TiKV — распределённая база данных key-value для cloud native

28 августа организация CNCF (Cloud Native Computing Foundation), стоящая за Kubernetes, Prometheus и другими Open Source-проектами для современных облачных приложений, объявила о принятии нового продукта в свою «песочницу» — TiKV.
Эта распределённая, транзакционная база данных типа ключ-значение зародилась как дополнение к TiDB — распределённой СУБД, которая предлагает возможности OLTP и OLAP и обеспечивает совместимость с протоколом MySQL… Но давайте обо всём по порядку.
TiDB как родитель
Начнём с «родительского» проекта TiDB, созданного китайской компанией PingCAP Inc.

Первый крупный публичный релиз этой СУБД — 1.0 — состоялся меньше года назад. Главные её особенности — «гибридность», совмещающая транзакционную и аналитическую обработку данных (Hybrid Transactional/Analytical Processing, HTAP), а также уже упомянутая совместимость с протоколом MySQL. Более полная картина TiDB возникает при упоминании других — уже обыденных для новых СУБД — фич, таких как горизонтальная масштабируемость, высокая доступность и строгое соответствие ACID.
Общая архитектура TiDB представляется следующим образом:
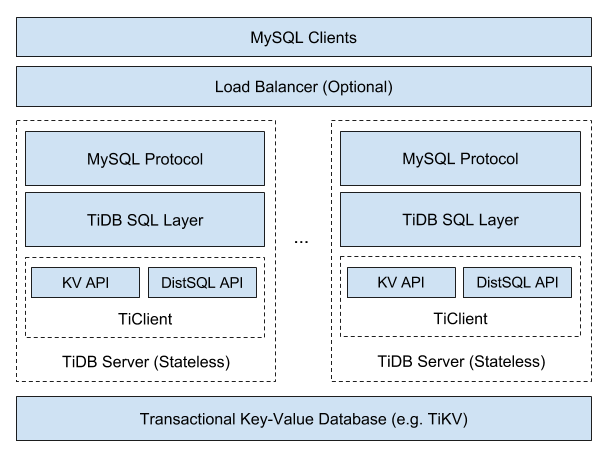
Поскольку TiDB предлагает масштабируемость NoSQL и гарантии по ACID, её относят к категории NewSQL. Авторы не скрывают, что создавали продукт под вдохновением от других представителей NewSQL: Google Spanner и F1. Однако китайские разработчики настаивали на «своих лучших практиках и решениях при выборе технологий». В частности, они выбрали алгоритм для решения задач консенсуса Raft (вместо Paxos, что используется в Spanner), хранилище RocksDB (вместо распределённой файловой системы), а в качестве языка программирования — Go (и Rust).
Многие подробности об устройстве TiDB можно найти в докладе «How we build TiDB» от соучредителя и генерального директора PingCAP — Max Liu, —, а к некоторым из них, тесно связанным с TiKV, мы ещё вернёмся. Исходный код TiDB распространяется под свободной лицензией Apache License v2. Среди её крупных пользователей упоминаются Lenovo, Meizu, Bank of Beijing, Industrial and Commercial Bank of China и др.
Что же такое TiKV и какую роль играет в мире TiDB (и не только)?
Архитектура и особенности TiKV
Вернёмся к общей архитектуре TiDB, в чуть ином её представлении:

Можно увидеть, что сама TiDB обеспечивает реализацию SQL и совместимость с MySQL*, а остальную работу поручает кластеру TiKV. Что же это за «остальная работа»? Вот более подробная схема:
INSERT INTO user VALUES (1, "bob", "huang@pingcap.com");
INSERT INTO user VALUES (2, "tom", "tom@pingcap.com");
… получаются:

Индексы в TiDB — обычные пары, значения в которых указывают на строку с данными:

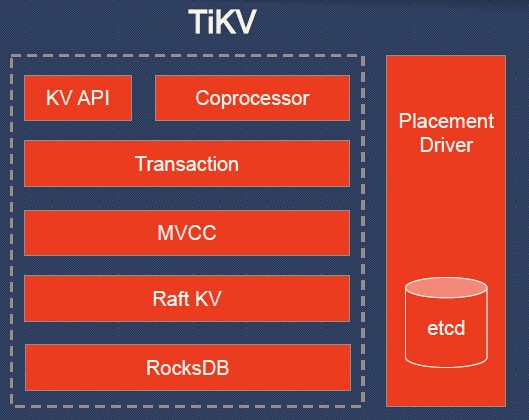
Пояснения к схеме TiKV:
- KV API — набор программных интерфейсов для записи/чтения данных;
- Coprocessor — фреймворк сопроцессора для поддержки распределённых вычислений (сравнивается с аналогичным у HBase);
- Transaction — транзакционная модель, похожая на Google Percolator (протокол коммитов в 2 фазы; использует timestamp allocator; см. также сравнение со Spanner);
- MVCC (MultiVersion Concurrency Control) для обеспечения чтения без блокировок и ACID-транзакций (данные тегируются версиями; любые изменения, сделанные в текущей транзакции, не видны другим транзакциям до момента коммита);
- Raft KV — уже упомянутый алгоритм Raft, используемый для горизонтального масштабирования и консистентности данных; его реализация на языке Rust портирована из etcd (проверена обширной эксплуатацией); к слову, авторами TiKV заявлена «простая масштабируемость до 100+ Тб данных»;
- RocksDB — локальное хранилище типа ключ-значение, тоже уже хорошо зарекомендовавшее себя в масштабных проектах в production (Facebook);
- Placement Driver — «мозг» кластера, созданный по концепту из Google Spanner и отвечающий за хранение метаданных о регионах, поддержку нужного количества реплик, равномерное распределение нагрузок (с помощью Raft).

Если обобщить взаимосвязи основных компонентов, то получится следующее:
- У каждого узла кластера TiKV есть одно или несколько хранилищ (RocksDB).
- У каждого хранилища есть множество регионов.
- Регион является «базовой единицей движения данных key-value», реплицируется (с помощью Raft) на множество узлов. Такие наборы реплик образуют группы Raft.
- Наконец, управляющий этим кластером Placement Driver, как видно, и сам является кластером.
Установка и тестирование TiKV
Кодовая база TiKV написана преимущественно на Rust, но имеет и несколько сторонних компонентов на других языках (RocksDB на C++ и gRPC на Go). Распространяется под той же свободной лицензией Apache License v2.
Как уже говорилось в начале статьи, TiKV изначально появился как важная составляющая TiDB, но на сегодняшний день может эксплуатироваться как в рамках этой СУБД, так и отдельно. (Но в любом случае для её работы потребуется Placement Driver, написанный на Go и распространяемый как отдельный компонент).
Самая короткая инструкция для запуска TiKV вместе с СУБД TiDB требует наличия Git, Docker (17.03+), Docker Compose (1.6.0+), MySQL Client и сводится к следующей:
git clone https://github.com/pingcap/tidb-docker-compose.git
cd tidb-docker-compose && docker-compose pull
docker-compose up -d
Результатом выполнения этих команд станет развёртывание кластера TiDB, по умолчанию состоящего из следующих компонентов:
- 1 экземпляр собственно TiDB;
- 3 экземпляра TiKV;
- 3 экземпляра Placement Driver;
- Prometheus и Grafana (для мониторинга и графиков);
- 2 экземпляра (мастер + слейв) TiSpark (прослойка для запуска Apache Spark поверх TiDB/TiKV для выполнения сложных OLAP-запросов);
- 1 экземпляр TiDB-Vision (для визуализации работы Placement Driver).
Дальнейшая работа с развёрнутой СУБД:
- подключение через MySQL-клиент:
mysql -h 127.0.0.1 -P 4000 -u root; - веб-интерфейс Grafana для просмотра состояния кластера —
http://localhost:3000под admin/admin; - веб-интерфейс TiDB-Vision для информации о балансировке нагрузки в кластере и миграции данных по узлам —
http://localhost:8010; - веб-интерфейс Spark —
http://localhost:8080(доступ к TiSpark — черезspark://127.0.0.1:7077).
Если же хочется не совсем стандартного кластера TiDB (т.е. изменить его размеры, используемые Docker-образы, порты и т.п.), то после клонирования репозитория tidb-docker-compose можно отредактировать конфиг для Docker Compose:
$ cd tidb-docker-compose
$ vi compose/values.yaml
$ helm template compose > generated-docker-compose.yaml
$ docker-compose -f generated-docker-compose.yaml pull
$ docker-compose -f generated-docker-compose.yaml up -d
Для ещё большей кастомизации — см. «Customize TiDB Cluster», где описана информация, откуда берутся конфиги для TiDB, TiKV, Placement Driver и другая специфика.
Для удобного деплоя TiDB в кластер Kubernetes подготовлен одноимённый оператор — TiDB Operator. Он есть в Helm-чартах, поэтому установка может быть сведена к следующим командам (слайд из презентации на TiDB DevConf 2018):

К слову, в той же презентации говорится о взгляде разработчиков TiDB на мониторинг этой СУБД. Текстовое описание, к сожалению, на китайском языке, но общее представление можно получить из этих слайдов:

Возвращаясь же к теме непосредственно TiKV — у этого проекты опубликованы свои руководства по запуску для тестовых целей:
А для деплоя TiKV в production есть готовые наработки с Ansible — опять же, с TiDB и без неё.
Наконец, в качестве интерфейсов для работы с TiKV предлагаются:
В планах разработчиков также значится создание клиента на Rust.
Итоги
Зародившись как компонент более крупного Open Source-проекта китайской компании, TiKV уже успел завоевать известность в достаточно широких кругах. Статистика GitHub свидетельствует не только о 3600+ звёздах, но и почти 500 форках, и почти 100 контрибьюторах (хотя более 10 коммитов сделали лишь два десятка из них).
Присоединение TiKV к числу проектов CNCF и тот факт, что это первый проект подобного типа, тоже однозначно указывают на признание продукта сообществом cloud native… и должно придать импульс более активному развитию его кодовой базы сторонними (т.е. вне компании-основателя и её СУБД) специалистами.
P.S.
Читайте также в нашем блоге:
