[Перевод] Инструкция по работе с TensorFlow Object Detection API

Перевод TensorFlow Object Detection API tutorial — Training and Evaluating Custom Object Detector.
Мы все умеем водить машину, ведь это довольно легко, правда? Но что вы будете делать, если кто-то попросит вас сесть за штурвал самолета? Совершенно верно — вы прочитаете инструкцию. Аналогично, руководство, которое вы найдете ниже, поможет вам настроить API и наслаждаться приятным полетом.
Прежде всего, клонируйте хранилище по ссылке. Надеюсь, TensorFlow у вас уже установлена.
git clone github.com/tensorflow/models.git
В машинном обучении мы, как правило, обучаем и проверяем модель при помощи CSV-файла. Но в данном случае мы действуем по схеме, приведенной на рисунке:

Прежде чем продолжить, остановимся на структуре каталогов, которыми мы будем пользоваться.
- data/ — Здесь будут содержаться записи и CSV-файлы.
- images/ — Здесь находится набор данных для обучения нашей модели.
- training/ — Сюда мы сохраним обученную модель.
- eval/ — Здесь будут храниться результаты оценки работы модели.
Шаг 1: сохранение изображений в CSV
Здесь всё довольно просто. Углубляться в эту задачу не будем, лишь приведу несколько полезных ссылок.
Наша задача — пометить изображение и создать файлы train.CSV и test.CSV.
- При помощи инструмента labelImg помечаем изображение. Как это сделать, смотрите здесь.
- Конвертируем XML в CSV, как показано здесь.
Cуществует множество способов создания CSV-файлов, в большей или меньшей степени подходящих для работы с каждым конкретным набором данных.
В рамках своего проекта мы постараемся добиться обнаружения легочных узлов при помощи датасета LUNA. Координаты узлов уже были известны, а потому создание CSV-файлов не составляло труда. Для обнаружения узлов мы используем 6 координат, показанных ниже:
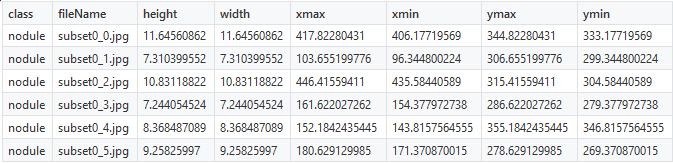
Вам следует исправить лишь название класса nodules (узлы), всё прочее останется без изменений. Как только отмеченные объекты будут представлены в виде цифр, можно переходить к созданию TFRecords.
Шаг 2: создание TFRecords
TensorFlow Object Detection API не принимает входные данные для обучения модели в формате CSV, поэтому необходимо создать TFRecords при помощи этого файла.
"""
Usage:
# From tensorflow/models/
# Create train data:
python generate_tfrecord.py --csv_input=data/train_labels.csv --output_path=train.record
# Create test data:
python generate_tfrecord.py --csv_input=data/test_labels.csv --output_path=test.record
"""
from __future__ import division
from __future__ import print_function
from __future__ import absolute_import
import os
import io
import pandas as pd
import tensorflow as tf
from PIL import Image
from object_detection.utils import dataset_util
from collections import namedtuple, OrderedDict
flags = tf.app.flags
flags.DEFINE_string('csv_input', '', 'Path to the CSV input')
flags.DEFINE_string('output_path', '', 'Path to output TFRecord')
FLAGS = flags.FLAGS
# TO-DO replace this with label map
def class_text_to_int(row_label):
if row_label == 'raccoon':
return 1
else:
None
def split(df, group):
data = namedtuple('data', ['filename', 'object'])
gb = df.groupby(group)
return [data(filename, gb.get_group(x)) for filename, x in zip(gb.groups.keys(), gb.groups)]
def create_tf_example(group, path):
with tf.gfile.GFile(os.path.join(path, '{}'.format(group.filename)), 'rb') as fid:
encoded_jpg = fid.read()
encoded_jpg_io = io.BytesIO(encoded_jpg)
image = Image.open(encoded_jpg_io)
width, height = image.size
filename = group.filename.encode('utf8')
image_format = b'jpg'
xmins = []
xmaxs = []
ymins = []
ymaxs = []
classes_text = []
classes = []
for index, row in group.object.iterrows():
xmins.append(row['xmin'] / width)
xmaxs.append(row['xmax'] / width)
ymins.append(row['ymin'] / height)
ymaxs.append(row['ymax'] / height)
classes_text.append(row['class'].encode('utf8'))
classes.append(class_text_to_int(row['class']))
tf_example = tf.train.Example(features=tf.train.Features(feature={
'image/height': dataset_util.int64_feature(height),
'image/width': dataset_util.int64_feature(width),
'image/filename': dataset_util.bytes_feature(filename),
'image/source_id': dataset_util.bytes_feature(filename),
'image/encoded': dataset_util.bytes_feature(encoded_jpg),
'image/format': dataset_util.bytes_feature(image_format),
'image/object/bbox/xmin': dataset_util.float_list_feature(xmins),
'image/object/bbox/xmax': dataset_util.float_list_feature(xmaxs),
'image/object/bbox/ymin': dataset_util.float_list_feature(ymins),
'image/object/bbox/ymax': dataset_util.float_list_feature(ymaxs),
'image/object/class/text': dataset_util.bytes_list_feature(classes_text),
'image/object/class/label': dataset_util.int64_list_feature(classes),
}))
return tf_example
def main(_):
writer = tf.python_io.TFRecordWriter(FLAGS.output_path)
path = os.path.join(os.getcwd(), 'images')
examples = pd.read_csv(FLAGS.csv_input)
grouped = split(examples, 'filename')
for group in grouped:
tf_example = create_tf_example(group, path)
writer.write(tf_example.SerializeToString())
writer.close()
output_path = os.path.join(os.getcwd(), FLAGS.output_path)
print('Successfully created the TFRecords: {}'.format(output_path))
if __name__ == '__main__':
tf.app.run()
Скачав файл, внесите одно маленькое изменение: в строке 31 вместо слова raccoon поставьте собственную отметку. В приведённом примере это nodules, узлы. Если ваша модель должна будет определять несколько видов объектов, создайте дополнительные классы.
Примечание. Нумерация меток должна начинаться с единицы, а не с нуля. Например, если вы используете три вида объектов, им должны быть присвоены значения 1, 2 и 3 соответственно.
Для создания файла train.record воспользуйтесь следующим кодом:
python generate_tfRecord.py --CSV_input=data/train.CSV --output_path=data/train.record
Для создания файла test.record воспользуйтесь следующим кодом:
python generate_tfrecord.py — CSV_input=data/test.CSV — output_path=data/test.record
Шаг 3: обучение модели
Как только нужные нам файлы созданы, мы почти готовы приступить к обучению.
- Выберите модель, которую будете обучать. Вам следует найти компромисс между скоростью работы и точностью: чем выше скорость, тем ниже точность определения, и наоборот. В качестве примера здесь используется
sd_mobilenet_v1_coco. - Решив, с какой моделью будете работать, скачайте соответствующий файл конфигурации. В данном примере это
ssd_mobilenet_v1_coco.config. - Создайте файл object-detection.pbtxt, который выглядит так:
item { id: 1 name: 'nodule' }
Присвойте классуnoduleдругое имя. Если классов несколько, увеличивайте значениеidи вводите новые имена.
Пришло время настроить файл конфигурации, внеся следующие коррективы.
Измените количество классов согласно своим требованиям.
#before
num_classes: 90
#After
num_classes: 1
Если мощность вашего GPU недостаточна, понизьте значение batch_size.
batch_size: 24
Укажите путь к модели ssd_mobilenet_v1_coco, которую мы скачали ранее.
#before
fine_tune_checkpoint: "PATH_TO_BE_CONFIGURED/model.ckpt"
#after
fine_tune_checkpoint: "ssd_mobilenet_v1_coco/model.ckpt"
Укажите путь к файлу train.record.
#before
train_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/mscoco_train.record"
}
label_map_path: "PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt"
}
#after
train_input_reader: {
tf_record_input_reader {
input_path: "data/train.record"
}
label_map_path: "data/object-detection.pbtxt"
}
Укажите путь к файлу test.record.
#before
eval_input_reader: {
tf_record_input_reader {
input_path: "PATH_TO_BE_CONFIGURED/mscoco_val.record"
}
label_map_path: "PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt" shuffle: false
num_readers: 1}
#after
eval_input_reader: {
tf_record_input_reader {
input_path: "data/test.record"
}
label_map_path: "data/object-detection.pbtxt"
shuffle: false
num_readers: 1}
Теперь скопируйте папки data/ и images/ в папки models/research/object-detection. Если поступит предложение о слиянии папок, примите его.
Кроме того, нам понадобится расположенный в директории object-detection/ файл train.py.
cd models/research/object-detection
Создайте в папке object-detection/ папку training/. Именно в training/ мы сохраним нашу модель. Скопируйте в training/ файл конфигурации ssd_mobilenet_v1_coco.config. Обучение выполняется при помощи команды:
python train.py --logtostderr \
--train_dir=training/ \
--pipeline_config_path=training/ssd_mobilenet_v1_coco.config
Если всё пойдет по плану, вы увидите, как меняется функция потерь на каждом этапе.
Шаг 4: оценка модели
Наконец, мы оцениваем модель, сохраненную в директории training/. Для этого запускаем файл eval.py и вводим следующую команду:
python eval.py \
--logtostderr \
--pipeline_config_path=training/ssd_mobilenet_v1_coco.config \
--checkpoint_dir=training/ \
--eval_dir=eval/
Результаты проверки отразятся в папке eval/. Их можно визуализировать с помощью TensorBoard.
#To visualize the eval results
tensorboard --logdir=eval/
#TO visualize the training results
tensorboard --logdir=training/
Откройте ссылку через браузер. Во вкладке Images вы увидите результаты работы модели:
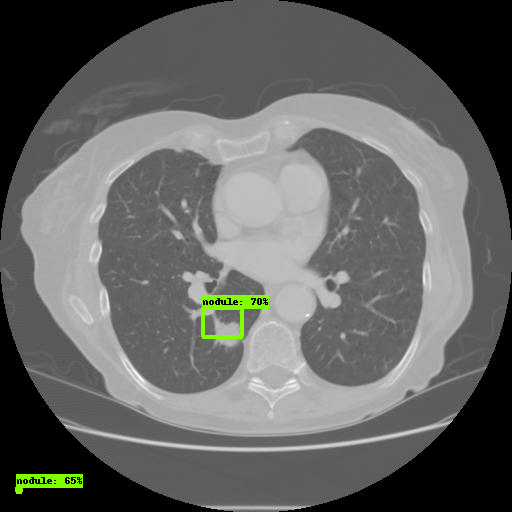
На этом всё, вы успешно настроили TensorFlow Object Detection API.
Одна из самых распространенных ошибок:
No module named deployment on object_detection/train.py
Решается при помощи команды:
# From tensorflow/models/research/
export PYTHONPATH=$PYTHONPATH:`pwd`:`pwd`/slim
О способах изменения параметров Faster-RCNN/SSD вы можете прочитать здесь.
Спасибо за внимание!
