[Из песочницы] PostgreSQL и btrfs — слон на маслянной диете
Недавно, просматривая статью на вики про файловые системы, заинтересовался btrfs, а именно его богатыми возможностями, стабильным статусом и главное — механизмом прозрачного сжатия данных. Зная, как легко жмутся базы данных содержащие текстовую информацию, мне стало любопытно уточнить на сколько это применимо в сценарии использования например с postgres.
Данное тестирование конечно нельзя назвать полным, ибо задействовано только чтение и то линейное. Но результаты уже заставляют поразмыслить на тему возможного перехода на btrfs в определенных случаях.
Но основная цель — узнать мнение сообщества о том, на сколько это разумно и каких подводных камней может таить в себе подход прозрачного сжатия на уровне файловой системы.
Для тех, кто не хочет тратить время, сразу расскажу про полученные выводы. БД PostgreSQL размещенная на btrfs c опцией compress=lzo, сокращает объем бд в двое (в сравнении с любыми ФС без сжатия) и при использовании многопоточного, последовательного чтения, значительно сокращает нагрузку на дисковую подсистему.
Итак, что в наличии
Физический сервер — 1 шт
- CPU: 2 Сокета по 6 ядер
- RAM: 48 ГБ
- Storage:
- 2x — SAS 10K 300GB в конфигурации RAID 1 + 0 — для ОС и основной бд postgres
- 2x — SAS 10K 300GB в конфигурации RAID 1 + 0 — для тестов
- OS: Ubuntu 14.04.2 — 3.16.0–41
- PG: 9.4.4×86_64
Методика тестирования
Итак, у нас имеется физическая машина с 2-мя дисками: на первой хранится основная бд postgres (которая после initdb), а второй диск полностью, без создания на нем разметки форматируется в тестируемые ФС (ext4, btrfs lzo/zlib).
На испытуемый диск кладется табличное пространство из резервной копии, которое участвует в тестировании, сделанное с помощью pg_basebackup. Восстанавливается так же и основная бд postgres.
Суть тестирования заключается в последовательном чтении пяти таблиц — клонов в пять потоков.
Скрипт экстремально простой и являет собой обычный «explain analyze».
Каждая таблица имеет размер 13ГБ, общий объем ~ 65ГБ.
Данные для графиков берем из sar с самыми простыми параметрами: «sar 1» — CPU ALL; «sar -d 1» — I/O.
Перед каждым запуском сбрасываем pagecache с помощью команды:
free && sync && echo 3 > /proc/sys/vm/drop_caches && free
Проверяем завершение фоновых процессов:
SELECT sa.pid, sa.state, sa.query
FROM pg_stat_activity sa;
Цифры
Размеры
| ФС | Размер в БД | Размер на диске | Фактор сжатия |
|---|---|---|---|
| btrfs-zlib | 156GB | 35GB | 4.4 |
| btrfs-lzo | 156GB | 67GB | 2.3 |
| ext4 | 156GB | 156GB | 1 |
Последовательное чтение (explain analyze)
| btrfs-zlib | 302000 ms |
| btrfs-lzo | 262000 ms |
| ext4 | 420000 ms |
Графики
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 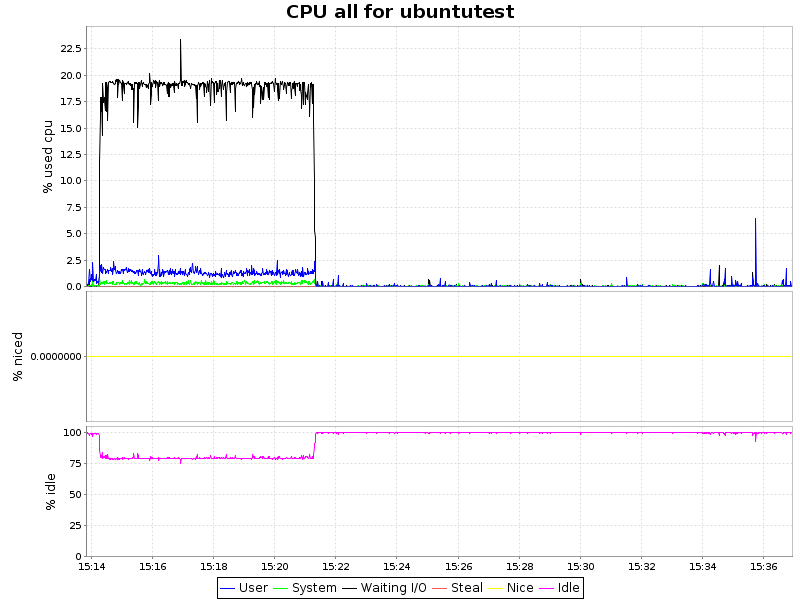 |
| btrfs-zlib |  |
| btrfs-lzo |  |
| ext4 | 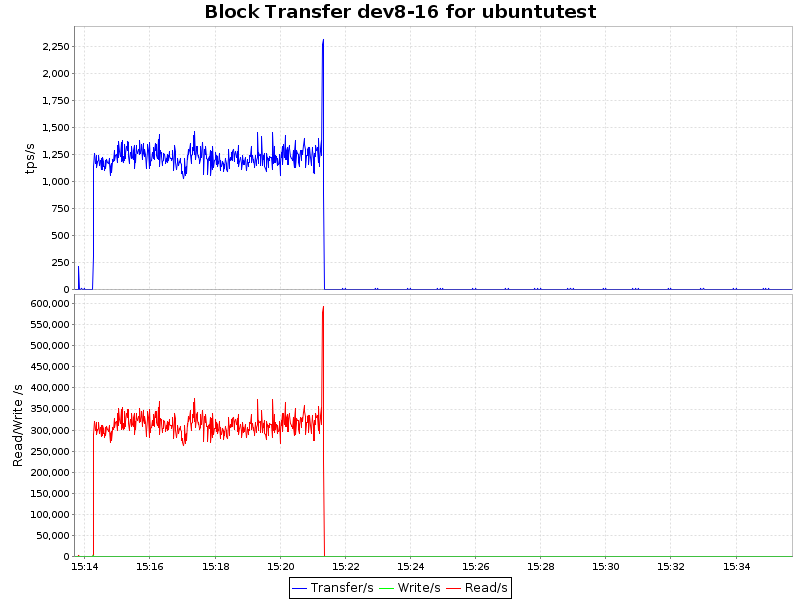 |
| btrfs-zlib | 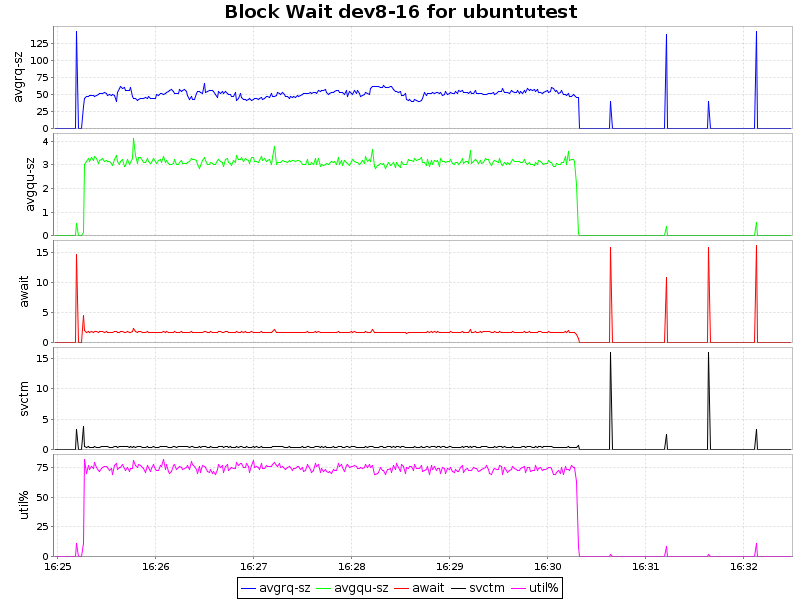 |
| btrfs-lzo | 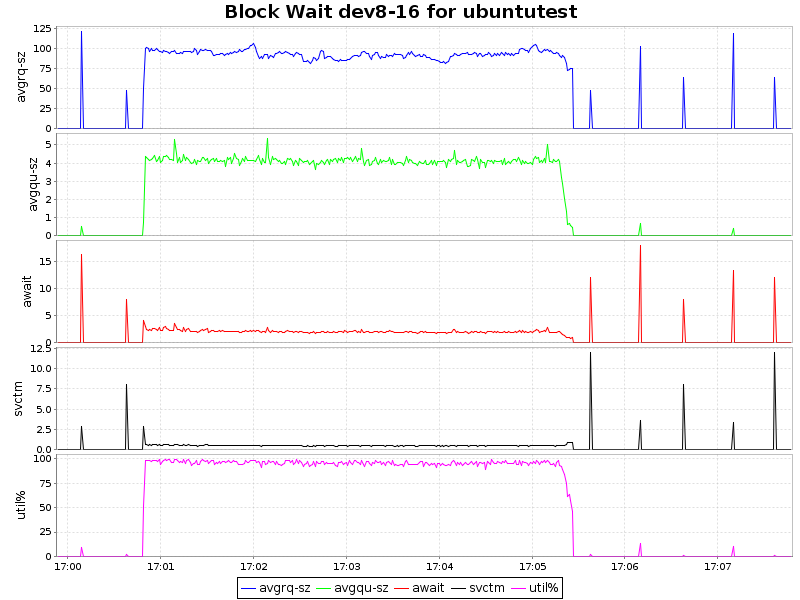 |
| ext4 |  |
Вывод
Как видно из графиков, сжатие с алгоритмом lzo дает лишь незначительную нагрузку на ЦП, что в купе с 2-х кратным уменьшением объемов занимаемого пространства и некоторым ускорением делает такой подход крайней привлекательным. Zlib жмет нашу БД в 4 раза, но при этом нагрузка на процессор возрастает уже ощутимо (~ 7.5% процессорного времени), что для определенных сценариев так же вполне приемлемо. Однако btrfs лишь недавно приобрел статус стабильного (с ядра 3.10) и внедрять в продуктивную среду возможно преждевременно. С другой стороны, наличие синхронной реплики решает и этот вопрос.
P.S.
На сколько мне известно, zlib и, вероятно, lzo используют инструкции из SSE 4.2, что уменьшает загрузку процессоров и вполне возможно, что в некоторых средах виртуализации высокая загрузка процессора не даст воспользоваться преимуществами сжатия.
Если кто подскажет как влиять на это, то я постараюсь перепроверить разницу с аппаратным ускорением и без.
