[Из песочницы] Kaggle. Предсказание продаж, в зависимости от погодных условий

Не далее, как в прошлую пятницу у меня было интервью в одной компании в Palo Alto на позицию Data Scientist и этот многочасовой марафон из технических и не очень вопросов должен был начаться с моей презентации о каком-нибудь проекте, в котором я занимался анализом данных. Продолжительность — 20–30 минут.
Data Science — это необъятная область, которая включает в себя, много всего. Поэтому, с одной стороны, есть из чего выбрать, но с другой стороны, надо было подобрать проект, который будет правильно воcпринят публикой, то есть, так, чтобы слушатели поняли поставленную задачу, поняли логику решения, и при этом они могли проникнуться тем, как подход, который я использовал может быть связан с тем, чем они каждый день занимаются на работе.
За несколько месяцев до этого, в эту же компанию пытался устроиться мой знакомый индус. Он им рассказывал про одну из своих задач, над которой он работал в аспирантуре. И, навскидку, это выглядело хорошо: с одной стороны, это связано с тем, чем он занимается последние много лет в университете, то есть он может объяснять детали и ньансы на глубоком уровне, а с другой стороны, результаты его работы были опубликованы в рецензируемом журнале, то есть это вклад в мировую копилку знаний. Но на практике это сработало совсем по-другому. Во-первых, чтобы объяснить, что ты хочешь сделать и почему, надо кучу времени, а у него на всё про всё 20 минут. А, во-вторых, его рассказ про то, как какой-то граф, при каких-то параметрах разделяется на кластеры, и как это всё похоже на фазовый переход в физике, вызвал законный вопрос: «А зачем это надо нам?». Я не хотел такого же результата, так что я не стал рассказывать про: «Non linear regression as a way to get insight into the region affected by a sign problem in Quantum Monte Carlo simulations in fermionic Hubbard model.»
Я решил рассказать про одно из соревнований на kaggle.com, в котором я участвовал.
Выбор пал на задачу в которой надо было предсказать продажи товаров, которые чувствительны к погодным условиям в зависимости от даты и этих самых погодных условий. Соревнование проходило с 1 апреля по 25 мая 2015 года. В отличие от обычных соревнований, в которых призёры получают большие и не очень деньги, и разрешается делиться кодом и, что важнее, идеями, в этом соревновании, приз был прост: job recruiter посмотрит на твоё резюме. И так как рекрутер хочет оценить твою модель, то делиться кодом и идеями было запрещено.
Задача:
- 45 гипермаркетов в 20 различных местах на карте мира (географические координаты нам неизвестны)
- 111 товаров, продажи которых теоретически могут зависеть от погоды, типа зонтиков или молока (товары анонимезированы. То есть мы не пытаемся предсказать, сколько галош было продано в данный день. Мы пытаемся предсказать, сколько было продано товара, скажем с индексом 31)
- Данные с 1 января, 2012 по 30 сентября 2014 года

На этой не очень понятной картинке, которая позаимствована со страницы с описанием данных для данного соревнования, изображено:
- Колонка с цифрами справа — метеорологические станции.
- У каждой метеорологической станции два ряда: нижний все даты, верхний — даты с нестандартными погодными условиями: шторм, сильный ветер, сильный дождь или град, и т.д.
- Синие точки — train set, для которого известны и погода, и продажи. Красные — test set. Погодные условия известны, а вот продажи нет.
Данные представлены в четырёх csv файлах:
- train.csv — продажи каждого из 111 товаров, в каждом из 45 магазинов, каждый день в предстваленный в train set
- test.csv — даты, в которые надо предсказать продажи в каждом из 45 магазинов, для каждого из 111 товаров
- key.csv — какие метеорологические станции расположены рядом с какими магазинами
- weather.csv — погодные условия для каждого из дней в интервале с 1 января 2012 по 30 сентября 2012 для каждой из 20 погодных станций
Метеорологические станции представляют следующие данные (В скобках процент отсутствующих значений.):
- Максимальная температура [градусы Фаренгейта] (4.4%)
- Минимальная температура [градусы Фаренгейта] (4.4%)
- Средняя температура [градусы Фаренгейта](7.4%)
- Отклонение от ожидаемой температуры [градусы Фаренгейта] (56.1%)
- Точка росы [градусы Фаренгейта] (3.2%)
- Температура по влажному термометру [градусы Фаренгейта] (6.1%)
- Время восхода (47%)
- Время заката (47%)
- Суммарное описание типа дождь, туман, торнадо (53.8%)
- Осадки в виде снега [дюймы] (35.2%)
- Осадки в виде дождя [дюймы] (4.1%)
- Атмосферное давление на станции [дюймы ртутного столба](4.5%)
- Атмосферное давление на уровне моря [дюймы ртутного столба](8.4%)
- Скорость ветра [мили в час](2.8%)
- Направление ветра [градусы](2.8%)
- Средняя скорость ветра [мили в час](4.2%)
Очевидные проблемы с данными:
- Мы не знаем географических координат магазинов. И это плохо. Дождь или солнце — это важно, но скорее всего Аляска и Сан Франциско покажут разную динамику продаж.
- Названия товаров анонимезированы. Мы не знаем ID=35 это молоко, виски или ватные штаны.
- Организаторы соревнования решили усугубить предыдущий пункт и английским по белому написали, что нет никаких гарантий, что ID=35 в одном магазине будет означать то же что и в другом.
- Метеорологические станции меряют не всё и не всегда. Погодные данные достаточно дырявые. И вопрос как эти пробелы заполнять надо будет как-то решать.
Для меня, в любой задаче в машинном обучении, над которой я работаю — это «вопроc». В том смысле, что надо понимать вопрос, чтобы найти ответ. Это кажется тавтологией, но у меня есть примеры и в научной деятельности, и в сторонних проектах вроде кагла, когда люди пытались найти ответ не на тот вопрос, который был задан, а на какой-то ими самими придуманный, и ничем хорошим это не заканчивалось.
Второе по важности — это метрика. Мне не нравится как звучит: «Моя модель точнее твоей». Гораздо приятнее будет звучать похожее по смыслу, но чуть более точное: «Моя модель точнее твоей, если мы применим данную метрику для оценки.»
Нам надо предсказать сколько товаров будет продано, то есть эта регрессионная задача. Стандартную регрессионную метрику среднеквадратичного отклонения использовать можно, но нелогично. Проблема в том, что алгоритм, который будет пытаться предсказать сколько пар резиновых сапог будет продано, может предсказать отрицательные значения. И тогда встанет вопрос, что с этими отрицательными значениями делать? Обнулять? Брать абсолютное значение? Муторно это. Можно сделать лучше. Давайте сделаем монотонное преобразование того, что надо предсказать, так чтобы преобразовынные значения могли принимать любые вещественные, в том числе и отрицательные значения. Предскажем их, а потом произведём обратное преобразование на интервал неотрицательных вещественных чисел.
Об этом можно думать, как если наша метрика определена вот таким образом: 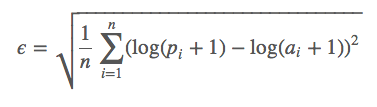
Где:
- a — реальное значение
- p — наше предсказание
- натуральный логарифм от сдвинутого на 1 аргумента — это монотонное отображение с неотрицательной вещественной оси на всю ось, с очевидным обратным преобразованием.
Но, что ещё важнее — в данном соревновании точность нашего предсказания оценивается именно этой метрикой. И использовать я буду именно её: что хотят организаторы, то я им и выдам.
Нулевая итерация или базовая модель.
При работе над различными задачами хорошо себя показал такой подход: как только ты начал работать над задачей — создаёшь «корявый» скрипт, который делает предсказание на нашем test set. Корявый потому, что создаётся по тупому, без размышлений, не смотря на данные, не строя никаких распределений. Идёя в том, что мне нужна нижняя оценка точности модели, которую я могу предложить. Как только у меня есть такой «корявый» скрипт я могу проверять какие-то новые идеи, создавать новые признаки, настраивать параметры модели. Оценку точности я обычно провожу двумя способами:
- hold out set если train set большой и равномерный, 5 fold cross validation если train set маленький или неравномерный
- Результат оценки предсказания на test set, который нам показывает Public Leaderboard на kaggle.
Второй хорош тем, что не занимает много времени. Сделал предсказание, отправил на сайт — получил результат. Плох тем, что число попыток в день ограничено. В данном соревновании это 5. Ещё он хорош тем, что показывает относительную точность модели. Ошибка 0.1 — это много или мало? Если у многих на Public Leaderboard ошибка их предсказания меньше, то это много.
Первый хорош тем, что можно оценивать различные модели, сколько угодно раз.
Проблема в том, что модель оцененная одной и той же метрикой может дать различную точность в этих двух подходах:
Источниками такого несоответствия могут быть:
- данные в train и test из разных распределений
- очень маленький train или test
- хитрая метрика не позволяет сделать человеческий cross validation
На практике достаточно, чтобы улучшение точности модели используя cross validation соответствовало улучшению результатов на Public Leaderboard, точное численное соответствие не обязательно.
Так вот. Первым делом я написал скрипт, который:
- Перегоняет время рассвета/заката из часов и минут в число минут с полуночи.
- Суммарное описание погодных условий в dummy variables.
- Вместо всех пропущенных значений -1.
- Соединяем соответствующие train.csv/test.csv, key.csv и weather.csv
- Полчившийся train set — 4,617,600 объектов.
- Получившийся test set — 526,917 объектов.
Теперь надо скормить эти данные какому-нибудь алгоритму и сделать предсказание. Существует море различных регрессионных алгоритмов, каждый со своими плюсами и минусами, то есть есть и чего выбрать. Мой выбор в данном случае для базовой модели — это Random Forest Regressor. Логика этого выбора в том, что:
- Random Forest обладает всеми преимуществами алгоритмов из семейства Decision Tree, как например теоретически безразличен к тому, если переменныя численная или категорийная.
- Достаточно шустро работает. Если мне не изменяет память — сложность O (n log (n)), где n — число рядов. Что хуже чем метод стохастического градиентного спуска с его линейной сложностью, но лучше чем метод опорных векторов с нелинейным ядром, в котором O (n^3).
- Оценивает важность признаков, что важно для интерпретации модели.
- Безразличен к мультиколлинеарности и коррелированности данных.
Предсказание => 0.49506
Итерация 1.
Обычно, во всех online классах очень много обсуждают какие графики строить, чтобы попытаться понять, что вообще происходит. И это идея правильная. Но! В данном случае есть проблема. 45 магазинов, 111 товаров, причём нет гарантии, что одно и то же ID в разных магазинах соответствует одному и тому же товару. То есть получается, что надо исследовать, а затем предсказать 45×111 = 4995 различных пар (магазин, товар). Для каждой пары погодные условия могут работать по разному. Правильная, простая, но неочевидная идея — построить для каждой пары (магазин, товар) heatmap, на котором отобразить, сколько единиц товара было продано за всё время:

- Во вертикали — индекс товара.
- По горизонтали — интекс магазина.
- Яркость точек — Log (сколько единиц товара было продано за всё время).
И что мы видим? Картинка достаточно бледная. То есть не исключено, что какие-то товары в каких-то магазинах впринципе не продавались. Я это связываю с географическим расположением магазинов. (Кто будет покупать пуховый спальник на Гаваях?). А давайте исключим из нашего train и test те товары, которые в данном магазине никогда и не продавались.
- train из 4617600 рядов сокращается до 236038
- test из 526917 сокращается до 26168
то есть размер данных сократился почти в 20 раз. И как следствие:
- Мы убрали часть шума из данных. Как следствие, алгоритму будет проще тренироваться и предсказывать, то есть должна увеличиться точность модели.
- Модель тренируется гораздо быстрее, то есть проверять новые идеи стало гораздо проще.
- Теперь мы тренируем на уменьшенном train (236038 объектов), предсказываем на уменьшенном test (26168 объектов), но так как кагл хочет предсказание с размером (526917 объектов) то остаток забиваем нулями. Логика в том, что если какой-то товар никогда не был продан в данном магазине, то либо он так никогда и не будет продан, либо он будет продан, но мы этого не сможем предсказать в любом случае.
Предсказание → 0.14240. Ошибка уменьшилась в три раза.
Итерация 2.
Урезание размеров train/test сработало замечательно. Можно ли усугубить? Оказывается, что можно. После предыдущей итерации у меня получилось всего 255 ненулевых пар (магазин, товар), а это уже обозримо. Я просмотрел на графики для каждой пары и обнаружилось, что какие-то товары не продавались не из-за полохих/хороших погодных условий, а просто потому что их не было в наличии. Например, вот такая картинка для товара 93, в магазине 12:
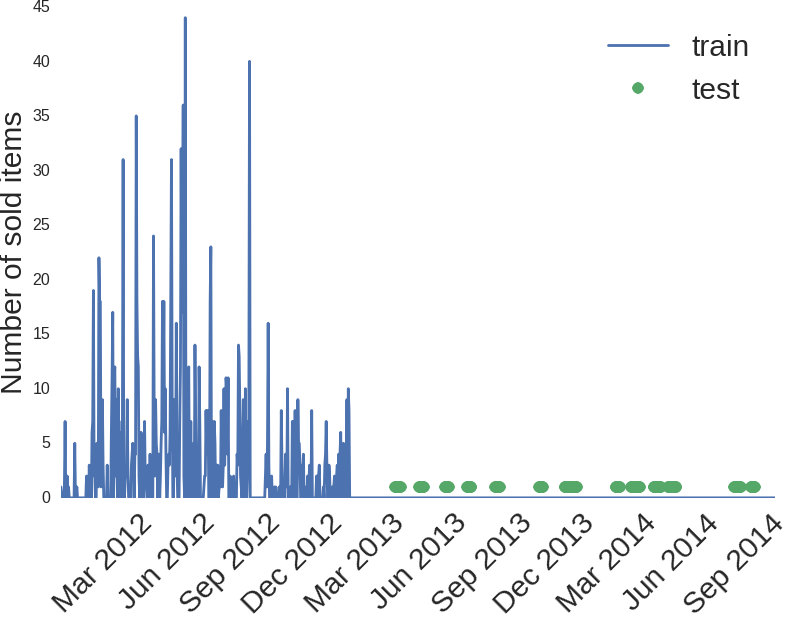
Я не знаю, что это за товар, но есть подозрение, что его продажи закончились в конце 2012 года. Можно попробовать удалить эти товары из train, и в test всем им поставить 0, как наше предсказание.
- train уменьшается до 191000 объектов
- test уменьшается до 21272 объектов
Предсказание → 0.12918
Итерация 3.
Название соревнований предполагает предсказание на основе погодных данных, но, как обычно, они лукавят. Задача, которую мы пытаемся решить звучит по другому:
«У вас есть train, у вас есть test, крутитесь, как хотите, но сделайти наиболее точное при данной метрике предсказание.»
А в чём разница? А разница в том, что у нас есть не только погодные данные, но и дата. А дата — это источник очень мощных признаков.
- Данные за три года => годовая периодичность => новые признаки год и число дней с нового года
- Люди получают зарплату раз в месяц. Не исключено что есть месячная периодичность в покупках. => новый признак месяц
- То, как люди совершают покупки может быть связано с днём недели. Дождь это, конечно, да, но вечер пятницы, это вечер пятницы => новый признак день недели.
Предсказание → 0.10649 (кстати мы уже в топ 25%)
А что насчёт погоды?
Оказывается, что погода не очень-то и важна. Я честно пытался добавить ей веса. Пытался заполнять пропущенные значения различными способами, как то средние значние по признаку, по разным хитрым подгруппам, пытался предсказывать пропущенные значения используя различные алгоритмы машинного обучения. Слегка помогло, но на уровне погрешности.
Следующий этап — линейная регрессия.
Не смотря на кажущуюся простоту алгоритма, и кучу проблем, которыми данный алгоритм обладает, есть и у него существенные преимущества, которые делают его одним из моих любимых регрессионных алгоритмов.
- Категорийные признаки как день недели, месяц, год, номер магазина, индекс товара перегоняются в dummy variables
- Масштабирование, чтобы увеличисть скорость сходимости и интепретируемость результатов.
- Подкрутка параметров L1 и L2 регуляризации.
Предсказание → 0.12770
Это хуже, чем Random Forest, но не так, чтобы очень сильно.
Спрашивается, зачем мне вообще линейная регрессия на нелинейных данных? Есть на то причина. И причина эта — оценка важности признаков.
Я использую три различных подхода для этой оценки.
Первый — это то, что выдаёт RandomForest после того, как мы его натренировали: 
Что мы видим на этой картинке? То что тип продаваемого товара, а так же номер магазина — это важно. А остальное гораздо меньше. Но это мы могли сказать даже и не глядя на данные. Давайте уберём тип товара и номер магазина: 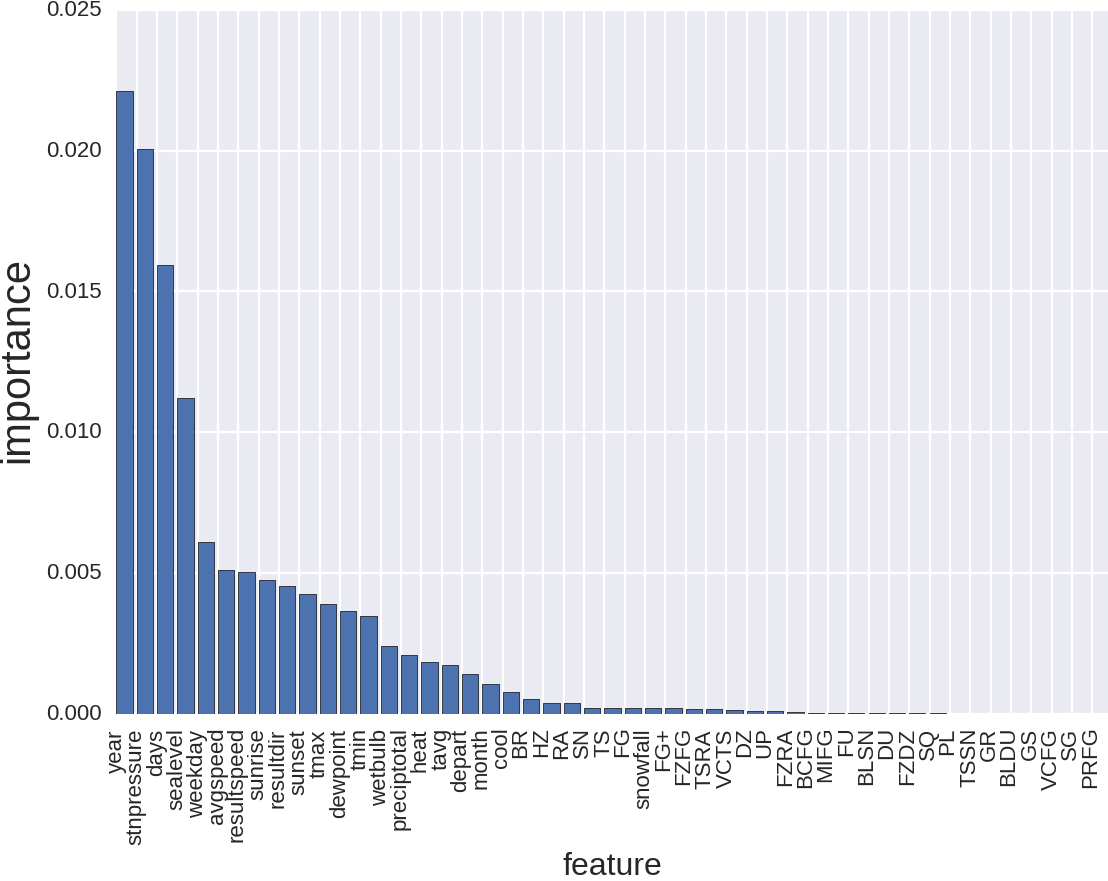
И что тут? Год — возможно это логично, но это мне неочевидно. Давление — это, мне, кстати, было понятно, а вот людям которым я это вещал было не очень. Всё-таки в Питере частая смена погода, которая сопровождается сменой атмосферного давления, и то, как это меняет настроение и самочувтствие, и в особенности у пожилых людей я был вкурсе. Людям, живущим в Калифорнии, с её стабильным климатом это было неочевидно. Что дальше? Число дней с начала года — тоже логично. Отсекает в какой сезон мы пытаемся предсказать продажи. А погода, как ни крути, с сезоном может быть и связана. Далее день недели — тоже понятно. и т.д.
Второй способ — это абсолютная величина коэффициентов, которую выдаёт линейная регрессия на отмасштабированных данных. Чем больше коэффициент — тем большее влияние он имеет.
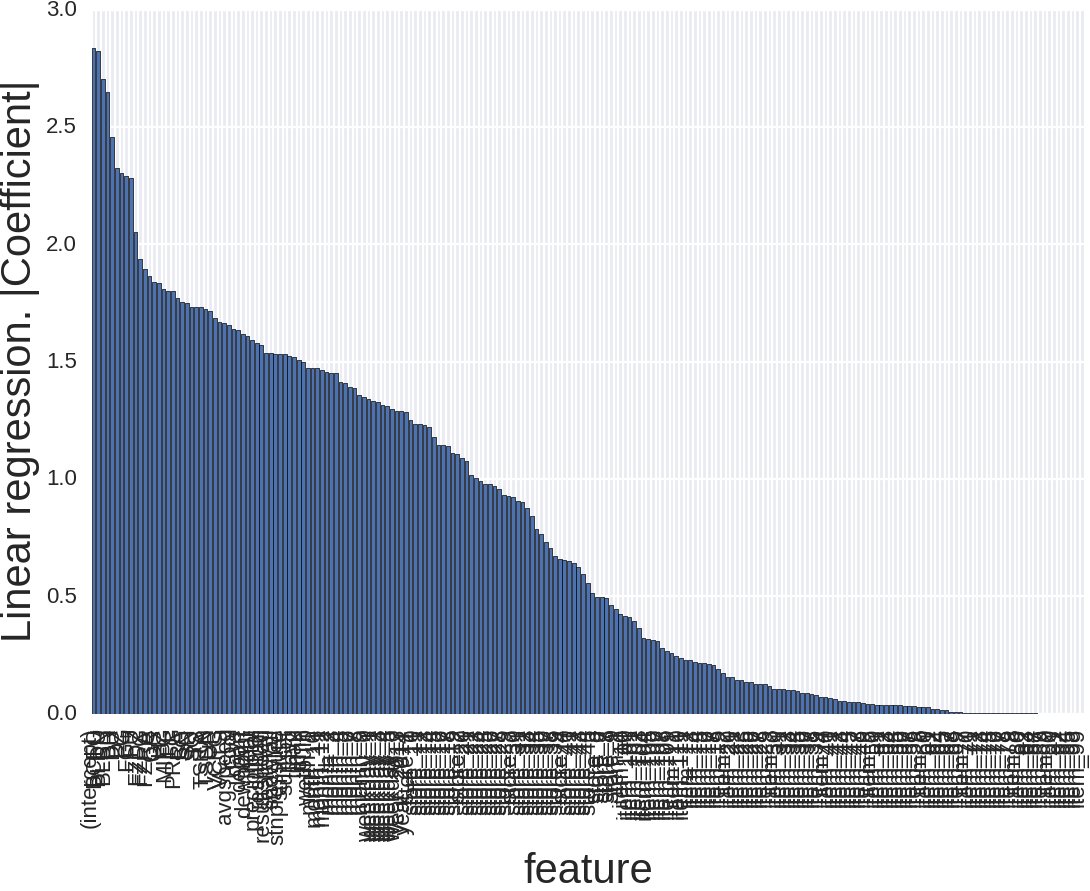
Картинка выглядит вот так и тут мало что понятно. Причина того, что независимых переменных так много в том, что, например, типа товара для RandomForest — это однин признак, а тут их аж 111, то же и с номером магазина, месяцем и днём недели. Давайте уберём тип товара и номер магазина.
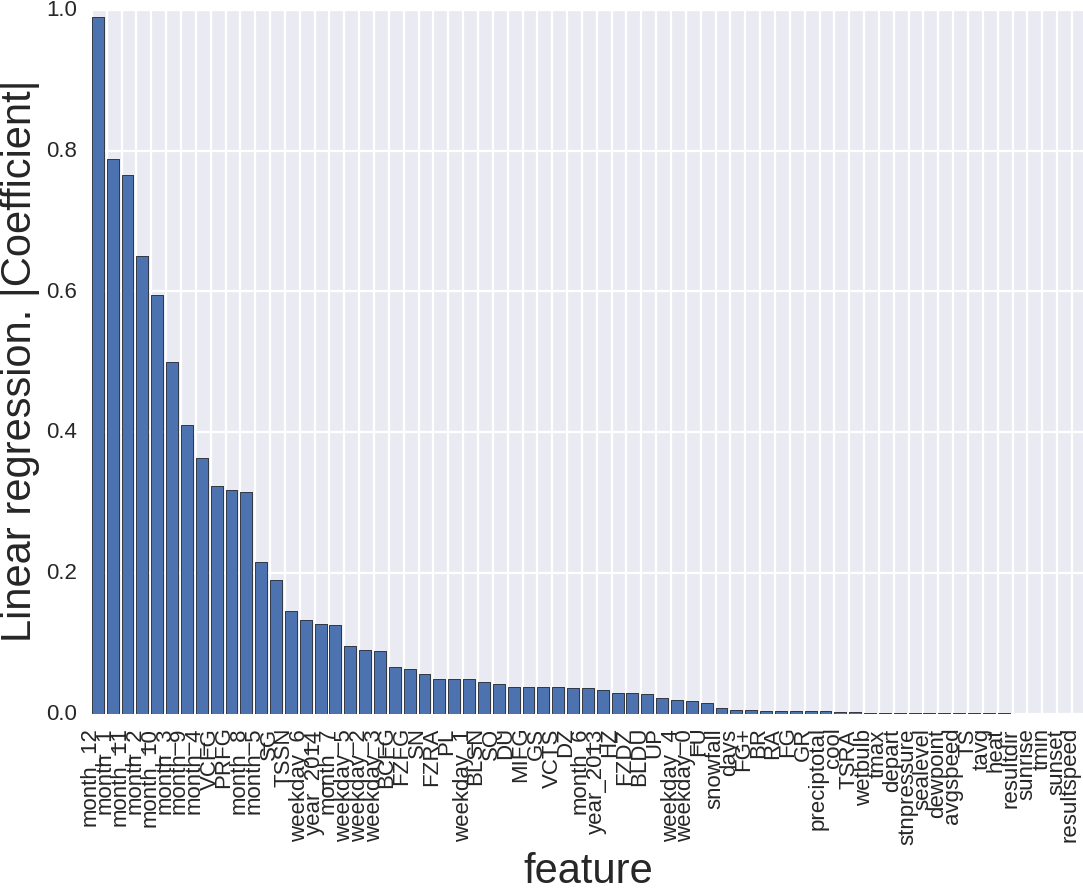
Так лучше. И что тут происходит? Месяц — это важно, причём особенно, если это декабрь, январь или ноябрь. Вроде тоже логично. Зима. Погода. И что немаловажно, праздники. Тут и новый год, и день благодарения, и рождество.
Третий метод — метод грубой силы, выкидывать признаки по одному и смотреть, как это повлияет на точность предсказания. Самый надёжный, но самый муторный.
С нахождением признаков и их интерпретацией вроде закончили, теперь численные методы. Тут всё прямолинейно. Пробуем разные алгоритмы, находим оптимальные параметры вручную или используя GridSearch. Комбинируем. Предсказываем.
- Линейная регрессия (0.12770)
- Random Forest (0.10649)
- Gradient Boosting (0.09736)
Я особо изобретать не стал. Взял взвешенное среднее от этих предсказаний. Веса вычислил, предсказывая этими алгоритмами на holdout set, который откусил от train set.
Получилось что-то вроде 0.85% Gradient Boosting, 10% Random Forest, 5% Linear regression.
Результат 0.09532 (15 место, топ 3%)

Где best known result — это первое место на Private LeaderBoard.
Что не сработало:
- kNN — простой алгоритм, но часто хорошо показывает себя как часть ансамбля. Я не смог выжать из него больше (0.3)
- Нейронные сети — при правильном подходе даже на таких разношёрстных данных показывают достойный результат, и что важно, часто замечательно показывают себя в ансамлях. Тут у меня прямоты рук не хватило, что-то где-то я перемудрил.
- Я пытался строить отдельные модели для каждой погодной станции, товара, магазина, но данных становится совсем мало, так что точность предсказания падает.
- Была предпринята попытка анализа временных рядов и выделения тренда, и периодичных компонент, но это точность предсказания также не увеличило.
Итого:
- Хитроумные алгоритмы — это важно, и сейчас существуют алгоритмы, которые прямо из коробки выдают очень точные результаты. (Например, меня порадовала конволюционная нейронная сеть из 28 слоёв, которая сама вычленяет выжные признаки из изображений.)
- Подготовка данных, и создание умных признаков — это часто (но не всегда) гораздо важнее чем сложные модели.
- Часто гениальные идеи не работают.
- Иногда, совершенно глупые и бесперспективные идеи работают замечательно.
- Люди — это такие существа, которые любят находится в зоне комфорта, и следовать своему проверенному временем графику, который основывается на календаре, а не на сиюминутном импульсе, вызванном погодными условиями.
- Я пытался выжать как можно больше из этих данных, но если бы мы знали цену товаров, или их названия, или географическое положение магазинов решение было бы другим.
- Я не пробовал добавлять погоду до и после дня, для которого надо делать предсказание. Также я не пробовал создавать отдельный признаку для описания праздников. Не исключено, что это бы помогло.
- На все, про всё я потратил неделю, время от времени отрываясь от дописывания диссертации и запуская очередную итерацию. Возможно, точность предсказания можно было бы увеличить, если бы я потратил больше времени, хотя с другой стороны, раз я этого не сделал за неделю, значит так тому и быть. На kaggle.com куча интересных соревнований, и зацикливаться на каком-то одном не очень правильно с точки зрения эффективности получения знаний.
- Всем, кто не пробовал участвовать в соревнованиях на kaggle.com — рекомендую. Оно интересно и познавательно.
