[Перевод] Эволюция облачной системы авторизации

Краткий обзор истории развития принципов авторизации — начиная с локального использования идентификаторов и паролей, заканчивая современными предложениями облачных сервисов. В статье разбираются основные переходные этапы на этом пути, а также приводятся примеры передовых решений, реализованных крупнейшими платформами интернета.
Аутентификация в эпоху SaaS и облачных сервисов
Для начала разберём различие между аутентификацией и авторизацией. Несмотря на то, что многие склонны эти понятия смешивать, они представляют собой два различных процесса.
Аутентификация подразумевает подтверждение достоверности того, что вы являетесь тем, кем представились. В прошлом для этого использовались ID и пароли. Сегодня же более популярным способом стало применение магических ссылок, мульти-факторной аутентификации и прочих методов, хотя, по сути, процесс не изменился.
Раньше за аутентификацию отвечала операционная система, авторизующая пользователя после предоставления пароля. Однако в течение последних 15 лет по мере перехода в эпоху SaaS и облачных структур, это изменилось. В первом поколении облачных и SaaS-приложений этот процесс пришлось изобретать заново, поскольку здесь у нас уже не было операционной системы, которая бы проверяла подлинность пользователя.
За эти 15 лет представители индустрии совместными усилиями разработали стандарты аутентификации вроде OAuth2, OpenID connect и SAML. Мы также начали использовать JWT и прочие инструменты. Сегодня никому уже не нужно создавать систему авторизации, если он сам того не захочет, поскольку на то существует множество сервисов.
В целом можно сказать, что мы успешно перенесли проверку подлинности пользователей из локальных сред в сферу облачных SaaS-решений.
А вот авторизация в облако не переехала. По своей сути, авторизация, иначе называемая контроль доступа, подразумевает определение, что вам дозволено видеть и делать после входа в учётную запись. В отличие от аутентификации эта задача ещё далеко не решена.
Проблема в том, что для авторизации не существует единых стандартов индустрии. Вы можете применять некие модели вроде контроля доступа на основе ролей (RBAC) или атрибутов (ABAC), но стандартов здесь нет, поскольку авторизация — это задача, решаемая в различных предметных областях. В этой сфере также не существует каких-либо специализированных разработчиков или сервисов. Вот вы можете представить себе использование для авторизации Twilio или Stripe? А поскольку не существует ни стандартов, ни заточенных под это сервисов, компании теряют гибкость из-за необходимости тратить время на создание собственных систем авторизации, преодолевая все сопряжённые с этим трудности.
Здесь также необходимо учитывать затраты. Во сколько вам обойдётся время, которое вы будете вынуждены вложить не в наращивание предлагаемой вашим бизнесом ценности, а в разработку и обслуживание собственной системы контроля доступа? А когда компании берутся реализовывать это самостоятельно, то зачастую получается у них это не особо удачно. Именно поэтому слабые места в системах контроля доступа лидируют в списке 10 наиболее распространённых уязвимостей, составленном открытым проектом по обеспечению безопасности веб-приложений (OWASP).
Похоже, что мы сами забрались в очень глубокую кроличью нору, откуда теперь нам предстоит усердно выбираться.
Облачная авторизация
Давайте разберём, как мы вообще к этому пришли. Всего произошло три перехода, которые повлияли на мир ПО в целом и на технологии авторизации в частности:
- Переход к SaaS: этот переход успешно прошла аутентификация, но не контроль доступа. Если попытаться понять, почему, то мы увидим, что в прошлом, когда приложения взаимодействовали лишь с ОС, у нас был каталог вроде LDAP. В этом каталоге находились группы, по которым распределялись пользователи. Эти группы обычно сопоставлялись с ролями в приложении, и всё было довольно просто. Сегодня же у нас нет операционной системы или глобального каталога, к которому можно было бы обратиться, поэтому процесс авторизации приходится встраивать в каждое приложение.
- Появление микросервисов: мы пережили архитектурный переход от монолитных приложений к микросервисам. Во времена монолитов авторизация осуществлялась в одно время и в одном месте кода. Сегодня же мы имеем множество микросервисов, каждому из которых необходимо выполнять собственную авторизацию. Нам также приходится продумывать взаимодействие этих процессов между микросервисами, чтобы допускались лишь правильные модели таких взаимодействий.
- Принцип нулевого доверия: изначальный подход безопасности, основанный на защите периметра, был заменён системой защиты с нулевым доверием. Этот переход привёл к перекладыванию большого объёма ответственности со среды на приложение.
Сегодня мы живём уже в новом мировом порядке, когда всё находится в облаке, всё основывается на микросервисах, и защита по принципу нулевого доверия является необходимой мерой. К сожалению, не все приложения поспевают за этой парадигмой, и когда мы сравниваем хорошо спроектированные программы с неудачными, то перед нами отчётливо вырисовывается пять антипаттернов, в противовес которым рождается пять лучших практик.
Пять лучших практик облачного контроля доступа
▍ 1. Специализированный сервис авторизации
Сегодня каждый сервис выполняет свою собственную авторизацию. И если этот процесс должен реализовываться всеми микросервисами, то в каждом случае он будет несколько отличаться. Поэтому, когда вы хотите изменить поведение авторизации во всей системе, вам нужно подумать о том, как следует обновить каждый микросервис, а также учесть логику его работы. Однако по мере добавления в систему всё большего их числа этот процесс становится весьма хлопотным.
В качестве лучшей практики здесь мы рассматриваем извлечение логики авторизации из микросервиса и создание специализированного микросервиса, который будет отвечать конкретно за неё.
В последние пару лет крупные организации начали публиковать работы, описывающие принцип действия их специализированных систем авторизации. Всё началось с публикации Google Zanzibar, в которой рассказано о создании такой системы для Google Drive и других сервисов. За Google последовали и другие компании, которые описали разработку своих специализированных сервисов авторизации и окружающих их распределённых систем. Речь идёт о таких инструментах, как AuthZ компании Intuit, Himeji ресурса Airbnb, AuthZ платформы Carta и PAS компании Netflix. Теперь мы начинаем анализировать их опыт и применять его в собственном ПО.
▍ 2. Детальный контроль доступа
Вторым антипаттерном является встраивание в приложение многокомпонентных ролей. Мы зачастую встречаем такой подход в приложениях, где есть роли вроде «администратор», «участник» и «наблюдатель». Эти роли внедряются непосредственно в код, и когда разработчики впоследствии вносят дополнительные разрешения, они пытаются каскадировать их внутри этих ролей, усложняя тем самым тонкую настройку модели авторизации.
В данном случае лучшей практикой будет начать с детальной модели, построенной на принципе наименьших привилегий. Цель — предоставить пользователю только нужные разрешения, ни больше ни меньше. Это важно, потому что в случае взлома идентифицируемой сущности — что является вопросом не возможности, а, скорее, времени — мы путём сокращения присвоенных ролям разрешений можем ограничить потенциальный вред, который эта сущность окажется способна нанести.
▍ 3. Управление доступом на основе политик
Третий антипаттерн — это реализация контроля доступа в виде спагетти-кода, то есть, когда разработчики беспорядочно раскидывают инструкции switch и if по всему коду, управляющему логикой авторизации. Это плохой подход, который создаёт массу трудностей, когда нам нужно изменить способ осуществления авторизации по всей системе.
Лучшей практикой здесь будет поддержание отчётливого разделения обязанностей и хранение логики авторизации в соответствующей политике. Отделяя эту политику от кода приложения, мы гарантируем, что команда разработки будет отвечать конкретно за разработку приложения, а команда безопасности конкретно за его безопасность.
▍ 4. Проверки доступа в реальном времени
Четвёртый антипаттерн связан с использованием в токене доступа старых разрешений. Это обычно происходит на ранних этапах развития приложения, когда разработчики устанавливают области доступа пользователей, а затем встраивают эти области в токен доступа.
Рассмотрим в качестве примера сценарий с авторизацией пользователя, которому доступна область «администратор». Эта область встраивается в токен доступа. Теперь, когда пользователь взаимодействует с системой, используя действующий токен с областью «администратор», он получает привилегии администратора. Почему это плохо? Дело в том, что если мы захотим лишить пользователя этой области доступа и сделать её недействительной, то столкнёмся со сложностями. До тех пор, пока пользователь обладает неистёкшим токеном доступа, он сможет использовать все ресурсы, к каким этот токен его предоставляет.
При использовании токенов доступа невозможно реализовать детальную модель управления. Даже если издатель токена видит, к каким ресурсам пользователь имеет доступ, будет непрактичным встраивать эти права в токен. Предположим, у нас есть коллекция документов, и мы хотим дать пользователю разрешение на доступ к одному из них. О каком документе идёт речь? Может, обо всех? Или о нескольких? Очевидно, что такой подход не масштабируется.
Лучшей практикой будет никогда не предполагать, что в токене доступа есть необходимые нам разрешения, и вместо этого использовать проверки доступа в реальном времени, которые учитывают контекст идентификации, контекст ресурса и разрешение.
▍ 5. Централизованные логи решений
Как уже говорилось, неавторизованный доступ является не вопросом возможности, а вопросом времени. Тем не менее компании склонны пренебрегать ведением согласованных логов авторизации, что ограничивает их возможность отслеживать инциденты с неавторизованным доступом.
Лучшей практикой здесь будет использование детальных, централизованных логов авторизации. Необходимо вести мониторинг и логировать всю информацию в централизованном месте, чтобы впоследствии её можно было проанализировать для понимания произошедших в системе событий.
Паттерны детального контроля доступа

Давайте подробнее поговорим о детальном контроле доступа и его появлении.
▍ Списки контроля доступа (ACL)
В далёких 80-х годах операционные системы определяли для файлов и каталогов разрешения вроде «чтение», «запись» и «выполнение». Эти паттерны назывались списками контроля доступа (ACL).
С помощью ACL можно было ответить на такие вопросы, как «Есть ли у Алисы доступ к «чтению» этого файла?»
▍ Контроль доступа на основе ролей (RBAC)
RBAC, или контроль доступа на основе ролей, вошёл в обиход в период между 90-ми и началом 2000-х вместе с появлением каталогов вроде LDAP и Active Directory. Такие каталоги дают возможность создавать группы и добавлять в них пользователей. При этом каждая группа обычно соответствует конкретной роли в приложении. Администратор приписывал пользователя группе, чтобы дать ему нужные разрешения, производя все необходимые манипуляции в одной консоли.
С помощью RBAC можно отвечать на вопросы вроде: «Состоит ли Боб в роли «администратор продаж»?»
▍ Контроль доступа на основе атрибутов (ABAC)
Очередным витком развития стал контроль на основе атрибутов (ABAC), и именно здесь мы начали уходить от многокомпонентных ролей в сторону детального контроля доступа. В начале 2000-х и 2010-х мы увидели, как стандарты вроде XACML определяют построение политик детальной авторизации.
Вы могли определять разрешения на основе атрибутов, включая пользовательские атрибуты (например, к какому отделу принадлежит пользователь), атрибуты ресурсов (например, к какому каталогу пользователь пытается получить доступ?) и даже атрибуты среды (например, где географически находится пользователь? Который сейчас день и час?).
С помощью ABAC можно ответить на вопросы вроде: «Состоит ли Мэллори в отделе «Продаж»? Находится ли документ в каталоге «Продажи»? или «Рабочее ли сейчас время в США?».
▍ Контроль доступа на основе связей (ReBAC)
Последней, но не менее важной является новая модель авторизации, описанная в работе Zanzibar под названием контроль доступа на основе отношений (ReBAC). Согласно этой модели, вы определяете набор субъектов (обычно ваших пользователей или групп) и объектов (например, организаций, каталогов или клиентов). Следом вы также определяете, имеет ли конкретный субъект связь с неким объектом. Например, между пользователем и объектом каталога такими связями будут выступать «наблюдатель», «администратор» или «редактор».
С помощью ReBAC можно отвечать на очень сложные вопросы, перебирая граф отношений, сформированный объектами, субъектами и их связями.
Два подхода к детальному контролю доступа
Вокруг концепции детального контроля доступа сформировалось две экосистемы:
▍ 1. Политика как код
В этой парадигме мы выражаем политики как набор правил, написанных на языке Rego. Она представляет собой продолжение ABAC, и наиболее популярным проектом здесь является Open Policy Agent (OPA).
OPA — это механизм принятия решений общего назначения, который создавался для управления доступом на основе политик и ABAC. Однако у него есть свои недостатки: используемый для написания политик язык — Rego — является производным от языка Datalog, который очень труден для освоения. При этом он также не сгодится для моделирования авторизации в приложении. А поскольку OPA поистине является механизмом общего назначения, вам придётся собирать всё из рудиментарных кирпичиков.
OPA также оставляет непростую задачу по передаче механизму принятия решений необходимых данных о пользователе и ресурсе реализующему проект разработчику. Эта передача информации очень важна, поскольку решение должно приниматься в течение миллисекунд, так как оно находится на критическом пути запроса любого приложения. И это означает, что для построения на базе OPA системы авторизации вам придётся решать данную задачу распределённых систем самим.
Если же оценивать в общем, то OPA является хорошей отправной точкой, но без сложностей здесь не обойдётся.
▍ 2. Политика как данные
В этом случае политика хранится не как набор правил, а является встроенной в структуру данных. Граф связей сам по себе является самодостаточной системой, поэтому заниматься разработкой модели вам не придётся. Здесь у нас есть «субъекты», «объекты» и «связи», что обеспечивает широкую гибкость.
Если ваша модель области выглядит, как Google Drive и несёт в себе каталоги, файлы и пользователей, то именно с этого подхода следует начать. С другой стороны, эта экосистема всё ещё находится на этапе становления и представлена множеством конкурирующих опенсорсных реализаций, в связи с чем будет сложно совместить её с другими моделями авторизации вроде RBAC и ABAC.
Управление доступом на основе политик
Управление доступом на основе политик, как и предполагает название, выносит логику авторизации из кода приложения в политику, действующую автономно.
Вот пример политики, написанной на Rego:
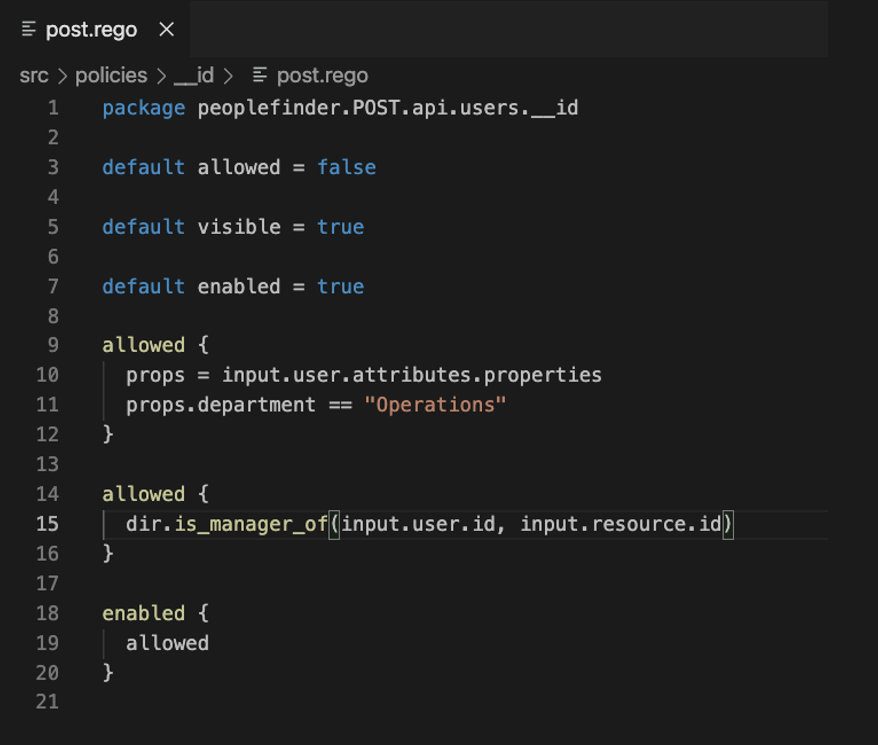
Здесь поистине задействуется принцип наименьших привилегий. Тут мы видим, что, например, в условии allowed, доступ не разрешается, пока у нас не будет достаточно доказательств для его получения. Политика будет возвращать allowed = false, пока мы не предоставим причину для изменения этого равенства на allowed = true. Обратите внимание, что на строке 9 выполняется проверка, относится ли пользователь к отделу "Operations". Если это так, данное условие allowed будет оценено как true.
Далее мы вкратце посмотрим, как выглядит код приложения после извлечения логики
авторизации в политику:
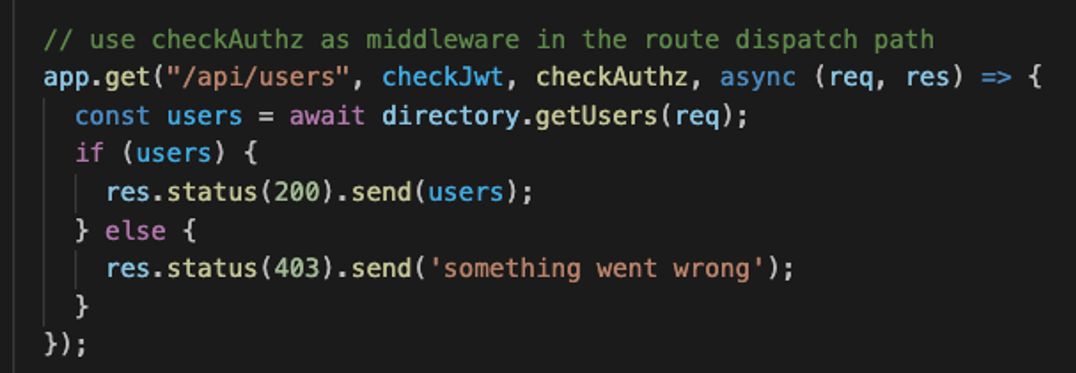
Фрагмент выше — это конечная точка express.js, отвечающая за передачу идентификационных данных пользователя, верифицируемых промежуточной программой с использованием JWT. Если условие allowed политики вернёт true, эта программа передаст запрос следующей функции, если нет — вернёт ошибку 403.
Существует множество причин для выноса логики авторизации из кода приложения. Это позволяет создать отдельный компонент, который можно сохранить и версионировать аналогично коду приложения. Каждая корректировка политики будет становиться частью лога изменений в Git, что позволит нам все эти корректировки отслеживать.
Кроме того, отделяя логику авторизации от кода приложения, мы следуем принципу разделения обязанностей. Команда безопасности сможет заниматься политикой авторизации, а команда разработки — сосредоточиться на приложении. И когда у нас есть отдельный компонент политики, мы можем встроить его в немутабельный образ и снабдить подписью для поддержания безопасной цепочки доставки. Вот ссылка на открытый проект, реализующий как раз эту задачу: https://github.com/opcr-io/policy.
Контроль в реальном времени — это задача распределённых систем
В современных системах авторизации очень важны проверки в реальном времени. Авторизация — это действительно сложная задача, поскольку при верной реализации она становится задачей распределённых систем.
Первая сложность заключается в том, что наш сервис авторизации должен выполнять контроль доступа локально, поскольку он находится на критическом пути каждого запроса приложения. Авторизация выполняется для каждого запроса, который пытается получить доступ к защищённому ресурсу. При этом она требует 100% доступности и должна осуществляться в течение миллисекунд, в связи с чем эту операцию следует выполнять именно локально.
Нам нужно производить авторизацию локально, но при этом управлять её политиками и данными глобально. Кроме того, нам также нужно обеспечить, чтобы данные, на которых мы основываем соответствующие решения, являлись актуальными по всем нашим локальным авторизаторам. Для этого нам потребуется уровень контроля, который будет управлять политиками, каталогом пользователей и всеми данными ресурсов, а также обеспечивать, чтобы каждое изменение распределялось по периферии в реальном времени. Помимо этого, нам нужно собирать логи решений со всех локальных авторизаторов и передавать их выбранной системе логирования.
Заключение
Облачная авторизация — это сложная задача, которая пока ещё полностью не решена, в связи с чем каждое облачное приложение, по сути, заново изобретает колесо. В статье мы разобрали пять антипаттернов и соответствующие лучшие практики реализации контроля доступа в приложениях в эпоху облачных вычислений:
Во-первых, вам необходимо создавать детальные модели авторизации, используя любой паттерн контроля доступа, будь то RBAC, ABAC, ReBAC или их комбинацию — смотря, что лучше подойдёт вашему приложению или организации.
Во-вторых, нужно разделить ответственности и вынести логику авторизации из кода в политику, которой будет заниматься команда безопасности.
В-третьих, очень важно выполнять проверки доступа в реальном времени, используя актуальную информацию о пользователе и ресурсе.
В-четвёртых, для повышения гибкости всеми пользователями, ресурсами, политиками и связями нужно управлять в одном месте.
Наконец, с целью внутреннего контроля следует собирать и хранить логи принятых решений об авторизации.
Telegram-канал с розыгрышами призов, новостями IT и постами о ретроиграх

