[Перевод] Использование потенциальных полей в сценарии стратегии реального времени
Реализация поведения юнитов в RTS играх может стать серьезной проблемой. Компьютер, зачастую, контролирует огромное количество юнитов, в том числе и принадлежащих игроку, которые должны передвигаться в большом динамическом мире, попутно избегая столкновения друг с другом, выискивая врагов, защищая собственные базы и координируя атаки для истребления противника. Стратегии реального времени работают в реальном времени, что делает довольно сложным слежение за планированием действий и навигацией.
Этот урок описывает метод планирования течения игры и навигации юнитов, который использует многоагентные потенциальные поля. Он основан на работах под номерами [1, 2, 3]. (Смотри в конце статьи ссылки на используемые материалы)

Что такое потенциальное поле?
ПП (Потенциальное Поле) имеет ряд сходств с картами влияния (influence maps). Карты влияния часто используются для определения находится ли зона в игровом мире под контролем игрока или врагов (в зоне дальнобойности оружия или передвижения), или же это зона, которая в данный момент не находится под контролем кого-либо (ничья земля). Идея состоит в том, чтобы поместить положительные значения на клетки под контролем игрока, а отрицательные — под контролем врага. Плавно уменьшая значение к нулю, мы создадим карту, отражающую влияние своих и вражеских юнитов в зоне. Рисунок ниже показывает пример карты влияния с одним своим и одним вражеским юнитом.

Потенциальные поля работают схожим образом — на интересующую позицию в игровом мире кладётся заряд и генерирует поле, которое постепенно сходит на ноль. Заряд может быть притягивающим (положительным) или отталкивающим (отрицательным). Обратите внимание, что в некоторой литературе о потенциальных полях отрицательные заряды притягивающие и наоборот. В этом уроке положительные заряды всегда прятивающие. Рисунок ниже показывает простой игровой мир с некоторой непроходимой территорией (коричневая), вражеского юнита (зелёный) и пункт назначения юнита (Е). Притягивающий заряд расположен в точке назначения.

Заряд генерирует поле, которое распространяется по игровому миру: 
И затухает до нуля: 
Навигация с помощью ПП
На иллюстрации выше притягивающее поле распространилось вокрут точки назначения «Е». Смысл в том, чтобы позволить зелёному юниту двигаться к позициям с наиболее притягиваемыми значениями и в конце концов найти путь к точке назначения. Чтобы заставить это работать нам также надо разобраться с препятсвиями в игровом мире, в данном случае с горами (коричныевые зоны). Если мы заставим горы генерировать небольшие отталкивающие поля и сложим их с притягивающими полями (с рисунка выше), мы получим результирующее поле, которое может быть использовано для навигации. Так как юниты всегда передвигаются на соседнюю позицию с максимально притягивающим значением, мы обойдем горы, если есть другой путь.

Та же идея используются и для других препятствий. На картинке ниже добавилось еще два своих юнита (белые). Они генерируют небольшие отталкивающие поля, которые снова суммируются с результирующим полем.

Таким образом наш зелёный юнит обойдет эти юниты, чтобы избежать столкновения. Теперь мы получили финальный путь для нашего юнита. Юнит может двигаться из текущей позиции к точке назначения и обойдет все препятствия без использования какого-либо алгоритма поиска пути.
Преимущества использования ПП
Одно из самых главных преимуществ использования потенциальных полей — возможность обрабатывать динамические игровые миры. Так как юниты (агенты) двигаются только по одному шагу за расчёт, вместо генерации полного пути из А в Б, то нет риска, что путь станет недоступен из-за изменений в игровом мире. Поиск пути в динамическом мире может часто быть сложным для реализации и требовать большое количество ресурсов для расчёта. Когда используется подход на основе потенциальных полей, решение проблемы приходит само, автоматически. Конечно нужно быть аккуратным при реализации системы ПП, чтобы не забывать делать обновления потенциальных полей эффективными насколько это возможно. (Об этом чуть позже).
Другое важное приемущество это возможность создавать сложное поведение, просто играясь с настройками формы генерируемых полей. Вместо линейного затухания до нуля мы можем использовать нелинейные поля. Если у нас, например, есть стреляющие юниты вроде танков в нашей армии, мы не хотим чтобы танки предвигались слишком близко к вражеским юнитам, но окружали их на нужной дистанции (например, на расстоянии дальности их стрельбы). Это поведение может быть достигнуто помещением нулевого заряда в точке нахождения вражеского юнита, генерирующего увеличивающеся поле с наиболее притягиваемой точкой на дальности стрельбы, а затем угасающее до нуля. Картинка снизу показывает пример с двумя танками (зелёные), движущимися в атаку на вражеского юнита (красный), генерирующему нелинейное ПП.

Пример уравнения, как такое поле может быть сгенерировано: 
Здесь W1 — значение для изменения относительной силы поля. D — максимальная дальность стрельбы и R — максимальная дальность обнаружения (откуда наш агент видит вражеского агента)
Другое поведение, которое легко реализовать это «пнул-убежал». Сперва юнит подходит на максимальное расстояние атаки.

После атаки наш юнит должен перезарядить своё оружие и отступает от вражеского юнита до тех пор, пока не будет готов стрелять снова.

Во время фазы отступления все вражеские юниты генерируют сильное отталкивающее поле с радиусом максимальной дальности стрельбы юнита. Это пример того, как специфичные потенциальные поля могут быть активными или неактивными в зависимости от внутреннего состояния агента, контроллирующего данного юнита. Неактивное поле просто игнорируется, когда суммируется результирующее потенциальное поле.
Картинка ниже — скриншот нашего бота, основанного на ПП для ORTS engine. Левая сторона изображения это 2D вид текущего состояния игры. Оно показывает наши танки (зеленые круги), идущие атаковать вражеские базы (красные квадраты) и юниты (красные круги). Коричневые и черные зоны — непроходимая территория (горы). С правой стороны изображения показано потенциальное поле этого состояния игры. Как и на других картинках из этого урока, голубые зоны наиболее притягивающие. Светлые линии — атаки наших танков. ПП-представление четко показывает как наши юниты окружают врага на максимальной дистанции выстрела, в то же время избегая столкновений друг с другом и местностью. Поведение окружения врага работает отлично и было, возможно, одним из ключевых в нашем успехе 2008 го года на ORTS tournament.

Пока мы разрабатывали нашего бота для ORTS, мы обнаружили одну вещь — совершенно иное поведение, когда суммирование потенциалов вражеских юнитов, сгенерированных в каждой точке сравнивалось с просто наиболее высоким потенциалом вражеского юнита в этой точке. На рисунке ниже потенциалы, сгенерированные тремя вражескими юнитами просуммированы и добавлены к результирующему полю. Таким образом наибольший потенциал оказывается прямо в центре вражеского кластера юнитов (обведено красным) и наши юниты очень стремились атаковать врагов в их самых сильных точках.

Решение было не суммировать потенциалы, но вместо этого брать наибольший потенциал в точке от всех юнитов. В последнем случае наиболее высокий потенциал вокруг врагов на допустимом расстоянии (показан красными линиями).

Заметки о реализации
С хорошим планом и реализацией ПП системы, затраты ресурсов на рассчёт не превысят традиционных решений на основе алгоритма А*. Наш ORTS бот использовал наименьшее количество ресурсов ЦП в сравнении с двумя другими ботами, работающими на алгоритмах поиска пути, с турнира 2007-го года. Однако, мы отметим, что сложно точно посчитать использование ЦП, из-за того, что побеждающий бот использует больше ресурсов в конце игры, так как у него остаётся больше юнитов под контролем. Многопоточность также усложняет задачу подсчета требуемых ресурсов ЦП. Сравнение было проведено путём сравнивания общего количества ресурсов ЦП, использованных каждым клиентским процессом в среде Линукса в течение 100 игр. По крайней мере мы можем сделать вывод, что бот был хорош в рамках выделенного времени в 0.125 сек, используемому в ORTS.
Для улучшения производительности мы поделили ПП на три категории:
- Статические поля. Поля, которые остаются статическими всю игру. В нашем случае местность. Это поле генерируется при старте.
- Полу-статическоие поля. Поля, не требующие частых обновлений. В нашем случае наши и вражеские базы. Эти поля генерируются при старте и обновляются при уничтожении базы.
- Динамические поля. Все динамические объекты игрового мира, такие как наши и вражеские танки. Эти поля обновляются каждый кадр. Для уменьшения времени рассчета можно считать их каждй второй или третий кадр.
Мы эксперементировали с двумя основными архитектурами для генерации ПП…
Пре-генерация
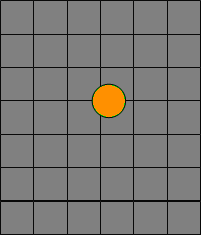
Поле, генерируемое каждым типом объекта было заранее рассчитано и хранилось в статических массивах в заголовочном файле. Во время выполнения программы эти поля просто добавлялись к общему ПП на нужной позиции. Чтобы сделать это возмоным игровой мир был поделен на тайлы, в нашем случае каждый тайл состоял из 8×8 точек игрового мира. Этот подход показал недостаточную детализацию и бот выступил плохо (2007 год турнира ORTS). Так как игровой мир был поделен на значительно большие тайлы, мы сталкивались с проблемами решения того, какой тайл (какие тайлы) объект занимает. Предположим объект (оранжевый круг) и база (оранжевый квадрат). Какие тайлы (серые квадраты) занимает наш зеленый юнит и какие тайлы должна занимать база?
Этот подход может подойти для игр типа Wargus, которые используют менее детализированную тайловую навигационную систему.

Вычисления в реальном времени
Потенциалы, генерируемые в точке, рассчитываются в реальном времени, путём рассчета расстояния между точкой и всеми ближайшими объектами, передавая каждое расстояние как переменную в функцию и затем подсчитывая потенциал. Этот подход, на самом деле, использует меньше ресурсов ЦП в нашем боте, нежели пре-генерированные поля.
Благодаря:
- Мы считаем потенциалы только тех точек, которые являются кандидатами на передвижение в них юнитов. В пре-генерированном варианте считаются все потенциалы всего игрового мира (естественно, это можно оптимизивать схожим методом).
- Рассчитав расстояние до объекта быстрым методом Манхэттена, мы можем избежать дорогостоящего рассчета расстояния в Эвклидовом пространстве для большого количества объектов в игровом мире.
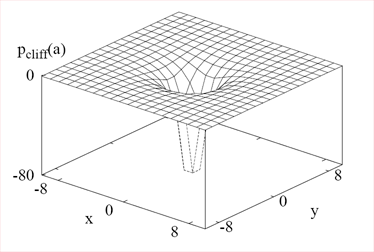
Этот подход был использован во второй версии нашего бота (турнир ORTS 2008 года). Пример формулы ПП (с 2Д и 3Д графиками), используемый для подсчета потенциала, генерируемоего утёсом в точке с расстоянием «а» от утёса.


А что с проблемой локального оптимума?
Одна из наиболее обычных проблем с ПП это проблема локального оптимума. На картинке снизу пример когда это проблема появляется. Пункт назначения «Е» генерирует круговое поле, которое блокируется горой. Юнит двигается к позициям с наиболее высокими потенциалами и заканчивает на самом большом, где он в данный момент и стоит. Юнит застрял.

Мы решили это использованием следа, схожего со следом феромонов, описанном в [4]. Каждый агент, контроллирующий юнит, добавляет след в последних N позициях, посещенных юнитом, а также в текущую позицию юнита. След генерирует легкий отталкивающий потенциал и «толкает» юнит вперёд. Смотрите как след толкает юнита вокруг локального оптимума (желтая линия) и юнит может найти путь к точке назначения.

Но даже со следами остаётся риск, что юнит застрянет в ситуациях, подобных той, что на картинке ниже.

Такое можно решить путём заполнения пустот:

Заключение
Ниже мы составили критику против решений, основанных на ПП с нашей точки зрения:
У ПП есть проблемы вроде локального оптимума, которые сложно решить. С использованием следа большинство локальных оптимумов могут быть решены. У ПП проблемы на очень сложной местности, в этих случаях себя лучше показывают методы поиска пути. Сила ПП в обработки больших динамичных миров с большими открытыми пространствами и наименее сложной местностью. Это случай для многих RTS-игр сегодняшних дней.
Решений на базе ПП требуют много ресурсов. Мы в своей работе показали, что решения на базе ПП могут быть реализованы с такой же или даже лучшей эффективностью как и методы поиска пути. Эффективность может быть проблемой, но в этих случаях чаще подходят случаи поиска пути.
Основанные на ПП решения сложны для реализации и настройки. ПП могут быть реализованы с очень простой архитектурой. Настройка может быть сложной и времязатратной, но относительная важность между полями была бы тут кстати (например что важнее уничтожить базу или юнитов?). Графическое представление ПП тоже очень ценно.
Ссылки
Using Multi-agent Potential Fields in Real-time Strategy Games
Johan Hagelbäck and Stefan J. Johansson
International Conference on Autonomous Agents and Multi-agent Systems (AAMAS), 2008.
1. Скачать PDF
The Rise of Potential Fields in Real Time Strategy Bots
Johan Hagelbäck and Stefan J. Johansson.
Proceedings of Artificial Intelligence and Interactive Digital Entertainment (AIIDE), 2008.
2. Скачать PDF
A Multiagent Potential Field-Based Bot for Real-Time Strategy Games
Johan Hagelbäck and Stefan J. Johansson
International Journal of Computer Games Technology, 2009.
3. Скачать PDF
Learning Human-like Movement Behavior for Computer Games
C. Thurau, C. Bauckhage, and G. Sagerer
International Conference on the Simulation of Adaptive Behavior (SAB), 2004.
4. Скачать PDF
