[Из песочницы] Магия newtype в Haskell

Основной способ задать новый тип данных в Haskell — это использование конструкции data. Однако, есть ещё и newtype. Практикующие программисты Haskell пользуются конструкцией newtype постоянно, популярный линтер hlint предлагает заменять data на newtype если это возможно.
Но почему?
Сначала я планировал эту статью для новичков. Действительно, конструкция newtype упоминается в первых главах учебников по Haskell. Вроде бы идея простая: мы ограничиваем представление для типа данных и выигрываем в скорости выполнения. В разных источниках можно найти упоминания, что newtype экономит на вложенности указателей. Но я не нашёл подробного разбора, что на самом деле происходит с этой конструкцией в компиляторе и почему это так круто и нужно. Чтобы заполнить эти пробелы, я и решил написать статью на Хабр.
И так, нам понадобится haskell stack и базовые знания о модели выполнения Haskell и GHC (знаем что такое ленивые вычисления, thunks (невычисленные объекты), слышали немного о стеке и куче GHC).
Семантика
Синтаксис конструкции newtype точно такой же, как и конструкции data, за исключением того, что newtype может иметь только один конструктор и только одно упакованное (boxed type) поле внутри.
-- | Объявляем новый тип данных с целым числом внутри
data MyValDL = MyValDLC Int
-- | Ещё одна версия, в которой мы запретим содержимому быть thunk'ом
-- (форсируем строгое вычисление Int)
data MyValDS = MyValDSC !Int
-- | А теперь мы также определяем новый тип данных с целым числом внутри,
-- но используем ключевое слово newtype
newtype MyValN = MyValNC IntКстати, всякие record syntax и phantom types тоже работают:
newtype MyFunnyA a b c = MyFunnyA { getA :: a }Но в чём же отличие между MyValDL (MyValDS) и MyValN?
В отчёте Haskell'98 говорится, что конструкция newtype вводит новый тип, чьё представление идентично существующему. То есть Int и MyValN изоморфны. Но разве это не так для data-типов? Оказывается, нет. Дело в том, что в Haskell есть «поднятые» (lifted) и «не поднятые» типы. Ко всем типам, объявленным с помощью data, добавляется дополнительный элемент «дно» (bottom, или ⊥) — они становятся поднятыми (для программы, «дно» это undefined). Это значит, что »MyValDLC ⊥ :: MyValDL» и »⊥ :: MyValDL» являются различными значениями. В отличие от data, newtype-тип не поднят (unlifted type), а значит ⊥ :: MyValN «заимствуется» у вложенного типа (через MyValN ⊥).
Можно сказать, что для компилятора поднятый тип означает лишний слой указателей (указатель может ссылаться на вложенный объект, или на дно (undefined)). Для программиста это значит, что если поле data конструктора может содержать undefined, ещё не всё потеряно: пока мы не трогаем это поле, программа не сломается. С другой стороны, невычисленное поле может быть местом утечки памяти (чередой thunkов). Со строгим MyValDS дело обстоит немного сложнее: вроде бы MyValDSC ⊥ немедленно вычисляется до ⊥, но семантика этих двух конструкторов одинакова. Кстати, поэтому профессионалы рекомендуют объявлять все поля в конструкторах data строгими, если только нет реальной необходимости использовать поле лениво — так можно избежать долгих часов поиска утечек памяти.
На Haskell wiki есть отличный набор примеров, иллюстрирующих разницу между data и newtype; я приведу их здесь с поправкой на вольный перевод и мои названия типов:
-- Аргумент не вычисляется (он ведь ленивый),
-- поэтому сопоставление шаблонов успешно
xDL :: Int
xDL = case MyValDLC undefined of
MyValDLC _ -> 1 -- 1
-- Аргумент вычисляется строго, поэтому undefined вызывает ошибку
xDS :: Int
xDS = case MyValDSC undefined of
MyValDSC _ -> 1 -- undefined
-- newtype ведёт себя как Int, поэтому результат будет 1
-- (на первый взгляд, неочевидное поведение, но см. далее yInt)
xN :: Int
xN = case MyValNC undefined of
MyValNC _ -> 1 -- 1
-- Сопоставление конструкторов вызывает ошибку
yDL :: Int
yDL = case undefined of
MyValDLC _ -> 1 -- undefined
-- Сопоставление конструкторов вызывает ошибку
yDS :: Int
yDS = case undefined of
MyValDSC _ -> 1 -- undefined
-- newtype ведёт себя как Int, поэтому конструктора MyValN
-- на самом деле вообще нет во время выполнения!
yN :: Int
yN = case undefined of
MyValNC _ -> 1 -- 1
-- А вот так ведёт себя Int:
-- case выражение вычислилось бы до undefined,
-- но его результат полностью игнорируется,
-- поэтому и самое выражение никогда не вычисляется
yInt :: Int
yInt = case (undefined :: Int) of
_ -> 1 -- 1Приведённое выше описание является моей интерпретацией Haskell wiki. Но на этом мы не остановимся и рассмотрим ещё несколько вопросов.
Как это устроено?
Требование одинакового представления исходного типа и его newtype обёртки для компилятора означает, что:
- В системе типов »
data A» и »newtype NA = N A» — это разные типы. - Во время выполнения представление »
NA» и »A» одинаково.
GHC работает с типами на двух уровнях: «видимая» система типов Haskell, и репрезентативные типы (representation types). Видимая система типов — это то, с чем мы работаем, программируя на Haskell. Однако, в определённый момент компилятор преобразует типы Haskell в машинное представление. Часто получается, что два разных типа в Haskell могут иметь одинаковое представление в машинном коде. В современном GHC, с помощью системы ролей, можно сравнивать типы не только номинально, но и по их представлению. Это позволило реализовать механизм бесплатных приведений типов (видимых только на уровне системы типов Haskell) в модулях Data.Type.Coercion и Data.Coerce.
Принимая во внимание вышесказанное, общая идея реализации newtype очевидна: все упакованные значения в Haskell представляются в виде описания с указателем на конструктор (object info tables); следовательно, значение newtype-типа может в своём описании использовать указатель прямо на конструктор вложенного значения; получается что-вроде type синонимов, только на более низком уровне.
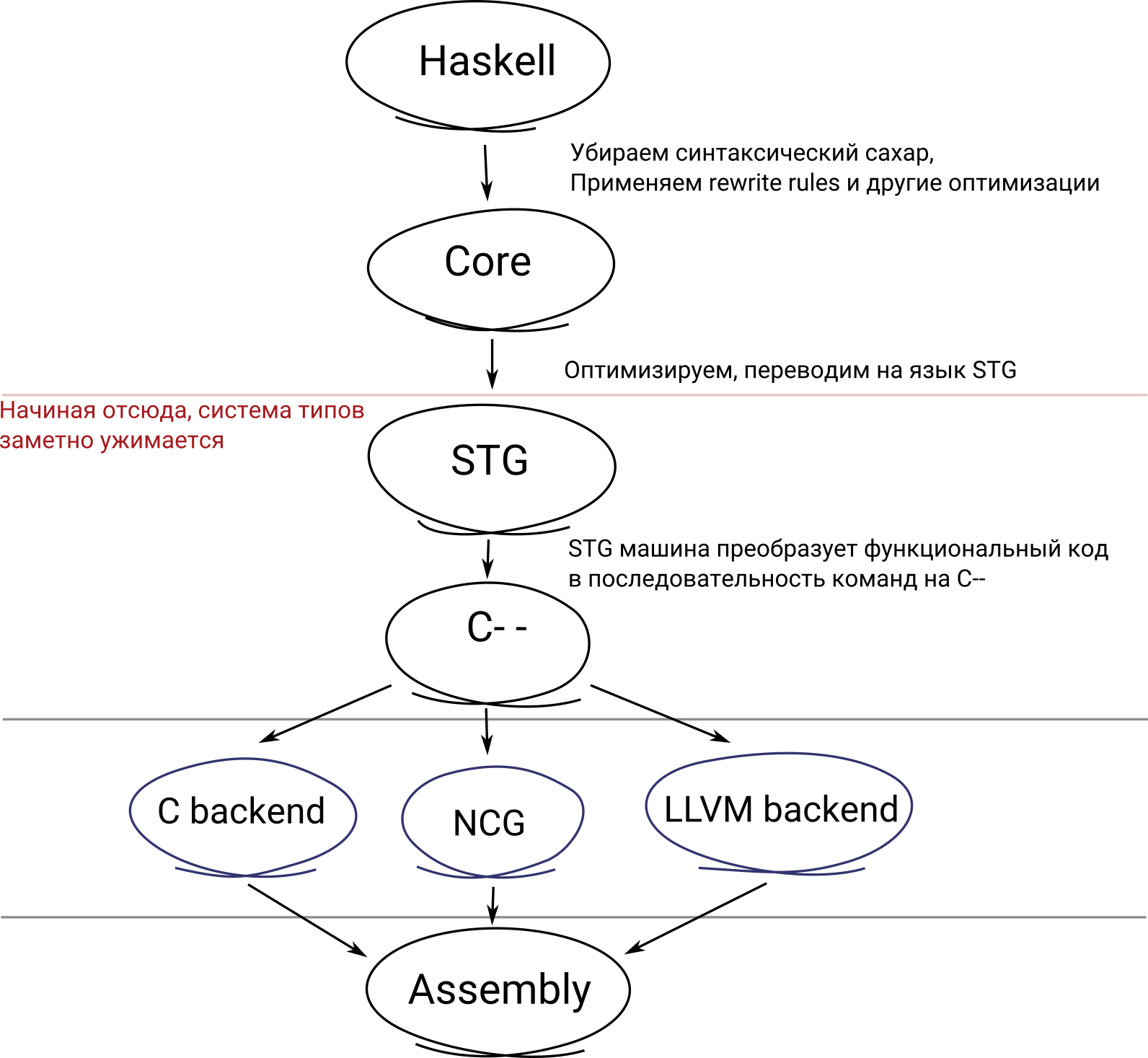
Каждый программист Haskell знает, что GHC не компилирует исходный код сразу в ассемблер, а производит сложную череду преобразований кода в несколько этапов, с оптимизациями почти на каждом из них. Сначала синтаксическое дерево Haskell преобразуется в упрощённую версию языка — GHC Core (который основан на системе F). Затем Core преобразуется в функциональный STG (Spineless Tagless G-machine), потом в императивный С--, а оттуда уже различными путями в ассемблер.
Вроде бы, утверждение, что конструкторы newtype-типов «исчезают» во время выполнения общеизвестно. Однако, разобраться, как это происходит, оказалось достаточно сложно. Описание STG на сайте GHC даёт нам понять, что STG оперирует уже только репрезентативными типами, то есть newtype должен теряться до него. Другая страница GHC wiki намекает, что некоторые типы видны всегда, а некоторые только для type checker«а (последние, кстати, вроде бы имеют префикс tc на разных уровнях генерируемого кода). Чтобы узнать наверняка, что происходит с newtype типами, я решил посмотреть все промежуточные стадии компилируемого кода на следующем примере:
newtype MyNewtypeStruct = MyNewtypeConstr { unNewtypeStruct :: Int }
data MyDataStruct = MyDataConstr { unDataStruct :: Int }
ntToD :: MyNewtypeStruct -> MyDataStruct
ntToD x = case x of
MyNewtypeConstr y -> MyDataConstr y
dToNt :: MyDataStruct -> MyNewtypeStruct
dToNt x = case x of
MyDataConstr y -> MyNewtypeConstr yРезультат не заставил себя ждать на первом же этапе:
stack exec ghc-core -- --no-asm Main.hs -fforce-recomp -O0 -fno-enable-rewrite-rulesПрограмма ghc-core, доступная в одноименном пакете на hackage, выводит немного подчищенный GHC Core. Уже на этом этапе все вхождения MyNewtypeConstr заменяются на операции cast, в то время как MyDataConstr честно остаётся на своём месте:
unNewtypeStruct1_rG2 :: MyNewtypeStruct -> MyNewtypeStruct
unNewtypeStruct1_rG2 = \ (ds_dGl :: MyNewtypeStruct) -> ds_dGl
unNewtypeStruct :: MyNewtypeStruct -> Int
unNewtypeStruct =
unNewtypeStruct1_rG2
`cast` (_R -> N:MyNewtypeStruct[0]
:: ((MyNewtypeStruct -> MyNewtypeStruct) :: *)
~R#
((MyNewtypeStruct -> Int) :: *))
unDataStruct :: MyDataStruct -> Int
unDataStruct =
\ (ds_dGj :: MyDataStruct) ->
case ds_dGj of _ [Occ=Dead] { MyDataConstr ds1_dGk -> ds1_dGk }
ntToD :: MyNewtypeStruct -> MyDataStruct
ntToD =
MyDataConstr
`cast` (Sym N:MyNewtypeStruct[0] -> _R
:: ((Int -> MyDataStruct) :: *)
~R#
((MyNewtypeStruct -> MyDataStruct) :: *))
dToNt :: MyDataStruct -> MyNewtypeStruct
dToNt =
\ (x_awb :: MyDataStruct) ->
case x_awb of _ [Occ=Dead] { MyDataConstr y_awc ->
y_awc
`cast` (Sym N:MyNewtypeStruct[0]
:: (Int :: *) ~R# (MyNewtypeStruct :: *)) Следующий этап — STG, его можно посмотреть следующей командой:
stack exec ghc -- Main.hs -fforce-recomp -O0 -fno-enable-rewrite-rules -ddump-stg > Main.stgОн не сильно отличается от Core, за исключением интересной детали: Main.MyDataConstr определяется явно в генерируемом коде, а Main.MyNewtypeConstr.
Main.MyDataConstr :: GHC.Types.Int -> Main.MyDataStruct
[GblId[DataCon],
Arity=1,
Caf=NoCafRefs,
Str=DmdType m,
Unf=OtherCon []] =
\r srt:SRT:[] [eta_B1] Main.MyDataConstr [eta_B1]; На уровне С-- и далее можно найти такие конструкции, как Main.$tc'MyNewtypeConstr и Main.$tc'MyDataConstr, однако Main.MyDataConstr не находит себе пары newtype. Видимо, $tc (от слова Type Checker) — это ещё один намёк на типы, которые используются только на уровне проверки типов.
Как мы видим, уже этапе преобразований GHC Core, newtype конструкторы заменяются на примитивные преобразования типов. На уровне C-- можно сравнить низкоуровневый императивный код Main.unNewtypeStruct_entry() и Main.unDataStruct_entry(), чтобы убедиться, что unNewtypeStruct не делает фактически ничего, в отличие от unDataStruct.
Все уровни вывода можно посмотреть с помощью нескольких команд:
stack exec ghc -- ${filename}.hs -fforce-recomp -O0 -fno-enable-rewrite-rules -fllvm -keep-llvm-files
stack exec ghc-core -- --no-asm --no-syntax ${filename}.hs -fforce-recomp -O0 -fno-enable-rewrite-rules > ${filename}.hcr
stack exec ghc -- ${filename}.hs -fforce-recomp -O0 -fno-enable-rewrite-rules -ddump-stg > ${filename}.stg
stack exec ghc -- ${filename}.hs -fforce-recomp -O0 -fno-enable-rewrite-rules -ddump-opt-cmm > ${filename}.cmmОтформатированный мной вывод есть под катом. Я оставил только более-ли-менее интересные части (текста и так слишком много).
-- CORE ------------------------------------------------------------------------
unNewtypeStruct1_rG2 :: MyNewtypeStruct -> MyNewtypeStruct
unNewtypeStruct1_rG2 = \ (ds_dGl :: MyNewtypeStruct) -> ds_dGl
unNewtypeStruct :: MyNewtypeStruct -> Int
unNewtypeStruct =
unNewtypeStruct1_rG2
`cast` (_R -> N:MyNewtypeStruct[0]
:: ((MyNewtypeStruct -> MyNewtypeStruct) :: *)
~R#
((MyNewtypeStruct -> Int) :: *))
unDataStruct :: MyDataStruct -> Int
unDataStruct =
\ (ds_dGj :: MyDataStruct) ->
case ds_dGj of _ [Occ=Dead] { MyDataConstr ds1_dGk -> ds1_dGk }
ntToD :: MyNewtypeStruct -> MyDataStruct
ntToD =
MyDataConstr
`cast` (Sym N:MyNewtypeStruct[0] -> _R
:: ((Int -> MyDataStruct) :: *)
~R#
((MyNewtypeStruct -> MyDataStruct) :: *))
dToNt :: MyDataStruct -> MyNewtypeStruct
dToNt =
\ (x_awb :: MyDataStruct) ->
case x_awb of _ [Occ=Dead] { MyDataConstr y_awc ->
y_awc
`cast` (Sym N:MyNewtypeStruct[0]
:: (Int :: *) ~R# (MyNewtypeStruct :: *))
-- ...
$tc'MyNewtypeConstr1_rGD :: TrName
$tc'MyNewtypeConstr1_rGD = TrNameS "'MyNewtypeConstr"#
$tc'MyDataConstr1_rGF :: TrName
$tc'MyDataConstr1_rGF = TrNameS "'MyDataConstr"#
-- ..
$tcMyNewtypeStruct1_rGE :: TrName
$tcMyNewtypeStruct1_rGE = TrNameS "MyNewtypeStruct"#
$tcMyDataStruct1_rGG :: TrName
$tcMyDataStruct1_rGG = TrNameS "MyDataStruct"#
-- ...
-- STG -------------------------------------------------------------------------
unNewtypeStruct1_rG2 :: Main.MyNewtypeStruct -> Main.MyNewtypeStruct
[GblId, Arity=1, Caf=NoCafRefs, Str=DmdType, Unf=OtherCon []] =
sat-only \r srt:SRT:[] [ds_sQ7] ds_sQ7;
Main.unNewtypeStruct :: Main.MyNewtypeStruct -> GHC.Types.Int
[GblId[[RecSel]],
Arity=1,
Caf=NoCafRefs,
Str=DmdType,
Unf=OtherCon []] =
\r srt:SRT:[] [eta_B1] unNewtypeStruct1_rG2 eta_B1;
Main.unDataStruct :: Main.MyDataStruct -> GHC.Types.Int
[GblId[[RecSel]],
Arity=1,
Caf=NoCafRefs,
Str=DmdType,
Unf=OtherCon []] =
\r srt:SRT:[] [ds_sQ8]
case ds_sQ8 of _ [Occ=Dead] {
Main.MyDataConstr ds1_sQa [Occ=Once] -> ds1_sQa;
};
Main.ntToD :: Main.MyNewtypeStruct -> Main.MyDataStruct
[GblId, Arity=1, Caf=NoCafRefs, Str=DmdType, Unf=OtherCon []] =
\r srt:SRT:[] [eta_B1] Main.MyDataConstr [eta_B1];
Main.dToNt :: Main.MyDataStruct -> Main.MyNewtypeStruct
[GblId, Arity=1, Caf=NoCafRefs, Str=DmdType, Unf=OtherCon []] =
\r srt:SRT:[] [x_sQb]
case x_sQb of _ [Occ=Dead] {
Main.MyDataConstr y_sQd [Occ=Once] -> y_sQd;
};
-- ... constructors seem to be defined exactly the same way for both types ...
-- There is one more definition in the STG dump
Main.MyDataConstr :: GHC.Types.Int -> Main.MyDataStruct
[GblId[DataCon],
Arity=1,
Caf=NoCafRefs,
Str=DmdType m,
Unf=OtherCon []] =
\r srt:SRT:[] [eta_B1] Main.MyDataConstr [eta_B1];
-- C-- -------------------------------------------------------------------------
unNewtypeStruct1_rG2_entry() // [R2]
{ [(cQj,
unNewtypeStruct1_rG2_info:
const 4294967301;
const 0;
const 15;)]
}
{offset
cQj:
_sQ8::P64 = R2;
goto cQl;
cQl:
R1 = _sQ8::P64 & (-8);
call (I64[R1])(R1) args: 8, res: 0, upd: 8;
}
}
Main.unNewtypeStruct_entry() // [R2]
{ [(cQv,
Main.unNewtypeStruct_info:
const 4294967301;
const 0;
const 15;)]
}
{offset
cQv:
_B1::P64 = R2;
goto cQx;
cQx:
R2 = _B1::P64;
call unNewtypeStruct1_rG2_info(R2) args: 8, res: 0, upd: 8;
}
}
Main.unDataStruct_entry() // [R2]
{ [(cQJ,
block_cQJ_info:
const 0;
const 32;),
(cQM,
Main.unDataStruct_info:
const 4294967301;
const 0;
const 15;)]
}
{offset
cQM:
_sQ9::P64 = R2;
if ((Sp + -8) < SpLim) goto cQN; else goto cQO;
cQN:
R2 = _sQ9::P64;
R1 = Main.unDataStruct_closure;
call (I64[BaseReg - 8])(R2, R1) args: 8, res: 0, upd: 8;
cQO:
I64[Sp - 8] = block_cQJ_info;
R1 = _sQ9::P64;
Sp = Sp - 8;
if (R1 & 7 != 0) goto cQJ; else goto cQK;
cQK:
call (I64[R1])(R1) returns to cQJ, args: 8, res: 8, upd: 8;
cQJ:
_sQa::P64 = R1;
_sQb::P64 = P64[_sQa::P64 + 7];
R1 = _sQb::P64 & (-8);
Sp = Sp + 8;
call (I64[R1])(R1) args: 8, res: 0, upd: 8;
}
}
section ""data" . $tc'MyNewtypeConstr1_rGD_closure" {
$tc'MyNewtypeConstr1_rGD_closure:
const GHC.Types.TrNameS_static_info;
const cRI_str;
}
section ""data" . Main.$tc'MyNewtypeConstr_closure" {
Main.$tc'MyNewtypeConstr_closure:
const GHC.Types.TyCon_static_info;
const Main.$trModule_closure+1;
const $tc'MyNewtypeConstr1_rGD_closure+1;
const 10344856529254187725;
const 4384341159368653246;
const 3;
}
section ""data" . $tc'MyDataConstr1_rGF_closure" {
$tc'MyDataConstr1_rGF_closure:
const GHC.Types.TrNameS_static_info;
const cRU_str;
}
section ""data" . Main.$tc'MyDataConstr_closure" {
Main.$tc'MyDataConstr_closure:
const GHC.Types.TyCon_static_info;
const Main.$trModule_closure+1;
const $tc'MyDataConstr1_rGF_closure+1;
const 12971553621823397951;
const 6686958652479025466;
const 3;
}
section ""data" . Main.MyDataConstr_closure" {
Main.MyDataConstr_closure:
const Main.MyDataConstr_info;
}
Main.MyDataConstr_entry() // [R2]
{ [(cSE,
Main.MyDataConstr_info:
const 4294967301;
const 0;
const 15;)]
}
{offset
cSE:
_B1::P64 = R2;
goto cSG;
cSG:
Hp = Hp + 16;
if (Hp > I64[BaseReg + 856]) goto cSI; else goto cSH;
cSI:
I64[BaseReg + 904] = 16;
goto cSF;
cSF:
R2 = _B1::P64;
R1 = Main.MyDataConstr_closure;
call (I64[BaseReg - 8])(R2, R1) args: 8, res: 0, upd: 8;
cSH:
I64[Hp - 8] = Main.MyDataConstr_con_info;
P64[Hp] = _B1::P64;
_cSD::P64 = Hp - 7;
R1 = _cSD::P64;
call (P64[Sp])(R1) args: 8, res: 0, upd: 8;
}
}
Main.MyDataConstr_con_entry() // []
{ [(cSN,
Main.MyDataConstr_con_info:
const iSP_str-Main.MyDataConstr_con_info;
const 1;
const 2;)]
}
{offset
cSN:
R1 = R1 + 1;
call (P64[Sp])(R1) args: 8, res: 0, upd: 8;
}
}
Main.MyDataConstr_static_entry() // []
{ [(cSO,
Main.MyDataConstr_static_info:
const iSQ_str-Main.MyDataConstr_static_info;
const 1;
const 7;)]
}
{offset
cSO:
R1 = R1 + 1;
call (P64[Sp])(R1) args: 8, res: 0, upd: 8;
}
}
-- LLVM ------------------------------------------------------------------------
%Main_zdtczqMyNewtypeConstr_closure_struct = type <{i64, i64, i64, i64, i64, i64}>
@Main_zdtczqMyNewtypeConstr_closure$def = internal global %Main_zdtczqMyNewtypeConstr_closure_struct<{i64 ptrtoint (i8* @ghczmprim_GHCziTypes_TyCon_static_info to i64), i64 add (i64 ptrtoint (%Main_zdtrModule_closure_struct* @Main_zdtrModule_closure$def to i64),i64 1), i64 add (i64 ptrtoint (%rGD_closure_struct* @rGD_closure$def to i64),i64 1), i64 -8101887544455363891, i64 4384341159368653246, i64 3}>
@Main_zdtczqMyNewtypeConstr_closure = alias i8* bitcast (%Main_zdtczqMyNewtypeConstr_closure_struct* @Main_zdtczqMyNewtypeConstr_closure$def to i8*)
%Main_zdtcMyNewtypeStruct_closure_struct = type <{i64, i64, i64, i64, i64, i64}>
@Main_zdtcMyNewtypeStruct_closure$def = internal global %Main_zdtcMyNewtypeStruct_closure_struct<{i64 ptrtoint (i8* @ghczmprim_GHCziTypes_TyCon_static_info to i64), i64 add (i64 ptrtoint (%Main_zdtrModule_closure_struct* @Main_zdtrModule_closure$def to i64),i64 1), i64 add (i64 ptrtoint (%rGE_closure_struct* @rGE_closure$def to i64),i64 1), i64 2735651172251469986, i64 2399541496478989519, i64 3}>
@Main_zdtcMyNewtypeStruct_closure = alias i8* bitcast (%Main_zdtcMyNewtypeStruct_closure_struct* @Main_zdtcMyNewtypeStruct_closure$def to i8*)
%Main_zdtczqMyDataConstr_closure_struct = type <{i64, i64, i64, i64, i64, i64}>
@Main_zdtczqMyDataConstr_closure$def = internal global %Main_zdtczqMyDataConstr_closure_struct<{i64 ptrtoint (i8* @ghczmprim_GHCziTypes_TyCon_static_info to i64), i64 add (i64 ptrtoint (%Main_zdtrModule_closure_struct* @Main_zdtrModule_closure$def to i64),i64 1), i64 add (i64 ptrtoint (%rGF_closure_struct* @rGF_closure$def to i64),i64 1), i64 -5475190451886153665, i64 6686958652479025466, i64 3}>
@Main_zdtczqMyDataConstr_closure = alias i8* bitcast (%Main_zdtczqMyDataConstr_closure_struct* @Main_zdtczqMyDataConstr_closure$def to i8*)
%Main_zdtcMyDataStruct_closure_struct = type <{i64, i64, i64, i64, i64, i64}>
@Main_zdtcMyDataStruct_closure$def = internal global %Main_zdtcMyDataStruct_closure_struct<{i64 ptrtoint (i8* @ghczmprim_GHCziTypes_TyCon_static_info to i64), i64 add (i64 ptrtoint (%Main_zdtrModule_closure_struct* @Main_zdtrModule_closure$def to i64),i64 1), i64 add (i64 ptrtoint (%rGG_closure_struct* @rGG_closure$def to i64),i64 1), i64 5826051442705447975, i64 -4331072423017222539, i64 3}>
@Main_zdtcMyDataStruct_closure = alias i8* bitcast (%Main_zdtcMyDataStruct_closure_struct* @Main_zdtcMyDataStruct_closure$def to i8*)
%Main_MyDataConstr_closure_struct = type <{i64}>
@Main_MyDataConstr_closure$def = internal global %Main_MyDataConstr_closure_struct<{i64 ptrtoint (void (i64*, i64*, i64*, i64, i64, i64, i64, i64, i64, i64)* @Main_MyDataConstr_info$def to i64)}>
@Main_MyDataConstr_closure = alias i8* bitcast (%Main_MyDataConstr_closure_struct* @Main_MyDataConstr_closure$def to i8*)
@Main_MyDataConstr_info = internal alias i8* bitcast (void (i64*, i64*, i64*, i64, i64, i64, i64, i64, i64, i64)* @Main_MyDataConstr_info$def to i8*)
define internal ghccc void @Main_MyDataConstr_info$def(i64* noalias nocapture %Base_Arg, i64* noalias nocapture %Sp_Arg, i64* noalias nocapture %Hp_Arg, i64 %R1_Arg, i64 %R2_Arg, i64 %R3_Arg, i64 %R4_Arg, i64 %R5_Arg, i64 %R6_Arg, i64 %SpLim_Arg) align 8 nounwind prefix <{i64, i64, i64}><{i64 4294967301, i64 0, i64 15}>
{
cW0:
...
ret void
}
@Main_MyDataConstr_con_info = alias i8* bitcast (void (i64*, i64*, i64*, i64, i64, i64, i64, i64, i64, i64)* @Main_MyDataConstr_con_info$def to i8*)
define ghccc void @Main_MyDataConstr_con_info$def(i64* noalias nocapture %Base_Arg, i64* noalias nocapture %Sp_Arg, i64* noalias nocapture %Hp_Arg, i64 %R1_Arg, i64 %R2_Arg, i64 %R3_Arg, i64 %R4_Arg, i64 %R5_Arg, i64 %R6_Arg, i64 %SpLim_Arg) align 8 nounwind prefix <{i64, i64, i64}><{i64 add (i64 sub (i64 ptrtoint (%iWK_str_struct* @iWK_str$def to i64),i64 ptrtoint (void (i64*, i64*, i64*, i64, i64, i64, i64, i64, i64, i64)* @Main_MyDataConstr_con_info$def to i64)),i64 0), i64 1, i64 2}>
{ ...
}
@Main_MyDataConstr_static_info = alias i8* bitcast (void (i64*, i64*, i64*, i64, i64, i64, i64, i64, i64, i64)* @Main_MyDataConstr_static_info$def to i8*)
define ghccc void @Main_MyDataConstr_static_info$def(i64* noalias nocapture %Base_Arg, i64* noalias nocapture %Sp_Arg, i64* noalias nocapture %Hp_Arg, i64 %R1_Arg, i64 %R2_Arg, i64 %R3_Arg, i64 %R4_Arg, i64 %R5_Arg, i64 %R6_Arg, i64 %SpLim_Arg) align 8 nounwind prefix <{i64, i64, i64}><{i64 add (i64 sub (i64 ptrtoint (%iWL_str_struct* @iWL_str$def to i64),i64 ptrtoint (void (i64*, i64*, i64*, i64, i64, i64, i64, i64, i64, i64)* @Main_MyDataConstr_static_info$def to i64)),i64 0), i64 1, i64 7}>
{ ...
} PS: Разумеется, сам тип newtype N не может никуда исчезнуть во время компиляции: скомпилированный модуль должен экспортировать символы для использования в других модулях. Кроме того, нужно где-то хранить указатели на функции классов реализованных этим типом. Реальная польза newtype в том, что на низком уровне не нужно проходить цепочку конструкторов чтобы добраться до искомого значения.
А зачем это надо?
В предыдущем параграфе мы неявно определили почему лучше использовать newtype вместо data где это возможно (newtype быстрее и компактнее). Теперь нерешённый вопрос:, а зачем вообще использовать newtype — тип с одним конструктором и полем — когда можно просто использовать исходный тип или type синоним к нему? Для этого есть много причин.
Проще понимать вывод типов
Синонимы типов разыменовываются во время вывода типов, а newtype это всегда отдельный тип. Рассмотрим следующий пример:
newtype Height = Height Double
newtype Weight = Weight Double
newtype Percent = Percent Double
newtype Age = Age Int
diseaseRate :: Height -> Weight -> Age -> Percent
diseaseRate (Height h) (Weight w) = _
diseaseRate' :: Double -> Double -> Int -> Double
diseaseRate' h w = _И вывод компилятора:
Example.hs:19:36: error:
• Found hole: _ :: Age -> Percent
• ...
Example.hs:23:20: error:
• Found hole: _ :: Int -> Double
• ...
Намного проще понять, какой вид должна иметь функция Age -> Percent, чем Int -> Double. Знаменитая библиотека lens — могущественный инструмент, но разбор типов её комбинаторов часто снится мне в кошмарах.
Помощь в документации
Весьма простая причина, но она почему-то редко упоминается в учебниках и туториалах. В предыдущем примере очень просто перепутать рост и вес в качестве аргументов функции diseaseRate', но компилятор не позволит этого сделать в функции diseaseRate. Разумеется, это не отменяет документацию, но является очень хорошим дополнением к ней.
Если не хочется плодить большое количество новых типов под каждую функцию, есть удобный приём — использовать теггирование:
newtype Tagged tag a = Tagged { unTagged :: a }Можно теггировать перечисляемыми типами, или просто использовать GHC.TypeLits.
Первый раз этот приём я увидел на лекции Саймона Меера.
Скрытие деталей реализации
Используем ли мы Float или Double в качестве типа данных для вывода процентов? Иногда, пользователю библиотеки этого не следует знать (тип может различаться для разных платформ, или мы хотим поменять его в новой версии библиотеки).
Реализация нового поведения для существующего типа
Самая популярная причина. Создавая новый тип, мы можем по-новому реализовать некоторые классы. Например, я хочу выводить проценты в строке со знаком »%» после числа:
instance Show Percent where
show (Percent t) = show t ++ "%"Но, вообще-то, я бы хотел складывать и умножать проценты; желательно, без необходимости переопределять все методы Num и им подобные. В GHC для этого есть расширение GeneralizedNewtypeDeriving, которое позволяет естественным образом выводить реализации широкого круга классов для newtype-типов:
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
module Example where
newtype Percent = Percent Double
deriving (Eq, Ord, Num, Fractional, Floating, Real, RealFrac, RealFloat)
instance Show Percent where
show (Percent t) = show t ++ "%"
x :: Percent
x = 2 + Percent 4Примеры
Примеров использования newtype по различным причинам очень много. Может быть, он используется даже чаще чем data. Самый первый и главный пример — это, конечно, IO. Просто введите в консоли ghci команду :info IO:
ghci> :info IO
newtype IO a
= GHC.Types.IO (GHC.Prim.State# GHC.Prim.RealWorld
-> (# GHC.Prim.State# GHC.Prim.RealWorld, a #))
-- Defined in ‘GHC.Types’Да, весь IO это всего лишь newtype обёртка вокруг примитивной функции вычисление+состояние. Точно так же, как и монада STnewtype ST s a = ST (STRep s a).
Все монады и монадные трансформеры из пакета transformers реализованы по похожему принципуnewtype RWST r w s m a = RWST { runRWST :: r -> s -> m (a, s, w) }.
Два очень интересных и полезных модуля: Data.Semigroup и Data.Monoid содержат набор newtype-обёрток над типами данных для реализации поведения полугрупп и моноидов. Например, максимум (newtype Max a = Max { getMax :: a }) для типа Ord является полугруппой, а над Ord и Bounded становится моноидом. Но это тема для отдельной статьи!
