[Перевод] Гладко было на бумаге, или почему не стоит чрезмерно доверять туториалам
Такая история всегда начинается одинаково. Вам показывают демку, в которой набор проблем, ранее казавшийся сложным, решается на раз — достаточно запустить некий Волшебный Инструмент. Зачастую такой инструмент рекомендуют Большие Тузы из отрасли, либо не только рекомендуют, но и сами поддерживают. У вас в организации отыскиваются коллеги, ратующие за то, чтобы немедленно взять эту технологию на вооружение. Буквально в ночь наутро этот новый инструмент приравнивается к «решению всех наших проблем».
К тому моменту, как его обсуждение доходит до руководителей высшего звена, инструмент уже раскручен в пресс-релизах. Вы видите статьи в духе «Технология X морально устарела, время обзаводиться Волшебным Инструментом». Те из вас, кто не так давно работает в технической отрасли, могут предположить, что, пожалуй, была сделана какая-то добросовестная оценка, призванная проверить, в самом ли деле Волшебный Инструмент так хорош, или безопасен, или уместен именно в вашем бизнесе. Нет, вы ошибаетесь.
Вскоре запускается внутрикорпоративная инициатива. Среди начальства найдутся те, кто решат превратить Волшебный Инструмент в важный проект, и Волшебный Инструмент начинают навязывать в командах. Именно тут пробегают первые трещинки, когда команды, относительно индифферентные к Волшебному Инструменту, реально начинают им пользоваться. «Он же не делает всего того, чем нам приходится сейчас заниматься, а ещё не учтены пограничные случаи — в них с Инструментом работать гораздо сложнее, чем нам рассказывали».
Иногда команде, пытающейся выкатить эту новую технологию, удаётся разобраться со всеми пограничными случаями. Но время идёт, и вскоре новый Волшебный Инструмент уже выглядит таким де сложным и ощетинившимся острыми краями, как и те инструменты, что были в ходу ранее. В результате всей этой работы и разговоров организации ещё повезёт, если удастся нарастить производительность на 2–5% —, но речь и близко не идёт о том «квантовом скачке», который сулили поборники Волшебного Инструмента.
Почему раз за разом случается именно так?
Мы все одержимы идеей, будто писать программы слишком сложно, и так быть не должно. Когда мы приступаем к проекту, никто не знает наверняка, что именно мы делаем. Ваши регалии для этой работы — это то, что вы успели выучить на курсах или дома, ваше умение самостоятельно мастерить мелкие поделки. Скворечники на Java, может быть, часы на Python, которые запитаны от картофелины. Затем вам приходится пройти серию собеседований, где разные люди задают вам случайные вопросы, в основном не касающиеся вашей работы. «Как построить скворечник на 100 000 птиц?» В конце концов, вы приступаете к работе и оказываетесь в команде из 800 человек, которой поручено сконструировать истребитель. Перед началом работы вам вручают документацию, и в ней описано, как соорудить пикап F-150.
Таким образом, когда людям доводится увидеть туториал или демо, которые казалось бы, раз за разом дают именно тот результат, что требуется — у людей загораются глаза. Да, всегда предполагалось, что именно так и должно быть. Проблема была не во мне и не в моих коллегах, а в том, что мы выбрали неподходящую технологию. Облака рассеиваются, проступают звёзды, всё вновь наполняется смыслом. Но почти всегда и это ошибка. Не стоит рассчитывать, что большие технологические изменения, затрагивающие много команд и систем, когда-нибудь пройдут легко, возьмут — и подхватятся. Признаю, технология как таковая может быть превосходной, но с тем же успехом с ней можно натерпеться.
Далее я приведу 3 примера хороших технологий, работать с которыми в долгосрочной перспективе становится все хуже, поскольку упорно хочется держать порог вхождения новых сотрудников в эту технологию как можно ниже. И здесь рвение по поводу внедрения этих инструментов в конечном итоге вредит повседневной работе с этими инструментами. Docker, Kubernetes и Node. Все эти технологии в сообществе дико излюблены, и вот почему: возможностям каждой из них можно позавидовать, но истинная сложность вкатывания в каждую из них компенсируется внятными и простыми руководствами.
Поймите меня правильно: я не виню тех, кто занимается поддержкой этого софта. Я стараюсь донести, что мы должны качественнее справляться с заблаговременной обрисовкой предстоящих сложностей, чтобы люди понимали масштабы и глубину проблемы до того, как мы попытаемся укоренить эту проблему во всей индустрии. Часто приходится иметь дело со всплесками хайпа, при которых некая технология подаётся как «безальтернативная» — чтобы потом резко распрощаться с такими иллюзиями, как только они столкнутся с реальностью.
Ваше приложение не должно работать с root-правами внутри контейнера
Думаю, фундаментальные недоработки всей контейнерной индустрии ни в чём не проявляются так выразительно, как в проваленной безопасности. Задача за задачей, митап за митапом –, а мне по-прежнему попадаются люди, которые попросту не в курсе, что применяемая по умолчанию модель сборки контейнеров просто изначально ошибочная. Приложения, работающие в контейнерах, по умолчанию не должны наделяться правами администратора.
Но что в принципе означает «обладать админ-правами» в контейнере? Эта ситуация сложнее, чем кажется на первый взгляд. За кулисами выполняется масса работы, чтобы обращаться с контейнером было легко, и сложность, присущая этой работе, оставалась скрыта от вас. Давайте поговорим, как Docker дошёл до этой проблемы, и как Podman пытается с ней справиться.
Правда, вы должны усвоить следующее. Если вы эксплуатируете контейнер в стандартной конфигурации, пользуясь при этом аккаунтом с правами администратора, и из этого контейнера что-либо ускользнёт, то у вас серьёзные проблемы, Kubernetes это или не Kubernetes.
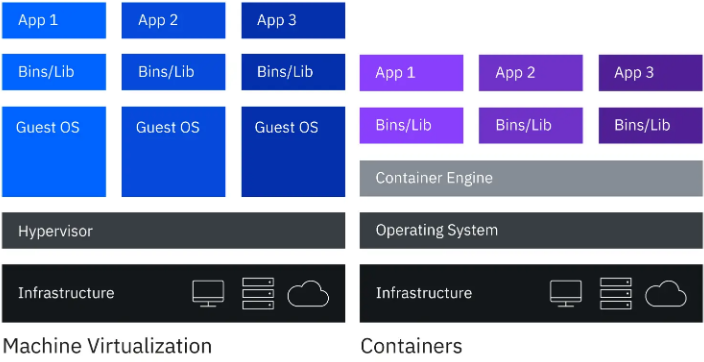 Сравнение виртуализованных и контейнерных инфраструктур
Сравнение виртуализованных и контейнерных инфраструктур
Всё-таки есть небольшая вероятность, что вы просто не знаете, как работают контейнеры.
Docker
Когда Docker вышел в свет и стал приобретать популярность, попытки гонять его на хосте, наделив правами администратора, воспринимались предосудительно. Но было две причины, по которым, как нам объясняли, такая практика действительно оправдана. Во-первых, так можно без всяких ограничений монтировать каталоги внутри контейнера, а во-вторых — привязываться в Linux к портам с номерами ниже 1024. Теперь в Docker уже нет обязательного требования использовать демон с правами администратора, но никуда не делись ограничения, связанные с монтированием каталогов и номерами портов. Кроме того, Docker должен учитывать характеристики той сети, в которой работает хост, и уйму прочих возможностей.
Всё это привело к активным дебатам. Казалось безумием просто отказаться от обеспечения всякой безопасности пользователей Linux в обмен на простоту разработки и тестирования, но сообщество форсило эту проблему. Нам говорили, что всё это в самом деле не важно, поскольку «администратор в контейнере — это не настоящий администратор». Поначалу этот довод не казался изрядно убедительным, но все мы с ним смирились. Привет, пространства имён ядра.
Парадоксально, но пространства имён в Linux совершенно не похожи на пространства имён в Kubernetes. Это изолирующая фича — то есть, сервис, работающий в одном пространстве имён, не может ни видеть процесс, действующий в другом пространстве имён, ни обращаться к этому процессу. Существуют пользовательские пространства имён — это механизм, позволяющий пользователю обладать правами администратора в своём пространстве имён, но без возможности передавать это право кому-либо. Есть пространства имён, разграничиваемые по ID процессов — то есть, может быть несколько процессов с идентификатором 1, работающих в изоляции друг от друга. Бывает сетевое пространство имён, привязанное к сетевому стеку, монтировочное пространство имён, в котором можно монтировать и размонтировать тома, не меняя при этом хост, IPC-пространства имён с разграниченными и изолированными очередями POSIX-сообщений. Есть, наконец, пространства имён UTS, соответствующие разным именам хостов и доменным именам.
Убедительно подано. У вас может быть несколько «администраторов», гоняющих кучу процессов — причём, эти процессы изолированы друг от друга в разных сетевых стеках. В рамках стека можно монтировать и размонтировать элементы, а также обмениваться сообщениями внутри пространства имён, не затрагивая при этом другие пространства имён. Объём выделяемых ресурсов и приоритет их использования контролируется на уровне cgroups, и именно здесь контейнеры сталкиваются с пределами возможностей ЦП и памяти.

Звучит здорово. Так в чём же проблема?
Пространства имён и группы cgroups не гарантируют идеальной безопасности, и с ними определённо далеко не уедешь, если не знать широкого дополнительного контекста. Например, при использовании контейнера с опцией --privileged исключается значение пространства имён. Такая практика обычна в стеках CI/CD, когда требуется гонять Docker в Docker. Docker также не использует всех опций пространства имён, и самое важное — он не обязывает пользовательские пространства имён переназначать другого пользователя данного хоста в качестве администратора, но поддерживает такую операцию.
Честно говоря, технари Docker очень и очень постарались сохранить практику использования Docker настолько простой, насколько это возможно, улучшая при этом безопасность. По умолчанию Docker отбрасывает некоторые возможности Linux, и этот список можно расширить по мере необходимости. Вот список всех возможностей Linux. Наконец, вот те возможности Linux, которые использует Docker. Как видите, команда безопасников отчаянно стремится упредить проблемы и хорошо справиться со своей работой.
Беда в том, что ничего из этого не сообщается людям на том этапе, когда технология осваивается на предприятии. Ничего этого как следует не излагается в руководствах, не акцентируется в демках, а чтобы с толком подступиться к этой области задач — нужно понимать Linux. Если бы Docker заранее заложил это требование в инструментарий и вынуждал вас с самого начала всё делать правильно, то у нас в целом было бы гораздо меньше проблем с безопасностью. В список таких обязательных требований я бы включил:
Выдавать пользователям кучу предупреждений, когда они работают при активированном флаге --privileged
По умолчанию создавать нового пользователя или пользовательское пространство с контейнерами, не наделяя пользователя правами администратора и закладывая один общий каталог, в который могут записывать информацию такие пользователи.
По умолчанию ставить --cap-drop=all, обязывая пользователей самостоятельно добавлять каждую привилегию, которая им нужна.
По умолчанию использовать --security-opt=no-new-privileges.
По умолчанию добавлять определения ресурсов так, как описано здесь: https://docs.docker.com/engine/reference/run/#runtime-constraints-on-resources
Помогать людям писать AppArmor или предусматривать какой-нибудь другой инструментарий для обеспечения безопасности, как показано здесь.
По умолчанию активировать Пользовательские Пространства Имён лишь при условии, что вы являетесь администратором. В таком случае есть возможность отобразить пользователя-администратора контейнера на пользователя с ненулевым uid вне контейнера, и работа по экранированию контейнера также упрощается.
Нет же, вместо этого почти все мы стали использовать контейнеры в качестве основополагающего элемента наших технологий — и в основном делали это неправильно. Кстати, Podman решает большинство из вышеупомянутых проблем, и именно им рекомендую вам пользоваться отныне. Начав с чистого листа, разработчики Podman избежали многих проблем, изначально присущих Docker, и реализовали гораздо более устойчивый и качественно спроектированный подход к контейнерам и обеспечению безопасности вообще. Снимаю шляпу перед этой командой.
Как мне определить, правильно ли устроены мои контейнеры
В Docker сделали отличный инструмент, помогающий решить эту задачу, он находится you здесь. Этот инструмент называется Docker Bench for Security (Стенд безопасности Docker). С его помощью можно сканировать контейнеры, смотреть, насколько они безопасны — и еще этот инструмент выдаёт вам рекомендации. Я его большой поклонник, и из работы с ним многое узнал о том, как правильно обращаться с Docker.
 Джефф (25 лет), попытавшийся освоить Kubernetes брутфорсом
Джефф (25 лет), попытавшийся освоить Kubernetes брутфорсом
Kubernetes
Я познакомился с Kubernetes много лет назад как с «системой, которую используют в Google». Теперь понятно, что это не так, внутренние системы Google и K8s разошлись в развитии уже очень давно. Но Kubernetes по-прежнему воспринимается как «большой скачок» в проектировании приложений. В один прекрасный день организации принялись рьяно внедрять Kubernetes, зачастую не вполне понимая, что это за система, и какие задачи она призвана решать. Kubernetes, как и все инструменты, хорош для решения одних классов задач и ужасно справляется с другими.
Лично я люблю k8s, и мне нравится работать с ним. Но оказалось, что на раннем этапе поборники Kubernetes обещали такие вещи, которые в ретроспективе кажутся безумными. K8s непрост как для понимания, так и для реализации, здесь хватает и острых кромок, и тупиковых случаев, встречающихся с завидной частотой. Демо-сцены Minikube не дают реалистичного представления о том, как будет выглядеть законченный продукт.
Скажу вам правду: k8s плохо подходит для большинства бизнес-контекстов.
Демки Kubernetes определённо выглядят впечатляюще, верно? Берёте ваши контейнеры, сметаете их в облако, и всё сразу начинает работать правильно, трафик поступает куда надо — как по волшебству. Всё масштабируется (и наращивается, и ужимается), вы не замыкаетесь на конкретном производителе или решении. Есть API на все случаи жизни, так что любым элементом можно манипулировать из единой плоскости управления. Когда вы впервые начинаете использовать k8s, он кажется волшебным, такой оверлей поверх вашего облачного провайдера, просто выполняющий вашу работу за вас.
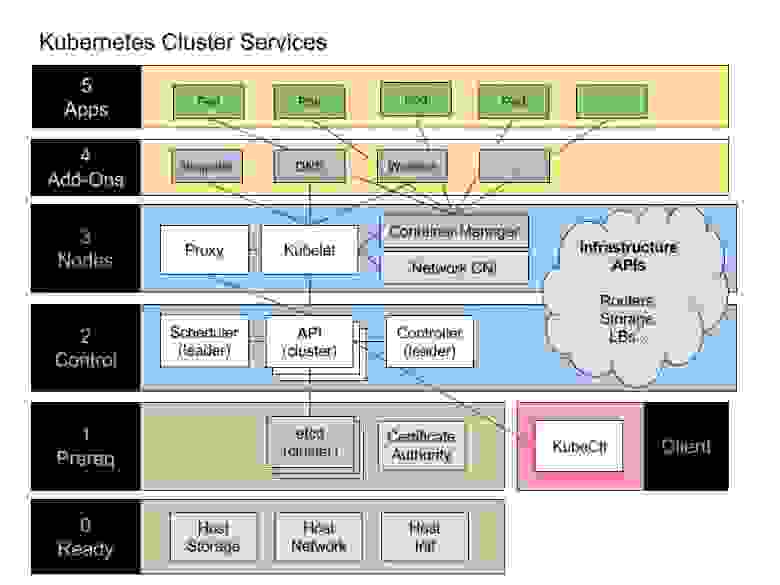 Мне нравится, как в этой схеме маршрутизаторы, хранилища данных и балансировщики нагрузки все скопом вынесены в облачко
Мне нравится, как в этой схеме маршрутизаторы, хранилища данных и балансировщики нагрузки все скопом вынесены в облачко
А что на самом деле
Реальность же такова, что вы, вводя k8s в продакшен, должны гораздо реальнее представлять, для решения каких задач он предназначен, а для каких — нет. K8s спроектирован для целиком эфемерных приложений. Они не завязаны на локальное хранилище данных, а принимают запросы, обрабатывают их и могут быть запросто остановлены. В то время как (сейчас) могут предусматриваться опции с хранилищем данных, пользоваться ими в целом неразумно, учитывая, как хранилища данных работают с различными зонами приложений в облачных провайдерах. Можно прибегать, например, к пакетным заданиям и к гарантированным прогонам внутри k8s, но на уровне типичного приложения это совершенно особый паттерн проектирования.
Кроме того, K8s не назовёшь неуязвимым. Часто приходится решать масштабные проблемы с разрешением DNS, поскольку внутренняя сетевая система сильно зависит от доменных имён. По умолчанию эта система широко распахнута и позволяет вам создавать такие пространства имён, которые не изолируют сетевой трафик (распространённая ошибка, о которой то и дело доводится слышать). Если вы пытаетесь выяснить, какой именно маршрут вызывает проблемы, то обязательно нужно реализовать сервисную сетку как своего рода трассировочное решение. Проблемы на уровне плоскости управления редки, но любая такая проблема — катастрофа. Чтобы обезопасить конечные точки API и трафик в целом требуется тщательно поработать.
Также вам придётся проделать обширные исследования, прежде, чем запускать k8s. Узнать, какой сетевой контейнерный интерфейс (CNI) лучше всего вам подходит, как должна работать внешняя DNS, как вы собираетесь организовать балансировку нагрузки при обращении с трафиком, где будет происходить завершение SSL, как вы собираетесь обновлять узлы, на которых фактически работают эти контейнеры? Как организуете мониторинг, графы, логирование, оповещение? Всё это нужно спланировать и расчертить. Безопасны ли ваши контейнеры? Понимаете ли вы, какие зависимости возникают между вашими приложениями?
Чтобы масштабно использовать k8s с участием нескольких сотен разработчиков, в вашей организации должно быть несколько человек, досконально разбирающихся в том, как он работает. Именно к ним вы будете обращаться за решением технических проблем, по мере того, как команды разработчиков приложений попытаются отмотать путь к той точке, где возникла проблема. Технические специалисты по Kubernetes постоянно должны быть в доступе, чтобы отвечать на вопросы. Помните, что принимаете на себя:
Целую облачную среду с IAM (управлением учётными данными), VPC (виртуальными частными каналами), политиками безопасности, серверами Linux, корзинами, очередями сообщений и всем прочим
Поверх всего этого добавляете, фактически, совершенно новую среду. Две эти системы, тем не менее, взаимодействуют и могут провоцировать проблемы друг другу, но из каждой из этих систем другая видна очень плохо. Возможно, диагностировать проблемы в таких системах будет бешено сложно.
Поэтому, чтобы всё это было сделано правильно, вам нужны люди, которые понимают оба пространства задач и могут помочь разобраться, где именно происходит каждый шаг.
Итак, когда же следует использовать Kubernetes
Вы тратите кучу денег на контейнеры, которые недоиспользуются, либо добавляете дополнительные мощности, чтобы приложение не падало совсем в период отказов. K8s действительно блещет в управлении ресурсами и отлично справляется с отказами узлов или подов.
Вы убеждённый сторонник микросервисов. K8s хорошо сплетается с типичными микросервисами, позволяя вам запекать в них функции мониторинга и трассировки, а также организовывать чёткие взаимодействия между микросервисами при помощи сервисных сеток.
Мультиоблако для вас — обязательное требование. Будьте чрезвычайно осторожны, выдвигая такое требование в качестве обязательного — зачастую оно глубоко ошибочно.
Серьёзной проблемой является зависимость от конкретного поставщика. Это приемлемо, только если вы олигарх из Fortune 500. В иных случаях даже не тратьте на это ваших серых клеточек.
Первоочередная задача — обеспечить работоспособность приложения. Если приложение работает, то любая заложенная в нём сложность вознаграждается.
Вы пытаетесь найти технологию, которая послужила бы вам мостиком между датацентром и облаком.
В иных случаях попробуйте какой-нибудь другой вариант, ведь имя им легион. Запускаете новую компанию? Попробуйте Lightsail. Задачи великоваты для Lightsail? Попробуйте ECS. Можно вырасти до исключительно больших размеров, полагаясь на эти технологии, которые значительно проще Kubernetes. Если вы переросли Lightsail — радуйтесь, вы достаточно выросли, чтобы вербовать команду. Если вы решите остановиться на k8s — поймите и начертите, что именно вы от него хотите. Не рассчитывайте, что, если всего лишь включить Kubernetes и записать в него немного yaml — то и так сойдёт.
Как правильно подготовиться к k8s
Наилучшее руководство на эту тему, которое мне попадалось, и которым я несколько раз пользовался — это NSA k8s hardening guide. В нём разобраны все типичные проблемы и соображения, возникающие при масштабном использовании k8s, на каждом этапе предлагаются хорошие и здравые рекомендации. Если вы — компания, обдумывающая, использовать ли k8s, либо уже используете его, но не уверены, правильно ли настроили систему — проштудируйте это руководство и обсудите те моменты, которые там акцентируются. Как минимум, это позволит вам подступиться к проекту, рассматривая его под правильным углом.
Node.js
С Node как таковым у меня проблем не возникало. Я не делаю ставок в этих скачках на тему «должны ли мы писать бэк и фронт на одном и том же языке». Нет, реальная проблема, возникавшая у меня с Node на самом деле связана с NPM. Поработав с командами, всесторонне полагавшимися на NPM как для предоставления приватных внутренних пакетов, так и для построения приложений, использующих внешние сторонние зависимости, я убедился, что такая практика небезопасна, с какой бы скоростью мы этим ни занимались.

NPM: простота важнее безопасности
Довольно долго разработка приложений развивалась по весьма ровному пути в вопросах, касающихся использования зависимостей. Вы стараетесь написать как можно кода, пользуясь стандартной библиотекой выбранного вами языка программирования, а сторонние зависимости подтягиваете сторонние зависимости, когда такая практика серьёзно экономит вам время, либо когда на уровне зависимостей решаются такие вещи, с которыми нормальные люди просто не хотят связываться (например, хеширование паролей или создание соединений с базами данных).
Как правило, вы вносили эти зависимости в ваш проект до самого завершения его существования, и в процессе ревью кода часто возникали дебаты о том, «целесообразно ли импортировать x строк кода навечно», чтобы сэкономить время или добавить этот новый функционал. Часто при дебатах требовалось учитывать затраты на поддержку кода, так как, если функция написана с привлечением одной лишь стандартной библиотеки, то её относительно легко обновлять от версии к версии.
Однако зависимости, в особенности, усложнённые или большие, вносят в код множество долгосрочных проблем. Сами эти зависимости зачастую обременены зависимостями, либо опираются на сравнительно эзотерические аспекты языка для решения проблем, которых в вашем проекте зачастую нет (так как поле использования библиотеки шире всего вашего проекта).
Приведу пример. Мы с коллегами разрабатывали приложение на PHP, и мне требовалось сделать кое-какие мелочи с привлечением S3. Я (естественно) добавил официальный AWS SDK для PHP, считая, что именно так и следует делать. Более опытный разработчик меня притормозил, верно указав, что я навсегда добавляю в репозиторий массу нового кода и, может быть, можно решить эту задачу как-нибудь получше.
curl -s https://api.github.com/repos/aws/aws-sdk-php | jq '.size' | numfmt --to=iec --from-unit=1024
190M
Много мегабайт, чтобы просто воспользоваться S3
Оказывается, это относительно легко сделать, не загружая навечно в нашу базу кода целый SDK и не привнося кучу новых зависимостей. Однако, на такие шатания уходит время, и поэтому ребятам зачастую требуется гораздо подробнее разобраться в тех сервисах, потребляемых их приложениями. Клиентские библиотеки для SaaS часто скрывают эту сложность за очень простыми методами, позволяющими быстро вкинуть в код ключ API и двигаться дальше.
Восхождение Node
Когда Node только появился в индустрии, он обещал совсем иные блага, нежели большинство серверных языков. Что, если команды по разработке клиентской и серверной части не будут вечно работать каждая над своими приложениями, дожидаясь, пока в API будут добавлены новые конечные точки? Пусть лучше всё приложение поддерживается одной и той же группой. Так Node вошёл в мир с потенциалом, позволявшим сэкономить массу времени и усилий и (в основном) не изменил своим ключевым обещаниям.
Меня неизменно впечатляет та модель конкурентности, что действует в Node — считаю, что обязан это сказать, просто чтобы меня не обвиняли, будто я ополчился на платформу только лишь потому, что это JavaScript. Мне доводилось работать с командами, годами действовавшими исключительно в пределах Node, о многих из них я могу сказать только самое хорошее. Определённо, есть во мне червячок зависти к ним, сумевшим стать настоящими экспертами в JavaScript и применить этот набор навыков при работе с самым широким инструментарием.
Однако настоящий конёк Node заключается в том, с какой скоростью команда способна создавать сложный функционал, даже если лишь ограниченно разбирается в бекенде. Низкий порог вхождения в NPM означает, что каждый теперь способен взять несколько классов и выставить их во всеобщий доступ в Интернете. Сначала казалось, что это замечательно, разработчики наслаждались тем, как легко у них получаются воспроизводимые сборки, пригодные для самых разных рабочих пространств и машин с NPM.
Но шло время, и эти бесконечные списки зависимостей стали реально обременять специалистов по поддержке, значительно обесцениваясь сами по себе. Из-за акцента на том, что скорость приоритетнее безопасности во всём NPM (и, значит, во всём Node), теперь уже становится опасно рекомендовать эту технологию любому, кому приходится обрабатывать пользовательские данные практически на любых мощностях.
Проблемы NPM
Имея дело с моим первым большим приложением на Node, я ужаснулся, измерив, сколько мне требуется стороннего кода, чтобы написать это приложение. У нас набрался почти миллион строк внешнего кода против нескольких тысяч строк кода в самом нашем приложении. Построить граф всех этих зависимостей было столь же сложно, как раскрыть схему по отмыванию денег. К несчастью, скажем, в тех приложениях на PHP, с которыми мне приходилось работать в прошлом, не было возможности даже попытаться проконтролировать всё множество этих внешних поставщиков. Поскольку все они были обязательны, мы были беззащитны перед любыми проблемами с безопасностью, которые могли возникнуть у любого из них.
Подробно расскажу, как я попытался исправить эту проблему.
Конечно же, я начал с азов, таких, как npm audit — этот инструмент работает, но является чисто реакционным. Он зависит от разработчиков, поддерживающих пакет, сообщающих о проблеме, то есть, от кого-то должна исходить такая инициатива. В мире Python, где я использую, наверное, всего 6 распространённых зависимостей, такой подход целесообразен. Но в мире NPM у меня тысячи зависимостей, и среди них много таких, каждую из которых поддерживает всего один человек, поэтому такой подход непрактичен.
Хорошо, а мы можем проверить каждый пакет, прежде, чем его добавлять? Даже если предположить, что я технически могу оценить каждый пакет, сравнив его с некоторым «гарантированно хорошим» параметром, масштаб этой задачи таков, что для её решения пришлось бы привлечь на фултайм тысячи человек. Взгляните на граф зависимостей только лишь самого NPM, который, напомню, в соответствии со многими руководствами должен вызывать пользователь-администратор.
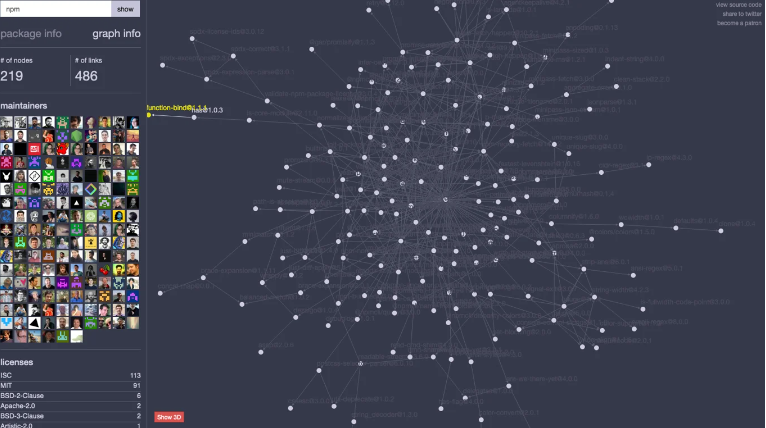 Матерь Божья https://npm.anvaka.com/#/view/2d/npm
Матерь Божья https://npm.anvaka.com/#/view/2d/npm
Ладно, убедили, это неподъёмная задача. Может быть, нам удастся, как минимум, смягчить эту проблему, ограничившись лишь пакетами с заданной областью. Мы, как минимум, знаем, что они поступили из нужной организации, а не возникли из-за опечатки. Оказывается, среди пакетов, наиболее активно скачиваемых из NPM, почти нет тех, у которых задана область. React, lodash, express, список можно продолжать. Список топовых пакетов NPM приведён здесь.
Хорошо, а я могу как-нибудь определить, требует ли конкретный пакет NPM как минимум двухфакторной аутентификации, чтобы его можно было загрузить? Насколько мне известно — нет. Те, кто поддерживает пакет, могут обязывать проведение двухфакторной аутентификации, но я не могу проверить её наличия.
В настоящее время NPM на самом деле серьёзно продвинулся в этом и стремится гарантировать, что пакет не был подделан. Это гарантируется при помощи ECDSA, в чём вы можете сами убедиться на примере https://registry.npmjs.org/underscore/1.13.6 в разделе «signatures»: [{ «keyid»: «SHA256:{{SHA256_PUBLIC_KEY}}», «sig»: «a312b9c3cb4a1b693e8ebac5ee1ca9cc01f2661c14391917dcb111517f72370809…».
Но моя базовая проблема никуда не делась. Да, я могу убедиться, что человек, опубликовавший пакет, его подписал (и это отлично). Но я всё равно импортирую тысячи пакетов. Плюс, подписывание пакетов не является обязательным, и притом, что многие большие пакеты снабжены подписью, у многих её нет.
На практике
Всё это приводит к тому, что приложения Node начинают «гнить» самыми пугающими темпами. Да, такое приложение можно быстро написать и поставить на ноги, но они требуют постоянного мониторинга на предмет проблем с безопасностью, а их деревья зависимостей простираются на тысячи пакетов. Кроме того, вы постоянно вовлекаетесь в конфликты версий при работе со вложенными зависимостями (и с этими конфликтами NPM борется путём вложения). Чтобы ваше приложение Node оставалось пропатчено, вы должны быть готовы переопределять некоторые зависимости пакетов, чтобы прийти к безопасной версии (при этом вы не знаете, будет ли с новой версией функционировать какая-нибудь конкретная зависимость, расположенная уровнем выше).
Следующий паттерн зависимостей типичен для приложения Node:

Вы снова и снова устанавливаете одну и ту же штуку, только её версии немного меняются. Приходится постоянно следить за всем графом зависимостей и проверять наличие заявленных проблем, а затем надеяться и вновь надеяться, что кто-то проверяет за вас все эти вещи в Интернете и сообщает о том, что удалось выявить — как и должен. Наконец, приходится надеяться, что ни у кого из этих специалистов по поддержке их код не угнали, либо что человек попросту не забросил поддержку.
Устойчивая модель Node
Не знаю, что можно сделать для исправления этой проблемы. Подозреваю, отличный вариант был бы таков: обязать, чтобы пространство зависимостей у каждого пакета было «плоским», разрешать только вышестоящие зависимости, а вложенных зависимостей не допускать. Однако, на данном этапе мы эту станцию, кажется, уже проехали.
Если вы стремитесь писать безопасный и долговечный код Node, то, думаю, вас устроит только с пристрастием не допускать в вашу базу кода пакеты, пытаясь максимально обходиться модулями ядра Node, как показано здесь. Хочу похвалить команду NPM за то, что они переключились на более устойчивую систему подписей и надеюсь, что эта практика широко распространится (есть признаки, что так и будет). В остальном приходится надеяться и уповать, что никто из тысяч людей, на которых вы полагаетесь, не решит сегодня подорвать ваше приложение.
Однако, желая продемонстрировать, как быстро приступить к написанию кода Node при помощи NPM, мы обрекли Node — ведь гарантировать долговременную поддержку всего этого хозяйства почти невозможно. Если вы вручную исправляете пакеты с хорошо известными проблемами безопасности, и из-за этого ваши тесты перестают выполняться, вам может предстоять титаническая задача по распутыванию этого клубка и выяснению, что именно в нём изменилось.
Заключение
Все эти технологии в основном приносят реальную, измеримую пользу. Зачастую они превосходят более ранние решения. Но многие организации заблуждаются, углубляясь в туториалы и демки, которые неадекватно отражают реальное практическое использование рассматриваемой технологии, пытаясь, напротив, продавить переход на эту технологию, выставляя её в самых радужных тонах. Я не виню энтузиастов за это, но думаю, что все мы должны быть немного честнее, презентуя новую технологию коллегам.
Обращаясь к тем, кто поддерживает эти технологии, отмечу: в конечном итоге, и ваша, и моя репутация пострадает, если вы заранее не изложите всех сложностей в инструментарии или в документации. В конце концов я подорвусь на этих минах, так почему бы не предупредить меня о них с самого начала? Если в какой-то момент мне придётся переписывать все мои контейнеры, то почему бы не помочь мне сразу всё сделать правильно? Если вы знаете, что мне придётся постоянно патчить мои зависимости NPM, то давайте, может быть, добавим более надёжную цепочку зависимостей, чтобы я мог проверять, что откуда берётся.
В конечном итоге, мы поможем друг другу, став честнее. Я хочу, чтобы вы работали с моим инструментом и извлекали из него максимум пользы, даже если максимально полезно для вас будет отказаться от него.
