в частности, удалить оттуда символы $ и запятые), чтобы позже над этими значениями можно было производить математические действия. В остальном загрузка данных прошла вполне гладко. Для каждого месяца был сгенерирован файл под названием (MONTH)_(YEAR).CSV. Каждый из этих файлов выглядел так:

Хотя в результате были сгенерированы десятки тысяч строк с данными о продажах комиксов, мне этого было недостаточно. То есть, у меня имелся нужный объем информации, но она получилась недостаточно широкой. Чтобы делать точные прогнозы, мне нужно было заполнить в модели и другие переменные, а не только название комикса, номер выпуска и цену. Издательство не имело значения, так как я решил поупражняться лишь с комиксами Marvel, а передача примерных данных по продажам была бы жульничеством, поскольку рейтинг зависит от продаж. Итак, чтобы улучшить мое множество данных, я извлек метаданные о каждом выпуске из «облака», воспользовавшись Marvel«s Developer API. К счастью, поскольку этот API является веб-сервисом, удалось обойтись без скрепинга экрана.
Извлекать и объединять эти данные было не так просто как может показаться. Основная проблема заключалась в том, что названия выпусков, полученные путем скрепинга, не полностью совпадали с названиями, сохраненными в базе данных Marvel. Например, в массиве данных, полученных путем скрепинга, фигурирует название «All New All Different Avengers». Воспользовавшись API для поиска по базе данных Marvel я ничего такого не нашел. В итоге удалось вручную отыскать у них в базе данных запись «All-New All-Different Avengers». В других случаях попадались лишние слова, сравните: «The Superior Foes of Spider-Man» и «Superior Foes of Spider-Man». Итак, чтобы выполнить поиск по названию, я должен был знать, в каком виде название может упоминаться в базе данных Marvel. Для этого я решил сделать список названий всех тех серий, чьи метаданные были изменены в течение промежутков времени, по которым у меня были данные о продажах. И вновь я столкнулся с препятствием. API Marvel позволял извлекать не более 100 результатов по одному запросу, а Marvel опубликовали тысячи комиксов. Чтобы обойти эту проблему, пришлось извлекать данные инкрементно, сегментируя их по алфавиту.

Даже здесь возникли небольшие проблемы, поскольку на некоторые буквы, например, «S», попадалось более 100 названий. Чтобы решить их, мне пришлось извлекать все названия на «S» сначала в алфавитном, а потом в обратном алфавитном порядке, затем комбинировать эти результаты и избавляться от всех дублей. Поэтому советую внимательно разбираться со всеми ограничениями того API, который вы собираетесь использовать. Возможно, какие-то ограничения окажутся неустранимыми, но, может быть, их и удастся обойти, изобретательно формулируя запросы.

На данном этапе у меня уже был список названий серий Marvel, сохраненных в нескольких CSV-файлах, которые я в итоге сложил в один файл MarvelSeriesList.csv, чтобы было проще работать. Но у меня было и еще кое-что. Извлекая названия серий, я также сохранял ID каждой серии и рейтинг ее репрезентативности. Поиск по ID гораздо более точен, чем по имени, а рейтинг репрезентативности может пригодиться при построении прогностической модели. Далее требовалось перебрать все строки CSV-файлов, созданных на основе данных о продажах, найти соответствия с ID из файла MarvelSeriesList.csv и использовать этот ID для извлечения соответствующих метаданных через API.
Как вы помните, последний этап понадобился потому, что заголовки, сохраненные в файлах с данными о продажах, не совпали с заголовками в API, и мне требовалось каким-то образом объединить два этих источника. Я не стал писать кейсы для обработки каждого сценария (например, несовпадение пунктуации, лишние слова), я нашел библиотеку Python для поиска нечетких соответствий. Мне попалась исключительно полезная библиотека Fuzzy Wuzzy.Fuzzy Wuzzy, в которой была функция extractOne(). Эта функция позволяет передать термин и сравнить его с массивом значений. Затем функция extractOne() возвращает найденный в массиве термин, максимально соответствующий запросу. Кроме того, можно задать нижний предел приемлемости соответствия (т.е. возвращать лишь те результаты, степень соответствия которых >= 90%).
Опять же, пришлось немного повозиться, чтобы такая конфигурация работала эффективно. На первый раз всего для 65% названий в списках продаж удалось найти соответствия. На мой взгляд, скрипт отсеивал слишком много данных, поэтому пришлось присмотреться к исключениям и выяснить, какие соответствия от меня ускользают. Так, обнаружилась следующая проблема: заголовки, привязанные в базе данных Marvel к конкретному году, например, «All-New X-Men (2012)», имели рейтинг соответствия более 80 при сравнении с такими заголовками как «All New X-Men». Эта проблема встречалась постоянно, поэтому я решил не занижать процент соответствия (в таком случае, скрипт мог не заметить некоторых реальных несовпадений), а при несовпадении отсекать год и проверять соответствие снова. Почти получилось. Была еще такая проблема: библиотека This was a pretty consistent issue, so rather than lowering the match percentage, which Fuzzy Wuzzy плохо сравнивала акронимы и акростихи. Так, при сравнении «S.H. E.I.L. D.» и «SHIELD» получалась степень соответствия около 50. Дело в том, что во втором варианте не хватало половины символов (точек). Поскольку в этом случае затрагивалось всего два названия, я написал поисковый словарь со специальными случаями, которые требовалось «переводить». В описываемом упражнении можно было пропустить этот шаг, поскольку у меня и так получалось приличное соответствие, но для стопроцентно точного поиска совпадений он необходим. Как только функция поиска соответствий заработала, я подключил urllib2 и извлек все метаданные по выпускам, которые смог достать.
В готовых файлах содержались не только данные о продажах (название, номер выпуска, месячный рейтинг, примерные продажи), но и информация об авторах, самих выпусках, персонажах, датах выхода и соответствующих сюжетных линиях.
