[Перевод] Интерфейсы — важнейшая концепция в разработке ПО

Интерфейс можно считать своеобразным договором между системой и внешним окружением. В рамках компьютерной программы «система» — рассматриваемая функция или модуль, а «окружение» — весь остальной проект. Интерфейс формально описывает, какие данные могут передаваться между системой и окружением. А «реализацию» можно охарактеризовать как «система минус интерфейс». В языках наподобие Haskell интерфейсы могут быть крайне специфическими. А в языках вроде Python они, напротив, очень обыденны. Выбранный тип интерфейса может повлиять на размер созданного технического долга и производительность программиста. О том, как это посчитать, написано ниже. Также будет предложен метод для оценки и сравнения разных интерфейсов. На основании этих сравнений вы сможете сами понаблюдать за способами использования языка или программного инструмента.
Важнейшая концепция в разработке ПО — концепция интерфейса. Эта статья не об интерфейсах на Java, а об интерфейсах в программном дизайне. И в меньшей степени — об интерфейсах в окружающем мире. Конечно, в разработке ПО используется немало других важных концепций, но я считаю, что большинство из них так или иначе зависят от важности интерфейса.
Большинству из нас знакомы две краткие формулировки:
Интерфейс — это договор между системой и внешним окружением.
Интерфейс — это сопряжение системы с внешним окружением.
Интерфейс = Система ∩ Окружение
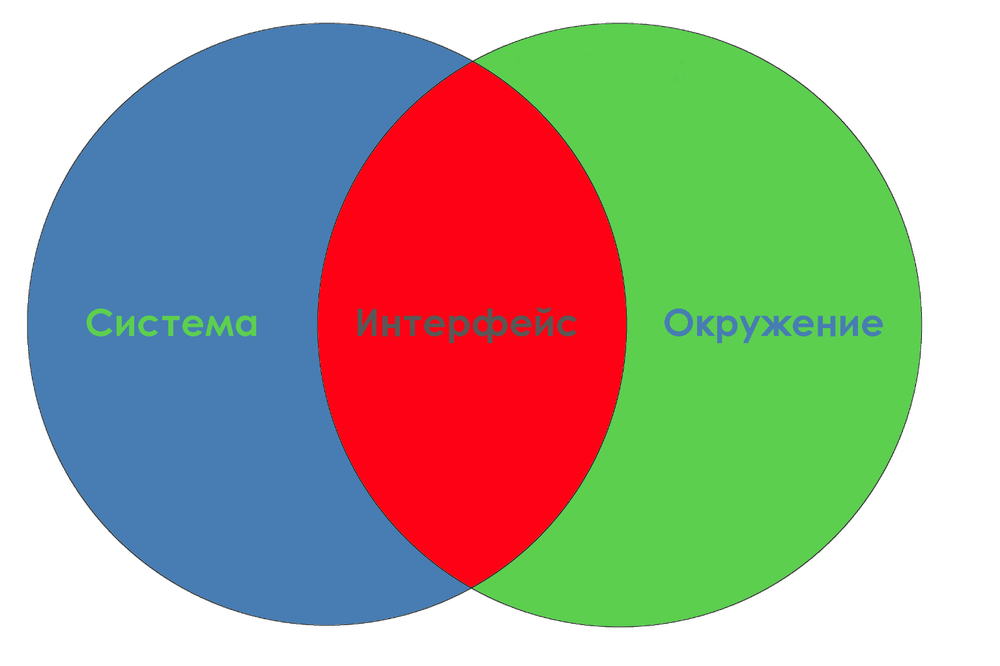
Определение с сопряжением подходит лучше, если система — это физический объект. Оба определения очень абстрактны, поэтому давайте рассмотрим их на примере печатания на клавиатуре:

Здесь система — ноутбук, окружение — руки (а также лапы кота, забравшегося на клавиатуру). Следовательно, интерфейс должен быть любой частью взаимодействия между руками и ноутбуком, которую нельзя отнести лишь к какой-то одной из сторон, а только к обеим. Обычно мы думаем о руках и о клавиатуре обособленно, так что точные границы интерфейса в данном случае — предмет философского спора. Вам решать: будет ли это клавиатура в целом или отдельные атомы, взаимодействующие друг с другом при контакте пальцев и клавиш.
Наверное, вас удивит, как этот пример соотносится с определением интерфейса как договора. В данном случае под договором подразумевается соглашение, что мы в своё время потратили достаточно усилий, когда запоминали расположение клавиш и нарабатывали мышечную память. С договором связан ещё ряд нюансов. Например, нажатие и удерживание клавиши имеет другое значение по сравнению с простым однократным нажатием.
Всё это любопытные философские рассуждения, но как они относятся к написанию ПО? Ну, начнём с того, что интерфейсы в программировании окружают вас со всех сторон, даже если вы не обращаете на это внимания. Например, если вы программируете на Java, то явным образом именуете интерфейсы в зависимости от их назначения. И в других языках они тоже присутствуют. Давайте рассмотрим пример интерфейса функции add_numbers:
unsigned int add_numbers(unsigned int, unsigned int);
void other_function(void){
add_numbers(3,4);
}
unsigned int add_numbers(unsigned int a, unsigned int b){
return a + b;
}
int main(void){
add_numbers(9,99);
return 0;
}
Применим ту же методику цветовой дифференциации штанов для описания окружения, системы add_numbers и интерфейса:

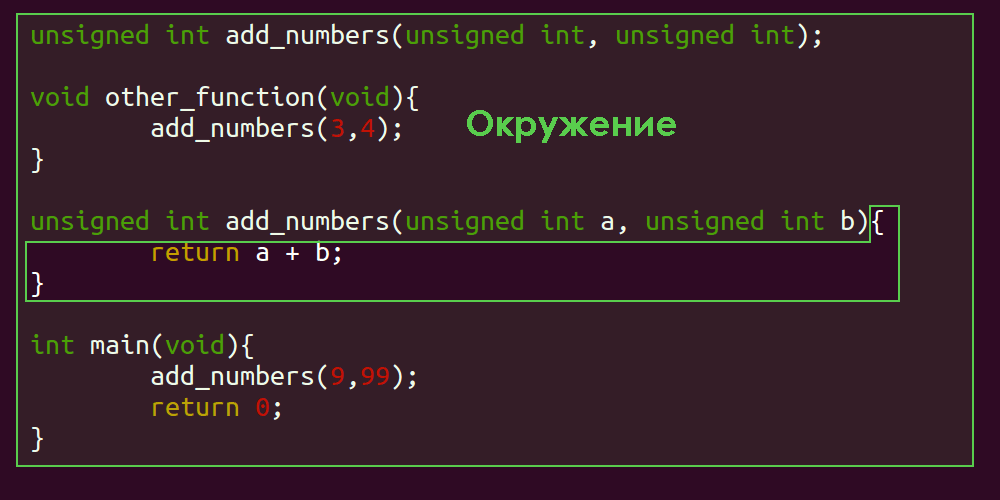
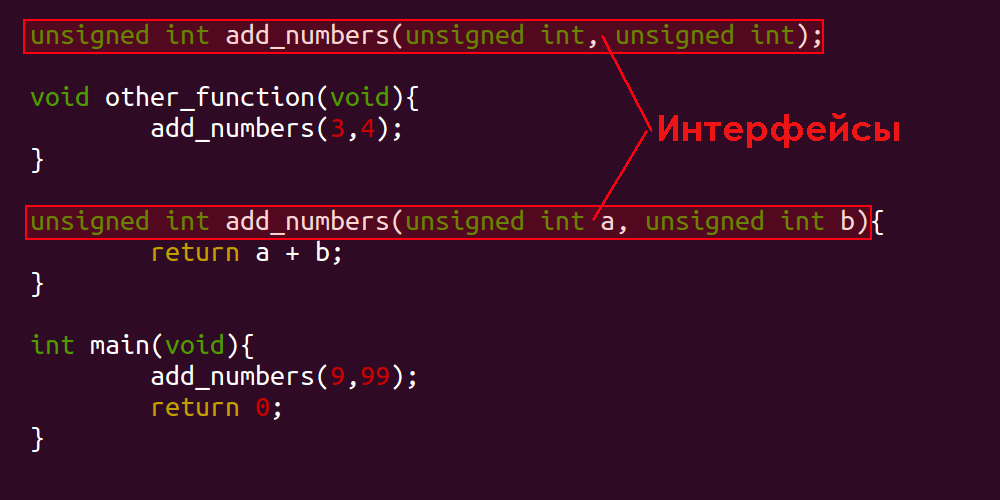
Рассматриваемая здесь «система» состоит из функции add_numbers. Если вы скажете, что можно рассматривать как отдельную систему основной метод — other_function, — то будете правы. Но для простоты мы считаем функцию add_numbers изолированной системой. Также целесообразно считать частью интерфейса обращения к add_numbers.
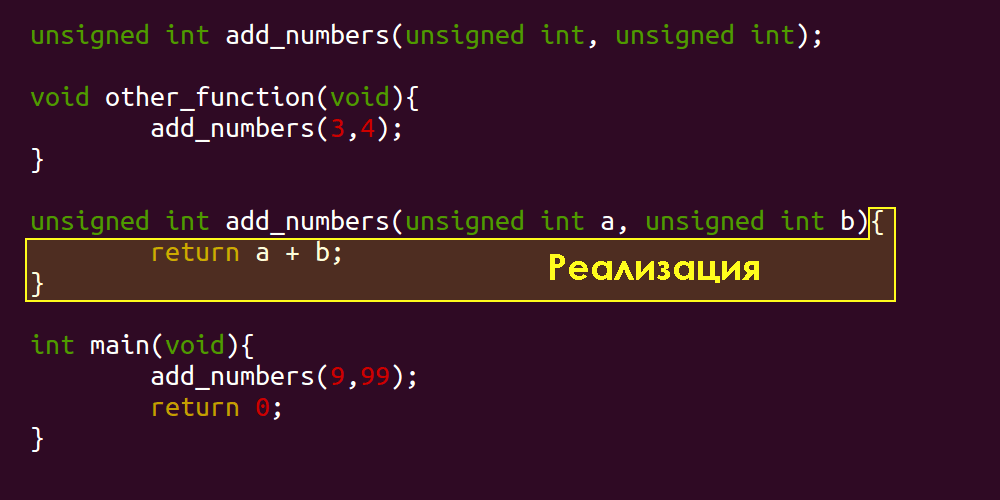
Как видите, здесь добавлена четвёртая концепция: «реализация». Довольно сложно дискутировать на тему интерфейсов без учёта конкретных реализаций. Давайте определим этот термин:
Реализация — это система минус интерфейс.
Implementation = System ∖ InterfaceImplementation = System ∖ (System ∩ Environment)
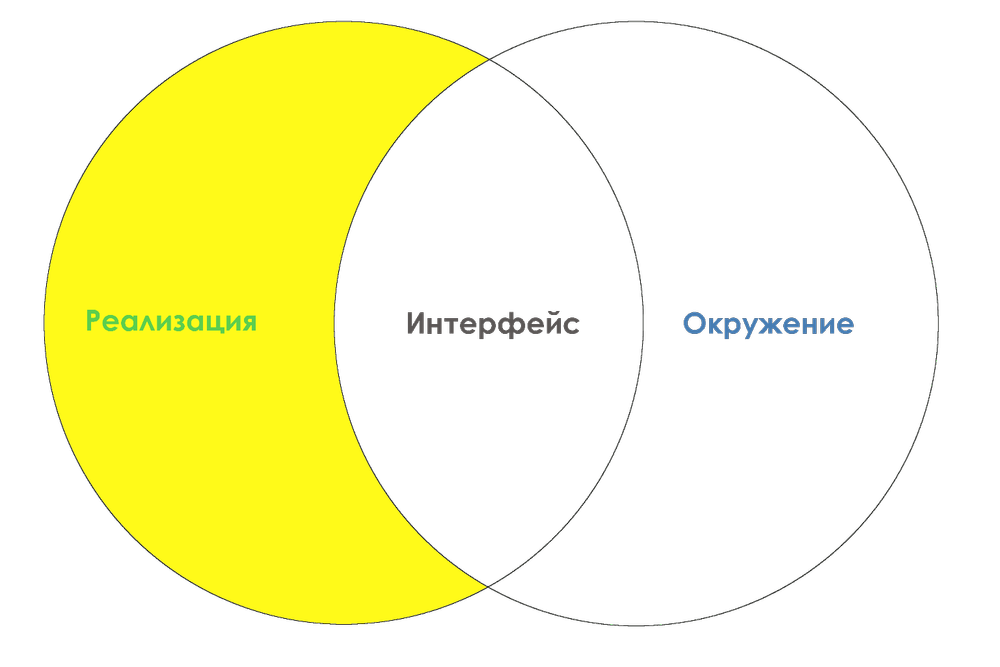
Должен признаться, что мне никогда раньше не попадалось такое определение реализации. Но это неизбежное расширение набора определений интерфейса, имеющее ряд преимуществ. Если вы бедный студент и готовитесь к экзамену, то наверняка ваш преподаватель никогда не слышал о таком определении. Не удивлюсь, если оно будет противоречить какой-нибудь таксономии объектно ориентированного программирования. Но даже в этом случае я не собираюсь его менять. Пускай лучше фанаты ООП переписывают свои конспекты в соответствии с моим определением.
Оно, в свою очередь, приводит нас к следующему логическому заключению: когда мы говорим об интерфейсах физической системы, то обычно представляем себе «реализацию» этой системы в виде единого физического объекта. Ведь было бы странно рассматривать «настоящую» реализацию без учёта кнопок, дисплеев или других компонентов. И это подталкивает нас к тому, чтобы рассматривать интерфейс больше как «соглашение», а не совокупность физических объектов. То есть в виде набора обещаний, гарантий или чего-то вроде… договора между системой и окружением.
Если рассматривать интерфейс функции add_numbers в виде договора, то гарантии будут такие:
- Функция
add_numbersсуществует. add_numbersимеет только два параметра, каждый из которых является unsignedint.add_numbersвозвращает лишь один unsignedint.
Интерфейс этой функции ничего не говорит нам:
- о прерывании выполнения
add_numbers; - об асимптотической сложности рантайма
add_numbers; - о количестве свободной памяти, необходимой для запуска
add_numbers; - о конкретной реализации unsigned
int; - о побочных эффектах (выделение памяти, модифицирование глобальных переменных).
Описанный выше интерфейс add_numbers известен под видом функции prototype. В предыдущих версиях K&R C использовалась более слабая форма описания интерфейсов:
unsigned int add_numbers();
Определение интерфейса как договора очень удобно для программирования. Ведь большинство программистских задач заключаются в определении и запрашивании наборов аксиом. Начальные и конечные условия обеспечивают какие-то свойства или поведение. Прежде чем две стороны завязывают друг с другом деловые отношения, они подготавливают договор. В нём сформулирован конечный результат, сумма и сроки оплаты. Также заранее оговариваются условия досрочного расторжения, возмещений и издержек. Если договор нарушается, то ситуацию разруливает суд или арбитраж. Но если вы забыли что-то указать в договоре, то могут возникнуть сюрпризы.
С компьютерными программами всё то же самое. Модули и функции говорят, что им нужно и (иногда) что они дадут взамен. Нарушение этого договора приведёт к ошибке компиляции, к ошибке выполнения, к сбою приложения, системы, средств контроля качества кода и к выговору от руководства. Я бы даже сказал, что определение интерфейса как договора не метафорическое. Здесь используются те же принципы, что и в коммерческом договоре, хотя он и не столь детализирован.
Я не буду давать вам советы в области права. Возможно, что-то из мною сказанного даже будет противоречить законам. Всё нижеследующее — лишь частное мнение автора.
Итак, я склонен буквально рассматривать интерфейс как «коммерческий договор» между двумя сущностями. Подчёркиваю — я не считаю это метафорой. Особенно я адресую эту интерпретацию специалистам по теории вычислительных машин и защитникам авторских прав.
Следует ли патентовать интерфейс? Учитывая его определение как договора между системой и окружением, я считаю, что использование патентов было бы ошибкой. И, судя по всему, существующее прецедентное право поддерживает мою позицию. Но имейте в виду, что слово «интерфейс» используется очень широко, и зачастую совсем не в том смысле, как я описал выше.
Следует ли защищать интерфейс авторскими правами? Опять же, учитывая «договорную» природу, я считаю, что объектом авторского права должен быть «исходный код» интерфейса. В то же время авторские права не должны применяться к тем аспектам интерфейсов, которые делают их такими особенными. Достаточно лишь защитить исходный код или рукописное изображение, но не гарантии или ограничения. Если гарантии или ограничения интерфейса станут неотделимы от любой из частей его кода, то эти части следует лишить права защиты.
Предлагаю простой тест, позволяющий оценить, нужно ли что-то защищать авторскими правами.
Если вы хотели бы защитить какой-то набор атрибутов, включая любые компоненты от третьей стороны, каким-либо образом используемые интерфейсом, то всегда можно будет создать подходящую замену. Замена реализует тот же самый интерфейс и успешно используется в ПО от третьей стороны, без каких-либо модификаций этого самого ПО, а также без нарушения любых авторских прав. Если любая замена будет приводить к нарушению авторских прав, или подразумевать модифицирование ПО от третьей стороны, или ухудшать функциональность, то набор атрибутов слишком агрессивен и должен быть сокращён.
Считаю, что с помощью этого теста целесообразно проверять ещё и на патентоспособность. Обратите внимание: цель теста — исключительно определить нецелесообразность защиты авторскими правами или патентом. Он не поможет в решении о том, что следует подвергнуть защите. Кроме того, этот тест — лишь моё мнение, а не нормативный акт или закон.
Также хочу отметить, что любой критерий, рассматриваемый как часть интерфейса в одном языке, может не являться таковым в другом языке. К примеру, в Java порядок объявления функций не влияет на выполнение программы. И если вы случайно скажете, что порядок следования функций в файле не имеет значения, то это будет ошибкой по отношению к программе на Python:
def foo():
print("asdf")
def foo(abc):
print(abc)
foo("lol")
Все эти разговоры о законах напомнили мне дело Oracle против Google. По приведённой ссылке вы можете найти интересные для разработчиков подробности, так что я буду опираться на них в своём анализе. Учитывая все аспекты, не вижу причин не соглашаться с решением дела в пользу Oracle. Не могу сказать, что безоговорочно их поддерживаю, поскольку нам доступно не так много деталей разбирательства.
Думаю, многие переживали, что будет создан прецедент, позволяющий защищать патентом или авторскими правами элементы интерфейса. Как раз тот случай, при котором не был бы пройден мой тест. Окружной суд принял решение: «Структура, последовательность и архитектура API могут быть защищены авторским правом». Не думаю, что это проблема, поскольку «структура, последовательность и архитектура» по своему определению вполне пройдут мой тест. Приведу пару выдержек из статьи по приведённой выше ссылке:
«Окружной суд заключил, что «есть лишь один способ написания» объявлений для взаимодействия с Java. Если это так, то использование одинаковых объявлений не подлежит защите авторским правом. В Google не оспаривают тот факт, что они могли бы написать свои собственные API для доступа к Java, за исключением трёх». И наконец, «В Google признали, что они дословно скопировали объявления».
Думаю, суд принял верное решение, заключив, что уникальные по сути свойства интерфейса не должны подвергаться защите. К тому же в Google признали «дословное» копирование. Если под этим подразумевается копипастинг, включая все пробелы и орфографические ошибки в комментариях, то я считаю это нарушением прав. Даже если нельзя защищать интерфейс, то это не должно мешать защите индивидуального творческого самовыражения.
Об этой тяжбе я знаю лишь из открытых сетевых источников, но, судя по всему, в Google полностью скопировали исходный Java-код, включая интерфейсы. Похоже, они и сами считали, что нужно лицензировать своё использование Java, поскольку это было предметом переговоров по лицензионным соглашениям с Sun ещё до 2010 года. Но эти соглашения потерпели неудачу после того, как Sun была приобретена Oracle. Тем не менее Google продолжала использовать «дословные» копии кода, что явно не пошло ей на пользу при судебном разбирательстве. Подозреваю, что их адвокаты знали о слабости своей позиции, поэтому выбрали стратегию защиты, основанную на законном требовании о нераспространении авторского права на интерфейсы. Надеялись выиграть дело за счёт представления интерфейса в виде исходного кода и его объединения с более философской концепцией.
При слове «модуль» у меня в голове возникает заглавная картина поста. Эта иллюстрация хорошо демонстрирует важность границ модуля и его взаимодействия с окружением. Интерфейс кубика жёстко ограничивает взаимодействие внешней среды с содержимым кубика. Вы не сможете обойти интерфейс, так что придётся соблюдать навязанные им «правила игры». Наконец, внутри кубика ничего нет, но это неважно: важно не его содержимое, а интерфейс.
Другой пример: строение клеточной мембраны. Различные компоненты обеспечивают прохождение через мембрану только необходимых веществ и только тогда, когда это нужно.
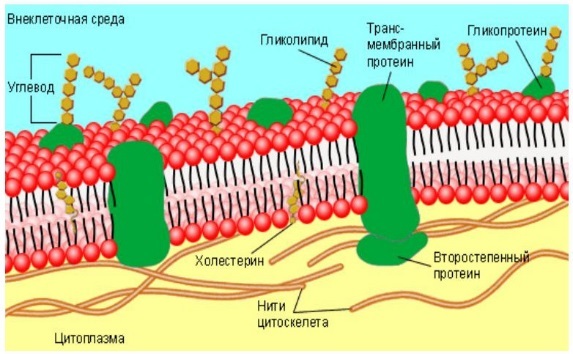
В контексте этой статьи я буду использовать термины «модули» и «абстракции» как синонимы. Конечно, толковый словарь со мной не согласится, и даже в разных языках программирования эти термины имеют разное значение. Но в данном случае меня интересует только то, что обе эти сущности можно рассматривать в качестве системы, как она понимается в этой статье. То есть абстракции и модули могут состоять из интерфейса и реализации.
Вы можете считать отдельную функцию модулем в языке С, «модулем» — в Python, классом или пакетом — в Java. Чем угодно, лишь бы оно имело внешний интерфейс и «скрытую» реализацию. Причём «скрытость» может быть следствием правил языка или даже решения программиста.
Насколько я знаю, идею дырявых абстракций выдвинул Джоел Сполски. В его эссе есть несколько хороших примеров, но я хотел бы привести свой. В программировании очень часто встречается концепция «карты»: представление структуры данных, состоящей из пар ключей и значений. Важное ограничение: карта гарантирует, что все ключи должны быть уникальными. Попытка записи нового значения для существующего ключа приведёт к ошибке или перезаписи предыдущего значения. Суть в том, что ключи не должны дублироваться. Чаще всего от программистов требуется желание перебирать все эти ключи. А поскольку карты не могут гарантировать определённый порядок сортировки ключей, то иногда приходится задаваться вопросом, в каком порядке они будут после перебора? Это — следствие того, что интерфейс карты не даёт гарантий по сортировке. И хотя считается, что это не имеет значения, но на практике всё же хочется отсортировать. Так нужно для более эффективной организации данных, например для облегчения проверки уже имеющихся ключей.
Перебор отсортированных данных может дать совсем другой результат по сравнению с перебором случайных данных. Допустим, нужно найти минимальное значение в списке:
min = null;
list = map.getMapKeys();
for (item in list){
if ( min == null ){
min = item
}else if (item < min){
min = min; /* This line has a bug */
}
}
Ветка else if никогда не будет выполнена, если данные отсортированы по возрастанию. Даже если вы начнёте проверку со случайного места списка, программа никогда не столкнётся с этой строкой. И это огромная проблема, поскольку если вы поменяете реализацию карты и она не будет возвращать отсортированные ключи, то ваш код неожиданно станет выполняться по ветке с багом. А к тому моменту вы совершенно забудете об этом коде и скрытой внутри него бомбе.
Хочу предложить своё собственное определение утечки абстракций.
Утечкой абстракций (abstraction leak) называется ситуация, когда реализация может влиять на окружение так, как не было предусмотрено интерфейсом.
Согласно этому определению, почти каждая абстракция — дырявая. Ведь описание в интерфейсе всех видов воздействия на окружение имеет смысл лишь в наиболее строгих математических системах. А что касается физических систем, то вам может вспомниться теорема Гёделя о неполноте.
Идея дырявости большинства абстракций не является необоснованной. Это подразумевал и Джоел Сполски в своём «The Law of Leaky Abstractions»:
«Все нетривиальные абстракции являются дырявыми до определённой степени».
Раз все абстракции дырявые, то о чём говорить? Проблемы возникают только тогда, когда часть окружения начинает опираться на один из непредусмотренных способов воздействия системы на окружение. Именно о таких утечках все и говорят.
Это приводит к далеко идущим последствиям, не только с точки зрения обычных багов, но и в сфере безопасности. С физическими системами, в которых присутствуют утечки во внешнее окружение, компрометирующие безопасность, связан термин «атака по сторонним каналам». В сочетании с заявлением, что все абстракции дырявы, это приводит нас к заключению:
Каждая физическая реализация криптосистемы уязвима к атакам по сторонним каналам.
Учитывая всё сказанное выше, эту идею можно распространить не только на физические, но и на эмулированные реализации.
Как мы уже видели выше, в интерфейсах на С задаются такие вещи, как тип возвращаемого значения и количество параметров, которые могут быть переданы функции. А что насчёт Python? Я использую термин «интерфейс» в соответствии с контекстом статьи, то есть в более широком понимании по сравнению с тем, что пишут в книгах об «интерфейсах» в Python.
def add_numbers(a,b):
return a + b
print(add_numbers(3,1))
print(add_numbers("abc","def"))
В этом языке нам требуется формализовать типы интерфейса функции. Это упрощает определение и вызов функции, поскольку нужно обработать меньше информации. С другой стороны — ограничений, по которым можно со временем проводить проверку для поиска ошибок, меньше.
Думаю, нужно кое-что сказать об оценке и сравнении разных характеристик интерфейса с точки зрения способов передачи информации. Оценивать можно как конкретный интерфейс, так и совокупность всех интерфейсов, которые могут быть реализованы на данном языке. Давайте вспомним наш пример с add_numbers и оценим, сколько информации мы можем передать через интерфейс и в обход него, с помощью утечек абстракции.
| Через интерфейс | В обход интерфейса | ||
| Описание характеристики | Кол-во возможных состояний | Описание характеристики | Кол-во возможных состояний |
| Тип параметра 1 | 1 (unsigned int) | Состояния глобальной переменной | (кол-во глобальных переменных) * (кол-во состояний глобальных переменных) |
| Тип параметра 2 | 1 (unsigned int) | Файловая система | Кол-во состояний файловой системы |
| Тип возвращаемого значения | 1 (unsigned int) | Время использования процессора | Не ограничено |
| Значение параметра 1 | 2^(кол-во бит в unsigned int) | Состояние кучи | Кол-во состояний кучи |
| Значение параметра 2 | 2^(кол-во бит в unsigned int) | Многие другие… | … |
| Возвращаемое значение | 2^(кол-во бит в unsigned int) |
И есть ряд вещей, которые могут коммуницировать с add_numbers через интерфейс Python.
| Передача информации через интерфейс Python | Передача информации в обход интерфейса Python | ||
| Описание характеристики | Кол-во возможных состояний | Описание характеристики | Кол-во возможных состояний |
| Тип параметра 1 | Практически бесконечное | Состояния глобальной переменной | Кол-во состояний файловой системы |
| Тип параметра 2 | Практически бесконечное | Файловая система | Не ограничено |
| Тип возвращаемого значения | Практически бесконечное | Время использования процессора | Кол-во состояний кучи |
| Значение параметра 1 | Практически бесконечное | Состояние кучи | … |
| Значение параметра 2 | Практически бесконечное | Многие другие… | (кол-во глобальных переменных) * (кол-во состояний глобальных переменных) |
| Возвращаемое значение | Практически бесконечное |
А теперь взгляните на количество типов интерфейсов, которые мы можем описать в Haskell:
add_numbers :: Int > Int -> Int
add_numbers 3 4 = 7
main = print (add_numbers 3 4)
Учитывая этот код, интерфейс add_numbers может получить следующую информацию:
| Передача информации через интерфейс Haskell | Передача информации в обход интерфейса Haskell | ||
| Описание характеристики | Кол-во возможных состояний | Описание характеристики | Кол-во возможных состояний |
| Тип параметра 1 | 1 (Int) | Время использования процессора | Не ограничено |
| Тип параметра 2 | 1 (Int) | Влияние на кэши процессора/памяти | Не ограничено |
| Тип возвращаемого значения | 1 (Int) | Прочие… | … |
| Значение параметра 1 | 1 (значение 3) | ||
| Значение параметра 2 | 1 (значение 4) | ||
| Возвращаемое значение | Как минимум 2^30[1] |
Для конкретного интерфейса на выбранном вами языке можно оценить ещё и количество уникальных способов передачи информации:
- через интерфейс;
- в обход интерфейса через утечки абстракций.
Можете также обратить внимание на следующее:
- сколько ограничений вы можете использовать в рамках этого языка с точки зрения минимального и максимального количества информации, передаваемой через интерфейс;
- какие инструменты предоставляет этот язык для предотвращения взаимодействия в обход интерфейса.
Проанализируем подобным образом графический пользовательский интерфейс, в котором есть возможность менять папки:

| Передача информации через GUI | Передача информации в обход GUI | ||
| Описание характеристики | Кол-во возможных состояний | Описание характеристики | Кол-во возможных состояний |
| Клик по Папке 1 | Кол-во пикселей на экране, занимаемых Папкой 1 * кол-во кликов | Скрытые возможности UI | Не ограничено |
| Клик по Папке 2 | Кол-во пикселей на экране, занимаемых Папкой 2 * кол-во кликов | Нестандартные комбинации быстрого вызова | Кол-во пикселей на экране, занимаемых Кнопкой 2 |
| Наведение курсора на Папку 1 | Кол-во пикселей на экране, занимаемых Папкой 1 | Прочие неожиданные возможности UI | … |
| Наведение курсора на Папку 2 | Кол-во пикселей на экране, занимаемых Папкой 2 | ||
| Время между наведением и кликом | Бесконечно | ||
| Стандартные клавиатурные события | Кол-во стандартных комбинаций клавиш | ||
| Площадь экрана, занимаемая GUI | Кол-во пикселей, используемых для отображения GUI |
А теперь рассмотрим ту же задачу смены папки с помощью командной строки и cd:
| Передача информации через GUI | Передача информации в обход GUI | ||
| Описание характеристики | Кол-во возможных состояний | Описание характеристики | Кол-во возможных состояний |
| Кол-во названий папок, которые можно набрать | Не ограничено | Переменные окружения | Не ограничено |
В предыдущие две таблицы я не включил такие данные, как количество шума в сигнале. Если сравнить сложность повторения одной и той же последовательности при нажатии клавиш (одна за другой) и движении мыши (пиксель за пикселем), то очевидно, что во втором случае ошибок гораздо больше. В графических интерфейсах это компенсируется благодаря принятию менее строгой семантики. Представьте, если бы на кнопках «OK» и «Cancel» доступная для кликов зона была шириной всего 1 пиксель.
Можно ещё больше усложнить анализ, если оценивать изменение доли ошибок у пользователей с физическими отклонениями.
Итак, мы рассмотрели один из возможных способов оценки и сравнения интерфейсов. На основании приведённых примеров и собственного опыта позволю себе сделать несколько экстраполяций:
- Люди предпочитают интерфейсы, которые не слишком строги при приёме информации, особенно если интерфейс незнакомый.
- Не слишком строгие интерфейсы чаще используют неправильно.
- Всеобъемлющие интерфейсы, принимающие большие объёмы информации, выглядят мощными, но часто используются неправильно.
- Если взаимодействие становится утомительным, люди стараются передавать информацию в обход интерфейса.
- При взаимодействии в обход интерфейса, через утечки абстракций, крайне вероятно возникновение неприятных неожиданностей.
Я опишу несколько наблюдений на основании анализа из предыдущего раздела. Но сначала приведу пару определений:
Дырявый интерфейс (leaky interface) — интерфейс, который игнорируется в ходе любых взаимодействий между системой и окружением.
Ограниченный интерфейс (specific interface) — интерфейс с относительно небольшим количеством возможных входов и выходов.
Хороший пример ограниченного интерфейса — кусочно-заданные функции, определённые только для небольшого количества входных данных.
Если вы можете обоснованно оценить «дырявость» или «ограниченность» интерфейсов, то имеет смысл очертить диапазон, на одном конце которого будут очень ограниченные и недырявые интерфейсы, а на другом — неограниченные и дырявые.
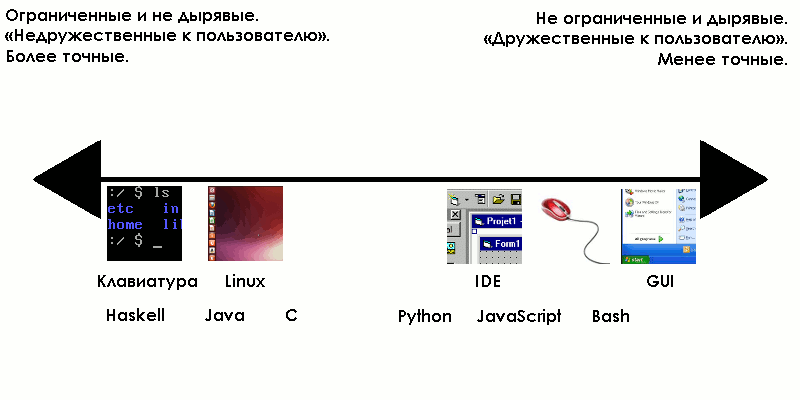
Вероятно, вы предложите кого-то подвинуть влево или вправо на шкале, но главное, что вы ухватили идею. Можно даже разбить на две отдельные шкалы: по степени дырявости и строгости. Хотя в целом эти два понятия хорошо коррелируют.
Следующая корреляция, которую я хочу предложить, выведена из моего опыта. На левом краю шкалы «ошибки» бывают реже, и обычно они возникают из-за сбоев при валидации. На правом краю шкалы ошибки возникают чаще, и зачастую их причина кроется в сбоях при верификации.
Начну с заявления:
Основная часть технического долга возникает в проекте либо из-за недопустимого полагания на утечки абстракций, либо из-за полагания на договоры крайне нестрогих интерфейсов, что сильно затрудняет прогнозирование последствий.
В самом начале проект содержит один-два модуля, и для проработки договора хорошего интерфейса вам понадобится выполнить объём работы О (1). Если ваш интерфейс плох, то объём технического долга тоже будет равен О (1), так что вам не придётся потратить слишком много времени на приведение в порядок договора интерфейса. Но при линейном росте количества модулей объём межмодульных связей может достигать О (N^2). Следовательно, при плохом интерфейсе, если каждый модуль взаимодействует со всеми остальными модулями, количество обращений к интерфейсу в худшем случае будет пропорционально N^2.
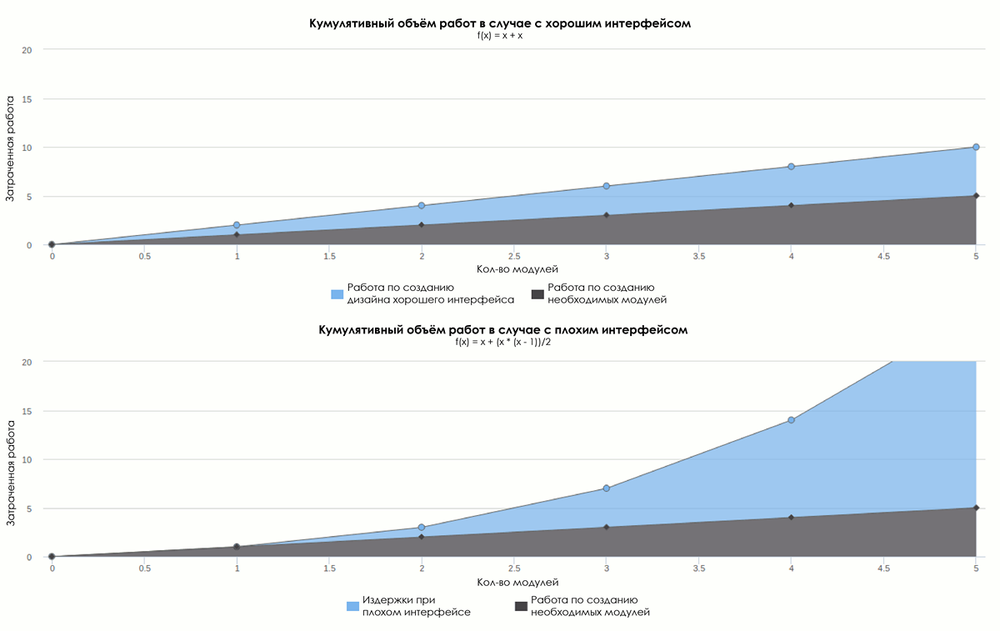
Как видно из графиков, изначально можно сэкономить на создании продуманного интерфейса. Но этот выигрыш быстро теряется из-за нарастания проблем, связанных с межмодульным взаимодействием. Объём работ из-за этого увеличивается в степени количества модулей, в то время как при хорошем интерфейсе он растёт линейно. Худший сценарий — когда каждый модуль общается с каждым модулем, возникает всё больше проблем в процессе хендшейка, отсюда и проистекает степенной рост.
Обычно уровень межмодульного взаимодействия растёт медленнее, чем О (N^2), но определённо быстрее, чем О (N). Также есть один фактор, сдвигающий начало быстрого роста в будущее: это человеческая память. Даже когда в вашем проекте 20 модулей, вы, вероятно, ещё помните, что делает каждый из них. Так, из всех договоров вам нужны лишь туманные названия функций и эзотерические соглашения. Но как только проект становится достаточно большим, то многие детали забываются, или когда в проект приходят новые люди — и начинается степенной рост трудовых затрат.
На этот вопрос вы получите от людей разные ответы, ни один из которых мне не кажется самым важным:
- Командная строка гибкая и даёт много возможностей.
- Она потребляет меньше ресурсов.
- Это позволяет лучше понимать, как всё работает.
Самое главное, почему мы всё ещё пользуемся командной строкой, это АВТОМАТИЗАЦИЯ! Вряд ли можно переоценить выгоды использования автоматизированных процессов. Если мне нужно запустить кластер на 100 серверов, то не стану же я подключаться к каждому из них по отдельности и вручную устанавливать ПО, кликая по куче кнопок в бесчисленных GUI. Даже если вам нужно автоматизировать процесс кликанья в GUI, то понадобится ещё какой-то файл, в котором будет сохраняться информация о том, куда и как нужно кликнуть. Нечто вроде файла с гибкими… командами.
Хотя мы и могли бы внедрять автоматизацию через кликанье и экранные грабберы, нельзя забывать о том, что такой тип взаимодействия с машиной придуман для людей. Он подразумевает использование нестрогого интерфейса, не требующего высокой точности. Поэтому ваш автоматизированный кликер наверняка будет сбоить, если окно вдруг сдвинется со своей позиции или поменяется системный шрифт. С GUI связано слишком много переменных. А командная строка позволяет действовать гораздо точнее, вы взаимодействуете через очень строгий интерфейс. Поэтому многие люди его не любят, в отличие от компьютерных программ.
Конечно, бывают ситуации, когда невысокая точность взаимодействия GUI — это благо. Например, при создании цифровых картин вам не нужно волноваться о размещении и цвете каждого пикселя. Главное, чтобы было нечто особенное для каждого пикселя. Поэтому шум, передаваемый рукой движению курсора, становится важной информацией в конечном продукте.
После раздела про асимптотическую сложность технического долга вы могли подумать, что любой проект нужно писать на языке с очень строгими условиями договоров интерфейса, вроде Haskell или Java. Но это не совсем то, что я хотел донести. Ответ на следующий вопрос может помочь вам сделать правильный выбор.
Насколько вероятно изменение требований к вашему проекту?
При начале нового дела ответ наверняка будет «очень вероятно», особенно если создается небольшой продукт, да ещё и при неясности его перспектив на рынке. Если же требования чётко сформулированы, как, например, в случае с созданием компилятора или разработкой проекта на базе международных стандартов, то ответ наверняка будет «не слишком вероятно».
Если вы ответили «очень вероятно», то используйте язык, который позволит терять меньше времени при уточнении договоров интерфейса: они наверняка будут работать против вас в случае изменения требований. Но главная задача здесь — получить не идеальную реализацию требований, а идеальные требования, позволяющие вам начать создавать финальную реализацию. Исключением может быть ситуация, когда ваш MVP представляет собой огромную систему с сотнями модулей. Если в проект вовлечено немало народу, то хороший интерфейс просто необходим для того, чтобы они не наступали друг другу на ноги.
Если вы ответили «не слишком вероятно», то используйте язык с очень строгими договорами интерфейса. Вначале придётся больше поработать, но зато потом внедрение новых возможностей потребует меньше усилий. Единственным исключением может быть ситуация, если вы пишете какой-то мелкий продукт (на несколько сотен строк).
Когда-то было сломано немало копий относительно того, что Twitter начали создавать на Ruby on Rails, а потом это стало причиной затруднений при масштабировании проекта. Позднее Twitter был переведён на Scala. Кто-то может считать, что разработчики совершили ошибку и им следовало сразу выбрать Scala. Я так не думаю. В основе Twitter«а лежит очень простая идея, и в условиях большого количества конкурентов им нужно было завоевать доминирующую позицию на рынке. Им требовалось расти как можно быстрее, невзирая на расходы. Циклы разработки новых возможностей должны были проходить максимально быстро, поскольку это позволяет в кратчайшие сроки понять, что именно нужно пользователям, какой продукт они хотят в результате получить. Трудности масштабирования — это признак не неудачи, а успеха. Было сформулировано видение Twitter«а как готового продукта, и оставалось только реализовать его. С точки зрения разработчиков, это просто нирвана, все о таком мечтают, но мало кому удаётся поработать в таких условиях: «Перепиши это дерьмо с нуля на своём любимом языке, как тебе удобно, лишь бы в будущем с ним было легче работать». Гораздо проще переписывать что-то с нуля, имея перед глазами более слабую реализацию, чем пытаться нащупать облик продукта, который позволит компании взлететь. К сожалению, большинство участников рынка идут только путем избегания «ненужных» расходов на создание с нуля и тратят массу сил и времени на масштабирование того, что изначально не предполагало масштабиро
