[Из песочницы] Архитектура Servo
От переводчика. Позвольте представить на суд хабрасообщества перевод части документации о браузерном движке Servo. Этот движок разрабатывается сообществом Mozilla на языке Rust, и является, пожалуй, самым большим активным проектом на этом языке. В этом документе рассказывается об архитектуре движка, как разработчики используют Rust совместно с C++ и с какими трудностями они столкнулись при разработке. Оригинал доступен в wiki проекта на github.
Это очень поверхностный обзор архитектуры Servo. Servo остаётся прототипом, и некоторые части архитектуры ещё не представлены в виде кода. Некоторые важные аспекты системы ещё не были подробно рассмотрены.
Servo — это исследовательский проект по разработке нового браузерного движка. Наша цель заключается в том, чтобы создать архитектуру, которая получает преимущества от параллелизма и в то же время устраняет распространённые источники багов и уязвимостей, связанных с некорректным управлением память и состояниями гонки.
Так как C++ не очень хорошо подходит для предотвращения этих проблем, Servo написан на Rust, новом языке, разработанном специально с учётом требований Servo. Rust предоставляет параллельную инфраструктуру, основанную на задачах (task-parallel infrastructure) и сильную систему типов, которая обеспечивает безопасность памяти и свободу от состояний гонок.
При принятии решений во время проектирования мы отдаём приоритет чертам современной web-платформы, которые сводятся к высокопроизводительным, динамичным, богатым мультимедиа приложениям, возможно, в ущерб тому, что не может быть оптимизировано. Мы хотим знать, что из себя представляет быстрая и отзывчивая web-платформа и реализовать её.
Servo явно не претендует на создание полноценного браузера (за исключением нужд демонстрации или экспериментов). Наоборот, он нацелен на создании целостного, внедряемого (embeddable) движка. Хотя Servo это исследовательский проект, он спроектирован быть пригодным к реальному использованию — код, который мы пишем, должен быть достаточно высокого качества, чтобы, в конечном счёте, достигнуть пользователей.
Стратегии параллелизма и конкурентности
Конкурентность это разделение задач на части для чередования выполнения. Параллелизм это одновременное выполнение нескольких частей работы для увеличения скорости. Некоторые идеи в этом направлении, которые мы изучаем или планируем рассмотреть:
- Архитектура, основанная на задачах. Главные компоненты системы должны быть
представлены в виде акторов, с изолированной памятью, с четными границами для возможности отказа и восстановления. Это также будет способствовать слабое связывание компонентов системы, позволяя нам заменять их с целью экспериментирования и исследования. Реализовано. - Конкурентный рендеринг. Рендеринг и композитинг производятся в разных потоках, отделённых от представления для обеспечения отзывчивости. Поток композитинга самостоятельно управляет своей памятью, чтобы избежать сборок мусора. Реализовано.
- Рендеринг на основе тайлов. Мы представляем экран как сетку из тайлов и отрисовываем каждый из них параллельно. Помимо выигрыша от параллелизма, тайлы нужны для производительности на мобильных устройствах. Реализовано частично.
- Послойный рендеринг. Мы разделяем список отображения (display list) на поддеревья, которые могут быть обработаны GPU и рендерим их параллельно. Реализовано частично.
- Сопоставление селекторов. Эта задача на удивление легко параллелизуется. В отличие от Gecko, Servo производит сопоставление селекторов отдельно от построения дерева отображения, что параллелизуется гораздо проще. Реализовано.
- Параллельное размещение. Мы строим дерево отображения использую параллельный обход DOM, который учиывает зависимости, основанные на элементах, такие как выравнивание (float). Реализовано.
- Формовка текста. Важная часть внутристрочного расположения, формовка текста (применение курсива, полужирного начертания — прим. пер.) достаточно затратная и потенциально может быть параллелизована. Не реализовано.
- Парсинг. В настоящее время мы пишем новый парсер HTML на Rust, фокусируясь в равной степени на безопасности и соответствии спецификации. В процессе.
- Декодирование изображений. Параллельное декодирование нескольких изображений это просто. Реализовано.
- Декодирование других ресурсов. Это, вероятно, менее важно, чем декодирование изображений, но всё, что загружается страницей может быть обработано параллельно, например, парсинг таблиц стилей или декодирование видео. Реализовано частично.
- Сборщик мусора JS конкурирует с отображением. Практически при любой архитектуре, включающей JS и отображение, JS будет ждать выполнения обращений к отображению, возможно часто. Это будет наиболее подходящее время для сборки мусора.
Сложности
- Производительность. Параллельные алгоритмы, как правило, требуют идти на тяжелые компромиссы. Важно действительно быть быстрым. Мы должны убедиться, что Rust сам по себе имеет производительность, близкую к C++.
- Структуры данных. Rust имеет довольно новаторскую систему типов, в частности для того, чтобы сделать параллельные типы и алгоритмы безопасными, и мы долны понять, как использовать её эффективно.
- Незрелость языка. Компилятор Rust и язык совсем недавно стабилизировались. Rust также располагает меньшим выбором библиотек, чем C++; мы можем использовать библиотеки на C++, но это требует больше усилий, чем просто использование заголовочных файлов.
- Не-параллельные библиотеки. Некоторые нужные нам сторонние библиотеки плохо ведут себя в многопоточной среде. В частности, со шрифтами были сложности. Даже если библиотеки технически и потокобезопасны, часто эта безопасность достигается за счёт единого для библиотеки мьютекса, что вредит нашим возможностям по параллелизации.
Диаграммы
Диаграмма надзора за задачами
Диаграмма взаимодействия задач
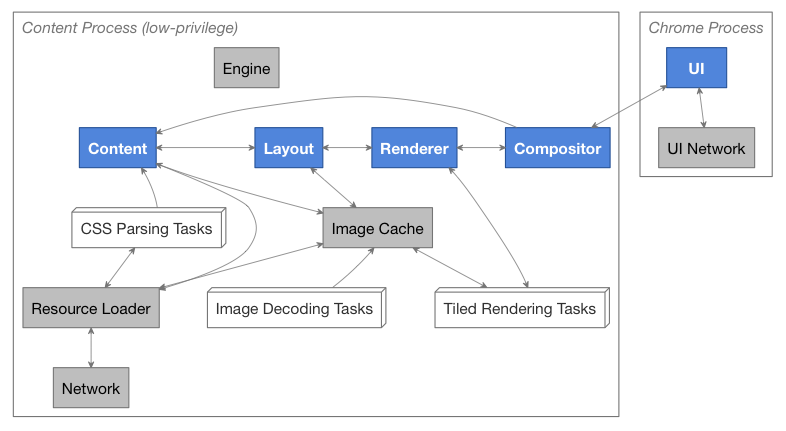
- Каждый прямоугольник представляет задачу Rust.
- Синие прямоугольники представляют главные задачи из конвейера браузера.
- Серые прямоугольники представляют вспомогательные задачи для конвейера.
- Белые прямоугольники представляют рабочие задачи. Каждый такой прямоугольник представляет несколько таких задач, точное количество которых зависит от загруженности.
- Прерывистые линии указывают на отношение надзора.
- Сплошные линии обозначают коммуникационные связи.
Описание
Каждый экземпляр constellation можно рассматривать как отдельную вкладку или окно. Он управляет конвейером задач, который принимает ввод, выполняет JavaScript для DOM, выполняет размещение элементов, строит списки отображения, рендерит списки отображения в тайлы и отображает финальное изображение на поверхность.
Конвейер состоит из четырёх основных задач:
- Скрипт — главная миссия скрипта заключается в том, чтобы создать собственную DOM и выполнить JavaScript. Он получает события из множества источников, включая события навигации, и перенаправляет их как требуется. Когда задаче, обрабатывающей содержимое, требуется получить информацию о размещения, она должна отправить запрос задаче размещения.
- Задача размещения — размещение делает слепок DOM, вычисляет стили и строит главную структуру данных отображения — дерево отображения. Дерево отображения используется для вычисления расположения узлов и на основании этого строится список отображения, который отправляется рендереру.
- Рендерер — рендерер получает список отображения и рендерит видимые части на один или несколько тайлов, по возможности, параллельно.
- Наборщик — наборщик объединяет тайлы от рендерера и отправляет их на экран. Будучи частью потока UI, наборщик это первый, кто получает события UI, которые, обычно, немедленно направляются содержимому для обработки (хотя некоторые события, такие как события прокрутки, могут быть предварительно обработаны наборщиком в целях отзывчивости).
В этом конвейере при взаимодействии задач используются две сложные структуры данных: DOM и список отображения. DOM передаётся от задачи по обработке содержимого к задаче по обработке размещения, и список отображения от задачи по размещению к рендереру. Поиск эффективного и типо-безопасного способа представлять, разделять и/или передавать эти две структуры — одна из главных сложностей этого проекта.
nwrite DOM
DOM в Servo это дерево с поддержкой версионирования узлов, которое может быть разделено между одним писателем и несколькими читателями. DOM использует стратегию копирование-при-записи (copy-on-write), чтобы позволить писателю модифицировать DOM параллельно с работой читателей. Задача обработки содержимого всегда пишет, а задачи размещения или их подзадачи всегда читают.
Узлы DOM это значения Rust, чьё время жизни управляется сборщиком мусора JavaScript. JavaScript обращается к узлам DOM напрямую — здесь нет XPCOM или похожей инфраструктуры.
Интерфейс DOM на данный момент не типо-безопасен — возможно некорректно манипулировать узлами, что приведет к разыменованию некорректных указателей. Устранение этой небезопасности высокоприоритетная и необходимая цель проекта; так как узлы DOM имеют сложный жизненный цикл это приведет к некоторым трудностям.
Список отображения
Рендеринг Servo полностью управляется cписком отображения- последовательностью высокоуровневых команд, созданных задачей расположения. Список отображения Servo неизменяем, так что он может быть разделён между конкурентно работающими рендерерами и он содержит всё необходимое для отображения. Это отличается от рендерера WebKit, который не использует список отображения и рендерера Gecko, который использует список отображения, но также, во время рендеринга, обращается к дополнительной информации, например, напрямую к DOM.
В настоящее время мы используем SpiderMonkey, хотя подключаемые движки это долгосрочная низкоприоритетная задача. Каждая задача обработки содержимого получает свою среду выполнения JavaScript. Привязки к DOM используют нативный API движка, вместо XPCOM. Автоматическая генерация привязок из WebIDL в приоритете.
Так же, как Chromium и WebKit2 мы намерены иметь доверенный процесс-приложение и несколько менее доверенных процессов-движков. Высокоуровневый API будет, фактически, основан на IPC, и скорее всего, с не-IPC реализациями для тестирования и однопроцессного варианта, хотя предполагается, что наиболее серьезные пользователи будут использовать несколько процессов. Процесс движка будет использовать предоставляемые операционной системой механизмы песочницы для ограничения доступа к системным ресурсам.
В настоящий момент мы не намерены вдаваться в крайности в отношении песочницы, как разработчики Chromium, в основном, потому что такое завязывание на песочницу требует много труда разработчиков (в частности на низкоприоритетных платформах, вроде Windows XP или старых Linux) и другие аспекты проекта более приоритетны. Система типов Rust также добавляет важный уровень обороны от уязвимостей, связанных с защитой памяти. Одно это нисколько не делает песочницу менее важной в плане защиты от небезопасного кода, багов в системе типов и сторонних библиотек и библиотек на локальном компьютере, но существенно это уменьшает возможность для атак на Servo по сравнению с другими браузерными движками. Кроме того, мы испытываем беспокойство касательно производительности, связанное с некоторыми техниками песочниц (например, проксирование всех вызовов OpenGL к отдельном процессу).
Веб-страницы зависят от множества внешних ресурсов, с большим количеством механизмов получения и декодирования. Эти ресурсы кешируются на нескольких уровнях — на диске, в памяти, и/или в декодированном виде. В рамках параллельного браузера, эти ресурсы должны быть распространены среди конкурентных задач.
Традиционно, браузеры были однопоточными, выполняя ввод-вывод в «главном потоке», где также производится большая часть вычислений. Это приводит к проблемам с задержками. В Servo нет «главного потока» и загрузка всех внешних ресурсов производится в едином менеджере ресурсов.
Браузеры используют много кешей, и архитектура Servo, основанная на задачах, подразумевает, что он, возможно, будет использовать больше кешей, чем существующие движки (у нас, возможно, будет как глобальный кеш, основанный на отдельной задаче, так и локальный для задачи кеш, который хранит результаты из глобального кеша, чтобы избежать обращений через планировщик). Servo должен иметь унифицированный механизм кеширования, с настраиваемыми кешами, которые будут работать в средах с малым объёмом памяти.
