[Из песочницы] Как работает метод главных компонент (PCA) на простом примере

В этой статье я бы хотел рассказать о том, как именно работает метод анализа главных компонент (PCA — principal component analysis) с точки зрения интуиции, стоящей за ее математическим аппаратом. Максимально просто, но подробно.
Математика вообще очень красивая и изящная наука, но порой ее красота скрывается за кучей слоев абстракции. Показать эту красоту лучше всего на простых примерах, которые, так сказать, можно покрутить, поиграть и пощупать, потому что в конце концов все оказывается гораздо проще, чем кажется на первый взгляд — самое главное понять и представить.
В анализе данных, как и в любом другом анализе, порой бывает нелишним создать упрощенную модель, максимально точно описывающую реальное положение дел. Часто бывает так, что признаки довольно сильно зависят друг от друга и их одновременное наличие избыточно.
К примеру, расход топлива у нас меряется в литрах на 100 км, а в США в милях на галлон. На первый взгляд, величины разные, но на самом деле они строго зависят друг от друга. В миле 1600 м, а в галлоне 3.8л. Один признак строго зависит от другого, зная один, знаем и другой.
Но гораздо чаще бывает так, что признаки зависят друг от друга не так строго и (что важно!) не так явно. Объем двигателя в целом положительно влияет на разгон до 100 км/ч, но это верно не всегда. А еще может оказаться, что с учетом не видимых на первый взгляд факторов (типа улучшения качества топлива, использования более легких материалов и прочих современных достижений), год автомобиля не сильно, но тоже влияет на его разгон.
Зная зависимости и их силу, мы можем выразить несколько признаков через один, слить воедино, так сказать, и работать уже с более простой моделью. Конечно, избежать потерь информации, скорее всего не удастся, но минимизировать ее нам поможет как раз метод PCA.
Выражаясь более строго, данный метод аппроксимирует n-размерное облако наблюдений до эллипсоида (тоже n-мерного), полуоси которого и будут являться будущими главными компонентами. И при проекции на такие оси (снижении размерности) сохраняется наибольшее количество информации.
Шаг 1. Подготовка данных
Здесь для простоты примера я не буду брать реальные обучающие датасеты на десятки признаков и сотни наблюдений, а сделаю свой, максимально простой игрушечный пример. 2 признака и 10 наблюдений будет вполне достаточно для описания того, что, а главное — зачем, происходит в недрах алгоритма.
Сгенерируем выборку:
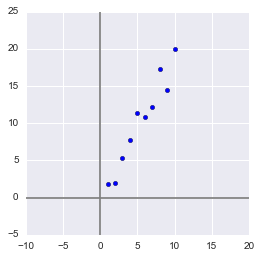
x = np.arange(1,11)
y = 2 * x + np.random.randn(10)*2
X = np.vstack((x,y))
print X
OUT:
[[ 1. 2. 3. 4. 5.
6. 7. 8. 9. 10. ]
[ 2.73446908 4.35122722 7.21132988 11.24872601 9.58103444
12.09865079 13.78706794 13.85301221 15.29003911 18.0998018 ]]
В данной выборке у нас имеются два признака, сильно коррелирующие друг с другом. С помощью алгоритма PCA мы сможем легко найти признак-комбинацию и, ценой части информации, выразить оба этих признака одним новым. Итак, давайте разбираться!
Для начала немного статистики. Вспомним, что для описания случайной величины используются моменты. Нужные нам — мат. ожидание и дисперсия. Можно сказать, что мат. ожидание — это «центр тяжести» величины, а дисперсия — это ее «размеры». Грубо говоря, мат. ожидание задает положение случайной величины, а дисперсия — ее размер (точнее, разброс).
Сам процесс проецирования на вектор никак не влияет на значения средних, так как для минимизации потерь информации наш вектор должен проходить через центр нашей выборки. Поэтому нет ничего страшного, если мы отцентрируем нашу выборку — линейно сдвинем ее так, чтобы средние значения признаков были равны 0. Это очень сильно упростит наши дальнейшие вычисления (хотя, стоит отметить, что можно обойтись и без центрирования).
Оператор, обратный сдвигу будет равен вектору изначальных средних значений — он понадобится для восстановления выборки в исходной размерности.

Xcentered = (X[0] - x.mean(), X[1] - y.mean())
m = (x.mean(), y.mean())
print Xcentered
print "Mean vector: ", m
OUT:
(array([-4.5, -3.5, -2.5, -1.5, -0.5, 0.5, 1.5, 2.5, 3.5, 4.5]),
array([-8.44644233, -8.32845585, -4.93314426, -2.56723136, 1.01013247,
0.58413394, 1.86599939, 7.00558491, 4.21440647, 9.59501658]))
Mean vector: (5.5, 10.314393916)
Дисперсия же сильно зависит от порядков значений случайной величины, т.е. чувствительна к масштабированию. Поэтому если единицы измерения признаков сильно различаются своими порядками, крайне рекомендуется стандартизировать их. В нашем случае значения не сильно разнятся в порядках, так что для простоты примера мы не будем выполнять эту операцию.
Шаг 2. Ковариационная матрица
В случае с многомерной случайной величиной (случайным вектором) положение центра все так же будет являться мат. ожиданиями ее проекций на оси. А вот для описания ее формы уже недостаточно толькое ее дисперсий по осям. Посмотрите на эти графики, у всех трех случайных величин одинаковые мат.ожидания и дисперсии, а их проекции на оси в целом окажутся одинаковы!

Для описания формы случайного вектора необходима ковариационная матрица.
Это матрица, у которой (i, j)-элемент является корреляцией признаков (Xi, Xj). Вспомним формулу ковариации:

В нашем случае она упрощается, так как E (Xi) = E (Xj) = 0:

Заметим, что когда Xi = Xj:
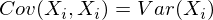
и это справедливо для любых случайных величин.
Таким образом, в нашей матрице по диагонали будут дисперсии признаков (т.к. i = j), а в остальных ячейках — ковариации соответствующих пар признаков. А в силу симметричности ковариации матрица тоже будет симметрична.
Замечание: Ковариационная матрица является обобщением дисперсии на случай многомерных случайных величин — она так же описывает форму (разброс) случайной величины, как и дисперсия.
И действительно, дисперсия одномерной случайной величины — это ковариационная матрица размера 1×1, в которой ее единственный член задан формулой Cov (X, X) = Var (X).
Итак, сформируем ковариационную матрицу Σ для нашей выборки. Для этого посчитаем дисперсии Xi и Xj, а также их ковариацию. Можно воспользоваться вышенаписанной формулой, но раз уж мы вооружились Python«ом, то грех не воспользоваться функцией numpy.cov (X). Она принимает на вход список всех признаков случайной величины и возвращает ее ковариационную матрицу и где X — n-мерный случайный вектор (n-количество строк). Функция отлично подходит и для расчета несмещенной дисперсии, и для ковариации двух величин, и для составления ковариационной матрицы.
(Напомню, что в Python матрица представляется массивом-столбцом массивов-строк.)
covmat = np.cov(Xcentered)
print covmat, "\n"
print "Variance of X: ", np.cov(Xcentered)[0,0]
print "Variance of Y: ", np.cov(Xcentered)[1,1]
print "Covariance X and Y: ", np.cov(Xcentered)[0,1]
OUT:
[[ 9.16666667 17.93002811]
[ 17.93002811 37.26438587]]
Variance of X: 9.16666666667
Variance of Y: 37.2643858743
Covariance X and Y: 17.9300281124
Шаг 3. Собственные вектора и значения (айгенпары)
О'кей, мы получили матрицу, описывающую форму нашей случайной величины, из которой мы можем получить ее размеры по x и y (т.е. X1 и X2), а также примерную форму на плоскости. Теперь надо найти такой вектор (в нашем случае только один), при котором максимизировался бы размер (дисперсия) проекции нашей выборки на него.
Замечание: Обобщение дисперсии на высшие размерности — ковариационная матрица, и эти два понятия эквивалентны. При проекции на вектор максимизируется дисперсия проекции, при проекции на пространства больших порядков — вся ее ковариационная матрица.
Итак, возьмем единичный вектор на который будем проецировать наш случайный вектор X. Тогда проекция на него будет равна vTX. Дисперсия проекции на вектор будет соответственно равна Var (vTX). В общем виде в векторной форме (для центрированных величин) дисперсия выражается так:
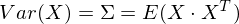
Соответственно, дисперсия проекции:
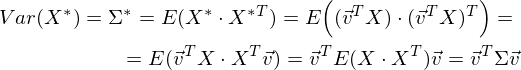
Легко заметить, что дисперсия максимизируется при максимальном значении vT Σv. Здесь нам поможет отношение Рэлея. Не вдаваясь слишком глубоко в математику, просто скажу, что у отношения Рэлея есть специальный случай для ковариационных матриц:
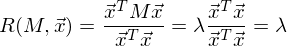
и

Последняя формула должна быть знакома по теме разложения матрицы на собственные вектора и значения. x является собственным вектором, а λ — собственным значением. Количество собственных векторов и значений равны размеру матрицы (и значения могут повторяться).
Кстати, в английском языке собственные значения и векторы именуются eigenvalues и eigenvectors соответственно.
Мне кажется, это звучит намного более красиво (и кратко), чем наши термины.
Таким образом, направление максимальной дисперсии у проекции всегда совпадает с айгенвектором, имеющим максимальное собственное значение, равное величине этой дисперсии.
И это справедливо также для проекций на большее количество измерений — дисперсия (ковариационная матрица) проекции на m-мерное пространство будет максимальна в направлении m айгенвекторов, имеющих максимальные собственные значения.
Размерность нашей выборки равна двум и количество айгенвекторов у нее, соответственно, 2. Найдем их.
В библиотеке numpy реализована функция numpy.linalg.eig (X), где X — квадратная матрица. Она возвращает 2 массива — массив айгензначений и массив айгенвекторов (векторы-столбцы). И векторы нормированы — их длина равна 1. Как раз то, что надо. Эти 2 вектора задают новый базис для выборки, такой что его оси совпадают с полуосями аппроксимирующего эллипса нашей выборки.
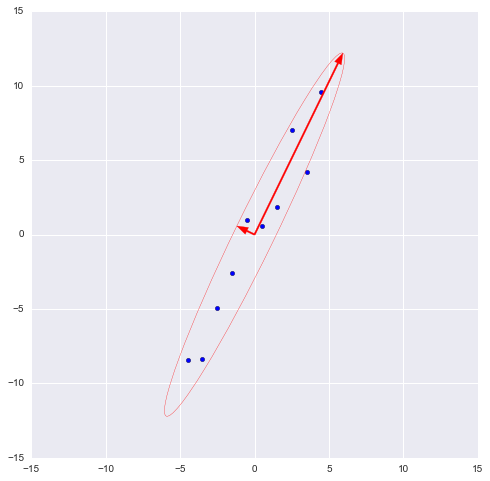
На этом графике мы апроксимировали нашу выборку эллипсом с радиусами в 2 сигмы (т.е. он должен содержать в себе 95% всех наблюдений — что в принципе мы здесь и наблюдаем). Я инвертировал больший вектор (функция eig (X) направляла его в обратную сторону) — нам важно направление, а не ориентация вектора.
Шаг 4. Снижение размерности (проекция)
Наибольший вектор имеет направление, схожее с линией регрессии и, спроецировав на него нашу выборку, мы потеряем информацию, сравнимую с суммой остаточных членов регрессии (только расстояние теперь евклидово, а не дельта по Y). В нашем случае зависимость между признаками очень сильная, так что потеря информации будет минимальна. «Цена» проекции — дисперсия по меньшему айгенвектору — как видно из предыдущего графика, очень невелика.
Замечание: диагональные элементы ковариационной матрицы показывают дисперсии по изначальному базису, а ее собственные значения — по новому (по главным компонентам).
Часто требуется оценить объем потерянной (и сохраненной) информации. Удобнее всего представить в процентах. Мы берем дисперсии по каждой из осей и делим на общую сумму дисперсий по осям (т.е. сумму всех собственных чисел ковариационной матрицы).
Таким образом, наш больший вектор описывает 45.994 / 46.431×100% = 99.06%, а меньший, соответственно, примерно 0.94%. Отбросив меньший вектор и спроецировав данные на больший, мы потеряем меньше 1% информации! Отличный результат!
Замечание: На практике, в большинстве случаев, если суммарная потеря информации составляет не более 10–20%, то можно спокойно снижать размерность.
Для проведения проекции, как уже упоминалось ранее на шаге 3, надо провести операцию vTX (вектор должен быть длины 1). Или, если у нас не один вектор, а гиперплоскость, то вместо вектора vT берем матрицу базисных векторов VT. Полученный вектор (или матрица) будет являться массивом проекций наших наблюдений.
v = (-vecs[0][1], -vecs[1][1])
Xnew = dot(v,Xcentered)
print Xnew
OUT:
[ -9.56404107 -9.02021624 -5.52974822 -2.96481262 0.68933859
0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
dot (X, Y) — почленное произведение (так мы перемножаем векторы и матрицы в Python)
Нетрудно заметить, что значения проекций соответствуют картине на предыдущем графике.
Шаг 5. Восстановление данных
С проекцией удобно работать, строить на ее основе гипотезы и разрабатывать модели. Но не всегда полученные главные компоненты будут иметь явный, понятный постороннему человеку, смысл. Иногда полезно раскодировать, к примеру, обнаруженные выбросы, чтобы посмотреть, что за наблюдения за ними стоят.
Это очень просто. У нас есть вся необходимая информация, а именно координаты базисных векторов в исходном базисе (векторы, на которые мы проецировали) и вектор средних (для отмены центровки). Возьмем, к примеру, наибольшее значение: 10.596… и раскодируем его. Для этого умножим его справа на транспонированный вектор и прибавим вектор средних, или в общем виде для всей выбоки: XTvT+m
Xrestored = dot(Xnew[9],v) + m
print 'Restored: ', Xrestored
print 'Original: ', X[:,9]
OUT:
Restored: [ 10.13864361 19.84190935]
Original: [ 10. 19.9094105]
Разница небольшая, но она есть. Ведь потерянная информация не восстанавливается. Тем не менее, если простота важнее точности, восстановленное значение отлично аппроксимирует исходное.
Вместо заключения — проверка алгоритма
Итак, мы разобрали алгоритм, показали как он работает на игрушечном примере, теперь осталось только сравнить его с PCA, реализованным в sklearn — ведь пользоваться будем именно им.
from sklearn.decomposition import PCA
pca = PCA(n_components = 1)
XPCAreduced = pca.fit_transform(transpose(X))
Параметр n_components указывает на количество измерений, на которые будет производиться проекция, то есть до скольки измерений мы хотим снизить наш датасет. Другими словами — это n айгенвекторов с самыми большими собственными числами. Проверим результат снижения размерности:
print 'Our reduced X: \n', Xnew
print 'Sklearn reduced X: \n', XPCAreduced
OUT:
Our reduced X:
[ -9.56404106 -9.02021625 -5.52974822 -2.96481262 0.68933859
0.74406645 2.33433492 7.39307974 5.3212742 10.59672425]
Sklearn reduced X:
[[ -9.56404106]
[ -9.02021625]
[ -5.52974822]
[ -2.96481262]
[ 0.68933859]
[ 0.74406645]
[ 2.33433492]
[ 7.39307974]
[ 5.3212742 ]
[ 10.59672425]]
Мы возвращали результат как матрицу вектор-столбцов наблюдений (это более канонический вид с точки зрения линейной алгебры), PCA в sklearn же возвращает вертикальный массив.
В принципе, это не критично, просто стоит отметить, что в линейной алгебре канонично записывать матрицы через вектор-столбцы, а в анализе данных (и прочих связанных с БД областях) наблюдения (транзакции, записи) обычно записываются строками.
Проверим и прочие параметры модели — функция имеет ряд атрибутов, позволяющих получить доступ к промежуточным переменным:
— Вектор средних: mean_
— Вектор (матрица) проекции: components_
— Дисперсии осей проекции (выборочная): explained_variance_
— Доля информации (доля от общей дисперсии): explained_variance_ratio_
Замечание: explained_variance_ показывает выборочную дисперсию, тогда как функция cov () для построения ковариационной матрицы рассчитывает несмещенные дисперсии!
Сравним полученные нами значения со значениями библиотечной функции.
print 'Mean vector: ', pca.mean_, m
print 'Projection: ', pca.components_, v
print 'Explained variance ratio: ', pca.explained_variance_ratio_, l[1]/sum(l)
OUT:
Mean vector: [ 5.5 10.31439392] (5.5, 10.314393916)
Projection: [[ 0.43774316 0.89910006]] (0.43774316434772387, 0.89910006232167594)
Explained variance: [ 41.39455058] 45.9939450918
Explained variance ratio: [ 0.99058588] 0.990585881238
Единственное различие — в дисперсиях, но как уже упоминалось, мы использовали функцию cov (), которая использует несмещенную дисперсию, тогда как атрибут explained_variance_ возвращает выборочную. Они отличаются только тем, что первая для получения мат.ожидания делит на (n-1), а вторая — на n. Легко проверить, что 45.99 ∙ (10 — 1) / 10 = 41.39.
Все остальные значения совпадают, что означает, что наши алгоритмы эквивалентны. И напоследок замечу, что атрибуты библиотечного алгоритма имеют меньшую точность, поскольку он наверняка оптимизирован под быстродействие, либо просто для удобства округляет значения (либо у меня какие-то глюки).
Замечание: библиотечный метод автоматически проецирует на оси, максимизирующие дисперсию. Это не всегда рационально. К примеру, на данном рисунке неаккуратное снижение размерности приведет к тому, что классификация станет невозможна. Тем не менее, проекция на меньший вектор успешно снизит размерность и сохранит классификатор.
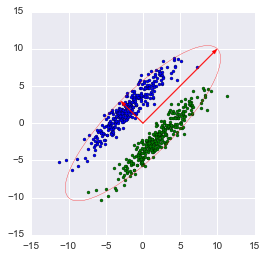
Итак, мы рассмотрели принципы работы алгоритма PCA и его реализации в sklearn. Я надеюсь, эта статья была достаточно понятна тем, кто только начинает знакомство с анализом данных, а также хоть немного информативна для тех, кто хорошо знает данный алгоритм. Интуитивное представление крайне полезно для понимания того, как работает метод, а понимание очень важно для правильной настройки выбранной модели. Спасибо за внимание!
P.S.: Просьба не ругать автора за возможные неточности. Автор сам в процессе знакомства с дата-анализом и хочет помочь таким же как он в процессе освоения этой удивительной области знаний! Но конструктивная критика и разнообразный опыт всячески приветствуются!
