[Из песочницы] Машинное обучение в IT-мониторинге
Введение

Netcracker — это международная компания, разработчик комплексных IT-решений, включающих услуги по размещению и поддержке клиентского оборудования, а также хостингу созданной IT-системы для телеком-операторов.
В основном это решения, связанные с организацией операционной и бизнес-деятельности телеком-операторов. Подробнее можно посмотреть тут.
Постоянная доступность разрабатываемого решения очень важна. Если у оператора связи хотя бы на один час перестанет работать биллинг, это приведет к большим финансовым и репутационным потерям как оператора, так и поставщика программного обеспечения. Поэтому одним из ключевых требований к решению является параметр availability, значение которого варьируется от 99,995% до 99,95% в зависимости от типа решения.
Само решение представляет собой сложный комплекс из центральных монолитных IT-систем, включающих сложное телеком-оборудование и сервисное ПО, размещенное в публичном облаке, а также множество микросервисов, интегрированных с центральным ядром.
Поэтому для команды поддержки очень важен мониторинг всех аппаратно-программных комплексов, интегрированных в единое решение. Чаще всего в компании используется традиционный мониторинг. Этот процесс хорошо отлажен: мы умеем строить подобную систему мониторинга с нуля и знаем, как правильно организовать процессы реагирования на инциденты. Однако в этом подходе есть несколько сложностей, с которыми мы сталкиваемся от проекта к проекту.
- Что мониторить
Какая метрика в данный момент важна, а какая будет важна в будущем? Однозначного ответа здесь нет, поэтому мы стараемся мониторить всё. Сложность номер один — количество метрик. Возникают проблемы с производительностью, операционные дэшборды все чаще напоминают пульт управления космическим кораблем.
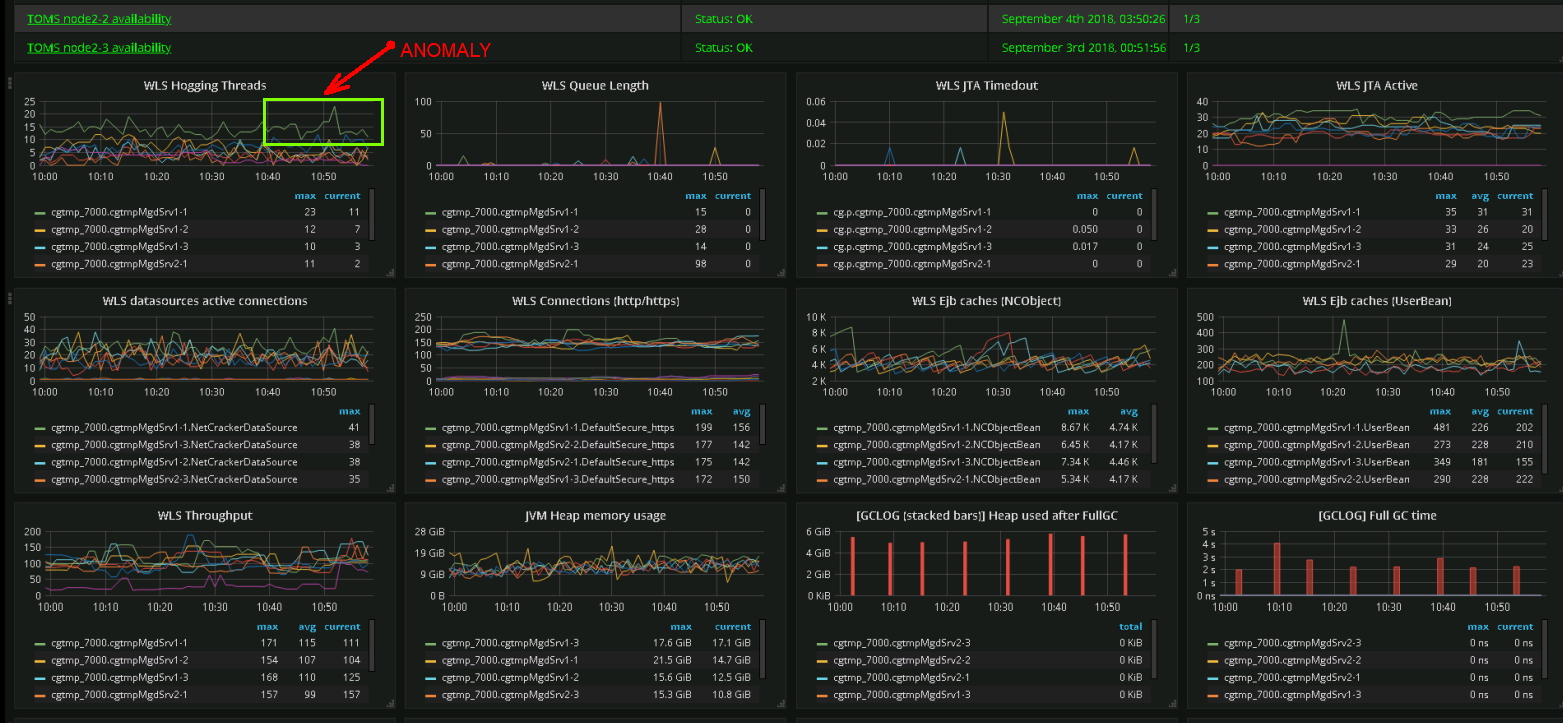
Скриншот реального дэшборда. Инженеры команды поддержки могут определять аномалии в поведении системы по их графическому представлению
- Alerting/thresholding
Несмотря на то что у нас есть опыт эксплуатации множества крупных систем, их мониторинг все еще является сложнейшей задачей в силу специфики используемого оборудования и версий ПО различных поставщиков. Опыт и готовые правила зачастую нельзя полностью перенести из одного решения в другое. Есть некий базовый набор, улучшение которого происходит итеративно, по мере анализа инцидентов, возникающих при эксплуатации решения.
Сложность номер два — отсутствие четких правил настройки. - Интерпретация результата
Когда происходит инцидент, очень важно быстро его локализовать. Это в значительной степени зависит от опыта команды поддержки, так как под валом второстепенных сообщений о сбоях можно не заметить основную причину проблем и потерять время на оперативное реагирование. И это сложность номер три.
При помощи правильно организованных процессов команда способна справляться с вышеперечисленными сложносятми, однако современный запрос на реактивное изменение решения — когда время для перехода от идеи к внедрению измеряется днями — значительно усложняет задачу. Необходимо непрерывное обучение команды. Постоянные изменения приводят к тому, что те или иные правила и причинно-следственные связи утрачивают смысл и, как следствие, инцидент, не будучи вовремя устранённым, может перерасти в аварию.
Как нам помогает машинное обучение
Прогнозирование сбоев работы аппаратно-программных комплексов становится очень востребованной функцией превентивного или реактивного реагирования на инциденты. Корпорация NEC, наша материнская компания, инвестирует значительные средства в развитие идеи мониторинга. Одним из результатов этих инвестиций стала запатентованная технология System Invariant Analysis Technology (SIAT).
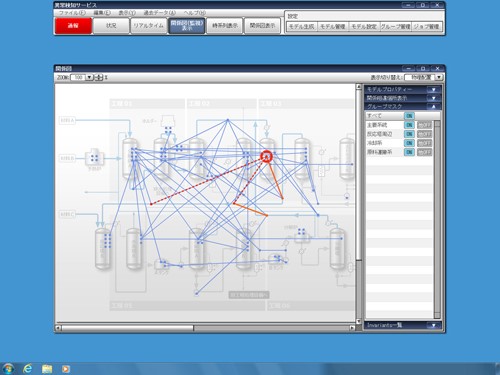
SIAT — технология машинного обучения, которая среди набора данных сенсоров или метрик, представленных как временные числовые ряды, находит с помощью алгоритмов ML неизменные функциональные взаимосвязи и строит общую модель — граф этих взаимосвязей. Подробно можно почитать тут.

Рисунок, иллюстрирующий найденную связь между сенсорами физических объектов
Идея, изначально разработанная для IT-систем, на данный момент получила распространение только для мониторинга физических комплексов, таких как заводы, фабрики, атомные электростанции. Компания Lockheed Martin, к примеру, внедряет эти технологию в своем космическом подразделении. В 2018 году компания Netcracker совместно с NEC переосмыслила данную идею и создала продукт, применимый для мониторинга IT-систем в качестве инструмента дополнительной аналитики. Важно: это только дополнение к системе мониторинга, но не ее замена.
Применения SIAT для IT-систем
Чем отличается физический комплекс от программного? В программных комплексах используются метрики, в физических — сенсоры. Метрик используется намного больше, так как физический сенсор всегда стоит денег и его размещают только там, где это имеет смысл. Программные же метрики, будучи правильно организованными, не стоят ничего. Кроме того, данные метрик информационных систем гораздо сложнее правильно интерполировать к состоянию системы. Человеку проще понимать сенсоры, связанные с физическим миром, тогда как конкретные значения программных метрик имеют смысл только в привязке к конкретному железу, конфигурации и нагрузке.
Также функциональная взаимосвязь в модели предполагает, что если мы заменим железо или версию ПО (например, OS patches) и все операции станут в равной мере быстрее или медленнее, то это не приведет к ложным сообщениям об авариях из-за того, что мы не изменили thresholds. Если же метрики перестали коррелировать между собой, это означает отклонение от нормы в поведении системы. Причем технология SIAT позволяет определять даже небольшие отклонения поведения в реальном времени, в том числе так называемые silent failures — сбои в работе, которые не сопровождаются какими-либо сообщениями о ошибках. И если данное отклонение просто предвестник более масштабного сбоя, у нас есть время, чтобы успеть правильно отреагировать.
Данное утверждение мы проверили, смоделировав небольшой Apache Web Server под нагрузкой, эмулируя внутренние ошибки с помощью механизма Fault Injection в Linux.
Результат представляется в виде числовой метрики Anomaly Score, величина которой связана с данной моделью. Чем больше величина, тем серьезнее сбой: больше метрик ведет себя аномально. Предельное значение — 100% метрик аномальны, система не работает. Кроме этого, в результате указываются те метрики, поведение которых в данный момент можно считать аномальным. Это значительно ускоряет анализ причины и идентификацию подсистемы, которая в данный момент сбоит в рамках текущей модели поведения.
В целом SIAT позволяет реагировать даже на незначительные изменения поведения, которые практически не обнаружимы с помощью традиционного или baseline-мониторинга.
Рисунок, иллюстрирующий нарушение взаимосвязи между сенсорами
Дополнительным плюсом SIAT является алгоритм построения модели поведения, не требующий указания какого-либо бизнес-смысла метрик. Алгоритм автоматически выделяет все метрики, поведение которых взаимосвязано друг с другом, и эта связь постоянна. Оставшиеся изолированные метрики — это или точечные подсистемы, не оказывающие влияния на IT-решение, или метрики, не важные для состояния решения в данный момент. Если есть смысл, мониторинг таких метрик реализуется в рамках традиционного подхода на основе threshold alerting.
Очень важно, что для создания модели требуются данные, связанные с нормальным функционированием системы, что значительно проще, чем при подходе с обучением на авариях.
Модель в дальнейшем уточняется и перестраивается, если поведение изменилось или мы добавили в нее новые метрики.
Так как нормальное поведение системы — переменная характеристика, зависящая от времени суток и других бизнес-условий, для более точного реагирования имеет смысл создавать несколько моделей, описывающих поведение системы в тех или иных условиях.
Как выглядит процесс
Процесс организации мониторинга выглядит следующим образом.
- Запускаем традиционный мониторинг. Очень важным является правильный выбор имени метрик. Дело в том, что результат включает имена метрик, поведение которых аномально, а значит, чем точнее метрика описывает место и смысл, тем быстрее будет получен результат. Например, метрика с именем ncp.erp_netcracker_com.apps.erp.clust4.wls.jdbc.LMSDataSource.ActiveConnectionsCurrentCount указывает, что в Netcracker ERP-системе, на четвертом Weblogic-кластере для LMSDataSource сбоит метрика с именем ActiveConnectionsCurrentCount. Для эксперта такой информации более чем достаточно, чтобы точно локализировать аномалию.
- Далее интегрируемся с системой хранения данных метрик — в нашем случае ClickHouse — и получаем данные всех метрик за некий период нормального поведения решения: лучшие модели строятся на основе 30-дневных результатов мониторинга. Для получения более точных моделей используем данные метрик поминутно без какой-либо агрегации.
- Строим модель с помощью SIAT на основе данных мониторинговой системы. В рамках построенной модели отфильтровываем функциональные взаимосвязи по степени похожести. Если кратко, то это степень отклонения поведения от заданного, выраженная в процентах.
- Проверяем модель на данных предыдущих дней, где сбои были обнаружены с помощью традиционного мониторинга и команды поддержки.
- Запускаем онлайн-мониторинг: каждые 10 минут данные всех метрик передаются в модель или модели. Получаем результат — anomaly score, и в случае, если результат не равен нулю, вдобавок получаем и список метрик, поведение которых в данный момент аномально.
- Полученный результат отправляем в общую систему мониторинга, где он становится частью общих дэшбордов и других инструментов традиционного мониторинга.
Испытания
Ни одно внедрение не происходит без проверок. В качестве испытуемых систем мы выбрали собственную ERP (монолит, Weblogic, Oracle, 4500 метрик) и системы маршрутизации всей нашей системы мониторинга, 7 миллионов метрик в минуту, — carbon-c-relay (1200 метрик).
В качестве входных данных были использованы дампы всех метрик, а также были указаны дни, в которые были зафиксированы сбои. Для оценки результата мы ввели следующие понятия:
- Число ошибок второго рода — когда традиционная система мониторинга или команда поддержки обнаружили сбой, а SIAT — нет.
- Число правильных обнаружений — когда и традиционный мониторинг, и SIAT обнаружили проблему.
- Число ошибок первого рода — когда SIAT обнаружил отклонение поведения, а команда поддержки не обнаружила его.
Мы не обнаружили ни одной ошибки второго рода для обеих тестируемых систем. Число правильных обнаружений — 85% от общего числа сбоев, найденных SIAT, причем в случае с отказом оборудования — вышел из строя RAID массив на базе данных — SIAT обнаружил деградацию поведения с точным указанием на метрики, связанные с базой данных, за семь часов до достижения установленного порогового значения в системе мониторинга.
Оставшиеся 15% указанных SIAT сбоев приходится на ошибки первого рода — аномальное поведение, которое не может объяснить команда поддержки. Это, возможно, связано с тем, что при построении модели были автоматически включены те метрики, которые имеют функциональный смысл, но не имеют заметного влияния на общее поведение системы. После нескольких ложных срабатываний IT-эксперт может отметить эти метрики как неважные и убрать их из модели, предварительно согласовав это с SME.
Результаты показали, что данный продукт полностью автоматизирует процесс обнаружения сбоев (в том числе скрытых), своевременно локализуя инцидент и оценивая его масштаб.
Что дальше
Сейчас мы накапливаем опыт эксплуатации продукта для разного вида аппаратно-программных комплексов с целью анализа применимости данного подхода к различным системам: сетевым устройствам, IoT-устройствам, облачным микросервисам и так далее.
На данный момент задача перестроения модели является самым узким местом. Для этого требуются значительные вычислительные мощности, но, к счастью, пересчет можно проводить на изолированной машине, экспортируя результат в виде готовой модели. Сам же мониторинг в режиме реального время не требует значительных затрат ресурсов и выполняется параллельно с традиционным мониторингом на том же оборудовании.
Заключение
Подводя итог, хочу заметить, что использование комбинации из методик традиционного мониторинга и алгоритмов машинного обучения позволяет построить простую модель, помогающую вовремя реагировать, выяснять место зарождения проблемы, а также поддерживать систему в рабочем состоянии.
Помимо перспективной технологии SIAT, мы анализируем возможности использования другой технологии NEC — Next Generation Log Analytics. Технология позволяет применять алгоритмы машинного обучения и использовать логи системы для определения связанных с внутреннем состоянием продукта аномалий, не влияющих на общую деградацию системы с точки зрения производительности.
А какую аналитику для мониторинга IT-систем используете вы?
