[Из песочницы] Свой pix2code с блэкджеком, но без нейронок
Ньютон — Лейбниц, Лобачевский — Гаусс, Белль — Грей, Бонд — Лассель… Эти пары фамилий объединяет одно: их можно привести как примеры так называемых множественных открытий: ситуаций, когда несколько учёных или изобретателей делают свою работу одновременно и независимо.
Нечто похожее произошло и с моим проектом. Чуть менее года назад я приступил к разработке системы генерации HTML — вёрстки на основе растрового изображения. Прошло немного времени, и в мае 2017 года была опубликована работа под названием pix2code, при этом получив неплохое распространение в специализированных СМИ. Время шло, я не отчаивался, двигаясь по своему пути. Но недавно произошло страшное: разработчики из FloydHub на основе pix2code создали свою нейронную сеть, верстающую сайты на основе картинок. В рунете эту новость подхватили, и о релизе FloydHub стало известно большому количеству людей. И это в тот момент, когда согласно заранее заданному мною же плану я должен был выпускать своё демо. Но, как известно, лучшее — враг хорошего, и желание улучшить проект «ещё и ещё» отложило релиз на неопределённое время.
В этот момент я понял: кодить, это, конечно, хорошо, но надо выносить свою работу в свет. Встречайте: «Щелкунчик» — альтернатива pix2code с блэкджеком, но, увы, без нейронок.
Прежде всего, хочу поправить себя. Множественным открытием «Щелкунчик» (историю названия проекта пока вынесем за скобки), и pix2code назвать нельзя: реализация задач различается в корне. Но назначение обеих систем совпадает чуть более, чем полностью: создать алгоритм, который принимает на вход простое растровое изображение и возвращает приемлемую html/css-вёрстку, которая, с одной стороны, достаточно точно воссоздаст исходный рисунок, а с другой — не вызовет у человека тошноту и даже будет вполне пригодна для дальнейшего сопровождения.
Назначение Щелкунчика
Надо сказать, что для решения задач, близких поставленной, уже существуют продукты (рекламу конкретным сервисам давать не буду, но гуглится довольно легко):
- Генерация html из PSD. Казалось бы, идеальная схема для мира сайтостроения: дизайнер делает макет в фотошопе — программист получает html-код. Проблема в том, что качество такого макета должно быть соответствующего уровня: дизайнер должен понимать, как верстается страница, и это понимание вложить в логику построения своего макета. По сути, хорошо созданный psd-макет — это наполовину свёрстанный сайт. В идеальном мире такие навыки веб-дизайнера являются базовыми. В реальном мире, к сожалению, доля дизайнеров такой компетенции оставляет желать лучшего.
- Конструктор сайта. Человек без опыта программирования заходит в программу и drug&drop«ом накидывает элементы, получая в итоге самый настоящий веб-сайт с модными стилями, работающими скриптами и всеми прелестями современного веба. Возможно, даже адаптивный. Возможно, даже кроссбраузерный. Минусы, я думаю, вы знаете все сами. Опустим даже качество полученного кода и сложность его дальнейшей поддержки. Самая большая проблема, которую вижу здесь я — это смешение ролей. Представить, что дизайнер променяет Его Величество Photoshop на сомнительные конструкторы, так же сложно, как представить архитектора зданий, создающего макеты с помощью LEGO. Вот и получается, что вместо работы коллектива профессионалов сайт создаёт «Сам себе дизайнер/frontend/seo-специалист».
- Шаблонизация сайтов. Изменённый вариант конструктора. Выбираете шаблон — заполняете поля — готово. Ввиду детерминированности можно ожидать неплохое качество кода. Но выбор, сами понимаете, ограничен.
Каждый из этих способов быстро получить сайт великолепно справляется с поставленной задачей в определённых условиях. Подробнее говорить об этом сейчас не имеет смысла. Я затронул их только для того, чтобы более точно дать понять, как я вижу назначение алгоритмов «img → html», и в каком контексте стоит их рассматривать.
В комментариях к публикациям о работе FloydHub можно часто увидеть что-нибудь вроде «пока, верстальщики»,»- frontend’еры» и т.д. Совершенно точно, это не верно. Что pix2code, что Щелкунчик, что любой другой аналог не стоит рассматривать, как убийца профессии frontend-разработчика. Frontend-разработчик работает не в вакууме — есть требования заказчика, есть корпоративные стандарты, есть логика, есть профессиональное чутьё, и в конце концов, талант. Вложить эти компоненты в ИИ современного уровня невозможно.
Так для чего тогда это нужно? Перейдём, наконец к сути и определим требования к Щелкунчику. Алгоритм должен распознать структуру изображения, выделить как можно больше характеристик объектов в этой структуре (цвет, шрифт, отступы…) и сгенерировать код, реализующий построение распознанной структуры.
При этом не требуется:
- распознать все атрибуты
- воссоздать картинку пиксель-в-пиксель
В идеале, достаточно, чтобы алгоритм безошибочно сгенерировал около 85% кода так, чтобы верстальщик любой квалификации мог без труда добавить оставшиеся 15% — здесь верно указать шрифт текста, там поставить изображение на фон, а где-то «доверстать» нетривиальный случай —, но главное, чтобы не нужно было принципиально менять структуру кода, а также думать о том, как, например, выровнять по высоте те три колонки в футере.
Ещё раз, другими словами, цель: автоматизировать работу создания html/css вёрстки, выполнив очевидные элементы, оставив человеку либо совсем простые случаи, где алгоритм банально ошибся, либо нетривиальные, дав возможность проявить свой гений.
Как мне видится, такая модель пригодится в следующих случаях:
- веб-агентствам в моменты большого завала — дешевле и быстрее, чем нанимать очередного джуниора или отдавать на аутсорс;
- для прототипирования и/или «тестирования» дизайна — появляется возможность более гибко проверять frontend-решения;
- «хочу сайт, как у них» — да-да, у любой палки два конца, в том числе и здесь не обойтись без риска увеличения воровства, но нужно предвидеть и такие моменты.
Немного о pix2code
Скажу пару слов о своём потенциальном конкуренте. Оговорюсь сразу, что с уважением отношусь к проделанной работе и даже не собираюсь «валить» очевидно умных и талантливых людей. Я лишь выскажу своё мнение о том, что у них получилось, и, что ещё важнее для текущей статьи, почему я сделал по-другому.
Первая мысль, которая пришла мне в голову, когда я только взялся за задачу: «нейронки». Ну правда, казалось бы, чего проще: берём колоссальное количество страниц из Интернета, делаем dataset из (грубо говоря) скриншотов и соответствующего html-кода, строим нейронку… лучше рекуррентную нейронку…, нет, лучше Байесовскую нейронку…, нет, лучше композицию нейронок… да, много нейронок, глубоких-преглубоких. Натравливаем на обучающую выборку — profit! Так?
Так бы, да не так. Чем больше я шёл по этому пути, тем больше видел проблем. Проблем не технических, а скорее концептуальных. Начнём с составления обучающей выборки. Как известно, не объемом единым сильно машинное обучение. Безусловно, для успешного применения глубокого обучения выборка должна быть ощутимо большая. Но не менее важно, чтобы она была репрезентативна. А вот с этим возникают проблемы. Думаю, что не сильно ошибусь, если скажу, что 90% сайтов обладают вёрсткой, которую… мягко говоря, не хотелось бы заимствовать. Ещё сильнее ситуацию осложняет то, что визуально похожие сайты могут иметь синтаксически принципиально разную вёрстку. Как быть в такой ситуации? Составлять отдельные выборки для каждого из фреймворков, для каждой из методологии? Генерировать собственную обучающую выборку? Понимаю, существуют варианты решения этих поставленных вопросов, но, на мой взгляд, трудоёмкость их выполнения превышает преимущества использования нейронных сетей.
Также хочу обратить внимание ещё на один момент. Здесь я рискую попасть под прицел всех адептов машинного обучения. Как написано во введении статьи, описывающей работу pix2code, чтобы обработать входные данные, не были спроектированы ни процесс извлечения «инженерных» характеристик, ни экспертные эвристики. Казалось бы, в этом и состоит суть машинного обучения: не уповать на заранее заданные экспертами правила, а отталкиваться от того, что есть непосредственно в данных, восстанавливая существующий закон природы. Но здесь я вынужден поспорить. Как я говорил ранее, не всё, чем руководствуется fronted-специалист, заложено в коде разметки. Есть и другие мета-параметры, которые со временем меняются в индустрии, и за которыми нужно следить, чтобы качество сгенерированного кода сохранялось на должном уровне. Можете придать меня анафеме, но я не могу отказаться в данной задаче от элемента экспертных эвристик.
Впрочем, надо признать, что с пути нейронных сетей меня всё-таки увела не принципиальная невозможность или некорректность их использования, а банальная лень и недостаточная квалификация использования мощного и сложного инструмента. С другой стороны, самым неправильным в работе я считаю ориентацию на средства труда, а не на цель. Поэтому я решил начать с более логичного для меня пути, который я опишу ниже. Возможно, если я не заброшу данную работу и это действительно потребует ситуация, я применю и нейронные сети.
Но вернёмся к pix2code и разработке FloydHub. Я прочитал весь опубликованный материал и не нашёл решения проблем, которые описал выше. Что ж, может быть, это не так важно, если код действительно работает? Начну с того, что я так и не смог получить результат на изображениях, кроме тех, что представлены в примерах. Учитывая, что это прототип, можно простить.
Но самое главное я понять так и не смог. Признаюсь честно, я не копал в суть достаточно глубоко, и буду благодарен, если в комментариях мне разъяснят, но как можно объяснить, что после 550 итераций получается код, абсолютно идентичный исходному? То есть полностью, на 100%. Я могу понять, как там оказались те же самые комментарии, но абсолютно одинаковые названия изображений вместе с абсолютно одинаковыми относительными путями вызывают у меня крайнее удивление.
Здесь у меня возникают две мысли: либо это мошенничество (во что, мне искренне не хочется верить), либо это самое жёсткое переобучение, которое я видел. Повторюсь, у меня нет цели завалить проект — я лишь хочу сказать, что это, скорее всего, результат того, что не были учтены проблемы, которые я описал в начале раздела. Я верю, что разработчики исправят данную ситуацию, но на данный момент я не вижу опровержений своим аргументам. Аргументы, которые привели меня к той архитектуре, которая в итоге стала основой Щелкунчика.
Архитектура
Один умный человек сказал, что, когда вы ищете метод решения задачи, найдите 5–6 популярных статей, затрагивающих эту задачу, и выберете тот метод, который критикуется в этих статьях больше всего. В этой статье не будет современнейших подходов и удивительных ноу-хау. Всё довольно прозаично и просто. Тем не менее, чем больше я этим занимаюсь, тем больше, к счастью, убеждаюсь в правильности подхода.
Я решил оттолкнуться от понимания естественного процесса создания вёрстки. Давайте будем честны, большинство верстальщиков использует вечный, единственный и неповторимый метод «копипаст». Изначально copy-paste применяется в прямом смысле. Я сам помню, как, будучи голодным студентом, зарабатывал свои первые деньги, то и дело вводя в google «прижать футер к низу страницы», «выровнять блок по вертикали», «колонки одинаковой высоты». Встречая незнакомый паттерн расположения блоков, ты описываешь его на естественном языке в поисковой строке, затем находишь пример кода в очередном туториале, и наконец изменяешь его под свои нужды. Далее, с опытом, обращений к google становится всё меньше, но принцип никуда не уходит: сталкиваясь с очередным шаблоном, ты достаёшь из своей головы подходящий пример и адаптируешь к текущей ситуации.
В науке такое мышление называется прецедентным. А в IT есть реализация этого процесса: case-based reasoning или «рассуждение на основе прецедентов». Это метод довольно старый (впрочем, нейронные сети тоже нельзя назвать младенцем), уходит историей в 70-е годы прошлого века, и, надо признать, сейчас проходит далеко не пик своего развития. Однако в данной ситуации он идеально вписывается в описанный процесс.
Тем, кто не знаком с данным подходом, во-первых, рекомендую почитать, например, статью Джанет Колоднер, а во-вторых, продолжить чтение данной статьи.
Описывая CBR одним предложением, можно сказать, что это способ решения проблем путём адаптации старых решений похожих ситуаций. Ключевым понятием CBR является прецедент (case). Прецедент — это тройка элементов:
- проблема — состояние мира, которое требуется «разрешить»,
- решение — собственно метод устранения проблемы,
- результат — состояние мира после разрешения проблемы.
Прецеденты хранятся в хранилище, или базе. Способ хранения, индексация, структура — вопросы открытые: можно использовать любой подходящий инструмент.
Самое главное в рассуждениях на основе прецедентов — так называемый CBR-цикл. Собственно, этот цикл — и есть способ решения проблем.
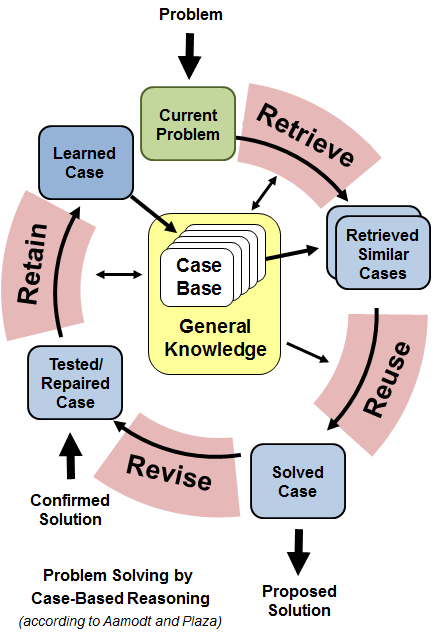
Цикл состоит из четырёх шагов (четыре RE):
- извлечение (retrieve): из базы прецедентов извлекается наиболее близкий (подобный) прецедент для рассматриваемой проблемой,
- адаптация (reuse): извлечённое решение адаптируется, чтобы лучше соответствовать новой проблеме,
- оценка (revise): адаптированное решение может быть оценено либо до его применения, либо после; в любом случае, если решение не подошло, то оно должно быть адаптировано ещё раз, либо извлечены дополнительные решения,
- сохранение (retain): если решение прошло проверку успешно, новый прецедент добавляется в базу.
Прежде чем описать, как именно case-based reasoning был применён для решения данной задачи, стоит описать общую архитектуру системы.
В глобальном смысле обработка состоит из двух частей:
- Распознавание изображения
- Генерация html-кода
Главная задача первого этапа — извлечь из изображения все значимые блоки и построить из них древовидную структуру по отношению вложения.
Обработка изображения происходит в несколько этапов:
- Распознаётся весь текст (здесь нам на помощь приходит tesseract), извлекаются все свойства, связанные с ним — шрифт, цвет, размер, стиль и т.д. –, а затем он полностью затирается фоновым цветом, чтобы не мешался далее.
- Извлекаются все картинки — т.е. всё то, что в последствии станет либо тегом , либо фоновым изображением блоков. Они также затираются.
- Наконец, распознаются все блоки, из которых затем будет собрана иерархия, или другими словами, дерево.
Собрать такое дерево, где каждый узел — это потенциальный dom-елемент, и есть задача первого этапа. Каждый узел описывается набором заранее заданных параметров. Сборка дерева — задача, вообще говоря не тривиальная. Однако, надо сказать, что из всей архитектуры на данный момент этот этап реализован лучше всего, и, если дизайн делал не эпилептик, то почти всегда гарантируется очень точное описание структуры изображения.
Когда дерево готово, переходим ко второму этапу. Обходим дерево префиксным способом, и обрабатываем каждый узел с помощью cbr-цикла.
Настало время чуть более подробно описать реализацию case based reasoning в Щелкунчике.
Прецедент в Щелкунчике имеет следующую структуру:
- Проблема: набор свойств узла, а также свойств его ближайших потомков в json-формате.
- Решение: jinja2-шаблон html и css кода, который реализует вёрстку описываемой структуры.
- Результат: html и css код, который был сгенерирован из решения-шаблона применительно к конкретному случаю.
Прецеденты хранятся в json-представлении в базе MongoDB. Я называю это «глобальным хранилищем». Есть ещё и локальное хранилище — о нём чуть позже. В глобальном хранилище прецеденты имеют только проблему и решение. Результата нет — ведь он появляется только, когда шаблон применяется к конкретной ситуации.
И вот у нас есть json-объект, описывающий структуру изображения, а также база прецедентов, которые содержат информацию, как сверстать каждый узел. Как я говорил ранее, обход дерева префиксный, то есть начинаем с корня. Берём свойства самого корня, добавляем к нему свойства ближайших потомков — вот у нас есть проблема.
Настал этап извлечения. Нужно найти прецедент с самой похожей проблемой. Здесь разворачивается простор для творчества ml-специалиста. По сути имеем классическую задачу многоклассовой классификации: есть свойства объекта, и есть n классов (n прецедентов в базе). Требуется отнести незнакомый нам объект к одному из классов. Хотите попробовать логистическую регрессию? Почему бы нет! Может быть, лучше подойдёт RandomForest? Вполне вероятно! В конце концов, и нейронные сети никто не отменял!
Но на первой итерации я обошёлся… методом k ближайших соседей. Причём, k равен 1. Вы всё верно поняли: я просто использую Евклидову меру и нахожу ближайший объект. Уже сейчас я сталкиваюсь со всеми минусами такого простого подхода, однако он более чем позволяет добиться приемлемого качества и не застревать на этом моменте, а постепенно двигаться по всем фронтам и доводить общий рисунок до конца.
Получив ближайший прецедент, нам теперь нужно адаптировать его решение для обрабатываемого узла. Здесь есть несколько задач:
- Из шаблона на jinja2 получить реальный код.
- Обработать css-классы: скорее всего, на предыдущих шагах нам уже встречались классы с таким названием. Есть несколько вариантов, как обработать такую ситуацию: либо создать совершенно новый класс, а в html сделать необходимые замены; либо создать еще один класс, который уточняет свойства объекта, и в html добавить его там, где нужно; либо понять, что это частный случай предыдущего результата и вообще ничего не делать — и так всё чудесно.
По канонам case based reasoning следующим шагом следует оценить полученный результат. И здесь, признаюсь, я встал в тупик. Как оценить, что вёрстка получилась действительно той, которая требуется? Какие критерии можно придумать? Мучительные терзания и поиски озарения привели меня к тому, чтобы написать в функции revise «return True» и двигаться дальше. Оценку я пока не реализовал. И что-то мне подсказывает, что, возможно, и не реализую никогда: достаточно будет сделать хороший классификатор на этапе извлечения и пригодную адаптацию.
Последний шаг — сохранение. Прецедент, который изначально содержал только проблему, теперь получил своё решение и результат. Его необходимо записать в хранилище, чтобы потом на основе него можно было более просто сверстать похожий блок. Но здесь я придумал хитрость. Прецедент записывается не в «глобальное хранилище», а в локальное. Локальное хранилище — это своего рода контекст для конкретного изображения. Он содержит блоки, которые уже присутствуют в текущем документе. Это позволяет, во-первых, легче находить похожие прецеденты, во-вторых, меньше тратить ресурсов на адаптацию и вообще минимизировать ошибки, когда одна и та же структура верстается по-разному. При обработке следующего узла дерева будет произведена попытка извлечения похожей проблемы сначала из локального хранилища, и только потом, если ничего похожего найти не удалось, алгоритм пойдёт в хранилище глобальное.
Если описать все эти шаги менее формально, то суть сводится примерно к такому рассуждению:
- Смотрим на макет с точки зрения самого верхнего уровня абстракции.
- Видим, что, например, это трёх-колоночный макет. Задаёмся вопросом, как же сверстать такой макет?
- Ищем в базе прецедентов самый подходящий случай.
- Получаем шаблон html и css.
- Подставляем в этот шаблон конкретные значения рассматриваемого случая (ширину, цвет, отступы и т.д.).
- Далее, рекурсивно обрабатываем каждый из потомков:
- Так, что тут у нас… В левой колонке пять блоков, расположенных вертикально. Как же это сверстать? Глянем в базу…
- …
- В центральном блоке видим три блока, расположенных вертикально, первый занимает 20% высоты, второй — 70%, третий — 10%
- и т.д.
- Так, что тут у нас… В левой колонке пять блоков, расположенных вертикально. Как же это сверстать? Глянем в базу…
Пример
Устали от букв? Сейчас будут картинки. И код.
Лично я двигаюсь от простого к сложному. Брать заведомо сложный сайт с кучей элементов — так можно убить себе психику и потерять ночи сна, разгребая результаты и причины неудач. Поэтому мой «Hello World» — это, в сущности, модульная сетка типового сайта.

Я подготовил вот такой макет: сайт с фиксированной шириной контента, резиновой шапкой, подвалом, прижатом к низу страницы, и сайдбаром. Посмотрим, как справится с ней Щелкунчик.
Первый этап — распознавание структуры. Результат таков:
{
"width": 2560,
"margin_bottom": null,
"the_same_bkgr_as_parent": null,
"margin_left": null,
"depth": 1,
"children_amount": 2,
"width_portion": 1.0,
"height": 1450,
"padding_right": 0,
"height_portion": 1.0,
"alignment": 1,
"background": null,
"margin_top": null,
"children_proportion": [
0.12275862068965518,
0.8772413793103448
],
"relative_position": null,
"children": [
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 2,
"children_amount": 0,
"width_portion": 1.0,
"height": 178,
"padding_right": null,
"height_portion": 0.12275862068965518,
"alignment": null,
"background": [
252,
13,
28
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
1.0,
0.12275862068965518
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
},
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": true,
"margin_left": 0,
"depth": 2,
"children_amount": 3,
"width_portion": 1.0,
"height": 1272,
"padding_right": 0,
"height_portion": 0.8772413793103448,
"alignment": 0,
"background": null,
"margin_top": 0,
"children_proportion": [
0.1171875,
0.765625,
0.1171875
],
"relative_position": [
0.0,
0.12275862068965518,
1.0,
1.0
],
"children": [
{
"width": 300,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 3,
"children_amount": 0,
"width_portion": 0.1171875,
"height": 1272,
"padding_right": null,
"height_portion": 0.8772413793103448,
"alignment": null,
"background": [
255,
255,
255
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
0.1171875,
1.0
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": true,
"type": "node",
"padding_left": null
},
{
"width": 1960,
"margin_bottom": 0,
"the_same_bkgr_as_parent": true,
"margin_left": 0,
"depth": 3,
"children_amount": 2,
"width_portion": 0.765625,
"height": 1272,
"padding_right": 0,
"height_portion": 0.8772413793103448,
"alignment": 1,
"background": null,
"margin_top": 0,
"children_proportion": [
0.8742138364779874,
0.12578616352201258
],
"relative_position": [
0.1171875,
0.0,
0.8828125,
1.0
],
"children": [
{
"width": 1960,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 4,
"children_amount": 1,
"width_portion": 0.765625,
"height": 1112,
"padding_right": 1560,
"height_portion": 0.766896551724138,
"alignment": 0,
"background": [
128,
128,
128
],
"margin_top": 0,
"children_proportion": [
0.20408163265306123
],
"relative_position": [
0.0,
0.0,
1.0,
0.8742138364779874
],
"children": [
{
"width": 400,
"margin_bottom": 112,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 5,
"children_amount": 0,
"width_portion": 0.15625,
"height": 1000,
"padding_right": null,
"height_portion": 0.6896551724137931,
"alignment": null,
"background": [
14,
126,
18
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
0.20408163265306123,
0.8992805755395683
],
"children": [],
"padding_bottom": null,
"margin_right": 1560,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
}
],
"padding_bottom": 112,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
},
{
"width": 1960,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 4,
"children_amount": 0,
"width_portion": 0.765625,
"height": 160,
"padding_right": null,
"height_portion": 0.1103448275862069,
"alignment": null,
"background": [
11,
36,
251
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.8742138364779874,
1.0,
1.0
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
}
],
"padding_bottom": 0,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
},
{
"width": 300,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 3,
"children_amount": 0,
"width_portion": 0.1171875,
"height": 1272,
"padding_right": null,
"height_portion": 0.8772413793103448,
"alignment": null,
"background": [
255,
255,
255
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.8828125,
0.0,
1.0,
1.0
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": true,
"type": "node",
"padding_left": null
}
],
"padding_bottom": 0,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
],
"padding_bottom": 0,
"margin_right": null,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
Ключевыми свойствами здесь являются type (может быть node, text или image) и alignment (0 — потомки расположены по горизонтали, 1 — по вертикали). Вы можете провести анализ json самостоятельно, но для наглядности я отобразил, какое дерево построил алгоритм (фоновые цвета блоков соответствует цвету круга, черные круги — композиционные блоки, цифра в круге соответствует параметру alignment):

Начинаем обход дерева. Формируем проблему из описания корневого узла:
{
"width": 2560,
"margin_bottom": null,
"the_same_bkgr_as_parent": null,
"margin_left": null,
"depth": 1,
"children_amount": 2,
"width_portion": 1.0,
"height": 1450,
"padding_right": 0,
"height_portion": 1.0,
"alignment": 1,
"background": null,
"margin_top": null,
"children_proportion": [
0.12275862068965518,
0.8772413793103448
],
"relative_position": null,
"children": [
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": false,
"margin_left": 0,
"depth": 2,
"children_amount": 0,
"width_portion": 1.0,
"height": 178,
"padding_right": null,
"height_portion": 0.12275862068965518,
"alignment": null,
"background": [
252,
13,
28
],
"margin_top": 0,
"children_proportion": null,
"relative_position": [
0.0,
0.0,
1.0,
0.12275862068965518
],
"children": [],
"padding_bottom": null,
"margin_right": 0,
"padding_top": null,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": null
},
{
"width": 2560,
"margin_bottom": 0,
"the_same_bkgr_as_parent": true,
"margin_left": 0,
"depth": 2,
"children_amount": 3,
"width_portion": 1.0,
"height": 1272,
"padding_right": 0,
"height_portion": 0.8772413793103448,
"alignment": 0,
"background": null,
"margin_top": 0,
"children_proportion": [
0.1171875,
0.765625,
0.1171875
],
"relative_position": [
0.0,
0.12275862068965518,
1.0,
1.0
],
"padding_bottom": 0,
"margin_right": 0,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
],
"padding_bottom": 0,
"margin_right": null,
"padding_top": 0,
"font_weight": null,
"the_same_bkgr_as_global": false,
"type": "node",
"padding_left": 0
}
В базе прецедентов производится поиск прецедента с самой похожей проблемой. Извлекается следующий прецедент:
{
"_id" : ObjectId("5a1ec4681dbf2cce65357bc4"),
"problem" : {
"children_proportion" : [
0.11,
0.89
],
"alignment" : 1,
"depth" : 1,
"height_portion" : 1.0,
"width_portion" : 1.0,
"children_amount" : 2,
"children" : [
{
"relative_position" : [
0.0,
0.0,
1.0,
0.11
],
"depth" : 2,
"height_portion" : 0.11,
"width_portion" : 1.0,
"the_same_bkgr_as_global" : false
},
{
"children_proportion" : [
0.15,
0.7,
0.15
],
"alignment" : 0,
"relative_position" : [
0.0,
0.11,
1.0,
1.0
],
"depth" : 2,
"height_portion" : 0.89,
"width_portion" : 1.0,
"children_amount" : 3,
"the_same_bkgr_as_global" : false,
"children" : [
{
"relative_position" : [
0.0,
0.0,
0.15,
1.0
],
"depth" : 3,
"height_portion" : 0.89,
"width_portion" : 0.15,
"children_amount" : 0,
"the_same_bkgr_as_global" : true
},
{
"the_same_bkgr_as_parent" : true,
"children_proportion" : [
0.89,
0.11
],
"alignment" : 1,
"relative_position" : [
0.15,
0.0,
0.85,
1.0
],
"depth" : 3,
"height_portion" : 0.89,
"width_portion" : 0.7,
"children_amount" : 2,
"the_same_bkgr_as_global" : false
},
{
"relative_position" : [
0.85,
0.0,
1.0,
1.0
],
"depth" : 3,
"height_portion" : 0.89,
"width_portion" : 0.15,
"children_amount" : 0,
"the_same_bkgr_as_global" : true
}
]
}
],
"the_same_bkgr_as_global" : false
},
"solution" : {
"html" : "{{ children[0]['content'] }} {{ children[1]['children'][1]['children'][0]['content'] }}",
"css" : "html,body,.wrapper {height: 100%;}.content {box-sizing: border-box;min-height: 100%;padding-top: {{ children[0]['height'] }};padding-bottom: {{ children[0]['height'] }};background:{{ children[1]['children'][1]['children'][0]['background'] }};}header{height: {{ children[0]['height'] }};margin-bottom: -{{ children[0]['height'] }};background:{{ children[0]['background'] }};position:relative;z-index:10;}.container{width:{{ children[1]['children'][1]['width'] }};margin-left: auto;margin-right: auto;}footer {height: {{ children[1]['children'][1]['children'][1]['height'] }};margin-top: -{{ children[1]['children'][1]['children'][1]['height'] }};background:{{ children[1]['children'][1]['children'][1]['background'] }};}"
},
"outcome" : null
}
Как мы видим, чтобы сгенерировать код html, необходимо получить свойство content у потомков, а сделать это можно, только обработав каждый из потомков тем же образом, что и текущий узел. Поэтому обходим дерево дальше, пока не достигнем всех листьев, у которых content будет пустой строкой.
Что касается css, то весь сгенерированный код из шаблона записывается в единый файл, попутно обрабатываются конфликты.
В итоге получился следующий код (обрабатывалось изображение большого размера, соответственно, получились такие большие значения):
aside.left {
background : rgb(14, 126, 18);
height : 1000px;
width : 400px;
float : left;
}
html,body,.wrapper {
height : 100%;
}
footer {
background : rgb(11, 36, 251);
height : 160px;
margin-top : -160px;
}
.container {
width : 1960px;
margin-left : auto;
margin-right : auto;
}
header {
background : rgb(252, 13, 28);
height : 178px;
margin-bottom : -178px;
z-index : 10;
position : relative;
}
.content {
box-sizing : border-box;
min-height : 100%;
padding-top : 178px;
padding-bottom : 178px;
background : rgb(128, 128, 128);
}
Результаты
На данный момент Щелкунчик справляется со следующими задачами:
- Извлечение структуры из изображения.
- Распознавание текста, шрифта, размера, стиля.
- Извлечение картинок из скриншота.
- Распознавание отступов и полей.
- Поиск ближайшего прецедента.
- Обработка конфликтов при составлении css-файла.
В ближайшее время планируется реализовать:
- Распознавание границ (borders): цвет, тип, ширина, закругление.
- Распознавание таблиц.
- Распознавание градиента.
- Обработка фиксированных блоков (display: fixed и display: absolute)
На мой взгляд, получается довольно многообещающая система, имеющая множество точек роста. Даже при самых примитивных методах Щелкунчик справляется с простыми задачами. Если же упаковать его более умными методами, как в плане распознавания изображения, так и при извлечении ближайших прецедентов, программа вполне будет способна работать с подавляющей частью дизайн-макетов.
Ещё одна приятная особенность — вариативность вёрстки. Имея несколько версий баз прецедентов, можно заставить Щелкунчика верстать, например, по bem-методологии, или использовать bootstrap определённой версии. А ещё компании могут занести в него свои корпоративные стандарты, и он не только будет сам верстать как сотрудник компании, но и можно будет оценивать, насколько та или иная вёрстка следует стандартам, сравнивая со сгенерированным кодом.
Может показаться, что заполнение такой базы — весьма трудоёмкий процесс. С этим, конечно, трудно поспорить, но лично я предполагаю, что будет достаточно порядка 100 прецедентов, чтобы покрыть большую часть задач. А заполнить такой объём, в принципе, соизмеримо со временем на типовой проект. Таким образом, frontend-специалисты смогут, один раз, инвестировав время на заполнение базы, затем разительно увеличить свою производительность.
Одна из целей статьи — получить обратную связь от сообщества. Сейчас у меня явное ощущение, что, глубоко закопавшись в данный проект, я могу не увидеть леса за деревьями. Поэтому буду признателен за конструктивную и даже не очень конструктивную критику в комментариях.
