[Из песочницы] Создание поиска по библиотеке юным программистом — каково это?
На днях наткнулся на публикацию моего ровесника, и она побудила меня написать и свою историю о своем проекте, который абсолютно так же не помог, а только помешал поступлению в ВУЗ.

В один прекрасный денек я зашёл в библиотеку за одним рассказом. Сказав название и автора рассказа библиотекарю, получил стопку сборников данного автора. Для того чтобы найти среди всего этого многообразия нужный рассказ, пришлось перебрать все произведения. Намного легче было бы «загуглить» нужное произведение и получить желаемое в несколько кликов.
И тогда я задумался: «А почему в библиотеках до сих пор нет подобного? Это же так удобно!». Естественно, как любой порядочный ленивый программист, я пошел прямиком в поисковик искать подобные проекты. И столкнулся с проблемами. Все найденные проекты были либо коммерческими (платными), либо любительскими и некачественными.
Естественно, подобную несправедливость срочно нужно было решать, несмотря на приближающееся ЕГЭ и поступление в ВУЗ.
Первым делом стало понятно, что без веб-части не обойтись. Несмотря на мою личную непереносимость к веб-программированию, я сел за гугл и начал изучать данный вопрос.
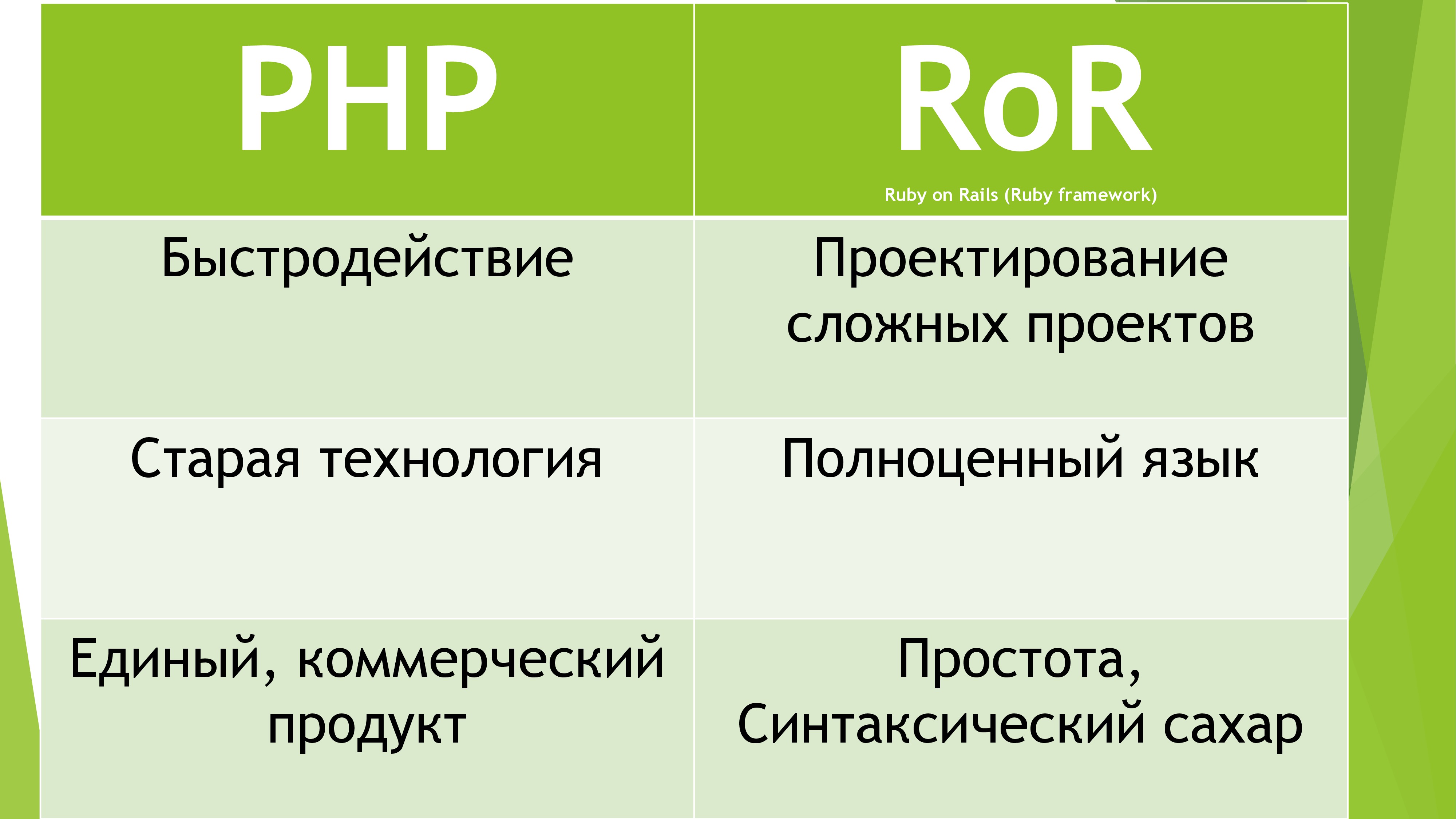
После нескольких часов я наконец-то выбрал необходимый язык. Точнее не язык, а FrameWork RubyOnRails. Почему он? Потому что он использует полноценный ООП язык, активно разрабатывается гигантским комьюнити и обладает быстрым ядром. К тому же, Ruby любят девушки (на презентации лучше не говорить).
Естественно, основан он был на «прекрасном» языке Ruby. Так как я на уровне Junior знаю Java, изучить любой другой ООП язык для меня не составило труда. Неделю каждый вечер смотрел по 2 лекции и в итоге мог похвастаться необходимыми знаниями синтаксиса Ruby. И потом мою самоуверенность опустили… А всё потому, что данный FrameWork настолько огромен и обширен, что знания Ruby помогли мне лишь чуть-чуть. Изучив MVC технологию и прочие задумки злобных веб-программистов, я приступил к реализации проекта.
Первым препятствием на моем пути стала, как это ни странно, авторизация. Решил я использовать технологию OAuth. Принцип её заключается в том, что используются токены вместо паролей. Использование токенов позволяет не беспокоиться, что твой пароль украдут, а так же настраивать каждый токен под себя (к примеру, можно брать одноразовые токены с правами лишь на одну операцию). Для хранения паролей на серверной части вначале я решил использовать MD5 шифрование, однако почитав про него в интернете, я решил, что данный метод устарел. Взлом на новых компьютерах осуществляется всего за 1 минуту. Поэтому я решил использовать bCrypt, который обеспечивает почти 100% защиту от расшифровки пароля в БД. Так как я решил самостоятельно сделать подобную систему, пришлось думать над оптимизацией. В первую очередь, токены пришлось переводить из строки в числовое значение, чтобы по БД можно было искать бинарным поиском.

Казалось бы, что сложного может быть в простейшем школьном проекте с авторизацией? Начнем с того, что окошко авторизации я делал 20 часов. А продолжим тем, что мой проект полностью OpenSource и запускается в локальной сети, а это значит, что достаточно развернуть свой сервер на мобильном, чтобы перехватывать токены. Поэтому я придумал собственную систему проверки валидности сервера. С каждым токеном сервер выдает два значения. ID в базе данных и уникальный малочисленный индетификатор. Каждый раз, когда клиент хочет проверить валидность сервера, он отправляет ID серверу, а сервер возращает ему индетификатор. И только тогда клиент отправляет серверу токен. Получается авторизация с двух сторон.
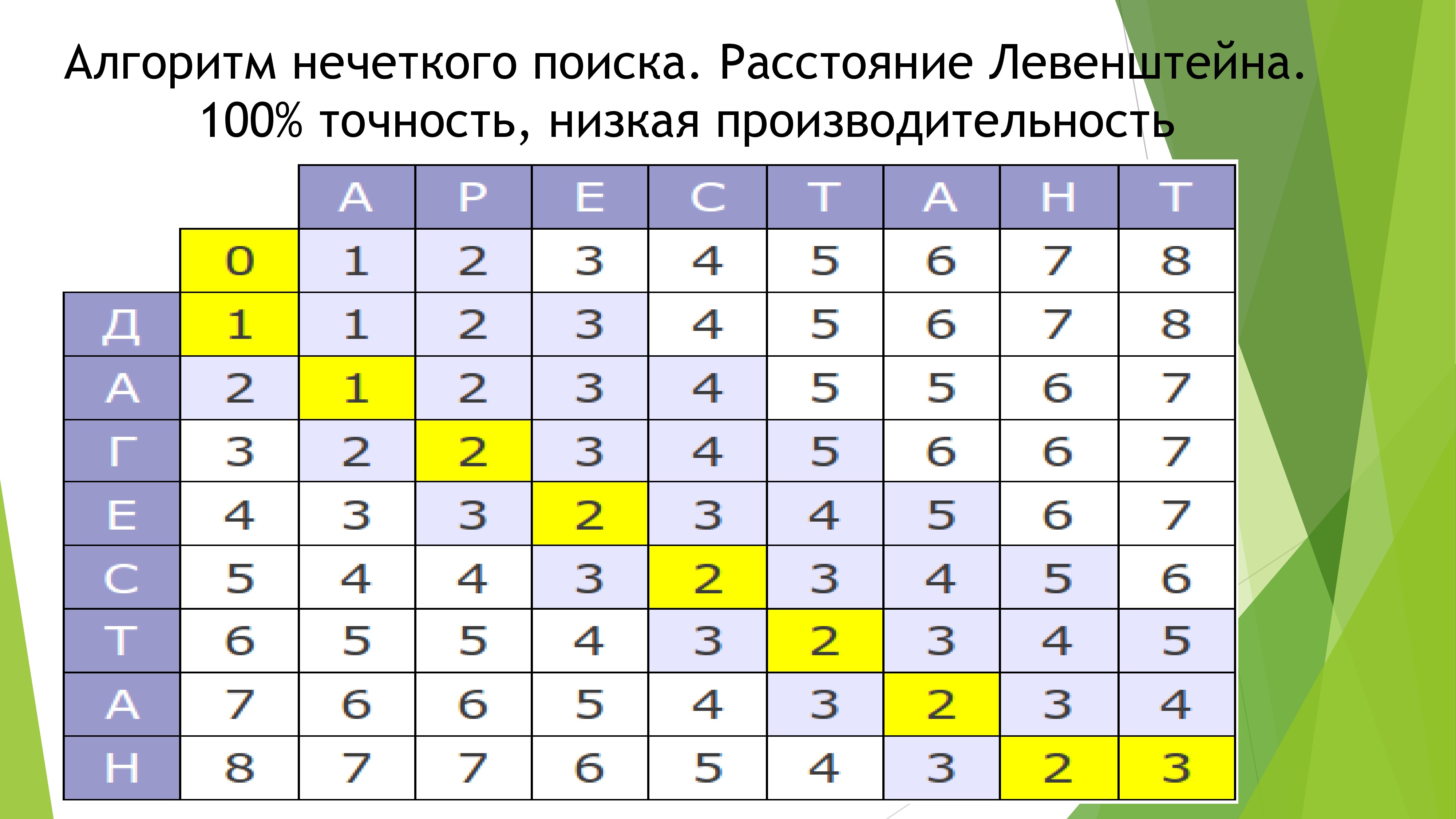
Во всех подобных проектах слабая сторона — поиск. Я бы не хотел, чтобы и в моем проекте присутствовал такой недостаток. Использование готовых решений полностью отметается по причине того, что все крупные поисковики требуют соединения с интернетом. Поэтому к данному вопросу я подошел со всей серьезностью. Почитав книгу про алгоритмы, я решил, что для сравнения строк лучше использовать алгоритм расстояния Дамерау-Левенштейна, так как он обладает максимальной точностью в ущерб производительности, что наиболее важно для проекта. Но возникла проблема в сравнении целых предложений. Сначала я использовал подобный алгоритм, разложив таблицу сравнения на древо графов. Довольно долго я мучался с этим, но в итоге получил не тот результат. Поэтому всё снес и вставил другой алгоритм в сравнение предложений. Его принцип прост до безумия. Если слово имеет меньше 3 ошибок, принять его за правильное и добавить в итоговый индекс 1 балл. Если два правильных слова идут подряд, добавить ещё 1 балл. И так далее.
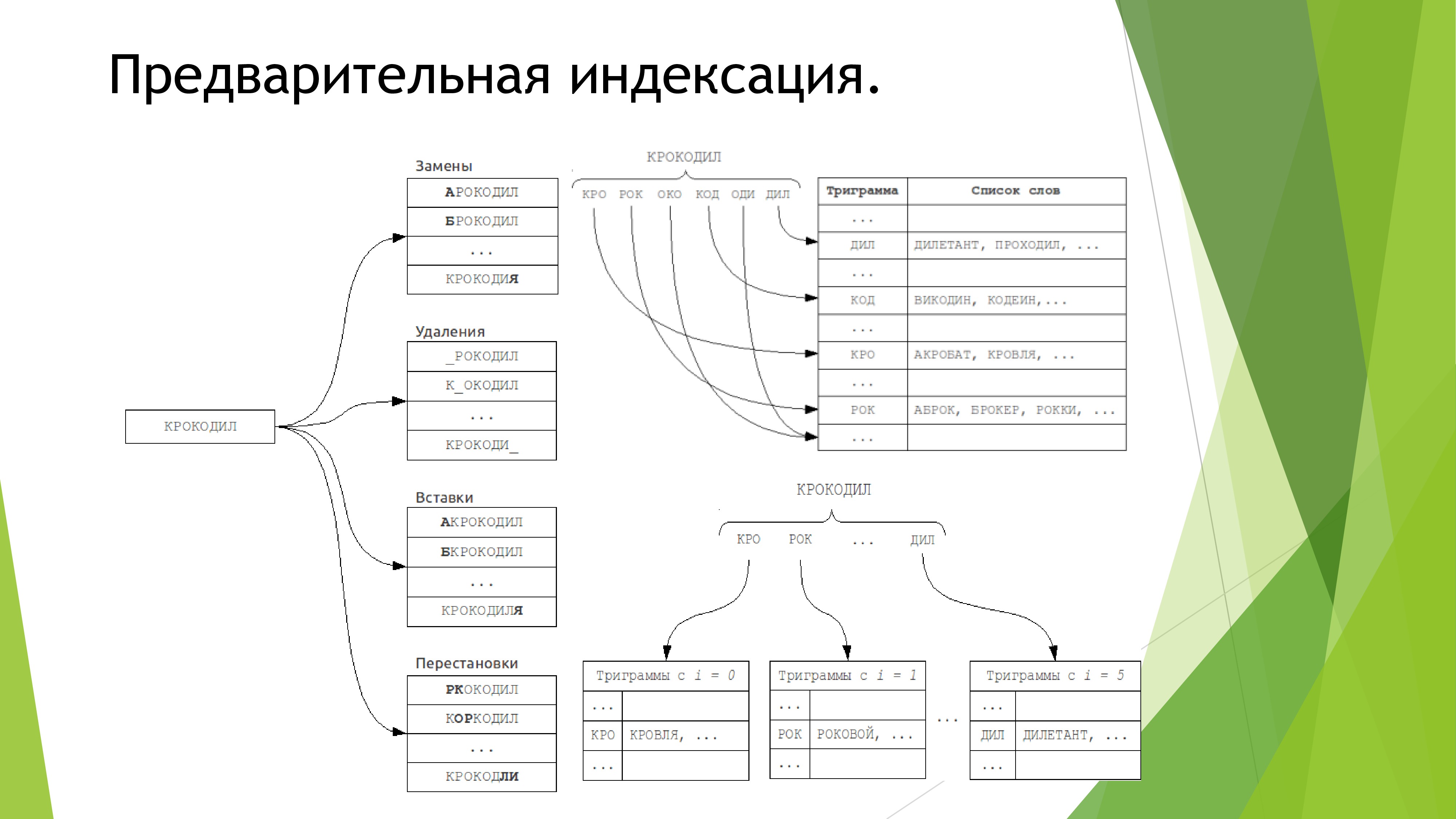
Так как поиск весьма жестко задан, использовать синтаксический смысл предложения не имеет смысла. Поэтому в будущем планируется добавить фонетический поиск и дальше работать в сторону улучшения самообучения системы и централизации всех данных.

Ещё одним способом улучшить качество поиска стало самообучение. Дело в том, что каждый запрос записывается в БД и при необходимости возомжно выдавать добавлять баллы популярным книгам. Допустим, пользователь «Гоша» любит фантастику. Мы это поняли по тому, что количество найденных книг по фантастике намного превышает другие жанры. Поэтому впоследствии, при выдачи результатов поиска, система поиска будет добавлять пользователю «Гоша» дополнительные баллы для книг по фантастике. К тому же, такой большой пласт статистических исследований пригодиться.
Естественно, данный алгоритм потом обзавелся различными оптимизациями, но об этом в другой раз. Такой ресурсоемкий алгоритм я решил реализовать на C++ и сделать мостик из Ruby с помощью плагина Rice. Вот ещё один наглядный пример, почему я выбрал RubyOnRails и не пожалел.
Решить проблему быстрой оцифровки библиотеки поможет только механизмы распознавания текста на картинке. Так как подносить к веб-камере ПК изображение для считывания довольно глупо, было принято решение разработать мобильное приложение для смартфонов. Написание базового приложения заняло порядка недели т.к. в смартфонах активно используется многопоточность и довольно жёсткие критерии для дизайна приложения.
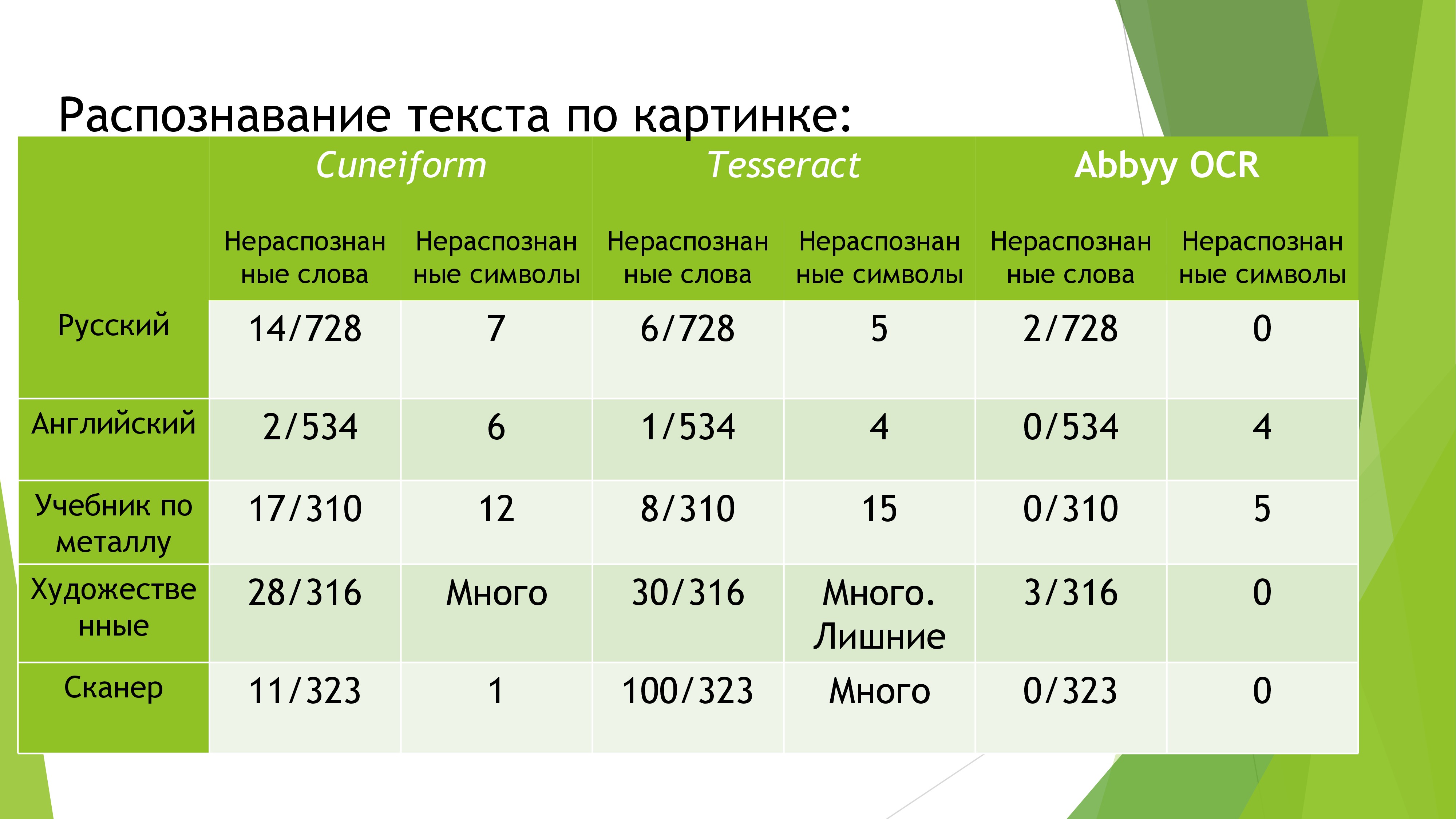
После, проведя глубокий анализ существующих решений, я выбрал Tessaract как самый лучший бесплатный open-source продукт, основанный на технологии OCR. К тому же, активно поддерживаемый Google. Попробовав с ним поиграться, я понял, что такой результат никуда не годиться. Для точного распознавания пришлось бы довольно долго работать с предварительной обработкой изображения. К тому же, в исходниках данного проекта я обнаружил пару грубых алгоритмических ошибок, исправление которых может затянуться на доооолго. Поэтому с грустью в голосе я пошёл просить временную лицензию у Abbyy. Спустя две недели ежедневных звонков, я получил её. Не могу не отметить, что документация и Java-обертка очень грамотно написаны и было в одно удовольствие работать с таким продуктом. Однако, механизм распознавания далёк от 100% точности. Поэтому мне пришлось делать автокоррекцию. За несколько часов я написал бота, который скачал всю БД книг с популярного сайта labirint.ru. Использовав подобную базу и вышеупомянутый алгоритм поиска, точность распознавания книг повысилось в разы.

Несмотря на очевидную простоту использования считывания книг, я решил использовать автозаполнение полей через ISBN. Так как скачать всю БД книг ISBN глупо, решил использовать Google Book Api для поиска по ISBN. Так же Offline-пользователям до сих пор доступна БД лабиринта с >200 000 русскоязычных книг. К тому же, легко реализовать сканер штрих-кода книг (на том же Abbyy API) и тогда добавление книг будет только в удовольствие.

Я подумал, что неплохо бы было сфотографировать полку и добавить все книги в электронный каталог. Реализовать такое легко возможно только с использованием бесплатной библиотеки OpenCV и с встроенным детектором границ Кенни. К тому же, потребуется написать свой алгоритм для более серьёзного анализа основных линий книг и отправлять каждый корешок в Abbyy API и получать нужный текст, обрабатывать его через БД лабиринта и отображать элементы взаимодействия с UI поверх сфотографированного изображения. (К сожалению, у меня так и не дошли руки допилить этот функционал до ума. Времени нет)

Низкая стоимость проекта и обширная технологическая база позволяет получить доступ к высоким и удобным технологиям даже ученикам обычных муниципальных школ. Прошу взять тот факт за внимания, что продукт абсолютно открытый и прекрасно работает без доступа к интернету. К тому же, ресурсоемкость проекта позволяет запустить сервер даже на Raspberry PI, стоимостью 20$.
Несмотря на то, что это мне не помогло никак в жизни, я получил ценный опыт разработки полноценного сайта и приложения и мне это было дико интересно. Ну и пара скринов:

Источники информации
- Большое спасибо англоязычной аудитории сайта www.stackoverflow.com
- Большое спасибо пользователю habrahabr.ru ntz за серию шикарнейших статей по нечеткому поиску
- Также в проекте были использованы материалы www.wikipedia.org
- Большое спасибо моей однокласснице Евгении Лендрасовой за красивые и яркие логотипы
- Гигантское спасибо моему преподавателю за поддержку в моих начинаниях
- Гигантское спасибо компании ABBYY за предоставленный OCR для распознавания текста. Без него я бы не смог реализовать этот проект
