[Перевод] Чат-бот для электронной коммерции

Например, посетитель сайта что-то ищет и пользуется для этого чат-ботом, работающим на сайте или в мобильном приложении. Бот разбирает сообщение и, основываясь на имеющихся в нём ключевых словах, отвечает пользователю, выдавая ссылку на страницу с результатами поиска, среди которых пользователь может найти то, что ему нужно.
Бот, о котором пойдёт речь в этом материале, создан с использованием Java и Apache OpenNLP. Здесь мы поговорим о том, как боты разбирают сообщения пользователей, удаляя из них всё ненужное.
Удаление из сообщений ненужных символов
Когда пользователь общается с ботом, в сообщениях пользователя могут присутствовать ненужные символы. Поэтому, прежде чем бот сможет адекватно ответить, всё ненужное из сообщений пользователя нужно удалить.
Вот пример сообщения, которое пользователь отправил боту. В верхней части находится исходный текст, а в нижней — он же, но очищенный от ненужных символов.

Исходное и обработанное сообщение
В Java для удаления ненужных символов можно воспользоваться следующим регулярным выражением:
"[^\\w.,;:'\"\\s]+"
Токенизация текста в OpenNLP
После очистки текста от ненужных символов его нужно токенизировать с использованием соответствующих инструментов OpenNLP. В результате исходное предложение будет разбито на мелкие фрагменты (токены). Этот процесс и называют токенизацией. В целом можно сказать, что исходный необработанный текст токенизируется с опорой на набор символов-разделителей (это, в основном, пробелы). Токенизация используется при решении, например, следующих задач:
- Проверка правописания.
- Выполнение поиска.
- Идентификация частей речи.
- Обнаружение предложений.
- Классификация документов.
В следующем примере сначала выполняется обучение токенизатора с использованием классов
TokenizerMe и TokenizerModel: try (InputStream modelIn = new ByteArrayInputStream(Files.readAllBytes(tokeniserTrainingFile.get()))) {
this.tokenizer = new TokenizerME(new TokenizerModel(modelIn));
}
Класс
TokenizerMe преобразует исходный текст в набор токенов. Он, принимая решение о разделении текста на токены, пользуется показателем энтропии.В машинном обучении энтропия — это мера неопределённости некоей системы (1 — полная определённость, 0 — полная неопределённость).
Затем выполняется токенизация текста:
private tokenizerMe;
final String[] tokenizedMessage = this.tokenizerMe.tokenize(RobotUtil.getOnlyValidCharacters(inputMessage));
На следующем изображении показан результат токенизации сообщения.
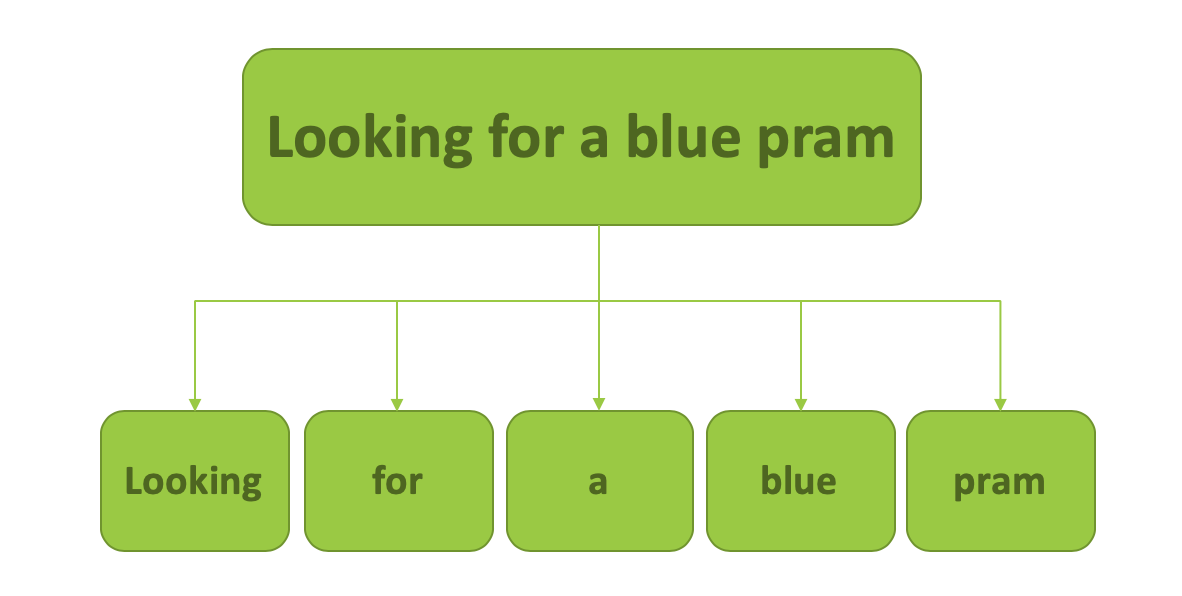
Результат токенизации сообщения
После токенизации сообщения нужно определить тип токенов, понять, к каким частям речи они относятся, и убрать те из них, которые нам не нужны.
Выявление частей речи с использованием OpenNLP
Теперь нам нужно выяснить то, к какой части речи относится каждый из токенов. Узнать о том, что это: имя существительное, глагол, наречие, имя прилагательное. В OpenNLP для обозначения частей речи используются сокращения, приведённые в следующей таблице.
Вот код, в котором для выявления частей речи в тексте используется класс
POSTaggerME: private POSTaggerME ptagger;
try (InputStream modelIn = new ByteArrayInputStream(Files.readAllBytes(trainingFile.get()))) {
this.ptagger = new POSTaggerME(new POSModel(modelIn));
}
Класс
POSTaggerME используется для определения частей речи в исходном тексте. Он, при обработке текста, использует показатель энтропии.final String[] tags = this.ptagger.tag(tokenizedMessage);
После того, как выяснено то, к какой части речи относится каждый из токенов, мы убираем из текста всё ненужное.
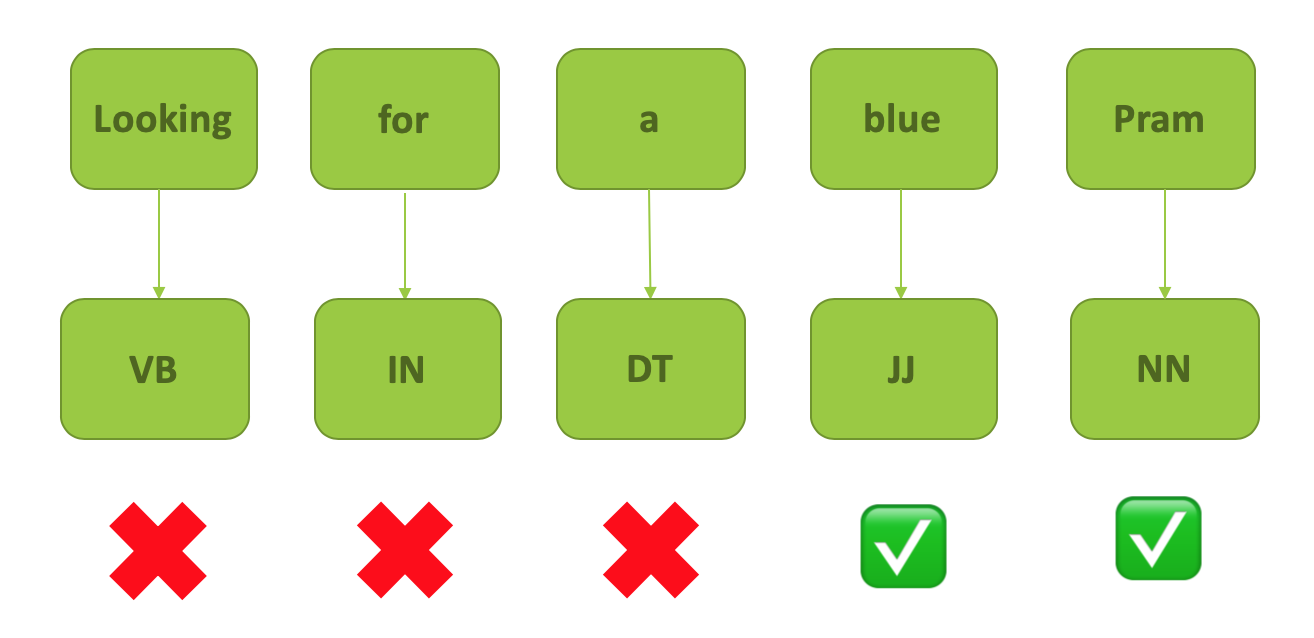
Удаление ненужных токенов
Нас в данном случае интересует имя прилагательное (JJ) и имя существительное (NN).
Теперь в нашем распоряжении оказываются ключевые слова. Бот, воспользовавшись ими, может выдать ссылку, позволяющую пользователю найти то, что ему нужно.

Бот отвечает пользователю
Применяются ли в ваших проектах чат-боты?

