[Из песочницы] Фоновое выполнение ячеек в IPython Notebook
Я много работаю с данными, поэтому практически все процессы у меня завязаны на Jupyter (IPython Notebook). Эта среда прекрасна и я её большой фанат. По сути, Jupyter — это обычная питоновая консоль и весь код там выполняется последовательно. Но иногда возникает желание запустить вычисления в ячейке и, не дожидаясь пока они закончатся, продолжить работу. Например, нужно скачать 1000 урлов и достать у них заголовки страниц. Хорошо бы запустить процесс скачивания и сразу начать отлаживать код для выделения заголовков.
Это должно выглядеть примерно так:

Удивительно, но готового способа так сделать я не нашёл и хотел бы поделиться простым, но удобным вариантом решения.
Теперь из проекта в проект у меня кочует следующий кусочек кода:
def jobs_manager():
from IPython.lib.backgroundjobs import BackgroundJobManager
from IPython.core.magic import register_line_magic
from IPython import get_ipython
jobs = BackgroundJobManager()
@register_line_magic
def job(line):
ip = get_ipython()
jobs.new(line, ip.user_global_ns)
return jobs
В нём используется встроенный в Jupyter модуль IPython.lib.backgroundjobs — надстройка над threading, которая ведёт учёт фоновых операций. Метод хорошо сочетается c виджетным прогресс-баром, о котором я недавно писал. Типичный пример использования:

Посмотреть состояние операций можно через метод status:
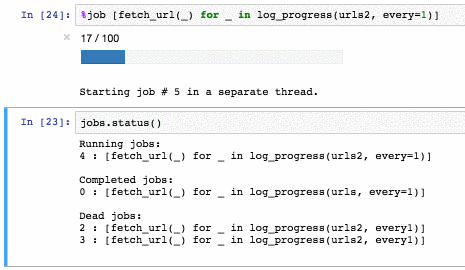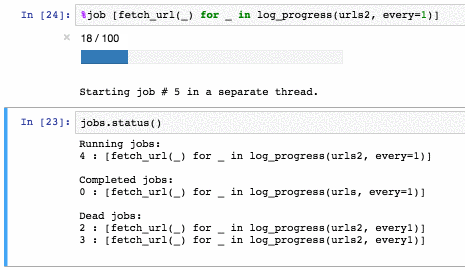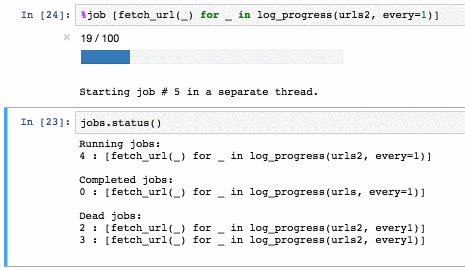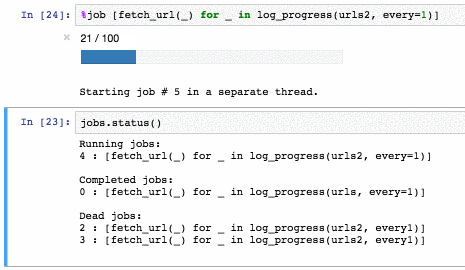
Чтобы убить операцию, используется специальный хак:
def kill_thread(thread):
import ctypes
id = thread.ident
code = ctypes.pythonapi.PyThreadState_SetAsyncExc(
ctypes.c_long(id),
ctypes.py_object(SystemError)
)
if code == 0:
raise ValueError('invalid thread id')
elif code != 1:
ctypes.pythonapi.PyThreadState_SetAsyncExc(
ctypes.c_long(id),
ctypes.c_long(0)
)
raise SystemError('PyThreadState_SetAsyncExc failed')
Например так:
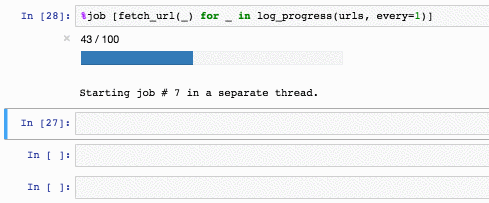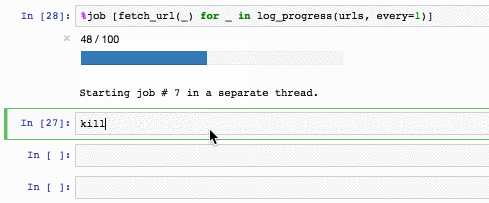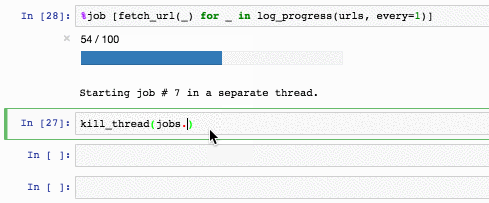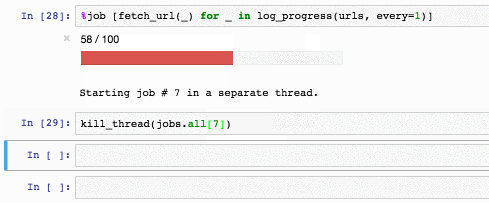
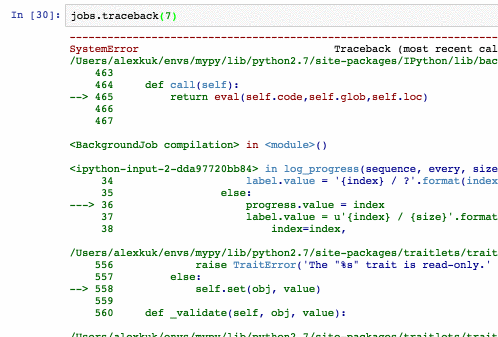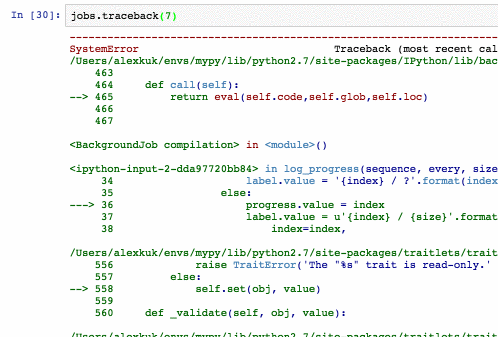
jobs также копит стектрейсы (kill_thread кидает SystemError внутри треда):
%job можно даже использовать как альтернативу multiprocessing.dummy.Pool:
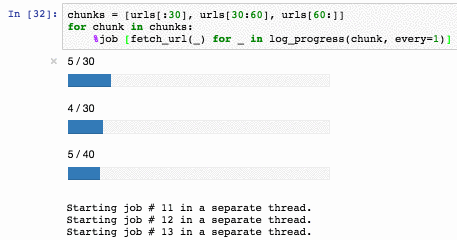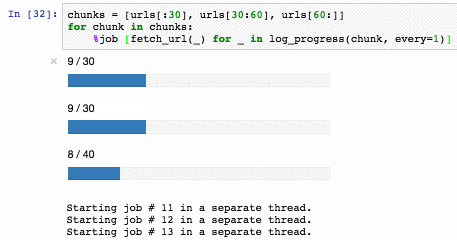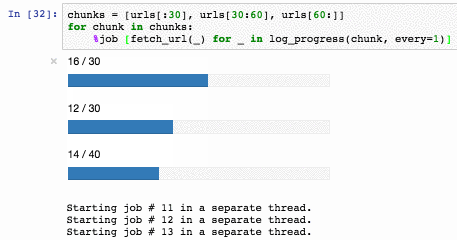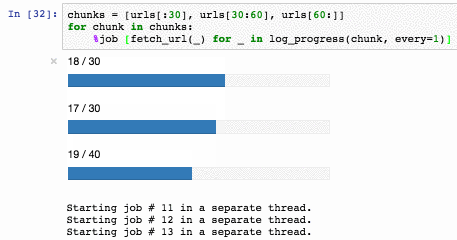
Нарезать последовательность на заданное количество кусочков удобно функцией:
def get_chunks(sequence, count):
count = min(count, len(sequence))
chunks = [[] for _ in range(count)]
for index, item in enumerate(sequence):
chunks[index % count].append(item)
return chunks
Завершить работу пула можно так:
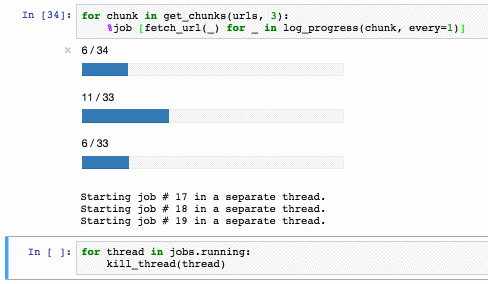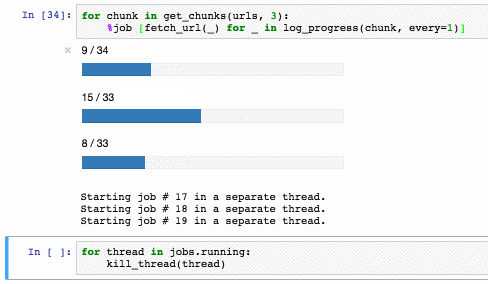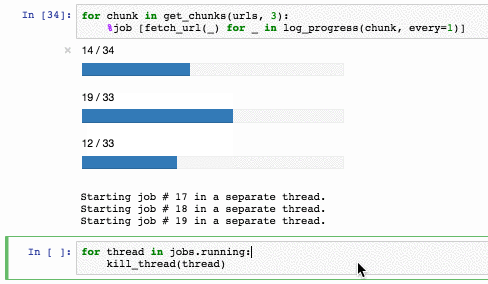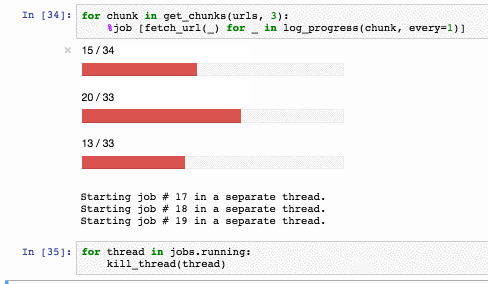
У метода есть ряд ограничений:
- %job работает на тредах, поэтому нужно помнить про GIL. %job — это не про распараллеливание тяжелых вычислений, которые происходят в питоновом байт-коде. Это про IO-bound операции и вызов внешних утилит.
- Нельзя нормально завершить произвольный код внутри треда, поэтому в kill_thread используется хак. Этот хак работает не всегда. Например, если код внутри треда выполняет sleep исключение, которое кидает kill_thread игнорируется.
- Код в %job выполняется через eval. Грубо говоря, можно использовать выражения, который могут встречаться после знака =. Никаких print и присваиваний. Впрочем, всегда можно завернуть сложный код в функцию и выполнить %job f ().
- Передача сообщений из %job выполняется через жёсткий диск. Например, нельзя непосредственно получить содержание скачанной страницы, нужно его сохранить на диск, а потом прочитать.
Код распространяет копипейстом и доступен на Гитхабе.
