[Перевод] Архитектура PlayStation 3, часть 1: Cell
 Оригинальная PlayStation 3 или PS3, выпущенная в 11.11.2006 в Японии, в 17.11.2006 в Америке и в 23/03/2007 в Европе
Оригинальная PlayStation 3 или PS3, выпущенная в 11.11.2006 в Японии, в 17.11.2006 в Америке и в 23/03/2007 в Европе
Примечание переводчика:
Оригинальная статья глубоко описывает техническое строение консоли PlayStation 3, начиная с процессора, и заканчивая описанием борьбы с пиратством. В итоге статья вышла достаточно содержательной, но огромной по объему текста. Поэтому полностью публиковать перевод всей статьи не имеет практического смыла.
Вместо этого, перевод будет разбит на несколько частей, каждая из которых описывает одну большую или небольших тем из оригинала. Часть 1 описывает устройство процессора Cell. Если Вам данный цикл переводов будет интересен, то будут выложены и следующие части. А пока, приятного чтения!
1. Краткое введение
В 2006 году Sony выпустила долгожданную игровую консоль «следующего поколения». Это блестящая (хоть и тяжелая) машина, чья базовая аппаратная архитектура развивает идеи Emotion Engine из PS2, то есть фокусируется на векторных вычислениях для достижения высокой производительности, даже ценой сложности. И в то же время, их новый «суперпроцессор», Cell Broadband Engine, был разработан в эпоху кризиса инноваций. Он должен будет идти в ногу с развитием тенденций в области мультимедиа.
В этой статье подробно рассматривается совместный проект Sony, IBM, Toshiba и Nvidia, а также его реализация и влияние на индустрию.
Ревизия материнской платы COK-001 (самая первая), взятая из моей модели CECHA12. Оставшиеся 128 МБ флэш-памяти NAND и разъемы PATA для привода Blu-ray, дочерняя плата Wi-Fi/BT, передняя панель и карт-ридер установлены сзади.Та же материнская плата, но с помеченными важными частями.Диаграмма основной архитектуры
1.1. О длине статьи
Я боюсь, что эта статья не будет из тех, которые я обычно пишу про другие консоли в данной серии статей. Если вы заинтересованы узнать про каждый технический аспект PlayStation 3, то вас ждёт увлекательное путешествие! Стоит отметить, что эта работа охватывает ~6 лет исследований и разработок, проведенных бесчисленным количеством инженеров. Поэтому я не ожидаю, что вы сможете переварить всё это за один раз. Пожалуйста, не торопитесь при чтении (и делаете перерывы при необходимости). Если в конце вам захочется ещё, то проходите в раздел «Источники»!
2. CPU
Время познакомится с самой узнаваемой и инновационной частью данной консоли.
2.1. Введение
Процессор PS3 сложно устроен, но он — удивительная инженерная работа, в которой пересекаются сложные потребности и необычные решения, выдающиеся в эпоху перемен и экспериментов. Итак, прежде чем мы перейдем к внутренностям процессора PS3, я написал следующие абзацы, чтобы привнести в статью некоторый исторический контекст. Следовательно, мы сможем разложить чип по кусочкам так, чтобы не только понимать, как он работает, но и почему были приняты те или иные главные конструкторские решения.
2.1.1. Состояние прогресса
Процессор PS1 (1994).
Создан LSI и Sony на основе MIPS
Прошло почти десять лет после выхода оригинальной PlayStation на процессоре MIPS, и мы находимся в начале 2000-х. В это время дела у SGI/MIPS шли не очень хорошо. Nintendo недавно отказалась от них в пользу бюджетного ядра PowerPC от IBM, в то время как Microsoft, будучи новичком на этом рынке, выбрала Intel и их доминирующую x86.
Emotion Engine, процессор PS2 (2001).
Создан Toshiba, опять же, на основе MIPS
Ранее Sony брала существующие бюджетные решения (дешевые ядра MIPS) и модифицировала их так, чтобы получить приемлемую производительность в 3D при сниженных затратах. В этот процесс включались другие компании, будь то LSI (для процессора PS1) или Toshiba (для Emotion Engine). Эта методология использовалась до 2004 года с выпуском PlayStation Portable. Итак, какой новый MIPS-агрегат они собирались создать для PlayStation 3?
Оказывается, что разработка PlayStation 3 предшествует разработке PlayStation Portable [1]. В 2000 году, через месяцы после выхода PS2, Sony сформировала альянс совместно с IBM и Toshiba под названием «STI». Единственная цель альянса — создать чип, который мог бы работать в следующем поколении суперкомпьютеров [2]. Если это звучит недостаточно экстравагантно, то будущий чип также будет использоваться в преемнике PS2. В конце 2004 года IBM представила процессор Cell Broadband Engine (также известный как «Cell BE» или просто «Cell») [3].
2.1.2. Новые конструкторские решения
Чтобы понять радикальные решения в Cell, мы должны описать проблемы, которые были актуальны в данную эпоху (конец 90-х — начало 00-х).
 Процессор Cell Broadband Engine.
К сожалению, он слишком блестящий для моей камеры.
Процессор Cell Broadband Engine.
К сожалению, он слишком блестящий для моей камеры.
С каждым годом потребители требуют всё больших скоростей. Это было всегда. Однако, последний подход, призванный это решить (конвейер данных и увеличение частот), теперь не справляется с масштабированием. Архитектура NetBurst от Intel не смогла развиваться дальше, а обещанный преемник так и не появился. Аналогично, IBM в своем PowerPC 970/G5 не смогла предоставить ни обещанных »3 ГГц», ни низкое энергопотребление (а значит, Apple не может поставлять ноутбуки с этим процессором) [4]. В общем, похоже, что инженеры столкнулись с новым кризисом масштабируемости.
Поэтому, фокус сместился на распределенные вычисления [5]. Другими словами, зачем увеличивать производительность одной машины, если вместо этого можно использовать несколько небольших машин, распределяющих рабочую нагрузку? Напротив, этот подход не является чем-то новым, поскольку все консоли, проанализированные на этом веб-сайте, содержат более одного процессора. Однако именно разработка «единого процессора с несколькими ядрами» открывает новые возможности для проектирования процессоров (которые могут использоваться не только в консолях).
Следовательно, Cell является частью этой новой волны исследований и разработок. Новый процессор сочетает в себе многоядерный дизайн с особым акцентом на векторные вычисления. Если помните, векторные вычисления являются оптимальными для симуляций (физика, освещение и подобное). Эту задачу ранее выполняли Geometry Transformation Engine или два блока Vector Unit. Но вы также увидите, почему дизайн Cell является большим шагом вперед по сравнению с двумя предыдущими решениями.
2.1.3. Новая эра многоядерности
Если задуматься, то и процессор PS1, и Emotion Engine уже были многоядерными. Тогда почему же вокруг Cell было так много шума? Ну, два предыдущих чипа состояли из одного универсального ядра и нескольких ядер для конкретных задач (аудио-процессор, декомпрессия изображений). Эти ядра сочетали различные архитектуры, в которых универсальное ядро управляло другими ядрами.
Пример гетерогенного дизайна.
По сей день это де-факто архитектура многих мощных консолей.
Этот тип архитектуры процессора относят к Гетерогенным вычислениям, и он являлся де-факто выбором для создания машин, которые предназначены для выполнения конкретных задач (в данном случае, игр). Аналог в виде Гомогенных вычислений более преобладает на рынке ПК, где процессоры должны выполнять более широкий круг задач (и все они имеют одинаковый приоритет). Поэтому, в последнем типе может быть несколько ядер одного и того же типа.
Пример гомогенного дизайна.
Каждое ядро могло выполнять те же задачи, что и раньше. Они не обязательно ограничены одной задачей.
Возвращаясь назад к теме, Cell сочетает обе модели: в этом процессоре одно универсальное «главное» ядро и 8 векторных «вспомогательных» ядер. Эти векторные ядра могут принимать различные роли, и при этом они выполняют те предыдущие задачи, которые первоначально решались с помощью гетерогенных конструкций.
Поскольку ядра Cell не ограничиваются одним типом задач, то они обеспечивают гибкость гомогенных компьютеров. В целом, данный дизайн не идеален и содержит некоторые компромиссы, но на протяжении этой статьи вы увидите различные проблемы, которые попытается решить Cell, и как ему это удалось.
2.2. Взгляд на Cell
Рассказав всю эту историю и теорию, думаю, что мы готовы представить нашего главного героя этого раздела. Знакомьтесь, Cell:
Cell Broadband Engine (вариант для PS3).
Создан IBM для суперкомпьютеров и научных исследований.
Перечеркнутый блок «SPE» означает, что он отключен (не используется).
Другие «SPE» слева предназначены для операционной системы.
К концу этого раздела вы будете знать, что делает каждый компонент.
2.2.1. Общая архитектура
Cell работает на частоте в 3.2 ГГц и состоит из множества компонентов. Итак, для целей этого анализа этот процессор можно разделить на три основные части [6]:
Управляющая: это часть Cell управляет остальной частью схемы. Здесь мы находим элемент под названием Power Processing Element (PPE).
Вспомогательная: эта часть столь же важна, как и PPE, но возможности её элементов ограничены ролью помощника или ускорителя. Эта часть состоит из 8 элементов Synergistic Processing Element (SPE).
Интерфейсная: так как потребность в пропускной способности растет экспоненциально, то внедряются новые интерфейсы для перемещения данных без создания узких мест. В этой группе мы находим несколько протоколов: шина Element Interconnect Bus (EIB), блок Broadband Engine Interface Unit (BEI), контроллер Memory Interface Controller (MIC) и шина Flex I/O.
Эта информация будет более подробно позже рассмотрена в статье, поэтому вам пока не нужно запоминать эти имена. Основная цель этого раздела — дать читателю мысленное представление о природе Cell и ознакомить со всеми компонентами, которые мы будем обсуждать в подходящее время.
2.2.2. Как организовано это исследование
Видя эту структуру, мне пришлось организовать её так, чтобы вам не надоело от большого количества информации. Поэтому мы собираемся проанализировать Cell путем изучения каждого его компонента в следующем порядке:
Шина Element Interconnect Bus (EIB), которая соединяет все компоненты.
PowerPC Processing Element (PPE) и его основной элемент PowerPC Processing Unit (PPU).
Какая память общего назначения доступна в этой консоли.
Блоки Synergistic Processing Element (SPE) и их основной элемент Synergistic Processing Unit (SPU).
Модель программирования, разработанная для эффективного программирования под Cell.
Учитывая это, давайте приступим к настоящему анализу.
2.3. Cell изнутри: Сердце
С момента своего анонса Cell упоминается как сеть на кристалле (Network-on-Chip, NoC) [7] вместо стандартного определения «системы на кристалле» (System-On-Chip, SoC). Это связанно с неортодоксальной шиной данных чипа Element Interconnect Bus (EIB). До сих пор мы видели, насколько требовательными могут быть компоненты процессора, если учитывать, в какой степени система подвержена узким местам. Чтобы решить эту проблему в одиннадцатый раз, IBM разработала новый дизайн … и задокументировала его, используя термины, аналогичные дорожному движению.
Упрощенная схема шины Element Interconnect Bus (EIB).
Каждая стрелка между «рампами» (узлами) представляет собой две однонаправленные шины, поэтому каждый узел подключен к следующему по четырем каналам.
Шина EIB состоит из 20-ти узлов (рампы), каждый из которых соединяет один компонент Cell. Рампы соединены между собой с помощью четырех шин, две из которых работают по часовой стрелке, а другие две — прочив часовой. Каждая шина (или канал) имеет ширину в 128 бит. При этом вместо того, чтобы повторять топологию с одной шиной (как это делали в Emotion Engine и его предшественник), рампы соединены между собой по топологии «маркерного кольца» (token ring). В ней пакеты данных должны через все соседние узлы, пока они не достигнут места назначения (прямого пути нет). Учитывая, что шина EIB предоставляет четыре канала связи, то есть четыре возможных маршрута (кольца).
Теперь вы можете подумать, в чем смысл маркерного кольца, если данные могут проходить более длинные пути (по сравнению с одной прямой шиной)? Ну, одна шина довольно сильно подвержена перегрузками данных. Поэтому инженеры шины EIB решили использовать эту топологию, чтобы обеспечить большой объем параллельного трафика (читайте дальше, если хотите узнать, как помогло данное кольцо).
Данные передаются в виде 128-битных пакетов [8]. Каждое кольцо может осуществлять до трех передач одновременно при условии, что пакеты не пересекаются. Шина EIB работает с использованием командных кредитов. Другими словами, всякий раз, когда компоненту нужно начать передачу, он отправляет запрос арбитру данных (Data Arbiter), который управляет трафиком внутри колец.
После утверждения запроса пакеты вводятся в кольцо и получают «маркер», который арбитр данных использует в качестве метаданных для контроля передачи. Кроме того, некоторые компоненты имеют более высокий приоритет, чем другие, например, контроллер Memory Interface Controller (MIC), в котором находится ОЗУ. Наконец, арбитр данных никогда не будет размещать пакеты в кольцах, путь которых длиннее половины кольца.
Каждая рампа участвует в передаче. Она читает адрес назначения пакета, чтобы знать, отправлять ли данные в свой компонент или передать их следующей рампе. Во время каждого тактового цикла рампы могут одновременно принимать и отправлять пакеты размером в 128 бит (16 байт). Итак, если учитывать наличие четырех каналов и частоту шины EIB в 1.6 ГГц (половина частоты Cell), то теоретическая максимальная скорость передачи составляет:
16 байт х 2 передачи/такт х 4 кольца х 1.6 ГГц = 204.8 ГБ/с
Конечно, это значение слишком оптимистичное, и есть много других внешних факторов (путь отправления или назначения, состояние шины), определяющих производительность. В любом случае, во многих исследовательских работах, выполненных IBM и другими авторами, были получены более реалистичные скорости с использованием практических экспериментов [9].
Теперь, когда вы увидели, как каждый компонент Cell связан между собой, пришло время рассмотреть первый компонент этого чипа…
2.4. Cell изнутри: Лидер
Здесь мы посмотрим на «главную часть» Cell. Это часть чипа, которая отвечает за управление остальной частью. Имя компонента — PowerPC Processing Element (PPE), и и его можно рассматривать как MIPS R5900 в Emotion Engine.
2.4.1. Состав PPE
Упрощенная схема PowerPC Processing Element (PPE)
Помните, как я ранее разделил Cell на разные области? То же самое можно сделать с PPE. IBM использует термин «элемент» для описания независимой машины [10], но, описывая её изнутри, использует термин «юнит», чтобы отделить основную схему от интерфейсов, которые взаимодействуют с остальной частью Cell.
Исходя из вышесказанного, PowerPC Processing Element неожиданно состоит из двух частей:
PowerPC Processing Unit (PPU): это логическая часть PPE («ядро» процессора). Не забывайте, что это не PPU от Nintendo! (хоть и они состоят из одних и тех же букв латинского алфавита… в том же самом порядке…).
PowerPC Processor Storage Subsystem (PPSS): большой интерфейс, который соединяет PPU с остальной частью Cell. Кроме того, он содержит огромный кэш L2 размером в 512 КБ.
Как вы можете видеть, архитектура PPE (и остального Cell) довольно модульная, что соответствует принципам архитектуры RISC. Вы скоро увидите, что модульность применяется даже внутри PPU.
2.4.2. PowerPC Processing Unit
Сейчас мы рассмотрим внутренности PPU. Напоминаю, мы сначала погрузились в Cell, потом в PPE, а затем в PPU. Мы проанализируем PPU так же, как и любое другое ядро процессора.
2.4.2.1. Знакомая архитектура
Начнем с того, что PPU не создан с нуля, а cтроится на основе существующей архитектуры PowerPC. Однако, в отличие от предыдущих итераций, когда IBM брала существующий процессор и немного обновляла его для соответствия новым требованиям, PPE не является преемником какого-либо предыдущего дизайна процессора.
Вместо этого IBM создала новый процессор, который реализует спецификацию PowerPC версии 2.02 (это последняя спецификация PowerPC перед ребрендингом в «Power ISA»). Суммируя вышесказанное, можно сказать, что с этого времени вы не найдете такой же дизайн PPU ни в одном существующем чипе того времени. Но он имеет те же машинные коды, что и в других чипах PowerPC.
Тем не менее, почему IBM выбрала архитектуру PowerPC для разработки высокопроизводительного чипа? Просто, PowerPC — это зрелая платформа [11], которая в течение 10 лет тестировалась на пользователях Macintosh и постоянно обновлялась. Она соответствует всем требованиям Sony, и, если возникнет такая необходимость, её можно адаптировать к различным средам.
Последнее, но тем не менее важное: использование хорошо известной архитектуры является благоприятным для существующих компиляторов и кодовых баз, что для новой консоли — большое стартовое преимущество.
Стоит отметить, что IBM была одним из автором первых чипов PowerPC совместно с Motorola и Apple (вспомните об альянсе AIM). Как бы то ни было, к началу 00-х годов так называемые участники альянса уже работали отдельно, где Motorola/Freescale разрабатывали отличную от IBM серию PowerPC.
2.4.2.2. Отличительные особенности
PPU имеет общую историю с PowerPC 970 (Apple называла его G5). Оба являются потомками POWER4, предшественника PowerPC, который в основном использовался в рабочих станциях и суперкомпьютерах. Это станет более очевидным, когда я скоро покажу вам модульные исполнительные устройства. Это радикальное изменение по сравнению с процессором линейки 750 в GameCube, который имел значительный вклад от Motorola, но затем был слегка изменен IBM.
Возвращаясь к теме, PPU — полноценный 64-битный процессор. Это означает, что:
Размер машинного слова — 64 бита.
Наличие 64-битных регистров общего назначения (всего их 32).
Шина данных, как минимум, шириной в 64 бита. В следующих главах статьи вы увидите она гораздо длиннее, но пока имеете в виду, что передача 64-битных слов не снижает производительность.
Адресная шина имеет ширину в 64 бита. В теории, процессор может адресовать до 16 экзабайт памяти. На практике это очень дорого обходится, если машина не вмещает всю эту память. Поэтому современные процессоры делегируют адресацию блоку управления памятью (Memory Management Unit, MMU), чтобы обеспечить больше возможностей для использования адресной шины.
Наконец, PPU реализует набор инструкций PowerPC версии 2.02, включая опциональные опкоды для квадратного корня с плавающей точкой [12]. Ядро также было расширено группой SIMD-инструкций, называемых Vector/SIMD Multimedia Extension (VMX). С другой стороны, в первоначальной спецификации нет некоторых элементов, в частности, режима little-endian (Cell работает только в режиме big-endian) и нескольких опкодов.
2.4.3. Строительные блоки PPU
Применяя «микроскопический» вид к PPU, мы можем видеть, что это устройство состоит из различных блоков или подблоков, выполняющие независимые операции (загрузка значений из памяти, выполнение арифметики и так далее). Возможности PPU определяются тем, что и как может делать каждый блок:
2.4.3.1. Инструкции
Упрощенная схема блока команд (IU)
Первый блок называется блоком команд (Instruction Unit, IU). Как следует из названия, он берёт инструкции из кэша L2 и даёт сигналы другим устройствам для выполнения запрошенной операции. Как и в современниках i686, часть набора инструкций интерпретируется при помощи микрокода (для этого IU включает в себя небольшой ROM). Наконец, в IU также размещен кэш L1 размером в 32 КБ для инструкций.
Обработка инструкции осуществляется с помощью 12-уровневого конвейера, хотя на практике общее количество уровней будет сильно различаться в зависимости от типа инструкции. Например, модуль предсказания переходов может пропустить большую часть конвейера. Если мы объединим IU с соседними блоками, то финальное число уровней часто приближается к 24 (да, это большое число, но помните, что Cell работает на частоте 3.2 ГГц).
Теперь самое интересное: IU имеет двойную обработку (dual-issue): в некоторых случаях IU может обработать до двух инструкций за такт, что значительно повышает пропускную способность. На практике, однако, существует множество условий для того, чтобы это работало, поэтому программисты или компиляторы отвечают за оптимизацию своих процедур, чтобы их последовательность инструкций могла использовать преимущества этой функции.
Кстати, двойная обработка реализована и в других процессорах, и этот термин может различаться между производителями. Поэтому я использовал определение от IBM.
В довершение всего, IU также многопоточный, то есть блок может одновременно выполнять две разные последовательности инструкций (называемых «потоками»). За кулисами, IU просто чередуется между двумя потоками за такт, создавая иллюзию многопоточности. По какой-то причине это поведение похоже на то, что в данный момент Intel определяет как hyper-threading. Возможно, что последнее ещё не было придумано. Тем не менее, многопоточность от IBM смягчает нежелательные эффекты, такие как остановка конвейера, поскольку процессор больше не будет блокироваться всякий раз, когда одна инструкция блокирует поток.
Чтобы достичь многопоточности, инженеры IBM продублировали внутренние ресурсы IU, включая регистры общего назначения (ранее я говорил, что регистров 32, но это для одного потока. В реальности их всего 64!). Однако ресурсы, которые не относятся спецификации PowerPC (например, кэш L1 или L2, интерфейсы), по-прежнему общие для потоков. Такие образом, ресурсы — однопоточные.
В общем, объединяя два потока с двойной обработкой, IU способен выполнять до четырех инструкций за такт. Несмотря на то, что это «наилучший сценарий», он все ещё предоставляет возможности оптимизации, которые пользователи в конечном итоге заметят в частоте кадров игры!
2.4.3.2. Управление памятью
Следующие блоки дают PPU возможность выполнения инструкций загрузки/сохранения и осуществлять управление памятью.
Начнем с того, что блок загрузки/сохранения (Load-Store Unit, LSU) выполняет опкоды «load» и «store», используя 32 КБ кэша данных L1. Как следствие, этот блок имеет прямой доступ к памяти и регистрам.
Упрощенная диаграмма блока загрузки-сохранения (Load-Store Unit, LSU) и его соседей
Кроме того, LSU содержит Memory Management Unit (MMU), который является обычным явлением в современном оборудовании. Короче говоря, MMU занимается адресацией памяти с помощью таблицы виртуальных адресов в сочетании с защитой памяти. Для улучшения последней MMU, в частности, оснащен сегментным блоком, который группирует адреса памяти, используя диапазоны под названием «сегменты». Также, что предотвратить снижение производительности в процессе работы, были включены Translation Lookaside Buffer (TLB) (кэширует преобразованные адреса) и Segment Lookaside Buffer (SLB) (кэширует сегменты).
2.4.3.3. Арифметика
Осталось объяснить всего два блока PPU, которые вычисляют математику, необходимую для любой игры.
Упрощенная диаграмма блоков, выполняющих арифметику
Первый блок — традиционное АЛУ Fixed-Point Integer Unit (FXU). Оно осуществляет целочисленные вычисления: деление, умножение, циклический сдвиг (схоже с обычным сдвигом, только уходящие биты возвращаются с конца) и нахождение ненулевого бита (например, оно полезно для нормализации координат вершины). Его конвейер длиной в 11 уровней.
Если вы посмотрите на диаграмму, вы увидите, что FXU, LSU и MMU объединены в один блок под названием исполнительный блок (Execution Unit, XU). Это потому, что они имеют один и тот же регистровый файл.
Второй блок куда более интересный. Vector/Scalar Unit (VSU) выполняет операции с числами с плавающей точкой и векторами. Он состоит из 64-битного блока FPU (на основе стандарта IEEE 754) и ** блока Vector/SIMD Multimedia Extension** (VXU), который исполняет набор SIMD-инструкций под названием VMX. Эти вектора длиной в 128 бит состоят из двух или трех 8/16/32-битных значений.
Возможно, вы уже слышали об расширении «VMX» раньше. Оно также называется «Altivec» у Motorola или «Velocity Engine» у Apple (да здравствуют торговые марки). И наоборот, конкурентные возможности SIMD в Cell можно найти и в другом процессоре, так что пока не расслабляйтесь!
2.4.4. Суммируя PPE
Вы только что видели, как работает PPE и что было сделано, но что это всё значит для разработчика?
В конце концов, PowerPC Processing Element — единственный процессор общего назначения на чипе. Но есть одно но: он не должен работать в одиночку. Помните ту широкую главную шину (EIB)? IBM разработала PPE так, чтобы инженеры могли совмещать его с другими процессорами для ускорения конкретных задач (высокопроизводительные вычисления, 3D-графику, научные симуляции, работа с сетями, обработка видео). Так как эта статья о PlayStation 3, то вы увидите, что остальная часть Cell отвечает за обработку графики и физики, поэтому в дальнейшем мы будем описывать эту часть.
2.5. Cell снаружи: Основная память
Давайте немного уйдем в сторону от Cell. Не столь важно то, насколько хорош PPE, если у нас нет подходящего рабочего пространства (памяти), чтобы заставить его работать.
Поэтому Sony добавила ОЗУ в виде XDR DRAM памяти объемом 256 МБ… Но опять-таки, что это всё значит? Для ответа на это, на нужно взглянуть на то, как работают блоки памяти и как они подключаются к Cell.
 Cell рядом с четырьмя чипами XDR DRAM на 64 МБ
Cell рядом с четырьмя чипами XDR DRAM на 64 МБ
Прежде всего, тип установленной памяти называется Extreme Data Rate (XDR). Вы можете думать о XDR DRAM, как о преемнике прóклятой RDRAM, установленной в Nintendo 64 и PlayStation 2. Но пока не спешите с выводами!
Rambus, как и любая другая компания, совершенствует свои изобретения. Их третья версия (XDR) теперь передает за такт 8 бит (это в 4 раза больше, чем у DDR DRAM) [13]. Задержка больше не создает проблем. Если мы посмотрим на данные одного из производителей, то задержка XDR составляет от 28 до 32 наносекунд [14], что почти в 10 раз быстрее, чем первое поколение чипов RDRAM.
Первая ревизия материнской платы PlayStation 3 содержит 4 чипа по 64 МБ, которые обрабатываются парами. XDR подключен к Cell, используя две 32-битных шины, по одной на каждую пару. Поэтому когда PPU записывает слово (64-битные данные), оно разделяется между двумя чипами XDR.
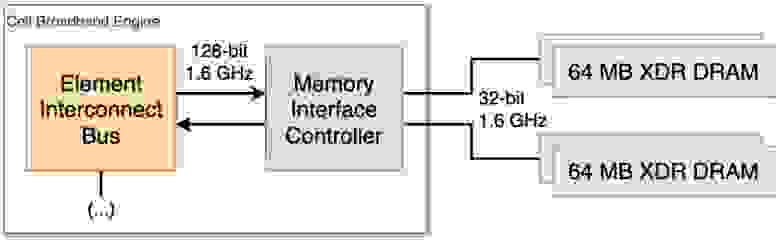 Cell рядом с четырьмя чипами XDR DRAM на 64 МБ
Cell рядом с четырьмя чипами XDR DRAM на 64 МБ
Cell соединяется с чипами XDR при помощи Memory Interface Controller (MIC), другой компонент внутри Cell (как и PPE). Дополнительно, MIC буферизирует передачи памяти для улучшения пропускной способности, но имеет одно ограничение: выравнивание больших байтов.
По сути, при передаче наименьший размер данных MIC составляет 128 байт, что хорошо работает для последовательного чтения и записи. Но если данные меньше, чем 128 байт, или требуется чередование между записью и чтением, то возникают проблемы с производительностью.
Тем не менее, является ли MIC узким местом или нет? Вы должны взглянуть на это в перспективе того, что оптимизация пропускной способности имеет решающее значение в системах, которые зависят от данных. В прошлом мы видели такие решения, как write-gather pipe или write back buffer. Поэтому MIC — просто новое предложение по решению повторяющейся проблемы.
Как бы то ни было, Sony утверждает, что скорость передачи данных составляет 25.6 ГБ/с. Однако на практике существует слишком много факторов, которые будут определять конечную скорость (вы видели, насколько сложно перемещать данные из одного места в другое в Cell).
Это все, что касается ОЗУ, но есть ещё больше памяти в другом месте: жесткий диск. PS3 позволяет играм использовать 2 ГБ на внутреннем жестком диске в качестве рабочей области (аналогично тому, что было в оригинальном Xbox) [15].
2.6. Cell изнутри: Помощники
Мы уже видели ранее, что Sony всегда добавляет к процессору общего назначения (в данном случае, PPE) дополнительные ускорители для достижения приемлемой производительности в играх (блоки VPU и IPU в случае с PS2; или GTE и MDEC с PS1).
Это обычная практика для аппаратного обеспечения игровых консолей, поскольку универсальный процессор может выполнять широкий спектр задач, при этом ни на чем не специализируясь. Консолям требуется лишь некоторый набор навыков (например, физика, графика и аудио), поэтому сопроцессоры позволяют им справляться с этими задачами.
[PPE] — это версия, которую урезали для снижения энергопотребления. Поэтому у нет тех лошадиных сил, как, например, у Pentium 4… Если взять код, который работает сейчас на Intel и AMD, независимо от мощности, и перекомпилировать его для Cell, то он будет работать — ну, может вам придется изменить одну, две библиотеки. Но полученный код будет примерно на 50–60% медленнее, и люди будут кричать «Боже мой! Этот процессор Cell ужасен!» Но это потому, что вы используете только одну его часть [16].
— Доктор Майкл Перроне, менеджер Отдела по разработке Cell, Исследовательский Центр IBM TJ Watson
Ускорители, входящие в состав Cell на PS3, это элементы Synergistic Processor Element (SPE). В Cell их восемь, однако один элемент отключается во время запуска консоли. Это связано с тем, что производство микросхем требует исключительной точности (изначально Cell создавался при техпроцессе в 90 нм), а оборудование не является совершенным.
Поэтому вместо того, чтобы выбрасывать схемы, которые оказались бракованными менее чем на 10%, Cell включает один запасной SPE. Таким образом, если один из них выходит из строя, весь чип не отбраковывается. Теперь этот запасной SPE всегда будет отключен, независимо от того, хорошо ли это или нет (у Sony может быть двух разных PS3 на рынке).
2.6.1. Состав SPE
Двигаясь дальше, Synergistic Processor Element (SPE) — крошечный независимый компьютер внутри Cell, управляемый PPE. Помните, что я рассказывал ранее о принятии элементов из гомогенных вычислений?
Что ж, эти сопроцессоры в некоторой степени универсальны и не ограничиваются одним приложением, поэтому они смогут помогать в решении широкого круга задач, то есть до тех пор, пока разработчики смогут их правильно запрограммировать.
Упрощенная диаграмма Synergistic Processor Element (SPE), в Cell этих элементов 8 (один отключен)
Как и в случае с PPE, мы рассмотрим SPE поподробнее. Это будет кратко, поэтому, если в конце вы хотите узнать больше о SPE, ознакомьтесь с разделом «Источники» в конце статьи. Итак, давайте начнем…
SPE — это процессор, который похож структурно на PPE, состоит из 2 частей: Memory Flow Controller и Synergistic Processor Unit.
2.6.1.1. Memory Flow Controller
Memory Flow Controller (MFC) — это блок, который находится между ядром и остальной частью Cell. Он является аналогом PowerPC Processor Storage Subsystem (PPSS) в PPE. Основная задача MFC — перемещать данные между локальной памятью SPU и основной памятью Cell, а также синхронизировать SPU со его соседями.
Для выполнения своих обязанностей MFC содержит в себе контроллер DMA, чтобы поддерживать связь между шиной EIB и локальной памятью SPU. Кроме того, MFC содержит другой компонент под названием Synergistic Bus Interface (SBI), который находится между шиной EIB и контроллером DMA.
Это довольно сложная схема для обобщения, но она в основном интерпретирует команды и данные, полученные извне, и подает сигналы внутренним блокам SPE. Являясь входной дверью для Cell, SBI работает в двух режимах: ведущая шина (master) (где SPE адаптирован для запросов данных снаружи) и ведомая шина (slave) (где SPE настроен на прием запросов извне).
Любопытный факт: если учитывать ограничение пакетов EIB (длиной до 128 бит), то в MFC блок DMA может перемещать только до 16 КБ данных за такт, иначе EIB вызовет исключение «Bus Error» во время выполнения [17].
2.6.1.2. Synergistic Processor Unit
Блок Synergistic Processor Unit (SPU) — это часть SPE, в котором находится основной процессор, аналогично «PPU» в PPE.
В отличии от PPU, SPU изолирован от остальной части Cell. Следовательно, между PPU или другими блоками SPU нет общей памяти. Вместо этого SPU содержит локальную память, используемую в качестве рабочей области. Однако, содержимое локальной памяти можно п
