[Из песочницы] О некоторых проблемах микрооптимизаций
Предыстория
Как-то раз у меня с коллегой завязался разговор по поводу улучшения инструментария для работы с битовыми флагами в перечислениях C++. На тот момент у нас уже была функция IsEnumFlagSet, принимающая на вход первым аргументом тестируемую переменную, вторым — набор флагов для проверки. Чем же она лучше старого доброго побитового И?
if (IsEnumFlagSet(state, flag))
{
}
// vs
if (state & flag)
{
}
На мой взгляд — читаемостью. Я довольно редко работаю с битовыми флагами и битовыми операциями вообще, поэтому при просмотре чужого кода намного легче воспринимать привычные имена функций, нежели загадочные & и |, которые сразу вызывают внутренний window.alert () c заголовком «Внимание! Тут, возможно, происходит какая-то магия».
if (state.Test(particularFlags)) {}
Особенно читаемость ухудшается при операциях установки или снятия флагов. Сравните:
state |= flag; // если вы используете enum class, то нужно перегружать оператор |=
state &= ~flag;
//vs
RaiseEnumFlag(state, flag);
ClearEnumFlag(state, flag);
В процессе обсуждения также была высказана идея о создании функции SetEnumFlag(state, flag, isSet): в зависимости от третьего аргумента, у state бы либо возводились флаги, либо снимались.
Так как предполагалось, что этот аргумент передается в рантайме, то без оверхеда по сравнению с парой RaiseEnumFlag/ClearEnumFlag, очевидно, не обойтись. Но ради академического интереса мне захотелось свести его к минимуму путем спуска в шахту к дьяволу микрооптимизаций.
Реализация
1. Наивная реализация
Для начала введем наше перечисление (не будем использовать enum class для упрощения):
#include
#include
enum Flags : uint32_t
{
One = 1u << 1,
Two = 1u << 2,
Three = 1u << 3,
OneOrThree = One | Three,
Max = 1u << 31,
All = std::numeric_limits::max()
};
И сама реализация:
void SetFlagBranched(Flags& x, Flags y, bool cond)
{
if (cond) {
x = Flags(x | y);
} else {
x = Flags(x & (~y));
}
}2. Микрооптимизация
Наивная реализация имеет очевидное ветвление, которое очень хотелось бы перенести в арифметику, что мы сейчас и попытаемся сделать.
Для начала нам нужно подобрать какое-то выражение, которое позволяет переходить из одного результата в другой на основе параметра. Например,
(x | y) & ~p- При
p = 0возводим флаги:(x | y) & ~0 ≡ (x | y) & 1 ≡ x | y - При
p = yфлаги снимаются:(x | y) & ~y ≡ (x & ~y) | (y & ~y) ≡ (x & ~y) | 0 ≡ x & ~y
Теперь нам нужно как-то «упаковать» в арифметику изменение значения параметра в зависимости от переменной cond (помним — ветвления запрещены).
Пусть изначально p = y, и если cond истина, то пытаемся обнулить p, если нет, то оставляем все как есть.
Напрямую с переменной cond толком не поработать: при преобразовании в арифметический тип в случае true мы получим только одну единицу в младшем разряде, а нам в идеале нужно получить единицы во всех разрядах. По итогу, в голову не пришло ничего лучше решения с использованием побитовых сдвигов.
Определим величину сдвига: мы не можем сразу сдвинуть все наши биты так, чтобы за одну операцию обнулить параметр p, потому что стандарт требует, чтобы величина сдвига была меньше размера типа.
Например, в документации по asm команде shift arithmetic left (SAL) так и написано «The count range is limited to 0 to 31 (or 63 if 64-bit mode and REX.W is used)»
Поэтому вычисляем максимальный размер сдвига, записываем предварительное выражение
constexpr auto shiftSize = sizeof(std::underlying_type_t) * 8 - 1;
(x | y) & ~ ( y >> shiftSize * cond);
И отдельно обрабатываем младший бит результата выражения y >> shiftSize * cond:
(x | y) & ~ (( y >> shiftSize * cond) & ~cond);
Упаковка ветвления произошла в shiftSize * cond — в зависимости от false или true в cond, величина сдвига будет либо 0, либо 31 соответственно, и наш параметр будет либо равен y, либо 0.
Что тут происходит при shiftSize = 31:
- При
cond = trueмы сдвигаем битыyна 31 вправо, вследствие чего самый старший битyстановится самым младшим, а все остальные обнуляются. У~condнаоборот, самый младший бит имеет значение 0, а все остальные — единица. Побитовое перемножение этих значений даст чистый 0. - При
cond = falseникакого сдвига не происходит,~condво всех разрядах имеет 1 и побитовое перемножение этих значений дастy.
Хочется заметить trade-off этого подхода, который не сразу бросается в глаза: без использования ветвлений мы вычисляем x | y (то есть одну из веток наивного варианта) в любом случае, а дальше, за счет «лишних» арифметических операций, преобразуем ее в требуемый результат. И все это имеет смысл, если накладные расходы на дополнительную арифметику будут меньше, чем ветвление.
Итак, финальное решение получилось следующим:
void SetFlagsBranchless(Flags& x, Flags y, bool cond)
{
constexpr uint32_t shiftSize = sizeof(uint32_t) * 8 - 1;
x = Flags((x | y) & ~(( y >> shiftSize * cond) & ~cond));
}3. Сравнение
Реализовав решение без ветвления, я отправился на quick-bench.com, чтобы удостовериться в его преимуществе. Для разработки мы в первую очередь используем clang, поэтому я решил прогонять бенчмарки на нем (clang-9.0). Но тут меня ждал сюрприз…
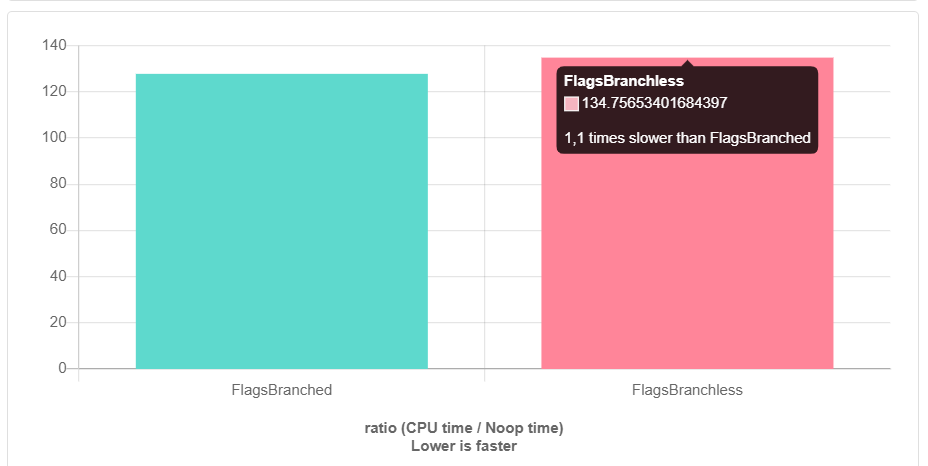
И это с -O3. Без оптимизаций все еще хуже. Как так получилось? Кто виноват и что делать?
Командуем «отставить панику!» и идем разбираться на godbolt.org (quick-bench также предоставляет asm листинг, но godbolt в этом плане выглядит удобнее).
Далее будет идти речь только о уровне оптимизации -O3. Итак, какой же код нам сгенерировал clang для наивной реализации?
SetFlagBranched(Flags&, Flags, bool): # @SetFlagBranched(Flags&, Flags, bool)
mov eax, dword ptr [rdi]
mov ecx, esi
not ecx
and ecx, eax
or eax, esi
test edx, edx
cmove eax, ecx
mov dword ptr [rdi], eax
ret
Неплохо, правда? Clang тоже умеет в trade-off, и понимает, что вычислить обе ветки и использовать команду conditional move, которая не вовлекает в работу branch predictor, будет быстрее использования команд условных переходов (conditional jump).
Код branchless реализации:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool)
mov eax, dword ptr [rdi]
or eax, esi
test edx, edx
mov ecx, 31
cmove ecx, edx
shr esi, cl
not esi
or esi, edx
and esi, eax
mov dword ptr [rdi], esi
ret
Почти «branchless» — я, вроде бы, заказывал тут обычное умножение, а вы мне, батенька, conditional move принесли. Возможно, компилятор прав, и test + cmove в данном случае будет быстрее, чем imul, но я не настолько хорошо разбираюсь в ассемблере (знающие люди, подскажите, пожалуйста, в комментариях).
Интересно другое — по сути, для обоих реализаций после оптимизаций компилятор сгенерировал не совсем то, что мы просили, и в результате получилось нечто среднее: в обоих вариантах используется cmove, просто в branchless реализации у нас много дополнительной арифметики, которая и заваливает бенчмарк.
Clang восьмой версии и старше вообще использует настоящие условные переходы, «благодаря» которым «branchless» версия становится чуть ли не в полтора раза медленнее:
SetFlag(Flags&, Flags, bool): # @SetFlag(Flags&, Flags, bool)
mov eax, dword ptr [rdi]
or eax, esi
mov cl, 31
test edx, edx
jne .LBB0_2
xor ecx, ecx
.LBB0_2:
shr esi, cl
not esi
or esi, edx
and eax, esi
mov dword ptr [rdi], eax
ret
Какой вывод можно сделать? Помимо очевидного «не занимайтесь микрооптимизациями без надобности», разве что можно посоветовать всегда проверять результат работы в машинном коде — может оказаться так, что компилятор уже достаточно соптимизировал изначальный вариант, а ваши «гениальные» оптимизации ему будут непонятны, и назло вам он понатыкает условных переходов вместо умножений.
На этом месте можно было бы и закончить, если бы не одно «но». Код gcc для наивной реализации идентичен clang-овскому, а вот branchless версия…:
SetFlag(Flags&, Flags, bool):
movzx edx, dl
mov eax, esi
or eax, DWORD PTR [rdi]
mov ecx, edx
sal ecx, 5
sub ecx, edx
shr esi, cl
not esi
or esi, edx
and esi, eax
mov DWORD PTR [rdi], esi
ret
Мое почтение разработчикам за столь изящный способ оптимизировать наше выражение, не используя ни imul, ни cmove. Что тут происходит: bool переменная cond побитово сдвигается влево на 5 знаков (потому что тип нашего enum — uint32_t, его размер 32 бита, то есть 1000002), а затем из полученного результата вычитается она же. Таким образом, мы получаем 111112 = 3110 в случае cond = true, и 0 в противном. Надо ли говорить, что такой вариант быстрее наивного, даже с учетом его conditional move оптимизации?

Что ж, итог получился совсем странный — в зависимости от компилятора вариант без ветвлений может оказаться как быстрее, так и медленнее реализации с ветвлениями. Давайте попробуем помочь clang и преобразовать наше выражение по методу gcc (заодно упростим часть ~((y >> shiftSize * cond) & ~cond) по де Моргану — это делает и clang, и gcc):
void SetFlagVerbose(Flags& x, Flags y, bool b)
{
constexpr auto shiftSize = sizeof(std::underlying_type_t) + 1;
x = Flags( (x | y) & ( ~(y >> ((b << shiftSize) - b)) | b) );
}
Такая подсказка имеет влияние только на trunk версию clang, где он действительно генерирует код аналогичный gcc (правда, в оригинальном «branchless» — все тот же test + сmove)
А что там у MSVC? В обоих версиях без ветвлений применяется честный imul (не знаю, насколько он быстрее/медленнее варианта clang/gcc — quick-bench не поддерживает этот компилятор), а в наивной версии появился conditional jump. Sad but true.
Итоги
Главным выводом, наверное, можно назвать то, что намерения программиста в высокоуровневом коде далеко не всегда отражаются в машинном коде — и это делает микрооптимизации бессмысленными без бенчмарков и просмотра листингов. Кроме того, результат микрооптимизаций может оказаться как лучше, так и хуже обычного варианта — все зависит от компилятора, что может представлять серьезную проблему, если проект кроссплатформенный.
