Fast-dreambooth. Имба для тонкой настройки StableDiffusion
Всем привет! Для всех кто ищет отправную точку для погружения в мир генеративных нейросетей в этой статье я расскажу как научить StableDiffusion генерировать изображения в вашем стиле. Или даже с вашим лицом.
Подготовка изображений.
StableDiffusion может обучаться на ваших изображениях и первое что вам нужно это подготовить качественные изображения. Я попробовал собрать изображения бельгийского оперного певца Werner Van Mechelen
 Werner Van Mechelen
Werner Van Mechelen
После этого необходимо обрезать изображения до квадрата 512×512 это можно сделать с помощью этого сервиса https://www.birme.net/? target_width=512&target_height=512 Загружаете туда изображения выбираете область кропа и сохраняете как зип файл себе на компьютер.
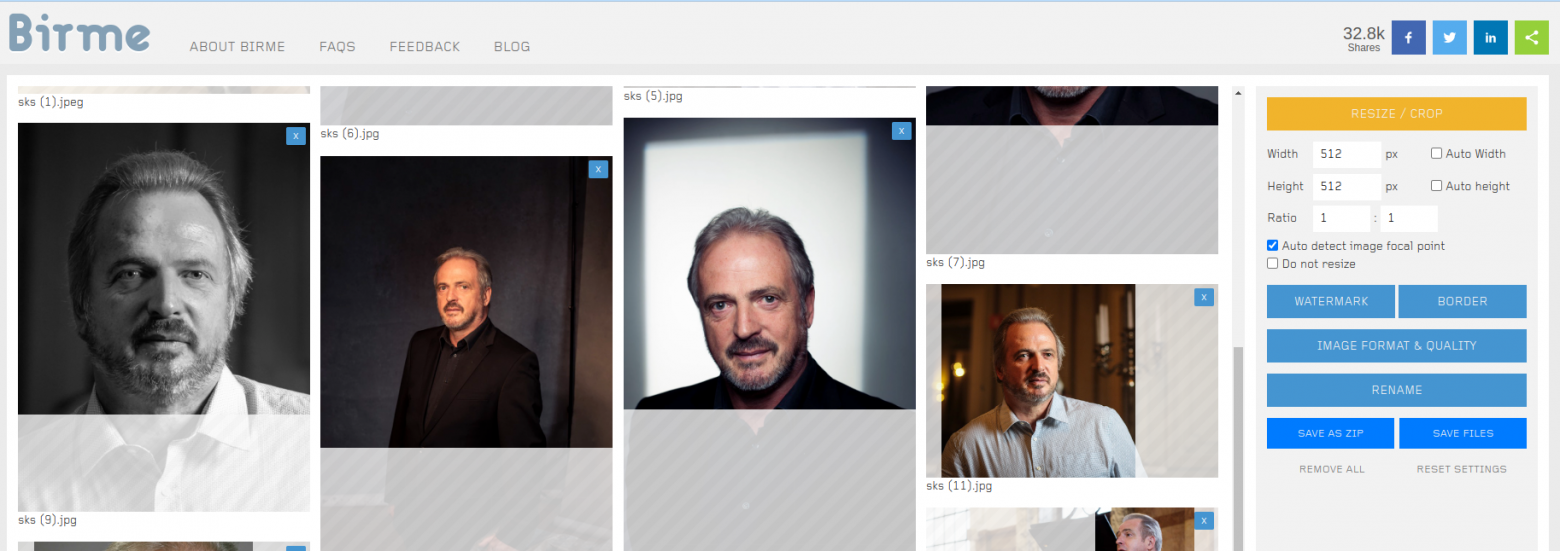 Birme
Birme
Затем нужно переименовать изображения следующим образом. Одинаковое имя + (n) по этому имени вы будете делать запрос к нейросети для генерации вашего изображения. Так что выбирайте то что не занято, что бы не запутать StableDiffusion я использую токен sks.
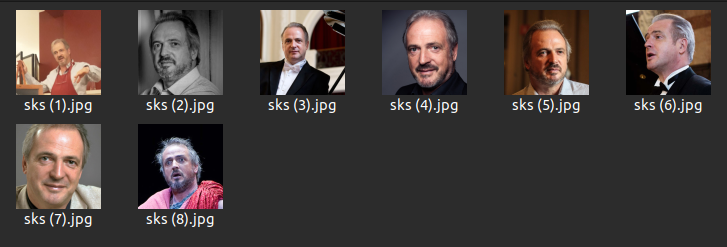 Именование изображений
Именование изображений
Инициализация collab
копируем себе эту версии dreamBooth https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb#scrollTo=O3KHGKqyeJp9
И запускаем эти две ячейки
Дальше нужно выбрать модель и предоставить токен для скачивания модели. Выбираем тут модель версии 1.5. Можете попытать счастье с версией 2, но у меня не запускалось обучение через этот колаб на второй версии модели, вероятно дело в том, что она появилась букавльно несколько дней назад и это ещё не стабильная версия. также вторая версия сложнее в обучения, так что я рекомендую использовать v1.5
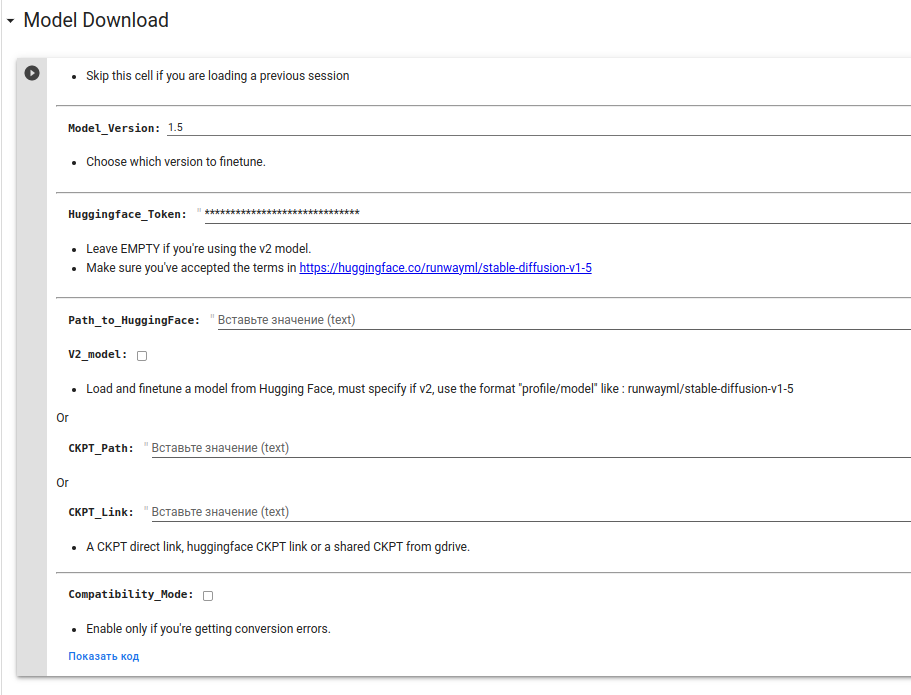
Если нет аккаунта на Hugging Face то создайте его и выпустите себе токен для того что бы колаб смог скачать модель StableDiffusion https://huggingface.co/settings/tokens
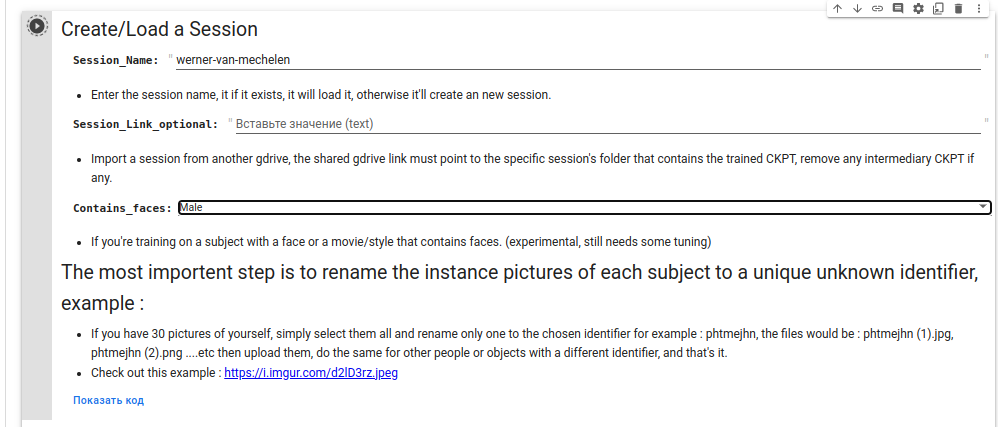
Дальше создаем сессию, на гуглдиске будет создана папка Fast-Dreambooth/Sessions/werner-van-mechelen так же выбираем опцию Contains_faces так как я обучал на фотографиях мужчины, то выбираю Male.
Теперь запускаем ячейку с загрузкой картинок и перетаскиваем туда картинки. После того как картинки будут загружены ячейка будет выполнена.
Теперь нужно запустить обучения и вабрать некоторые параметры
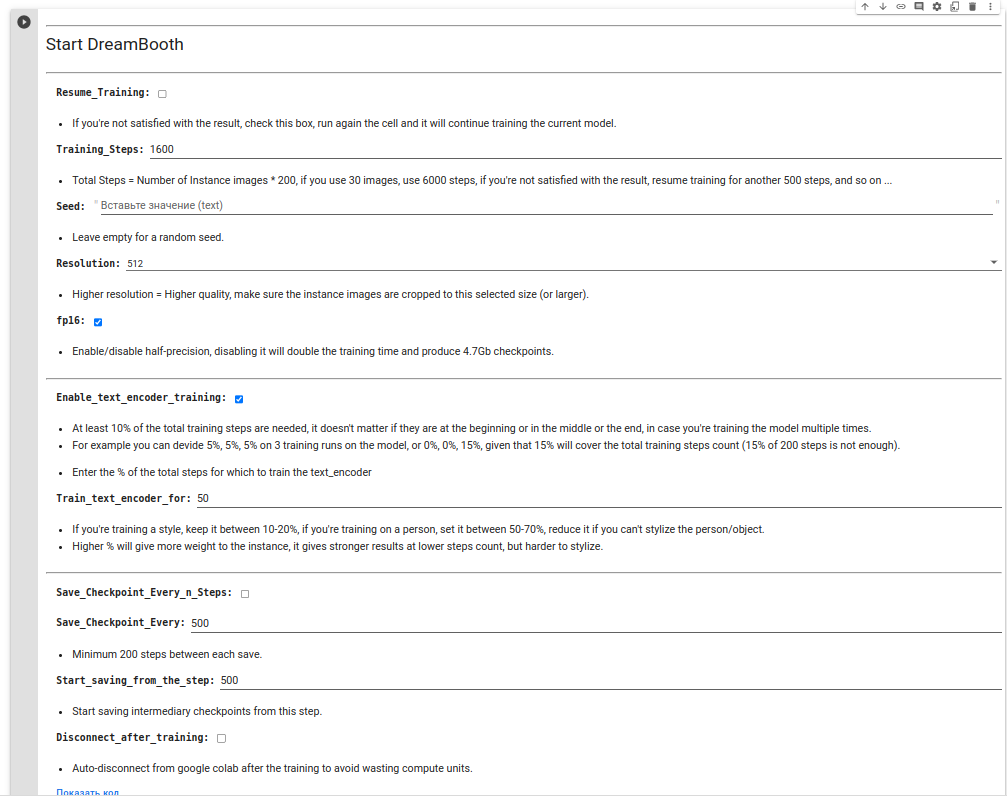
Training_Steps Умножаем количество картинок на 200 и вводим это число. Это будет количество тренировочных шагов.
Resolution 512
fp16 половиная точность, если эта опция включена то задействуется меньше памяти
Enable_text_encoder_training нужно оставить включеным, так обучения тектового энкодера повышает качество результатов.
Train_text_encoder_for выбираем процент сколько шагов будет тренироваться текстовый энкодер. Чем выше процент тем более точно сеть будет повторять входные изображения. Но за счёт этого снижается способность к «стилизации». Чем ниже процент тем проще будет стилизовать ваше изображение.
Save_Checkpoint_Every_n_Steps Не рекомендую включать эту галку, так как это может занять много места на гугл диске.
Ждем пока завершится обучение и запускаем получившеюся модель
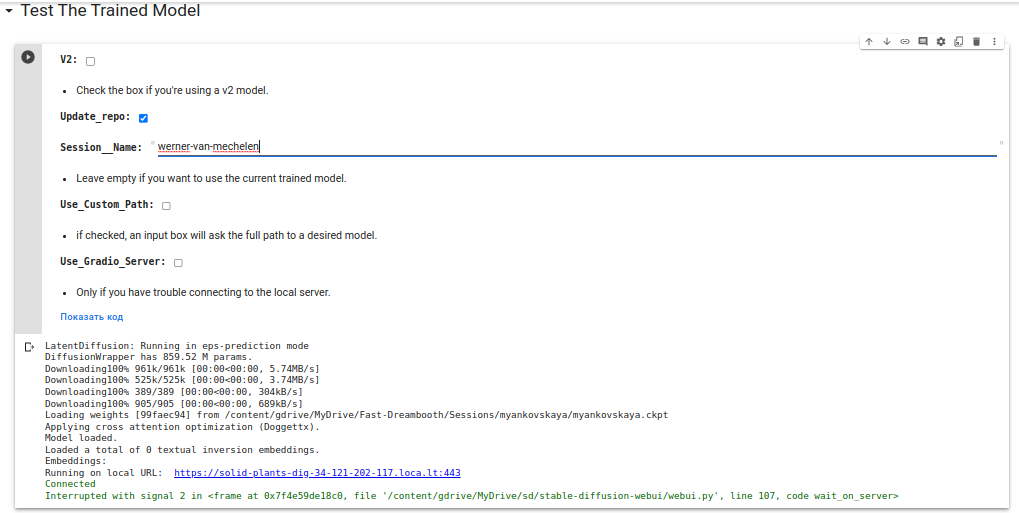
В результате блокнот даст ссылку на следующий интерфейс
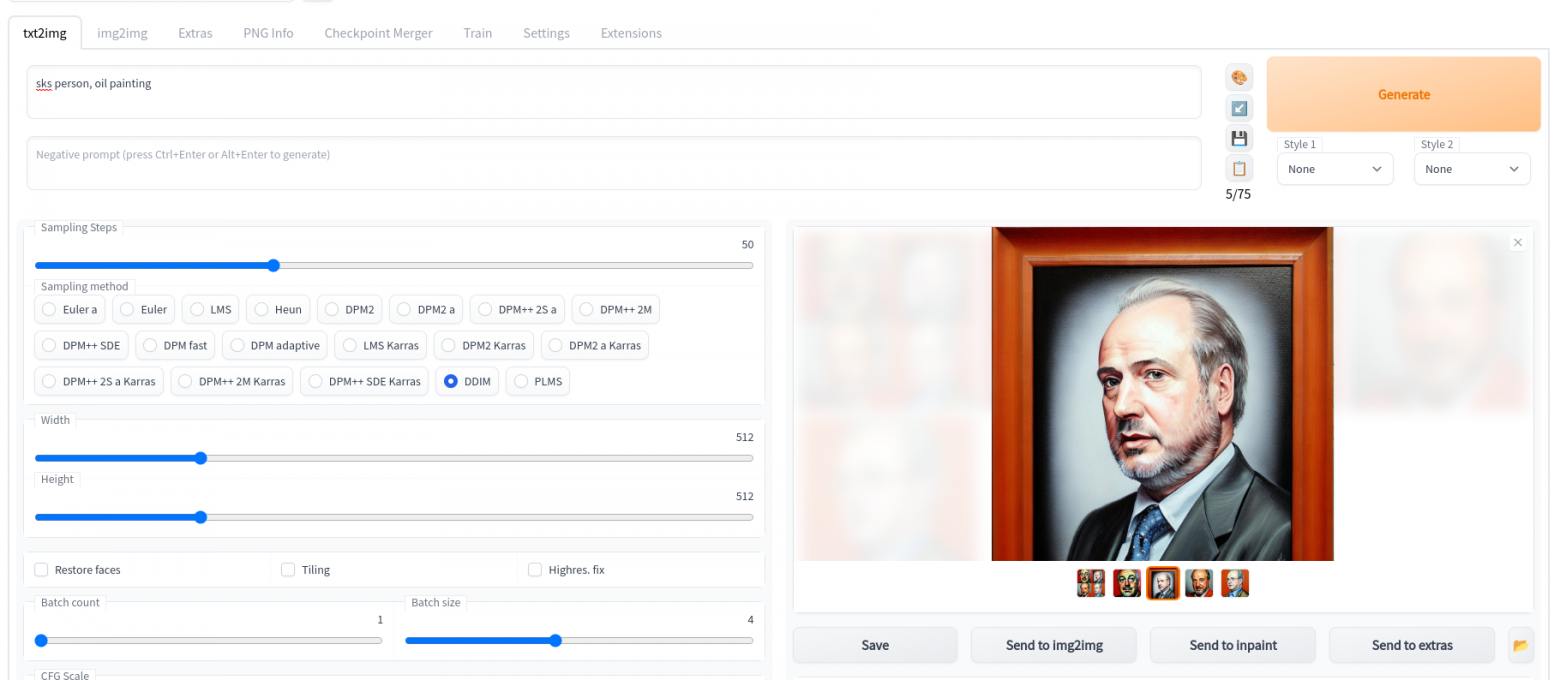
Я смотрю примеры запросов на этом сайте OpenArt тут можно найти какие изображения генерирует сеть по разным запросам и попробовать найти то что вам понравится. Далеко не все изображения удачные, можно поиграться с запросами и просто попробовать выполнить один запрос несколько раз, так как каждый раз вы будете получать разные изображения.
Вот несколько результатов:



Заключение
Этот блокнот предоставляет очень простой интерфейс для обучения сети и вдобавок сеть версии 1.5 обучается очень легко. Процесс обучения для 20 изображений занимает примерно 2–3 часа. По моим наблюдениям легче всего обучить её на лицах и генерировать разные арты персонажа.
