[Перевод] Форматы файлов в больших данных: краткий ликбез

Weather Deity by Remarin
Команда Mail.ru Cloud Solutions предлагает перевод статьи инженера Рахула Бхатии из компании Clairvoyant о том, какие есть форматы файлов в больших данных, какие самые распространенные функции форматов Hadoop и какой формат лучше использовать.
Зачем нужны разные форматы файлов
Серьезное узкое место в производительности приложений с поддержкой HDFS, таких как MapReduce и Spark — время поиска, чтения, а также записи данных. Эти проблемы усугубляются трудностями в управлении большими наборами данных, если у нас не фиксированная, а эволюционирующая схема, или присутствуют некие ограничения на хранение.
Обработка больших данных увеличивает нагрузку на подсистему хранения — Hadoop хранит данные избыточно для достижения отказоустойчивости. Кроме дисков, нагружаются процессор, сеть, система ввода-вывода и так далее. По мере роста объема данных увеличивается и стоимость их обработки и хранения.
Различные форматы файлов в Hadoop придуманы для решения именно этих проблем. Выбор подходящего формата файла может дать некоторые существенные преимущества:
- Более быстрое время чтения.
- Более быстрое время записи.
- Разделяемые файлы.
- Поддержка эволюции схем.
- Расширенная поддержка сжатия.
Одни форматы файлов предназначены для общего использования, другие для более специфических вариантов, а некоторые разработаны с учетом конкретных характеристик данных. Так что выбор действительно довольно большой.
Формат файлов Avro
Для сериализации данных широко используют Avro — это основанный на строках, то есть строковый, формат хранения данных в Hadoop. Он хранит схему в формате JSON, облегчая ее чтение и интерпретацию любой программой. Сами данные лежат в двоичном формате, компактно и эффективно.
Система сериализации Avro нейтральна к языку. Файлы можно обрабатывать разными языками, в настоящее время это C, C++, C#, Java, Python и Ruby.
Ключевой особенностью Avro является надежная поддержка схем данных, которые изменяются с течением времени, то есть эволюционируют. Avro понимает изменения схемы — удаление, добавление или изменение полей.
Avro поддерживает разнообразные структуры данных. Например, можно создать запись, которая содержит массив, перечислимый тип и подзапись.
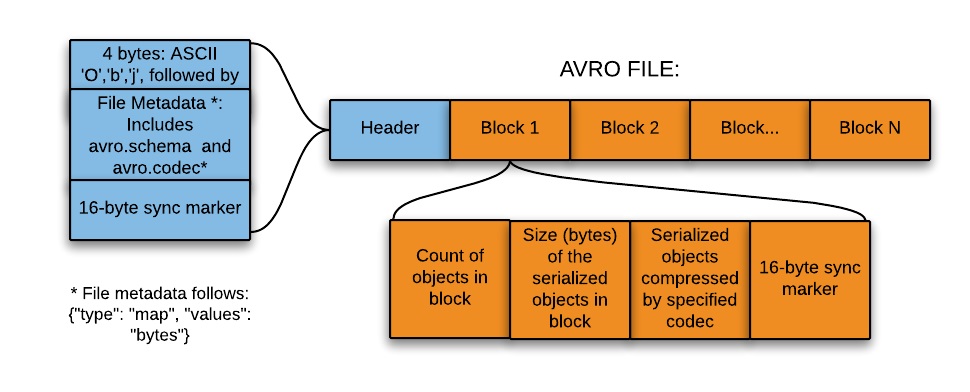
Этот формат идеально подходит для записи в посадочную (переходную) зону озера данных (озеро данных, или data lake — коллекция инстансов для хранения различных типов данных в дополнение непосредственно к источникам данных).
Так вот, для записи в посадочную зону озера данных такой формат лучше всего подходит по следующим причинам:
- Данные из этой зоны обычно считываются целиком для дальнейшей обработки нижестоящими системами — и формат на основе строк в этом случае более эффективен.
- Нижестоящие системы могут легко извлекать таблицы схем из файлов — не нужно хранить схемы отдельно во внешнем мета-хранилище.
- Любое изменение исходной схемы легко обрабатывается (эволюция схемы).
Формат файлов Parquet
Parquet — опенсорсный формат файлов для Hadoop, который хранит вложенные структуры данных в плоском столбчатом формате.
По сравнению с традиционным строчным подходом, Parquet более эффективен с точки зрения хранения и производительности.
Это особенно полезно для запросов, которые считывают определенные столбцы из широкой (со многими столбцами) таблицы. Благодаря формату файлов читаются только необходимые столбцы, так что ввод-вывод сводится к минимуму.
Небольшое отступление-пояснение: чтобы лучше понять формат файла Parquet в Hadoop, давайте посмотрим, что такое основанный на столбцах — то есть столбчатый — формат. В таком формате вместе хранятся однотипные значения каждого столбца.
Например, запись включает поля ID, Name и Department. В этом случае все значения столбца ID будут храниться вместе, как и значения столбца Name и так далее. Таблица получит примерно такой вид:
В строковом формате данные сохранятся следующим образом:
В столбчатом формате файлов те же данные сохранятся так:
Столбчатый формат более эффективен, когда вам нужно запросить из таблицы несколько столбцов. Он прочитает только необходимые столбцы, потому что они находятся по соседству. Таким образом, операции ввода-вывода сводятся к минимуму.
Например, вам нужен только столбец NAME. В строковом формате каждую запись в наборе данных нужно загрузить, разобрать по полям, а затем извлечь данные NAME. Столбчатый формат позволяет перейти непосредственно к столбцу Name, так как все значения для этого столбца хранятся вместе. Не придется сканировать всю запись.
Таким образом, столбчатый формат повышает производительность запросов, поскольку для перехода к требуемым столбцам требуется меньше времени поиска и сокращается количество операций ввода-вывода, ведь происходит чтение только нужных столбцов.
Одна из уникальных особенностей Parquet заключается в том, что в таком формате он может хранить данные с вложенными структурами. Это означает, что в файле Parquet даже вложенные поля можно читать по отдельности без необходимости читать все поля во вложенной структуре. Для хранения вложенных структур Parquet использует алгоритм измельчения и сборки (shredding and assembly).
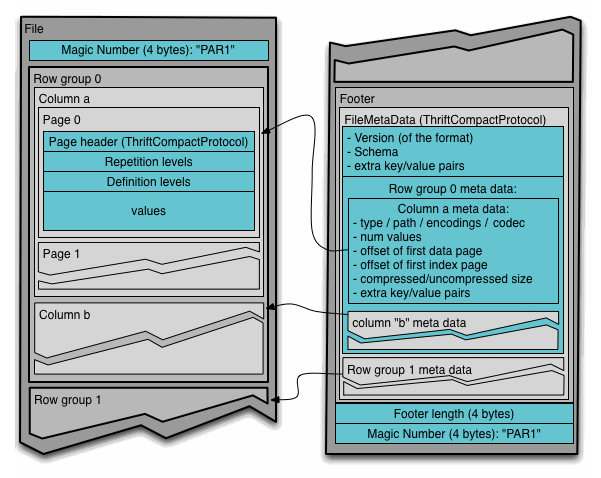
Чтобы понять формат файла Parquet в Hadoop, необходимо знать следующие термины:
- Группа строк (row group): логическое горизонтальное разбиение данных на строки. Группа строк состоит из фрагмента каждого столбца в наборе данных.
- Фрагмент столбца (column chunk): фрагмент конкретного столбца. Эти фрагменты столбцов живут в определенной группе строк и гарантированно будут смежными в файле.
- Страница (page): фрагменты столбцов делятся на страницы, записанные друг за другом. У страниц общий заголовок, так что при чтении можно пропустить ненужные.

Здесь заголовок просто содержит волшебное число PAR1 (4 байта), которое идентифицирует файл как файл формата Parquet.
В футере записано следующее:
- Метаданные файла, которые содержат стартовые координаты метаданных каждого столбца. При чтении нужно сначала прочитать метаданные файла, чтобы найти все интересующие фрагменты столбцов. Затем фрагменты столбцов следует читать последовательно. Еще метаданные включают версию формата, схему и любые дополнительные пары ключ-значение.
- Длина метаданных (4 байта).
- Волшебное число PAR1 (4 байта).
Формат файлов ORC
Оптимизированный строково-столбчатый формат файлов (Optimized Row Columnar, ORC) предлагает очень эффективный способ хранения данных и был разработан, чтобы преодолеть ограничения других форматов. Хранит данные в идеально компактном виде, позволяя пропускать ненужные детали — при этом не требует построения больших, сложных или обслуживаемых вручную индексов.
Преимущества формата ORC:
- Один файл на выходе каждой задачи, что уменьшает нагрузку на NameNode (узел имен).
- Поддержка типов данных Hive, включая DateTime, десятичные и сложные типы данных (struct, list, map и union).
- Одновременное считывание одного и того же файла разными процессами RecordReader.
- Возможность разделения файлов без сканирования на наличие маркеров.
- Оценка максимально возможного выделения памяти кучи на процессы чтения/записи по информации в футере файла.
- Метаданные сохраняются в бинарном формате сериализации Protocol Buffers, который позволяет добавлять и удалять поля.

ORC хранит коллекции строк в одном файле, а внутри коллекции строчные данные хранятся в столбчатом формате.
Файл ORC хранит группы строк, которые называются полосами (stripes) и вспомогательную информацию в футере файла. Postscript в конце файла содержит параметры сжатия и размер сжатого футера.
По умолчанию размер полосы составляет 250 МБ. За счет полос такого большого размера чтение из HDFS выполняется более эффективно: большими непрерывными блоками.
В футере файла записан список полос в файле, количество строк на полосу и тип данных каждого столбца. Там же записано результирующее значение count, min, max и sum по каждому столбцу.
Футер полосы содержит каталог местоположений потока.
Строчные данные используются при сканировании таблиц.
Индексные данные включают минимальные и максимальные значения для каждого столбца и позиции строк в каждом столбце. Индексы ORC используются только для выбора полос и групп строк, а не для ответа на запросы.
Сравнение разных форматов файлов
Avro по сравнению с Parquet
- Avro — формат хранения по строкам, тогда как Parquet хранит данные по столбцам.
- Parquet лучше подходит для аналитических запросов, то есть операции чтения и запрос данных гораздо эффективнее, чем запись.
- Операции записи в Avro выполняются эффективнее, чем в Parquet.
- Avro более зрело работает с эволюцией схем. Parquet поддерживает только добавление схемы, а в Avro реализована многофункциональная эволюция, то есть добавление или изменение столбцов.
- Parquet идеально подходит для запроса подмножества столбцов в многоколоночной таблице. Avro подходит для операций ETL, где мы запрашиваем все столбцы.
ORC по сравнению с Parquet
- Parquet лучше хранит вложенные данные.
- ORC лучше приспособлен к проталкиванию предикатов (predicate pushdown).
- ORC поддерживает свойства ACID.
- ORC лучше сжимает данные.
Что еще почитать по теме:
- Анализ больших данных в облаке: как компании стать дата-ориентированной.
- Скромное руководство по схемам баз данных.
- Наш телеграм-канал о цифровой трансформации.
