[Из песочницы] World of Tanks: от чего же зависит винрейт танков?
Сегодня мы поговорим об использовании Wargaming API, построим много графиков и проанализируем, от чего же зависит винрейт танков. Сразу хочу отметить, что я не гуру World of Tanks, и если я где-то ошибся, то напишите пожалуйста в комментариях.

На гистограмме винрейта по всем танкам видно, что общее распределение нормальное, но есть хвост справа. Попробуем разобраться.
В игре World of Tanks многие игроки уделяют большое внимание статистике своего аккаунта, а именно винрейту (процент побед), личному рейтингу, WN8 и т.д. Для этих параметров есть формулы, которые учитывают множество характеристик. В основном на винрейт игрока влияет средний урон за бой, выживаемость, средний уровень боёв и еще нескольких параметров. Но от чего же зависит винрейт отдельного танка? Самый очевидный вариант — от игроков, которые на нём больше играют. Но сегодня я хочу провести анализ параметров танков, не включая средний урон на танке по серверу и подобные характеристики, которые мы не можем увидеть из ангара.
И так если взять отдельный бой, то в каждой команде по 15 человек, следовательно, каждый игрок в среднем влияет на исход боя на 6.66%. Если бы в команде было меньше игроков, то их бы стало сложнее балансить, а так влияние каждого сглаживается. Команды формируются матчмейкером на основе веса каждого танка так, чтобы суммарная разница весов команд была минимальна. Вес танка зависит от его уровня боёв и его класса — тяжелый, средний, лёгкий, пт или пт-сау. Общепринятое мнение в игре, что все результаты боёв сводятся к усреднённым 49% побед, столько же поражений и 2% ничьих.
Понятно, что чем больше урона игрок будет наносить и чем меньше получать, тем больше шансов выиграть, а значит повысить свой винрейт. Это в большей степени зависит от самого игрока и его опыта, так как даже самый крутой танк в «не тех руках» не принесёт пользы команде.
Получение данных
Чтобы получить данные можно воспользоваться публичным Wargaming API, который предоставляет довольно много различных сведений об игроках и технике. С помощью GET запроса с полем account_id по адресу https://api.worldoftanks.ru/wot/account/tanks/ можно получить информацию о технике игрока, а именно общее количество боёв и побед на каждом танке в json формате. Я делал в лоб: в цикле от 0 до 40кк пытался получить данные по всем account_id. Отрывок кода на python:
url_users = 'https://api.worldoftanks.ru/wot/account/tanks/'
# создаётся соединение Keep-Alive, что уменьшает время на запрос
session = requests.Session()
def get_users_json(ids):
# можно передавать массив из 100 id
# application_id можно получить в кабинете разработчика WG
params = {'account_id': ids, 'application_id': 'demo'}
while True:
try:
r = session.get(url_users, params)
r_json = r.json()
except:
# хоть таким способом я не разу и не упёрся
# в лимит по количеству запросов, но всё же
time.sleep(1)
continue
if r.status_code == 200 and r_json['status'] == 'ok':
return r_json['data']
Конечно можно было воспользоваться модулем для многопоточности или для асинхронности, что несомненно бы ускорило загрузку. На моём компьютере скрипт работал 2 дня и скачал данные о 26 млн пользователей. Так как я уезжал на выходные, то 2 дня загрузки были не критичны.
Далее мы можем посчитать винрейт для каждого танка (всего 450), а также получить подробные характеристики по всей технике. Характеристики можно получить запросом на https://api.worldoftanks.ru/wot/encyclopedia/vehicles/, но API не говорит нам, какие модули являются топовыми для данного танка. В ответе этого метода есть поле «modules_tree», в котором содержится дерево исследования модулей танка, поэтому пройдя по нему можно выбрать топовые модули. По определению — это модуль наибольшего уровня, а если таких несколько, то наиболее дорогой для исследования. Теперь можно сделать запрос на https://api.worldoftanks.ru/wot/encyclopedia/vehicleprofile/ передав id нужных модулей. В итоге получаем подробные данные по 450 танкам.
Работа с признаками
Для анализа данных я использовал питоновскую библиотеку pandas. Загрузим все данные в pandas.DataFrame, получили 450 строк и 40 колонок. Список всех признаков:

Все фичи должны быть интуитивно понятны, кроме ap_damage, apcr_damage, he_damge, hc_damage и такие же с _penetration. Это урон и бронепробитие разными типами снарядов. API возвращает информацию об орудии в виде массива объектов, которые содержат данные о уроне и бронепробитие для конкретного типа снарядов. Их есть 4 типа:
- ARMOR_PIERCING — бронебойные снаряды
- ARMOR_PIERCING_CR — подкалиберные снаряды
- HIGH_EXPLOSIVE — осколочно-фугасные снаряды
- HOLLOW_CHARGE — кумулятивные снаряды
API не говорит какой из снарядов основной, а какой покупается за золото, что усложняет анализ.
Создание и отбор признаков
На основе исходных данных можно получить более информативные признаки:
df['power'] = df.engine_power / (df.weight / 1000) # в лошадях на тонну
df['max_damage'] = df[['ap_damage', 'apcr_damage', 'he_damage', 'hc_damage']].max(axis=1)
df['max_penetration'] = df[['ap_penetration', 'apcr_penetration', 'he_penetration', 'hc_penetraion']].max(axis=1)
df['dpm'] = df['max_damage'] * df['gun_fire_rate'] # урон в минуту
def get_armor(y):
# если есть башня, то берём среднее значение лобовой брони башни и корпуса
# если нет, то просто берём лобовую броню корпуса
if y[1]:
return np.mean(y[:2])
else:
return y[0]
df['armor'] = df[['armor_hull_front', 'armor_turrer_sides']].apply(get_armor, axis=1)
Методом проб и ошибок (random forest) я отобрал самые значимые признаки (но далее мы также рассмотрим еще два интересных признака):

Для тех, кто не играл в WOT, здесь отображены: уровень танка (от 1 до 10), премиумный танк или нет, количество очков прочности, мощность (лошадей/тонну), скорострельность (выстрелов/минуту), скорость сведения орудия (сек), разброс орудия (метры), скорость вперёд (км/ч), максимальный урон (хп), максимальное бронепробитие (мм), урон в минуту (хп/мин), броня (мм).
Нормализация признаков
Перед тем как приступить к анализу нужно нормализовать некоторые фичи. Мы хотим получить значения, не зависящие от уровня танка, поэтому для каждого уровня будем нормализовывать отдельно. Другими словами, сделаем так, чтобы среднее значение признаков по уровню было равно 0. Такую нормализацию я провёл для максимального урона, максимального бронепробития, урона в минуту, брони, прочности и мощности.
Анализ данных
Зависит ли винрейт от нации техники? Логично предположить, что нет, так как разработчики пытаются максимально сбалансировать это. Давайте построим график. Для построения графиков я использовал библиотеку seaborn:
sns.factorplot('nation','winrate', data=df_normalized,size=4,aspect=3)
sns.plt.title('Winrate from nation')

В глаза сразу бросаются чешские танки — среднее значение винрейта 51%, но и разброс самый большой. Это объяснятся тем, что ветка относительно новая и многие игроки, которые уже выкачали всё, что только можно, бросились выкачивать и эту ветку. Понятно, что такие игроки довольно скиловые, поэтому и процент побед выше среднего. Также еще не все, кто играют против чехов, знают их слабые места и зоны пробития. Но со временем значение винрейта скорее всего выровняется (а если нет, то WG понерфит многие танки в ветке).
А как обстоят дела с классом техники, какой класс «нагибает»? Построим похожий график:
ax = sns.factorplot('type','winrate', data=df_normalized,size=5,aspect=3)
sns.plt.title('Winrate from type')

Видно, что самый большой шанс победить на среднем танке, а самый маленький на лёгких танках и артиллерии. То, что на лёгких танках такое значение — понятно. Многие игроки на этом классе, несутся сломя голову вперёд, сразу после начала боя, и естественно сливаются, не принося особой пользы команде. Арта это вообще отдельная тема, которую не будем здесь обсуждать.
Далее мы не будем говорить об этих двух признаках, так как они не вносят особой пользы в модель на основе random forest.
Посмотрим на корреляцию выбранных раннее признаков и процента побед:

Выделяется сильная корреляция is_premium с winrate. Неужели премиумные танки намного лучше обычных? Не совсем так. Такая сильная зависимость скорее всего объясняется тем, что на премиумной технике играют опытные игроки, чтобы фармить серебро, так как у многих танков, покупаемых за золото, льготный уровень боёв, больше серебра за бой, возможность быстрой прокачки экипажа. Можно построить график и посмотреть, как распределён винрейт на премиумной и обычной технике:
facet = sns.FacetGrid(df_normalized, hue="is_premium",aspect=4)
facet.map(sns.kdeplot,'winrate',shade= True)
facet.set(xlim=(0.40, df_normalized['winrate'].max()))
facet.add_legend()
sns.plt.title('Winrate from premium')

Видно, что плотность распределения побед на обычной технике — это Гаусовское нормальное распределение со средним значением 49%. Плотность распределения побед на премиумной технике вытянута в сторону большего винрейта, среднее значение 52%, а дисперсия намного больше чем у обычной техники.
В игре всего 114 премиумных танка, а это 25% от общего количества. На гистограмме всех танков по проценту побед мы видели хвост справа. Давайте посмотрим, какие танки попали в него:

Получается 93% танков из хвоста — премиумные. Что интересно остальные 7% (2 из 31) это чешские танки.
Также из таблицы корреляции видно, что винрейт прямо пропорционален уровню танка. Рассмотрим подробнее на графике:

Легко объяснить такую картину. На первых двух уровнях техники такой маленький винрейт из-за того, что все начинающие игроки портят статистику танкам из-за отсутствия опыта. Также на первых уровнях больше шансов оказаться внизу списка. На 10 уровне наоборот, ты всегда в топе. Также на 9–10 уровне играть без премиум аккаунта убыточно, поэтому большинство людей там, играют с премиумом.
Из оставшихся признаков прямо пропорциональны винрейту: прочность, скорость вперёд, урон в минуту и броня. Обратно пропорциональны: скорость сведения, разброс орудия. Пока всё очевидно, но дальше видно, что максимальный урон и бронепробитие обратно пропорциональны проценту побед.
Это странно, ведь чем больше танк наносит урона, тем лучше. Так и есть. Если еще раз взглянуть на то, как я получал значения для максимального урона, можно догадаться в чем подвох. Я просто брал максимальные значения урона и бронепробития из всех возможных снарядов для топового орудия. Но ведь чаще всего самый большой урон у фугасов (при самом маленьком бронепробитие), а фугасы далеко не самые часто используемые снаряды у обычных танков, получаем неточность. Также разовый урон может быть большой, а урон в минуту маленький из-за долгой перезарядки. Более того, отрицательное значение корреляции возможно связано с тем, что у артиллерии обычно самый большой урон и самый маленький винрейт — отсюда и обратная пропорциональность.
Важность признаков
Теперь можно построить random forest на этих данных и посмотреть на результат. Random forest это один из самых распространённых алгоритмов машинного обучения, основанный на усреднении результатов множества разных деревьев решений. Этот алгоритм хорошо подходит для того чтобы узнать важность отдельных признаков:

Я пробовал разные параметры и признаки, но сильно уменьшить ошибку мне не удалось. Видно, что алгоритм в среднем ошибается в предсказаниях на 1.3% процента. А теперь посмотрим на важность признаков для этого леса:
importances = rf.feature_importances_
std = np.std([tree.feature_importances_ for tree in rf.estimators_], axis=0)
indices = np.argsort(importances)[::-1]
legends = []
for i in range(X.shape[1]):
legends.append('%d.%s (%f)' % (i + 1, X.columns[indices[i]], importances[indices[i]]))
plt.title('Feature importances')
bars = plt.bar(range(X.shape[1]), importances[indices], color='c', yerr=std[indices], align='center')
plt.xticks(range(X.shape[1]), range(1, X.shape[1] + 1))
plt.xlim([-1, X.shape[1]])
plt.legend(bars, legends, fontsize=12)

Получилось, что для этой модели наиболее важным параметром оказалось — премиумный танк или нет, важность этого признака в два раза больше чем следующего по убыванию за ним. Следующие четыре по важности признака — это характеристики орудия, что тоже предсказуемо. Можно заметить, что я также добавил фичу принадлежности к чешской нации, так как это немного уменьшило ошибку. А вот добавление всех остальных фичей с нациями и классами техники не улучшало работу алгоритма.
Что будет, если мы уберем из выборки премиумные танки и обучим random forest с такими же параметрами? Результаты удобно представить на boxplot:
fig, ax1 = plt.subplots(figsize=(10, 6))
data = [score_with_premium, score_without_premim]
bp = plt.boxplot(data, notch=0, sym='+', vert=1, whis=1.5)
ax1.set_title('Comparison of score with and without premium')
ax1.set_ylabel('mean_absolute_error')
xtickNames = plt.setp(ax1, xticklabels=['With premium', 'Without premium'])
plt.setp(xtickNames, rotation=0, fontsize=12)
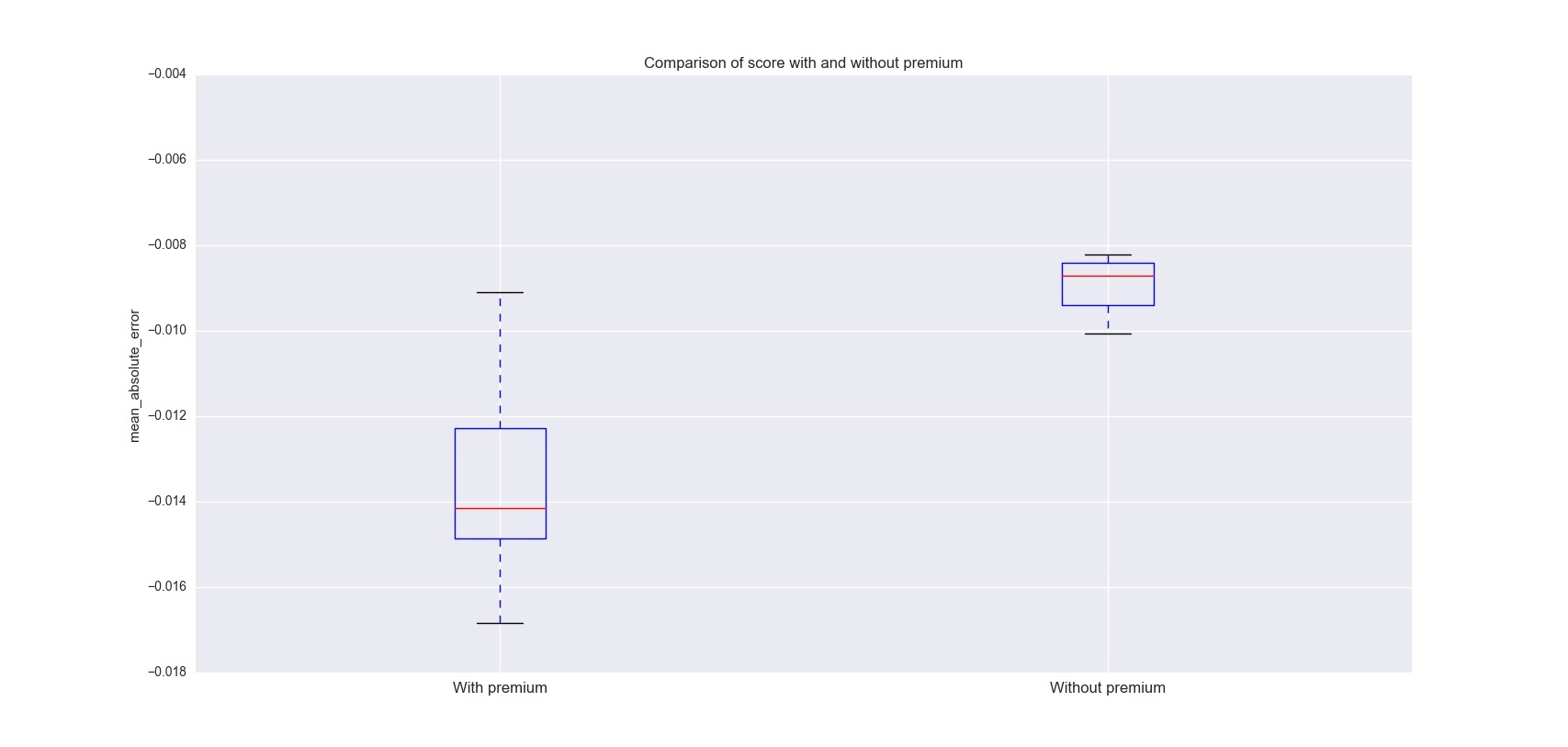
Алгоритму сразу стало намного легче угадывать процент побед и в среднем ошибка на кросс валидации уменьшилась до 0.9%, разброс ошибки также стал существенно меньше.
Заключение
Мы посмотрели, как работать с WG API. Узнали, как винрейт зависит от нации — на данный момент на чехах он самый нестабильный, от класса техники — на средних танках самый большой, а на арте самый маленький. Также увидели прямолинейную зависимость от уровня. Проанализировали, какие признаки у танка сильнее всего влияют на победу в бою — премиумный танк или нет, а также параметры орудия. Еще мы построили простую модель, которая относительно точно по характеристикам танка может предсказать его процент побед.
P.S.: Если вы тоже хотите поработать с этим датасетом, но не хотите загружать данные через API то пишите мне.
