[Перевод] Генерация произвольных реалистичных лиц с помощью ИИ
Контролируемый синтез и редактирование изображений с использованием новой модели TL-GAN
Пример контролируемого синтеза в моей модели TL-GAN (transparent latent-space GAN, генеративно-состязательная сеть с прозрачным скрытым пространством)
Весь код и онлайн-демо доступны на странице проекта.
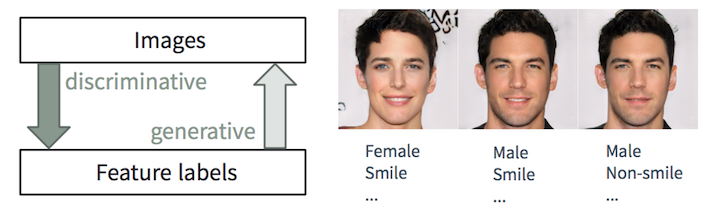
Дискриминантная и генеративные задачи
Человеку легко описать картинку, мы учимся делать это с самого раннего возраста. В машинном обучении это задача дискриминантной классификации/регрессии, т.е. предсказание признаков по входным изображениям. Последние достижения в методах ML/AI, особенно в моделях глубокого обучения, начинают преуспевать в этих задачах, иногда достигая или превосходя способности человека, как показано в задачах вроде визуального распознавания объектов (например, от AlexNet до ResNet по классификации ImageNet) и обнаружения/сегментации объектов (например, от RCNN до YOLO в наборе данных COCO) и т.д.
Тем не менее, обратная задача создания реалистичных изображений по описанию намного сложнее и требует многолетнего обучения графическому дизайну. В машинном обучении это генеративная задача, которая гораздо более сложна, чем дискриминационные задачи, так как генеративная модель должна генерировать намного больше информации (например, полное изображение на некотором уровне детализации и вариации) на основе меньших исходных данных.
Несмотря на сложность создания таких приложений, генеративные модели (с некоторым управлением) чрезвычайно полезны во многих случаях:
- Создание контента: представьте, что рекламная компания автоматически создаёт привлекательные образы, которые соответствуют содержанию и стилю веб-страницы, где вставляются эти картинки. Дизайнер ищет вдохновение, приказывая алгоритму сгенерировать 20 образцов обуви, связанных с признаками «отдых», «лето» и «страстный». Новая игра позволяет генерировать реалистичные аватары по простому описанию.
- Умное редактирование с учётом контента: фотограф меняет выражение лица, количество морщин и причёску на фотографии в несколько щелчков мыши. Художник голливудской студии преобразует кадры, снятые в облачный вечер, как будто они сделаны ярким утром, с солнечным светом с левой стороны экрана.
- Аугментация данных: разработчик беспилотных автомобилей может синтезировать реалистичные видео для определённого сценария аварии с целью увеличить набор данных обучения. Банк может синтезировать данные о мошенничестве определённого типа, слабо представленные в существующем наборе данных, чтобы улучшить антифродовую систему.
В этой статье расскажем о нашей недавней работе под названием Transparent Latent-space GAN (TL-GAN), которая расширяет функциональность самых современных моделей, обеспечивая новый интерфейс. В настоящее время мы работаем над документом, в котором будет больше технических деталей.
Сообщество глубокого обучения быстро совершенствует генеративные модели. Среди них можно выделить три перспективных типа: авторегрессионные модели, вариационные автоэнкодеры (VAE) и генеративные состязательные сети (GAN), показанные на рисунке ниже. Если вам интересны подробности, пожалуйста, можете прочитать отличную статью в блоге OpenAI.

Сравнение генеративных сетей. Изображение из курса STAT946F17 в Университете Ватерлоо
На данный момент самые качественные изображения генерируют сети GAN (фотореалистичные и разнообразные, с убедительными деталями в высоком разрешении). Посмотрите на потрясающие изображения, созданные сетью pg-GAN (прогрессивно растущая GAN) от Nvidia. Поэтому в данной статье мы сосредоточимся на моделях GAN.

Синтетические картинки, сгенерированные сетью pg-GAN от Nvidia. Ни одно из изображений не имеет отношения к реальности

Случайная и управляемая генерация изображений
Оригинальная версия GAN и многие популярные модели на её основе (такие как DC-GAN и pg-GAN) являются моделями обучения без учителя. После обучения генеративная нейросеть принимает в качестве входных данных случайный шум и создаёт фотореалистичное изображение, которое едва отличимо от обучающего набора данных. Тем не менее, мы не можем дополнительно контролировать особенности генерируемых изображений. В большинстве приложений (например, в сценариях, описанных в первом разделе) пользователи хотели бы создавать образцы с произвольными признаками (например, возраст, цвет волос, выражение лица и т.д.) В идеале, плавно настраивать каждую функцию.
Для такого управляемого синтеза созданы многочисленные варианты GAN. Их можно условно разделить на два типа: сети переноса стиля и генераторы по условию (conditional generators).
Сети переноса стиля
Сети переноса стиля CycleGAN и pix2pix обучены переводить изображение из одной области (домена) в другую: например, от лошади к зебре, от эскиза к цветным изображениям. В результате мы не можем плавно изменять конкретный признак между двумя дискретными состояниями (например. добавить немножко бороды на лице). Кроме того, одна сеть предназначена для одного типа передачи, поэтому для настройки десяти функций потребуется десять разных нейронных сетей.
Генераторы по условию
Условные генераторы — условные GAN, AC-GAN и Stack-GAN — в процессе обучения одновременно изучают изображения и метки объектов, что позволяет генерировать изображения с настройкой признаков. Когда вы хотите добавить новые признаки в процесс генерации, нужно переобучить всю модель GAN, что требует огромных вычислительных ресурсов и времени (например, от нескольких дней до недель на одном графическом процессоре K80 с идеальным набором гиперпараметров). Кроме того, для выполнения обучения необходимо полагаться на один набор данных, содержащий все пользовательские метки объектов, а не использовать разные метки из нескольких наборов данных.
Наша генеративно-состязательная сеть с прозрачным скрытым пространством (Transparent Latent-space GAN, TL-GAN) использует иной подход для управляемой генерации — и решает перечисленные проблемы. Она предлагает возможность плавно настраивать один или несколько признаков с помощью одной сети. Кроме того, можно эффективно добавить новые настраиваемые признаки менее чем за один час.
Делаем это таинственное прозрачное скрытое пространство
Возьмём модель pg-GAN от Nvidia, которая генерирует фотореалистичные изображения лиц с высоким разрешением, как показано в предыдущем разделе. Все признаки сгенерированного изображения 1024×1024 px определяются исключительно 512-размерным вектором шума в скрытом пространстве (как низкоразмерное представление содержимого изображения). Поэтому, если понять, что представляет собой скрытое пространство (т.е. сделать его прозрачным), то можно полностью контролировать процесс генерации.

Мотивация TL-GAN: понять скрытое пространство для управления процессом генерации
Экспериментируя с предварительно обученной сетью pg-GAN, я обнаружил, что у скрытого пространства на самом деле два хороших свойства:
- Оно хорошо заполнено, то есть большинство точек в пространстве генерируют разумные изображения.
- Оно достаточно непрерывно, то есть интерполяция между двумя точками в скрытом пространстве обычно приводит к плавному переходу соответствующих изображений.
Интуиция говорит, что в скрытом пространстве есть направления, которые предсказывают нужные нам признаки (например, мужчина/женщина). Если так, то единичные векторы этих направлений станут осями для управления процессом генерации (более мужское или более женское лицо).
Подход: раскрытие осей пространственных объектов
Чтобы найти в скрытом пространстве эти оси признаков, построим связь между скрытым вектором  и метками признаков
и метками признаков  при помощи обучения с учителем на парах
при помощи обучения с учителем на парах  . Теперь проблема в том, как получить эти пары, поскольку существующие наборы данных содержат только изображения
. Теперь проблема в том, как получить эти пары, поскольку существующие наборы данных содержат только изображения  и соответствующие им метки объектов .
и соответствующие им метки объектов .
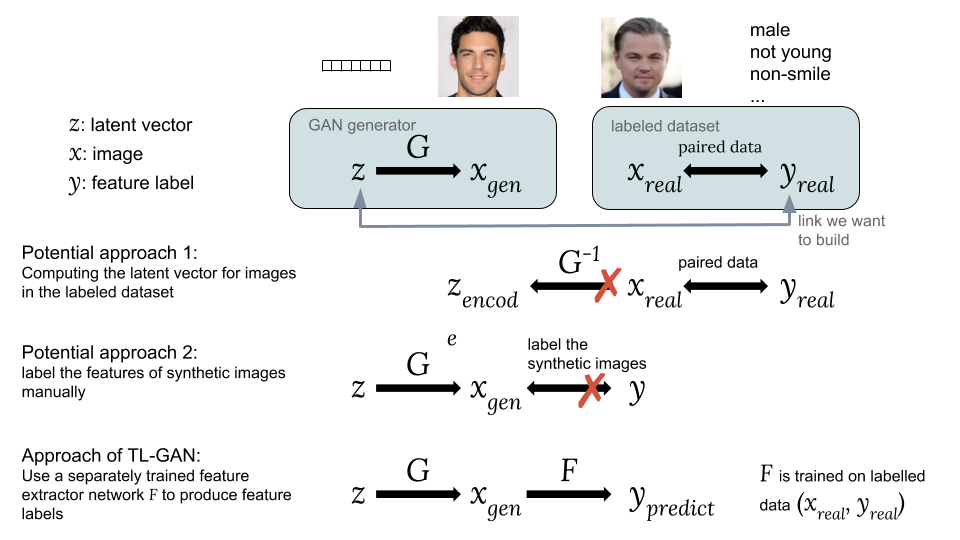
Способы связать скрытый вектор z с меткой признака y
Возможные подходы:
Один из вариантов — вычислить соответствующие скрытые векторы изображений  из существующего набора данных с интересующими нас метками
из существующего набора данных с интересующими нас метками  . Однако сеть GAN не даёт простого способа вычисления
. Однако сеть GAN не даёт простого способа вычисления  , что затрудняет реализацию этой идеи.
, что затрудняет реализацию этой идеи.
Второй вариант заключается в генерации синтетических изображений  , используя GAN из случайного скрытого вектора как
, используя GAN из случайного скрытого вектора как  . Проблема в том, что синтетические изображения не помечены, поэтому трудно использовать доступный набор помеченных данных.
. Проблема в том, что синтетические изображения не помечены, поэтому трудно использовать доступный набор помеченных данных.
Главное новшество нашей модели TL-GAN — обучение отдельного экстрактора (классификатор для дискретных меток или регрессор для непрерывных) с моделью  , используя существующий набор помеченных данных (, ), а потом запуск в связке обученного GAN-генератора
, используя существующий набор помеченных данных (, ), а потом запуск в связке обученного GAN-генератора  с сетью извлечения признаков
с сетью извлечения признаков  . Это позволяет предсказать метки признаков
. Это позволяет предсказать метки признаков  синтетических изображений с помощью обученной сети извлечения признаков (экстрактора). Таким образом посредством синтетических изображений устанавливается связь между и как и
синтетических изображений с помощью обученной сети извлечения признаков (экстрактора). Таким образом посредством синтетических изображений устанавливается связь между и как и  .
.
Теперь у нас есть парный скрытый вектор и признаки. Можно обучить модель регрессора  , чтобы раскрыть все оси признаков для управления процессом генерации изображений.
, чтобы раскрыть все оси признаков для управления процессом генерации изображений.
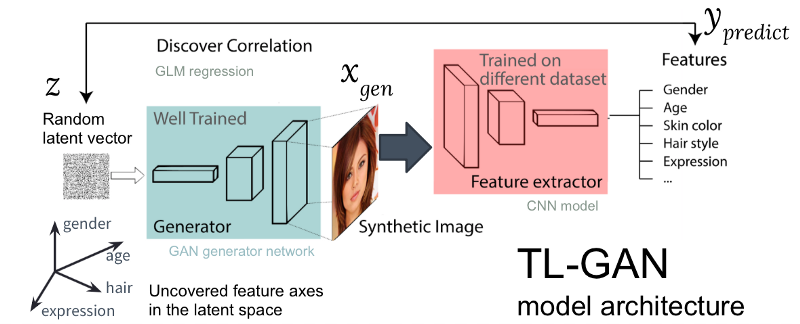
Рисунок: архитектура нашей модели TL-GAN
На приведённом выше рисунке показана архитектура модели TL-GAN, которая содержит пять шагов:
- Изучение распределения. Выбираем хорошо обученную модель GAN и генеративную сеть. Я взял хорошо обученную pg-GAN (от Nvidia), которая обеспечивает наилучшее качество генерации лиц.
- Классификация. Выбираем предварительно обученную модель извлечения признаков (экстрактор может быть свёрточной нейросетью или другими моделями компьютерного зрения) или обучить собственный экстрактор с помощью набора помеченных данных. Я обучил простую свёрточную нейросеть на наборе CelebA (более 30 000 лиц с 40 метками).
- Генерация. Создаём нескольких случайных скрытых векторов, пропускаем через обученный генератор GAN для создания синтетических изображений, затем используем обученный экстрактор признаков для генерации признаков на каждом изображении.
- Корреляция. Используем обобщённую линейную модель (GLM) для осуществления регрессии между скрытыми векторами и признаками. Наклон линии регрессии становится осями признаков.
- Исследование. Начинаем с одного скрытого вектора, перемещаем его вдоль одной или нескольких осей признаков и изучаем, как это влияет на генерацию картинок.
Я значительно оптимизировал процесс: на предварительно обученной модели GAN идентификация осей пространственных объектов занимает всего час на машине с одним GPU. Это достигается за счёт нескольких инженерных хитростей, включая перенос обучения, уменьшение размера картинок, предварительное кэширование синтетических изображений и т.д.
Посмотрим, как работает эта простая идея.
Перемещение скрытого вектора вдоль осей объектов
Сначала я проверил, можно ли использовать обнаруженные оси признаков для управления соответствующим признаком сгенерированного изображения. Для этого создаём случайный вектор  в скрытом пространстве GAN и генерируем синтетическое изображение
в скрытом пространстве GAN и генерируем синтетическое изображение  , пропуская его через генеративную сеть
, пропуская его через генеративную сеть  . Затем перемещаем скрытый вектор вдоль одной оси признаков
. Затем перемещаем скрытый вектор вдоль одной оси признаков  (единичный вектор в скрытом пространстве, скажем, соответствующий полу лица) на расстояние
(единичный вектор в скрытом пространстве, скажем, соответствующий полу лица) на расстояние  , в новое положение
, в новое положение  и генерируем новое изображение
и генерируем новое изображение  . В идеале, соответствующий признак нового изображения должен измениться в ожидаемом направлении.
. В идеале, соответствующий признак нового изображения должен измениться в ожидаемом направлении.
Результаты перемещения вектора вдоль нескольких осей признаков (пол, возраст и т.д.) представлены ниже. Это работает на удивление хорошо! Можно плавно трансформировать изображение между мужчиной/женщиной, юношей/стариком и т.д.

Первые результаты перемещения скрытого вектора вдоль запутанных осей признаков
Распутывание коррелированных осей признаков
В примерах выше виден недостаток исходного метода, а именно cпутанные оси признаков. Например, когда нужно уменьшить растительность на лице, сгенерированные лица становятся более женственными, что не является ожидаемым результатом. Проблема связана с тем, что пол и борода по своей природе коррелируют. Изменение одного признака приводит к изменению другого. Подобное случалось и с другими функциями, такими как причёска и кучерявость. Как показано на рисунке ниже, исходная ось признака «борода» в скрытом пространстве не перпендикулярна оси «пол».
Для решения проблемы я использовал приёмы простой линейной алгебры. В частности, проецировал ось бороды на новое направление, ортогональное оси пола, что эффективно устраняет их корреляцию и, таким образом, может потенциально распутать эти два признака на генерируемых лицах.
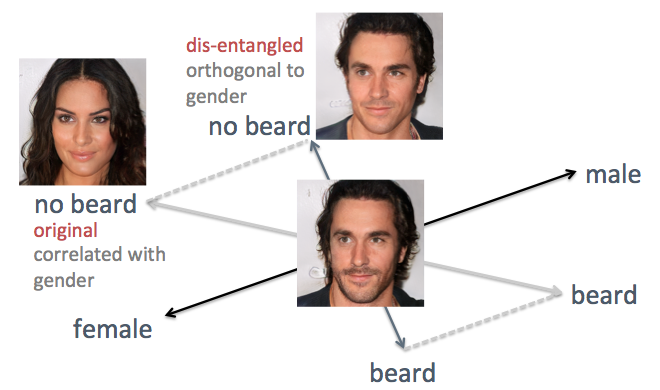
Распутывание скоррелированных осей признаков приёмами линейной алгебры
Я применил этот метод к тому же лицу. На этот раз оси пола и возраста выбраны опорными, проецируя все остальные оси так, чтобы они стали ортогональными полу и возрасту. Лица генерируются с перемещением скрытого вектора вдоль вновь сгенерированных осей признаков (показано на рисунке ниже). Как и ожидалось, теперь признаки вроде причёски и бороды не влияют на пол.

Улучшенный результат перемещения скрытого вектора вдоль распутанных осей признаков
Гибкое интерактивное редактирование
Чтобы посмотреть, насколько гибко наша модель TL-GAN способна управлять процессом генерации изображений, я создал интерактивный графический интерфейс с плавным изменением значений объектов по различным осям, как показано ниже.
Интерактивное редактирование с помощью TL-GAN
И опять модель работает на удивление хорошо, если изменять изображения по осям признаков!
Этот проект демонстрирует новый метод управления генеративной моделью без учителя, такой как GAN (generative adversarial network). Используя заранее хорошо обученный генератор GAN (pg-GAN от Nvidia), я сделал его скрытое пространство прозрачным, проявив оси значимых признаков. Когда вектор перемещается вдоль такой оси в скрытом пространстве, соответствующее изображение трансформируется вдоль этого признака, обеспечивая управляемый синтез и редактирование.
Этот метод имеет явные преимущества:
- Эффективность: чтобы добавить новый тюнер признаков для генератора, не нужно повторно обучать модель GAN, поэтому добавление тюнеров для 40 признаков занимает менее часа.
- Гибкость: можно использовать любой экстрактор признаков, обученный на любом наборе данных, добавляя больше признаков в хорошо обученный GAN.
Пару слов об этике
Данная работа позволяет детально управлять генерацией изображений, но она по-прежнему в значительной степени зависит от особенностей набора данных. Обучение на фотографиях голливудских звёзд означает, что модель будет очень хорошо генерировать фотографии преимущественно белых и привлекательных людей. Это приведёт к тому, что пользователи смогут создавать лица, представляющие только небольшую часть человечества. Если развернуть этот сервис как реальное приложение, то желательно расширить исходный набор данных, чтобы учесть разнообразие наших пользователей.
Хотя инструмент может сильно помочь в креативном процессе, нужно помнить о возможностях его использования в неблаговидных целях. Если мы создаём реалистичные лица любого типа, то в какой степени можно доверять лицу, которое мы видим на экране? Сегодня важно обсудить вопросы такого рода. Как мы видели на недавних примерах применения техники Deepfake, ИИ быстро прогрессирует, поэтому человечеству жизненно важно начать обсуждение, как лучше всего разворачивать такие приложения.
Весь код и онлайн-демо этой работы доступны на странице GitHub.
Если хотите поиграть с моделью в браузере
Вам не нужно загружать код, модель или данные. Просто следуйте инструкциям из этого раздела Readme. Вы cможете изменять лица в браузере, как показано на видео.
Если хотите попробовать код
Просто зайдите на страницу Readme репозитория GitHub. Код собран на Anaconda Python 3.6 с Tensorflow и Keras.
Если хотите внести свой вклад
Добро пожаловать! Не стесняйтесь отправить пул-реквест или сообщить о проблеме на GitHub.
Обо мне
Недавно я получил PhD в области вычислительной и когнитивной нейробиологии в Брауновском университете и степень магистра в области компьютерных наук, со специализацией по машинному обучению. В прошлом я изучал, как нейроны в мозге коллективно обрабатывают информацию для достижения таких функций высокого уровня, как зрительное восприятие. Мне нравится алгоритмический подход к анализу, имитации и реализации интеллекта, а также к применению ИИ для решения сложных проблем реального мира. Я активно ищу вакансию исследователя ML/AI в технологической индустрии.
Благодарности
Эта работа сделана за три недели как проект для стипендиальной программы InSight AI. Благодарю директора программы Эммануэля Амайзена и Мэтта Рубашкина за общее руководство, особенно Эммануэля за его предложения и редактирование статьи. Также выражаю благодарность всем сотрудникам Insight за отличную среду обучения и другим участникам программы Insight AI, у которых я многому научился. Особая благодарность Рубин Ся за многочисленные наводки и вдохновение, когда я решал, в каком направлении развивать проект, и за огромную помощь в структурировании и редактировании этой статьи.
