[Перевод] Изучаем Metaflow за 10 минут
Metaflow — это Python-фреймворк, созданный в Netflix и ориентированный на сферу Data Science. А именно, он предназначен для создания проектов, направленных на работу с данными, и для управления такими проектами. Недавно компания перевела его в разряд опенсорсных. Фреймворк Metaflow в последние 2 года нашёл широкое применение внутри Netflix. Он, в частности, позволил значительно сократить время, необходимое для вывода проектов в продакшн.
Материал, перевод которого мы сегодня публикуем, представляет собой краткое руководство по Metaflow.
Что такое Metaflow?
Ниже показан график, иллюстрирующий внедрение фреймворка Metaflow в Netflix.
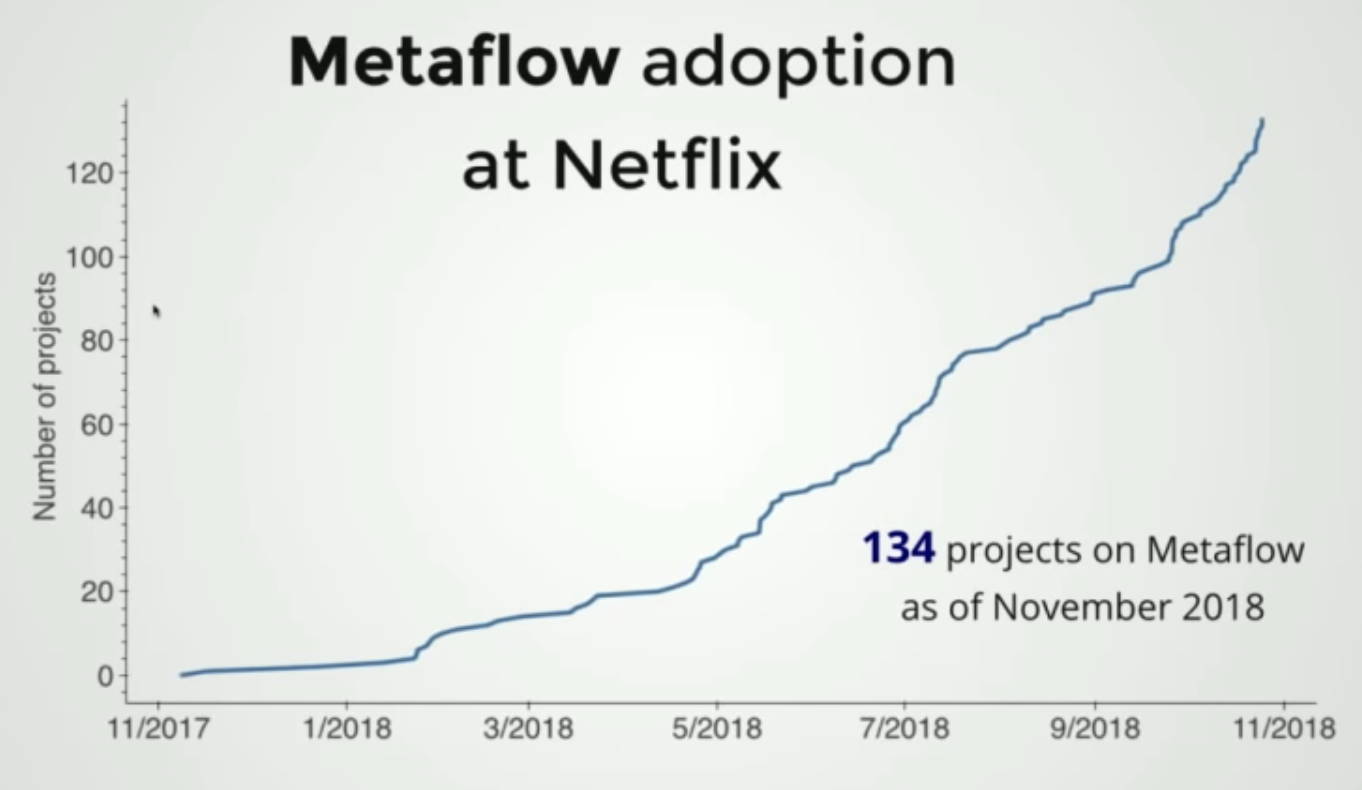
Внедрение Metaflow в Netflix
В ноябре 2018 года этот фреймворк использовался в 134 проектах компании.
Metaflow — это фреймворк для создания и выполнения рабочих процессов в сфере Data Science. Он отличается следующими возможностями:
- Управление вычислительными ресурсами.
- Контейнеризованный запуск задач.
- Управление внешними зависимостями.
- Версионирование, повторное выполнение задач, продолжение выполнения приостановленных задач.
- Клиентский API для исследования результатов задач, которым можно пользоваться в среде Jupyter Notebook.
- Поддержка режимов локального (например — на ноутбуке) и удалённого (в облаке) выполнения задач. Возможность переключения между этими режимами.
Пользователь vtuulos писал на Ycombinator о том, что Metaflow умеет автоматически создавать снапшоты (снимки) кода, данных и зависимостей. Всё это размещается в хранилище с адресацией по содержимому, в основе которого обычно лежит S3, хотя поддерживается и локальная файловая система. Это позволяет продолжать выполнение остановленных задач, воспроизводить ранее полученные результаты, исследовать всё, что имеет отношение к задачам, например, в Jupyter Notebook.
В целом можно сказать, что Metaflow нацелен на повышение продуктивности труда дата-сайентистов. Делается это благодаря тому, что фреймворк позволяет им заниматься исключительно работой с данными, не отвлекаясь на решение сопутствующих задач. Кроме того, Metaflow ускоряет вывод проектов, основанных на нём, в продакшн.

Потребности дата-сайентиста, связанные с его прямыми обязанностями, и решение вспомогательных задач, касающихся инфраструктуры, на которой выполняются вычисления
Сценарии организации работы, возможные благодаря Metaflow
Вот несколько сценариев организации работы, которые можно организовать с использованием Metaflow:
- Коллаборация. Один дата-сайентист хочет помочь другому в поиске источника ошибки. При этом помощнику хотелось бы загрузить на свой компьютер всю ту среду, в которой работала задача, давшая сбой.
- Продолжение выполнения остановленных задач с того места, где они были остановлены. Некая задача остановилась с ошибкой (или была остановлена намеренно). Ошибку исправили (или отредактировали код). Нужно перезапустить задачу так, чтобы её работа продолжилась бы с того места, в котором она дала сбой (или была остановлена).
- Гибридное выполнение задач. Нужно выполнить некий шаг рабочего процесса локально (возможно — это шаг загрузки данных из файла, который хранится в папке на компьютере), а другой шаг, требующий больших вычислительных ресурсов (возможно — это обучение модели), нужно выполнить в облаке.
- Исследование метаданных, полученных после выполнения задачи. Три дата-сайентиста занимаются подбором гиперпараметров одной и той же модели, стремясь повысить точность этой модели. После этого нужно проанализировать результаты выполнения задач по обучению модели и выбрать набор гиперпараметров, который показал себя наилучшим образом.
- Использование нескольких версий одного и того же пакета. В проекте нужно использовать разные версии, например, библиотеки sklearn. При препроцессинге требуется её версия 0.20, а при моделировании — версия 0.22.
Типичный рабочий процесс Metaflow
Рассмотрим типичный рабочий процесс, реализуемый в среде Metaflow, с концептуальной точки зрения и с точки зрения программирования.
▍Концептуальный взгляд на рабочий процесс Metaflow
С концептуальной точки зрения рабочие процессы Metaflow (цепочки задач) представлены ориентированными ациклическими графами (directed acyclic graph, DAG). Лучше понять эту идею помогут иллюстрации, представленные ниже.
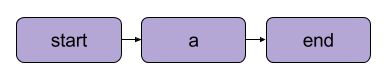
Линейный ациклический граф
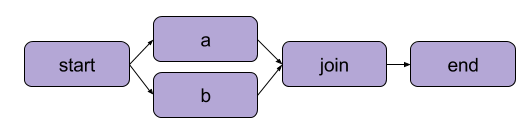
Ациклический граф с «параллельными» путями
Каждый узел графа представляет этап обработки данных в рабочем процессе.
На каждом шаге цепочки задач Metaflow выполняет обычный Python-код, не внося в него специальных изменений. Выполнение кода ведётся в отдельных контейнерах, в которые код упакован вместе с его зависимостями.
Ключевой аспект архитектуры Metaflow представлен тем фактом, что он позволяет внедрять в основанные на нём проекты практически любые внешние библиотеки из экосистемы conda и при этом не пользоваться плагинами. Этим Metaflow отличается от других подобных решений общего назначения. Например — от Airflow.
▍Рабочий процесс Metaflow с точки зрения программирования
Каждая цепочка задач (поток) может быть представлена в виде стандартного Python-класса (в именах таких классов обычно есть слово Flow) в том случае, если она удовлетворяет следующим минимальным требованиям:
- Класс является наследником класса Metaflow
FlowSpec. - К каждой функции, которая представляет шаг в цепочке задач, применён декоратор
@step. - В конце каждой
@step-функции должно присутствовать указание на подобную функцию, которая следует за ней. Сделать это можно с помощью конструкции такого вида:self.next(self.function_name_here). - Класс реализует функции
startиend.
Рассмотрим пример минимальной цепочки задач, состоящей из трёх узлов.
Её схема выглядит так:
start → process_message → end
Вот её код:
from metaflow import FlowSpec, step
class LinearFlow(FlowSpec):
"""
Цепочка задач, нацеленная на проверку возможности использования Metaflow.
"""
# Глобальная инициализация
@step
def start(self):
self.message = 'Thanks for reading.'
self.next(self.process_message)
@step
def process_message(self):
print('the message is: %s' % self.message)
self.next(self.end)
@step
def end(self):
print('the message is still: %s' % self.message)
if __name__ == '__main__':
LinearFlow()Инструкции по установке Metaflow
▍Установка и пробный запуск
Вот последовательность действий, которые нужно выполнить для установки и первого запуска Metaflow:
- Установите Metaflow (рекомендуется пользоваться Python 3):
pip3 install metaflow. - Поместите вышеприведённый фрагмент кода (вот он же на GitHub) в файл
linear_flow.py. - Для того чтобы посмотреть на архитектуру цепочки задач, реализуемой этим кодом, воспользуйтесь командой
python3 linear_flow.py show. - Для запуска потока выполните команду
python3 linear_flow.py run.
У вас должно получиться нечто, подобное тому, что показано ниже.
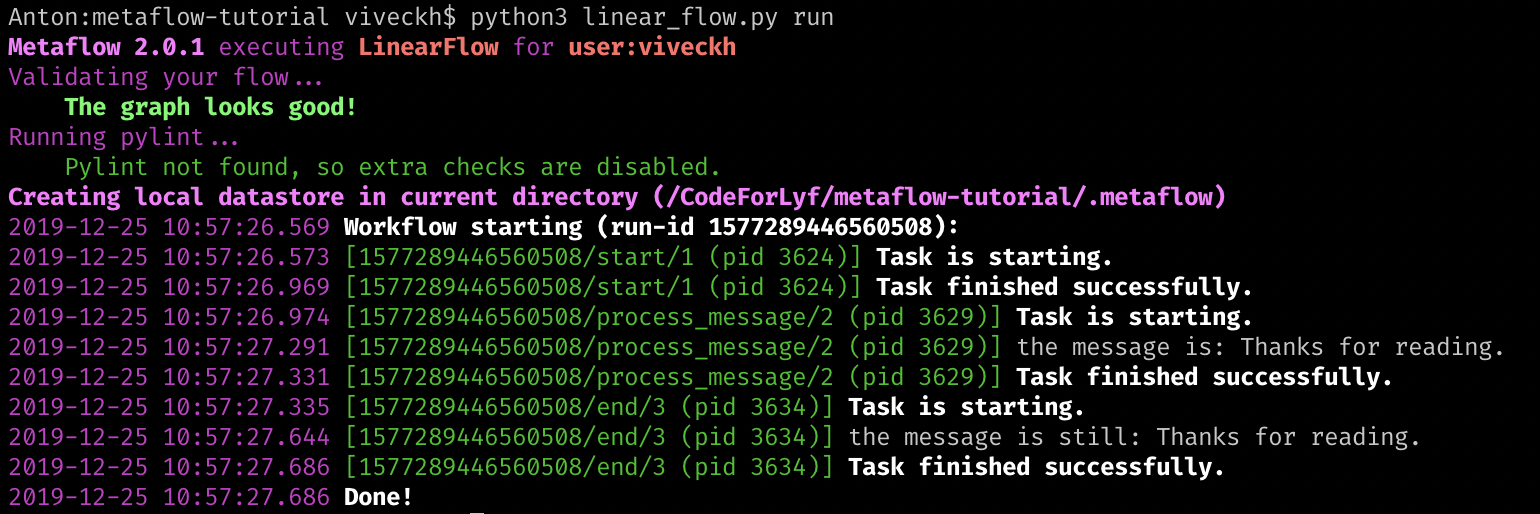
Успешная проверка работоспособности Metaflow
Тут стоит обратить внимание на некоторые вещи. Фреймворк Metaflow создаёт локальное хранилище данных .metaflow. Там он хранит все метаданные, касающиеся выполнения задач и снапшоты, связанные с сеансами выполнения задач. Если настроены параметры Metaflow, имеющие отношение к облачному хранению данных, то снапшоты будут храниться в AWS S3 Bucket, а метаданные, касающиеся запусков задач, попадут в службу Metadata, основанную на RDS (Relational Data Store, реляционное хранилище данных). Позже мы поговорим о том, как исследовать эти метаданные с помощью клиентского API. Ещё одна мелочь, хотя и важная, на которую стоит обратить внимание, заключается в том, что идентификаторы процессов (pid, process ID), прикреплённые к разным шагам, различаются. Вспомните — выше мы говорили о том, что Metaflow независимо контейнеризует каждый шаг цепочки задач и выполняет каждый шаг в его собственном окружении (передавая между шагами лишь данные).
▍Установка и настройка conda (если планируется внедрять зависимости)
Для установки conda выполните следующие шаги:
Теперь вы готовы к внедрению зависимостей conda в свои цепочки задач. Подробности этого процесса мы рассмотрим ниже.
Пример реализации реалистичного рабочего процесса
Выше мы говорили о том, как установить Metaflow, и о том, как убедиться в том, что система работоспособна. Кроме того, мы обсудили основы архитектуры рабочих процессов, рассмотрели простой пример. Здесь мы рассмотрим более сложный пример, попутно раскрывая некоторые концепции Metaflow.
▍Задание
Создадим средствами Metaflow рабочий процесс, который реализует следующие функции:
- Загрузка CSV-данных о фильмах в датафрейм Pandas.
- Параллельное вычисление квартилей для жанров.
- Сохранение словаря с результатами вычислений.
▍Цепочка задач
Ниже показан скелет класса GenreStatsFlow. Проанализировав его, вы поймёте сущность реализуемого здесь подхода к решению нашей задачи.
from metaflow import FlowSpec, step, catch, retry, IncludeFile, Parameter
class GenreStatsFlow(FlowSpec):
"""
Поток, вычисляющий показатели, характеризующие жанры фильмов.
Этот поток состоит из следующих шагов:
1) Загрузка CSV-данных в датафрейм Pandas.
2) Параллельное вычисление квартилей для жанров.
3) Сохранение словаря с результатами вычислений.
"""
@step
def start(self):
"""
Начальный шаг:
1) Загрузить метаданные фильмов в датафрейм Pandas.
2) Найти все уникальные жанры.
3) Запустить процесс параллельного вычисления показателей для каждого жанра.
"""
# TODO: Загрузка CSV и получение списка уникальных жанров
self.genres = []
self.next(self.compute_statistics, foreach='genres') # Фрагмент 1
@catch(var='compute_failed') # Фрагмент 2
@retry(times=1) # Фрагмент 3
@step
def compute_statistics(self):
"""Вычисление показателей для отдельного жанра. Выполняется в облаке."""
self.genre = self.input # Фрагмент 4
# TODO: Вычисление показателей для жанра
self.next(self.join)
@step
def join(self, inputs):
"""Объединение результатов обработки параллельных ветвей в виде словаря."""
# TODO: Объединение результатов
self.next(self.end)
@step
def end(self):
"""End the flow."""
pass
if __name__ == '__main__':
GenreStatsFlow()
Рассмотрим некоторые важные части этого примера. В коде есть комментарии вида # Фрагмент n, на которые мы будем ссылаться ниже.
- Во
Фрагменте 1, на шагеstart, обратите внимание на параметрforeach. Благодаря ему производится параллельное выполнение копий шаговcompute_statisticsв циклеfor eachдля каждой записи в спискеgenres. - Во
Фрагменте 2декоратор@catch(var='compute_failed')перехватит любое исключение, возникшее на шагеcompute_statisticsи запишет его в переменнуюcompute_failed(она может быть прочитана на следующем шаге). - Во
Фрагменте 3декоратор@retry(times=1)выполняет именно то, на что намекает его название. А именно, он, при возникновении ошибок, повторяет выполнение шага. - Откуда во
Фрагменте 4, вcompute_statistics, берётсяself.input? Дело в том, чтоinput— это переменная класса, предоставляемая Metaflow. Она содержит данные, применимые к конкретному экземпляруcompute_statistics(когда имеется несколько копий функции, выполняемых параллельно). Эта переменная добавляется Metaflow только тогда, когда узлы представлены несколькими параллельными процессами, или тогда, когда несколько узлов объединяются. - Здесь показан пример параллельного запуска одной и той же функции —
compute_statistics. Но, если нужно, параллельно можно запускать совершенно разные, не связанные друг с другом функции. Для этого требуется поменять то, что показано воФрагменте 1, на нечто вродеself.next(self.func1, self.function2, self.function3). Конечно, при таком подходе надо будет переписать и шагjoin, сделав так, чтобы на нём можно было бы обработать результаты выполнения разных функций.
Вот как можно представить вышеописанный скелет класса.
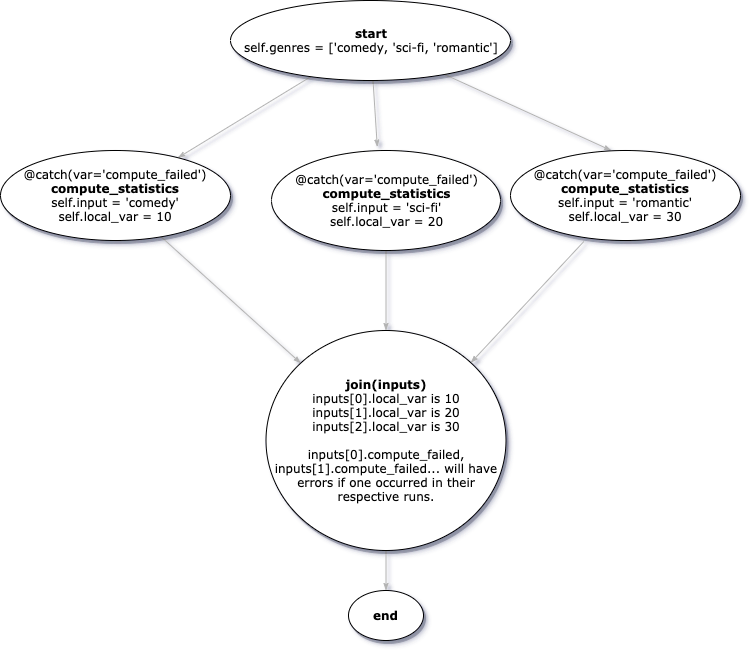
Визуальное представление класса GenreStatsFlow
▍Чтение файла с данными и передача параметров
- Загрузите этот CSV-файл с информацией о фильмах.
- Теперь нужно оснастить программу поддержкой возможности динамической передачи в цепочку заданий пути к файлу
movie_dataи значенияmax_genres. Нам поможет в этом механизм внешних аргументов. Metaflow позволяет передавать в программу аргументы, применяя дополнительные флаги в команде запуска рабочего процесса. Например, это может выглядеть так:python3 tutorial_flow.py run --movie_data=path/to/movies.csv --max_genres=5. - Metaflow даёт разработчику объекты
IncludeFileиParameter, которые позволяют прочитать входные данные в коде рабочего процесса. Мы обращаемся к переданным аргументам, назначая объектыIncludeFileиParameterпеременным класса. Зависит это от того, что именно мы хотим прочитать — файл, или обычное значение.
Вот как в коде выглядит чтение параметров, переданных программе при её запуске из командной строки:
movie_data = IncludeFile("movie_data",
help="The path to a movie metadata file.",
default = 'movies.csv')
max_genres = Parameter('max_genres',
help="The max number of genres to return statistics for",
default=5)▍Внедрение в цепочку задач conda
- Если вы ещё не устанавливали conda — обратитесь к разделу этого материала, посвящённого установке и настройке conda.
- Добавьте к классу
GenreStatsFlowдекоратор@conda_base, предоставляемый Metaflow. Этот декоратор ожидает, что ему передадут версию python. Её можно либо задать в коде, либо получить, воспользовавшись вспомогательной функцией. Ниже приведён код, в котором демонстрируется использование декоратора и показана вспомогательная функция.def get_python_version(): """ Вспомогательная функция, позволяющая получить версию python, используемую в этом руководстве. Это позволяет обеспечить создание окружения conda с применением доступной версии python. """ import platform versions = {'2' : '2.7.15', '3' : '3.7.4'} return versions[platform.python_version_tuple()[0]] # Использование в цепочке задач выясненной версии python. @conda_base(python=get_python_version()) class GenreStatsFlow(FlowSpec): - Теперь можно добавить декоратор
@condaк любому шагу цепочки задач. Он ожидает объект с зависимостями, который передаётся ему через параметрlibraries. Metaflow, перед запуском шага, возьмёт на себя задачу по подготовке контейнера с указанными зависимостями. Если нужно, то можно совершенно спокойно использовать разные версии пакетов на разных шагах, так как Metaflow запускает каждый шаг в отдельном контейнере.@conda(libraries={'pandas' : '0.24.2'}) @step def start(self): - Теперь выполним следующую команду:
python3 tutorial_flow.py --environment=conda run.
▍Реализация шага start
@conda(libraries={'pandas' : '0.24.2'})
@step
def start(self):
"""
Начальный шаг:
1) Загрузить метаданные фильмов в датафрейм Pandas.
2) Найти все уникальные жанры.
3) Запустить процесс параллельного вычисления показателей для каждого жанра.
"""
import pandas
from io import StringIO
# Загрузка набора данных в датафрейм Pandas.
self.dataframe = pandas.read_csv(StringIO(self.movie_data))
# В столбце 'genres' имеется список жанров для каждого фильма. Получим
# список уникальных жанров.
self.genres = {genre for genres \
in self.dataframe['genres'] \
for genre in genres.split('|')}
self.genres = list(self.genres)
# Нам нужно вычислить некоторые показатели для каждого жанра.
# Аргумент 'foreach' позволяет параллельно вычислять показатели для
# каждого жанра
self.next(self.compute_statistics, foreach='genres')
Рассмотрим некоторые особенности этого кода:
- Обратите внимание на то, что выражение импорта pandas находится внутри функции, описывающей шаг. Дело в том, что эта зависимость внедряется conda только в области видимости данного шага.
- Но переменные, объявленные здесь (
dataframeиgenres) доступны даже в коде шагов, выполняемых после данного шага. Тут дело в том, что Metaflow работает на основе принципов разделения окружений выполнения кода, но позволяет данным естественным образом перемещаться между шагами цепочки задач.
▍Реализация шага compute_statistics
@catch(var='compute_failed')
@retry
@conda(libraries={'pandas' : '0.25.3'})
@step
def compute_statistics(self):
"""
Вычисление показателей для отдельного жанра.
"""
# Обрабатываемый жанр представлен свойством класса
# 'input'.
self.genre = self.input
print("Computing statistics for %s" % self.genre)
# Найдём все фильмы с таким жанром и создадим датафрейм, содержащий
# только эти фильмы и только интересующие нас столбцы.
selector = self.dataframe['genres'].\
apply(lambda row: self.genre in row)
self.dataframe = self.dataframe[selector]
self.dataframe = self.dataframe[['movie_title', 'genres', 'gross']]
# Вычислим данные по столбцу gross для соответствующих фильмов.
points = [.25, .5, .75]
self.quartiles = self.dataframe['gross'].quantile(points).values
# Объединим результаты, полученные для других жанров.
self.next(self.join)
Обратите внимание на то, что на этом шаге мы обращаемся к переменной dataframe, которая была объявлена на предыдущем шаге start. Мы модифицируем эту переменную. При переходе к следующим шагам такой подход, подразумевающий использование нового модифицированного объекта dataframe, позволяет организовать эффективную работу с данными.
▍Реализация шага join
@conda(libraries={'pandas' : '0.25.3'})
@step
def join(self, inputs):
"""
Объединение результатов обработки параллельных ветвей в виде словаря.
"""
inputs = inputs[0:self.max_genres]
# Объединение результатов вычислений, выполненных для отдельных жанров.
self.genre_stats = {inp.genre.lower(): \
{'quartiles': inp.quartiles,
'dataframe': inp.dataframe} \
for inp in inputs}
self.next(self.end)
Тут стоит выделить пару моментов:
- На этом шаге мы используем совсем другую версию библиотеки pandas.
- Каждый элемент в массиве
inputsпредставляет собой копию ранее выполненнойcompute_statistics. Она содержит состояние соответствующего прогона функции, то есть — значения различных переменных. Так,input[0].quartilesможет содержать квартили для жанраcomedy, аinput[1].quartiles— квартили для жанраsci-fi.
▍Готовый проект
Полный код проекта, который мы только что рассмотрели, можно найти здесь.
Для того чтобы посмотреть на то, как устроен рабочий процесс, описанный в файле tutorial_flow.py, нужно выполнить такую команду:
python3 tutorial_flow.py --environment=conda show
Для запуска рабочего процесса используется следующая команда:
python3 tutorial_flow.py --environment=conda run --movie_data=path/to/movies.csv --max_genres=7Исследование результатов запуска рабочего процесса с помощью клиентского API
Для того чтобы исследовать снапшоты данных и состояний предыдущих запусков рабочего процесса, можно использовать клиентский API, предоставляемый Metaflow. Этот API идеально подходит для изучения подробностей о проведённых экспериментах в среде Jupyter Notebook.
Вот — простой пример вывода переменной genre_stats, взятой из данных последнего успешного запуска GenreStatsFlow.
from metaflow import Flow, get_metadata
# Вывод сведений о провайдере метаданных
print("Using metadata provider: %s" % get_metadata())
# Загрузка результатов анализа из MovieStatsFlow.
run = Flow('GenreStatsFlow').latest_successful_run
print("Using analysis from '%s'" % str(run))
genre_stats = run.data.genre_stats
print(genre_stats)Запуск рабочих процессов в облаке
После того, как вы создали и опробовали рабочий процесс на обычном компьютере, весьма вероятно то, что вам, для ускорения работы, захочется запустить код в облаке.
В настоящее время Metaflow поддерживает лишь интеграцию с AWS. На следующем изображении можно видеть сопоставление локальных и облачных ресурсов, используемых Metaflow.

Интеграция Metaflow и AWS
Для подключения Metaflow к AWS нужно выполнить следующую последовательность шагов:
- Для начала надо сделать единовременную настройку AWS, создав ресурсы, с которыми сможет работать Metaflow. Одними и теми же ресурсами могут пользоваться, например, члены рабочей команды, которые демонстрируют друг другу результаты выполнения рабочих процессов. Здесь можно найти соответствующие инструкции. Настройки выполняются достаточно быстро, так как в Metaflow имеется шаблон настроек CloudFormation.
- Далее, на локальном компьютере, надо выполнить команду
metaflow configure awsи ввести ответы на вопросы системы. Благодаря этим данным Metaflow сможет пользоваться облачными хранилищами данных. - Теперь, для запуска локальных рабочих процессов в облаке, достаточно добавить к команде запуска рабочего процесса ключ
--with batch. Например, это может выглядеть так:python3 sample_flow.py run --with batch. - Для того чтобы произвести гибридный запуск рабочего процесса, то есть — выполнить некоторые шаги локально, а некоторые — в облаке, нужно добавить декоратор
@batchк тем шагам, которые надо выполнить в облаке. Например — так:@batch(cpu=1, memory=500).
Итоги
Здесь хотелось бы отметить пару особенностей Metaflow, которые можно считать как достоинствами, так и недостатками этого фреймворка:
- Metaflow тесно интегрирован с AWS. Но в планах развития фреймворка есть поддержка большего числа облачных провайдеров.
- Metaflow — это инструмент, который поддерживает исключительно интерфейс командной строки. Графического интерфейса у него нет (в отличие от других универсальных фреймворков для организации рабочих процессов, таких, как Airflow).
Уважаемые читатели! Планируете ли вы пользоваться Metaflow?

