[Перевод] Имортируем открытые гео данные из OpenGeoDB в Elasticsearch
Задумывались ли вы когда-нибудь, найдя аккуратную публичную базу данных, как хорошо было бы включить её в своё приложение, чтобы оптимизировать какую-нибудь функциональность, пусть даже незначительно? Конечно же да! Этот пост расскажет как, использовать Logstash для превращения внешнего набора данных в желаемый формат, проверить результат в Kibana и убедиться что данные правильно индексированы в Elasticsearch так, что могут быть использованы при больших нагрузках на живых серверах.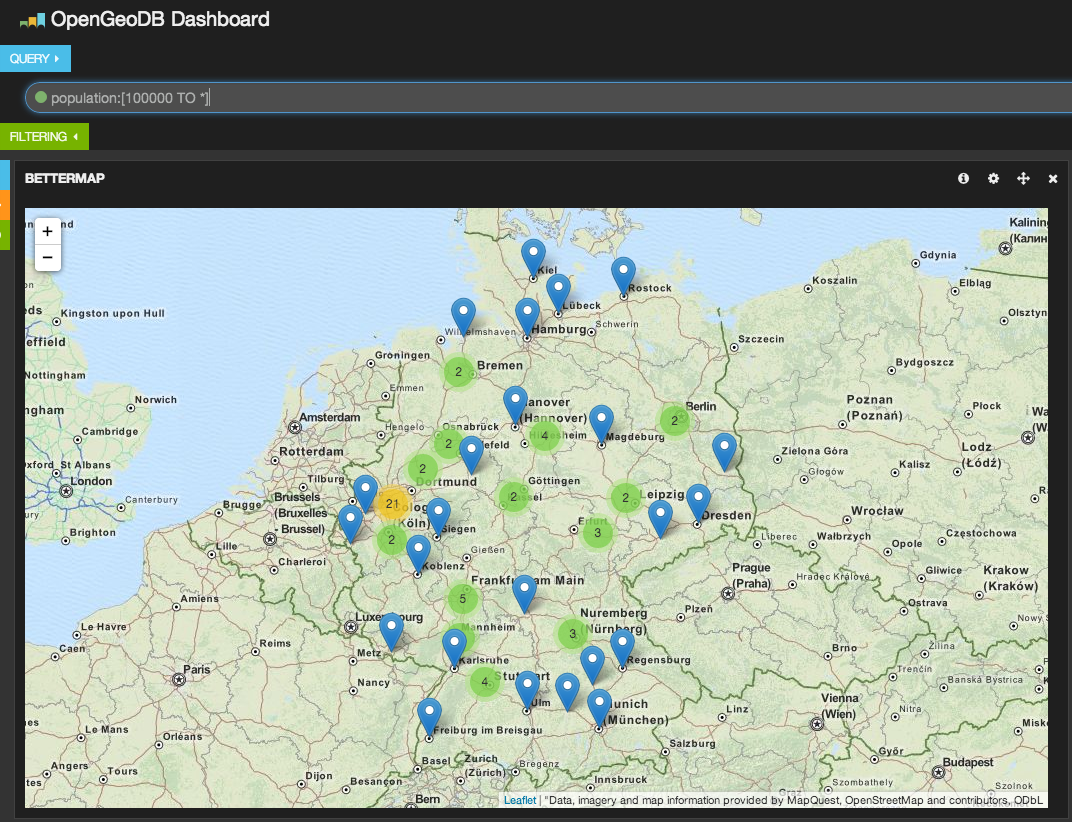
Я буду исходить из того что у вас уже установлена актуальная версия Elasticsearch и Logstash. Я буду использовать Elasticsearch 1.1.0 и Logstash 1.4.0 в последующих примерах.OpenGeoDB — это немецкий сайт, который содержит гео данные для Германии в форматах SQL и CSV. Так как мы хотим хранить данные в Elasticsearch то SQL нам не подходит, так же как и CSV. Однако, несмотря на это мы можем использовать Logstash чтобы преобразовать и проиндексировать данные в Elasticsearch. Файл, который мы собираемся индексировать, содержит список городов Германии, включая все их почтовые индексы. Эти данные доступны для скачивания с сайта OpenGeoDB (скачать файл) под лицензией public domain.
Рассмотрев данные можно заметить что, они состоят из следующих колонок: loc_id: уникальный идентификатор (внутри базы) ags: государственный административный код ascii: короткое название прописными буквами name: название сущности lat: широта (координаты) lon: долгота (координаты) amt: не используется plz: почтовый индекс (если больше одного, то разделяется запятой) vorwahl: телефонный код einwohner: количество населения flaeche: площадь kz: серия автомобильного номерного знака typ: тип административной единицы level: целое число, которое определяет положение местности в иерархии of: идентификатор местности частью которой является эта местность invalid: колонка недействительна Нам интересны поля name, lat, lon, area, population и license tag. Мы вернемся к ним вскоре…
используем csv фильтр logstash Следующим шагом будет поместить данные в Elasticsearch. Первым делом мы настроим Logstash. Скопируем конфиг ниже в файл opengeodb.conf. Обратите внимание на то что мы используем фильтр «csv»(comma-separated values), несмотря на то что разделителем является табуляция, а не запятая. input { stdin {} }
filter { # Step 1, possible dropping if [message] =~ /^#/ { drop {} }
# Step 2, splitting csv { # careful… there is a «tab» embedded in the next line: # if you cannot copy paste it, press ctrl+V and then the tab key to create the control sequence # or maybe just tab, depending on your editor separator => ' ' quote_char => '|' # arbitrary, default one is included in the data and does not work columns => [ 'id', 'ags', 'name_uc', 'name', 'lat', 'lon', 'official_description', 'zip', 'phone_area_code', 'population', 'area', 'plate', 'type', 'level', 'of', 'invalid' ] }
# Step 3, possible dropping if [level] != '6' { drop {} }
# Step 4, zip code splitting if [zip] =~ /,/ { mutate { split => [ «zip»,»,» ] } }
# Step 5, lat/lon love if [lat] and [lon] { # move into own location object for additional geo_point type in ES # copy field, then merge to create array for bettermap mutate { rename => [ «lat»,»[location][lat]», «lon»,»[location][lon]» ] add_field => { «lonlat» => [ »%{[location][lon]}»,»%{[location][lat]}» ] } } }
# Step 6, explicit conversion mutate { convert => [ «population», «integer» ] convert => [ «area», «integer» ] convert => [ »[location][lat]», «float» ] convert => [ »[location][lon]», «float» ] convert => [ »[lonlat]», «float» ] } }
output { elasticsearch { host => 'localhost' index => 'opengeodb' index_type => «locality» flush_size => 1000 protocol => 'http' } } Перед тем как продолжить, обратите внимание, вот так мы будем запускать Logstash для индексации данных. Elasticsearch должен быть запущен.
cat DE.tab | logstash-1.4.0/bin/logstash -f opengeodb.conf На этом этапе происходит довольно много всего (индексация может занять минуту или более, все зависит от вашего оборудования). Первое на что вы можете обратить внимание, это то что в конфигурации Logstash не используется ввод инструкцией «file». Это потому, что этот метод ввода ведет себя как «tail -f» в UNIX системах, то есть ожидает добавления новых данных в файл. Наш файл напротив имеет фиксированный размер, так что более разумно будет прочитать все его данные с помощью ввода «stdin».
Секция «filter» состоит из шести шагов. Давайте рассмотрим их подробнее и объясним что делает каждый из них.
шаг 1 — игнорируем комментарии На первом шаге избавляемся от комментариев. Их можно определить по символу решетки в начале строки. Это необходимо сделать потому, что первая строка в нашем файле именно такой комментарий, который содержит имена колонок. Их индексировать нам не нужно.шаг 2 — разбираем csv Второй шаг выполняет всю сложную работу по разбору CSV. Вам необходимо переопределить «separator» (разделитель) значением «tab» (табуляция), «quote_char» по умолчанию одна кавычка », которая присутствует в значениях наших данных и поэтому должна быть заменена другим символом. Свойство «columns» определяет имена колонок, которые будут использованы позже в качестве имен полей. Внимание! При копировании файла отсюда вам будет необходимо заменить символ «separator», так как вместо табуляции он будет скопирован как несколько пробелов. Если скрипт не работает как следует проверьте это в первую очередь.
шаг 3 — пропускаем не нужные записи Нам нужны только записи которые отображают информацию о городах (те у которых поле «level» в значении 6). Остальные записи мы просто игнорируем.шаг 4 — обрабатываем почтовый индекс Четвертый шаг нужен для правильной обработки почтового индекса. Если у записи больше одного почтового индекса (как например в больших городах), то они все содержатся в одном поле, но разделены запятыми. Чтобы сохранить их в виде массива, а не одной большой строкой, используем фильтр «mutate» чтобы разделить значения этого поля. Вот, к примеру, содержание этих данных в виде массива чисел позволит нам использовать поиск по диапазону числовых значений.шаг 5 — структура гео данных Пятый шаг сохранит гео данные в более удобном формате. При чтении из файла DE.dat создаются отдельные поля lat и lon. Однако смысл в этих полях есть только тогда, когда они хранятся вместе. Этот шаг записывает оба поля в две структуры данных. Одна выглядит как тип Elasticsearch geo_point и в результате как структура { «location»: { «lat»: x, «lon»: y }}. Другая же выглядит простой массив и содержит долготу (longitude) и широту (latitude) (именно в таком порядке!). Так что мы можем использовать компонент Kibana bettermap чтобы отобразить координаты.шаг 6 — явное приведения полей к типу Последний шаг фильтра явно присваивает типы данных некоторым полям. Таким образом Elasticsearch сможет выполнять числовые операции с ними в будущем.Секция «output» доступна в Logtash только начиная с версии 1.4, так что убедитесь что у вас версия не меньше. В предыдущей версии вам необходимо явно указать вывод «elasticsearch_http». Забегая вперед скажу что там будет только один вывод «elasticsearch» и вы сможете указать protocol => http чтобы использовать HTTP через порт 9200 для соединения с Elasticsearch.
Когда данные проиндексированы мы можем использовать Kibana для их дальнейшего анализа. Используя виджет bettermap и простой поисковый запрос вроде population:[10000 TO *] мы можем отобразить каждый большой город в Германии.
Вы можете использовать это, например, для таких целей:
Найти города с наибольшим населением Найти города в которых используется общая серия автомобильных номерных знаков (например, GT используется в Gütersloh и окрестностях) Использовать скрипт аггрегации для нахождения областей с наиболее плотным или редким населением на квадратный километр. Также можно предварительно посчитать эти показатели в Logstash. Всё это очень хорошо, но это никак не помогает нам улучшить существующие приложения. We need to go deeper.Настраиваем автодополнение Отвлечемся на мгновение и посмотрим какие полезные штуки возможно делать с этими данными. У нас есть города, почтовые индексы… и множество случаев в веб приложениях где необходимо вводить именно эти данные.Хорошим примером является процесс оформления покупки. Не каждый магазин заранее владеет данными пользователя. Это может быть магазин в котором заказы часто одноразовые или вовсе заказ можно сделать без регистрации. В этом случае может быть уместно помочь пользователю ускорить процесс оформления заказа. При этом «бесплатным» бонусом будет предотвращение потери заказа или отмены изза сложностей оформления заказа.
Elasticsearch обладает очень быстрым функционалом поиска по префиксу под названием «completion suggester». Но у этого поиска есть недостаток. Вам необходимо слегка дополнить ваши данные перед индексацией, но именно для этого у нас и есть Logstash. Чтобы лучше понять этот пример, вам может понадобится прочитать введение в «completion suggester»(англ).
Подсказки Предположим мы хотим помочь пользователю ввести название города в котором он или она живет. Также мы хотели бы предоставить список почтовых индексов, чтобы было легче найти подходящий к выбранному городу. Также вы можете сделать наоборот, сперва дав пользователю ввести почтовый индекс, а тогда уже автоматически заполнить информацию о городе.Пришло время внести несколько изменений в конфигурацию Logstash, чтобы это заработало. Начнем с простого, конфигурации внутри фильтра. Добавьте этот отрывок конфигурации в ваш opengeodb.conf, сразу после шага 5 и перед шагом 6.
# Step 5 and a half # create a prefix completion field data structure # input can be any of the zips or the name field # weight is the population, so big cities are preferred when the city name is entered mutate { add_field => [ »[suggest][input]»,»%{name}» ] add_field => [ »[suggest][output]»,»%{name}» ] add_field => [ »[suggest][payload][name]»,»%{name}» ] add_field => [ »[suggest][weight]»,»%{population}» ] } # add all the zips to the input as well mutate { merge => [ »[suggest][input]», zip ] convert => [ »[suggest][weight]», «integer» ] } # ruby filter to put an array into the event ruby { code => 'event[»[suggest][payload][data]»] = event[«zip»]' } Теперь Logstash запишет данные в структуре совместимой с «completion suggester», когда вновь будет индексировать данные. Однако также нужно настроить шаблон соответствия полей, чтобы функция подсказки была настроена и в Elaticsearch. Поэтому вам также необходимо явно указать шаблон в настройках Logstash в секции output > elastichsearch. # change the output to this in order to include an index template output { elasticsearch { host => 'localhost' index => 'opengeodb' index_type => «locality» flush_size => 1000 protocol => 'http' template_name => 'opengeodb' template => '/path/to/opengeodb-template.json' } } Этот шаблон очень схож с шаблоном Logstash по умолчанию, но в нем добавлены поля suggest и geo_point { «template» : «opengeodb», «settings» : { «index.refresh_interval» :»5s» }, «mappings» : { »_default_» : { »_all» : {«enabled» : true}, «dynamic_templates» : [ { «string_fields» : { «match» :»*», «match_mapping_type» : «string», «mapping» : { «type» : «string», «index» : «analyzed», «omit_norms» : true, «fields» : { «raw» : {«type»: «string», «index» : «not_analyzed», «ignore_above» : 256} } } } } ], «properties» : { »@version»: { «type»: «string», «index»: «not_analyzed» }, «location» : { «type» : «geo_point» }, «suggest» : { «type»: «completion», «payloads» : true, «analyzer» : «whitespace» } } } } } Теперь пришло время удалить старые данные (включая индекс) и запустить переиндексацию curl -X DELETE localhost:9200/opengeodb cat DE.tab | logstash-1.4.0/bin/logstash -f opengeodb.conf Теперь можно выполнить запрос к «сажжестеру» curl -X GET 'localhost:9200/opengeodb/_suggest? pretty' -d '{ «places» : { «text» : «B», «completion» : { «field» : «suggest» } } }' А вот и результат: { »_shards» : { «total» : 5, «successful» : 5, «failed» : 0 }, «places» : [ { «text» : «B», «offset» : 0, «length» : 1, «options» : [ { «text» : «Berlin», «score» : 3431675.0, «payload» : {«data»:[«Berlin»,»10115»,»10117»,»10119»,»10178»,»10179»,»10243»,»10245»,»10247»,»10249»,»10315»,»10317»,»10318»,»10319»,»10365»,»10367»,»10369»,»10405»,»10407»,»10409»,»10435»,»10437»,»10439»,»10551»,»10553»,»10555»,»10557»,»10559»,»10585»,»10587»,»10589»,»10623»,»10625»,»10627»,»10629»,»10707»,»10709»,»10711»,»10713»,»10715»,»10717»,»10719»,»10777»,»10779»,»10781»,»10783»,»10785»,»10787»,»10789»,»10823»,»10825»,»10827»,»10829»,»10961»,»10963»,»10965»,»10967»,»10969»,»10997»,»10999»,»12043»,»12045»,»12047»,»12049»,»12051»,»12053»,»12055»,»12057»,»12059»,»12099»,»12101»,»12103»,»12105»,»12107»,»12109»,»12157»,»12159»,»12161»,»12163»,»12165»,»12167»,»12169»,»12203»,»12205»,»12207»,»12209»,»12247»,»12249»,»12277»,»12279»,»12305»,»12307»,»12309»,»12347»,»12349»,»12351»,»12353»,»12355»,»12357»,»12359»,»12435»,»12437»,»12439»,»12459»,»12487»,»12489»,»12524»,»12526»,»12527»,»12529»,»12555»,»12557»,»12559»,»12587»,»12589»,»12619»,»12621»,»12623»,»12627»,»12629»,»12679»,»12681»,»12683»,»12685»,»12687»,»12689»,»13051»,»13053»,»13055»,»13057»,»13059»,»13086»,»13088»,»13089»,»13125»,»13127»,»13129»,»13156»,»13158»,»13159»,»13187»,»13189»,»13347»,»13349»,»13351»,»13353»,»13355»,»13357»,»13359»,»13403»,»13405»,»13407»,»13409»,»13435»,»13437»,»13439»,»13442»,»13465»,»13467»,»13469»,»13503»,»13505»,»13507»,»13509»,»13581»,»13583»,»13585»,»13587»,»13589»,»13591»,»13593»,»13595»,»13597»,»13599»,»13627»,»13629»,»14050»,»14052»,»14053»,»14055»,»14057»,»14059»,»14089»,»14109»,»14129»,»14163»,»14165»,»14167»,»14169»,»14193»,»14195»,»14197»,»14199»]} }, { «text» : «Bremen», «score» : 545932.0, «payload» : {«data»:[«Bremen»,»28195»,»28203»,»28205»,»28207»,»28209»,»28211»,»28213»,»28215»,»28217»,»28219»,»28237»,»28239»,»28307»,»28309»,»28325»,»28327»,»28329»,»28355»,»28357»,»28359»,»28717»,»28719»,»28755»,»28757»,»28759»,»28777»,»28779»,»28197»,»28199»,»28201»,»28259»,»28277»,»28279»]} }, { «text» : «Bochum», «score» : 388179.0, «payload» : {«data»:[«Bochum»,»44787»,»44789»,»44791»,»44793»,»44795»,»44797»,»44799»,»44801»,»44803»,»44805»,»44807»,»44809»,»44866»,»44867»,»44869»,»44879»,»44892»,»44894»]} }, { «text» : «Bielefeld», «score» : 328012.0, «payload» : {«data»:[«Bielefeld»,»33602»,»33604»,»33605»,»33607»,»33609»,»33611»,»33613»,»33615»,»33617»,»33619»,»33647»,»33649»,»33659»,»33689»,»33699»,»33719»,»33729»,»33739»]} }, { «text» : «Bonn», «score» : 311938.0, «payload» : {«data»:[«Bonn»,»53111»,»53113»,»53115»,»53117»,»53119»,»53121»,»53123»,»53125»,»53127»,»53129»,»53173»,»53175»,»53177»,»53179»,»53225»,»53227»,»53229»]} } ] } ] } Теперь, как вы уже могли заметить, логично использовать население города как его вес. Большие города будут в подсказке выше чем маленькие города. Возвращаемый результат содержит в себе название города и все его почтовые индексы, которые могут быть использованы для автоматического заполнения формы (особенно если найден всего один почтовый индекс).И это все на сегодня! Однако помните что это подходит не только для общедоступных баз данных. Я абсолютно уверен что где-то, глубоко внутри вашей компании, кто-нибудь уже собрал полезнешие данные, которые только и ждут чтобы быть дополнеными и использованными в ваших приложениях. Спросите своих колег. Вы найдете такие базы данных в любой компании.
Это мой первый перевод. Поэтому заранее благодарен всем, кто поможет улучшить его и укажет на мои ошибки.Спасибо.
