Видеоускоритель AMD Radeon RX 6800 XT: долгожданное топовое решение AMD
Прибытие новинок, визуальное сравнение с картами Nvidia
Особенности архитектуры
С выходом линейки видеокарт Radeon RX 6000 наконец-то настало время, когда компания AMD вернулась в борьбу за сегмент топовых видеокарт. Мы ждали этого уже довольно долго, и хотя Radeon RX 480, RX 580 и RX 590 были (да и до сих пор остаются за свою цену) отличными решениями, но верхние модели линеек Vega 64 и Radeon VII всегда в чем-то уступали конкурентам, да и сложно было их назвать массовыми моделями, производство этих графических процессоров по понятным причинам было довольно ограничено.
Так что, по сути, в самом верху рынка графических процессоров несколько долгих лет безраздельно царствовала Nvidia, и конкуренция в том сегменте была скорее условной. То Vega 64 откусит небольшой кусочек, то Radeon VII. И только теперь, с выходом мощных решений семейства Radeon RX 6000, это вполне может измениться. По крайней мере, все предпосылки для этого есть, ведь AMD анонсировала сразу несколько моделей, среднюю из которых мы рассмотрим сейчас, а старшая выйдет в декабре.

Лучшие графические процессоры AMD из предыдущего поколения, в виде Radeon RX 5700 (XT), были весьма неплохи по соотношению цены и производительности, но серьезно отставали от соответствующих видеокарт Nvidia как по возможностям, не имея аппаратной поддержки трассировки лучей и других фич DirectX 12 Ultimate, так и по энергоэффективности, серьезно отставая по этому показателю от лучших GPU конкурента. Ну и топовых решений архитектуры RDNA первого поколения так и не появилось, так как именно низкая энергоэффективность и не позволила создать мощный GPU с вменяемым потреблением.
Так что абсолютно очевидно, что основными задачами AMD за прошедшие с анонса RDNA 1 месяцы являлось значительное улучшение энергоэффективности в RDNA 2 при одновременном добавлении всех недостающих возможностей, появившихся в графических API. И они действительно пообещали улучшить энергоэффективность сразу на 50%, а также мы ожидали добавления поддержки DX12 Ultimate, главной из возможностей которой является аппаратная трассировка лучей, применяемая даже уже и в новых консолях (эти чипы также спроектировали в AMD, но это уже другая история). Сегодня мы подробно поговорим о том, чего и как достигли специалисты AMD в погоне за явно вырвавшимся вперед конкурентом.
Ведь в последние годы с подачи Nvidia в играх все чаще начал применяться гибридный рендеринг с эффектами, рассчитанными при помощи трассировки лучей, которые выполняют хоть и пока что не самую большую, но довольно важную часть отрисовки сцены, вроде отражений или теней. И делают это с большей реалистичностью, по сравнению с любыми хитрыми хаками растеризации, выдуманными за эти годы. И архитектура RDNA 2 как раз включает полную поддержку DX12 Ultimate, включая трассировку лучей и другие возможности, которые или уже используются или вскоре будут использоваться в будущих играх, включая мультиплатформенные.
Среди других важных особенностей новых решений семейства Radeon RX 6000 отметим внедрение совершенно новой кэш-памяти последнего уровня Infinity Cache объемом в космические 128 МБ (для сравнения, все предыдущие GPU имеют ну пусть по 4 МБ кэш-памяти, не больше), что может во многом поменять подход к разработке приложений, а также пусть и не особенно новую принципиально, но ставшую доступной только теперь возможность доступа системы ко всей видеопамяти при помощи технологии Smart Access Memory, о которой мы подробно поговорим далее. А заодно, AMD заявляет о практически удвоенной производительности новых решений относительно Radeon RX 5700 XT, и это касается как игр, так и профессиональных приложений.
Основой рассматриваемой сегодня модели видеокарты Radeon RX 6800 XT стал графический процессор Navi 21, также известный как Big Navi, основанный на новой архитектуре RDNA второго поколения, которая тесно связана как с RDNA 1, так и с GCN последних поколений. И перед прочтением статьи будет полезно ознакомиться с нашими предыдущими материалами по видеокартам компании AMD:

| Графический ускоритель Radeon RX 6800 XT | |
|---|---|
| Кодовое имя чипа | Navi 21 |
| Технология производства | 7 нм TSMC |
| Количество транзисторов | 26,8 млрд (у Navi 10 — 10,3 млрд) |
| Площадь ядра | 519,8 мм² (у Navi 10 — 251 мм²) |
| Архитектура | унифицированная, с массивом процессоров для потоковой обработки любых видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | DirectX 12 Ultimate, с поддержкой уровня возможностей Feature Level 12_2 |
| Шина памяти | 256-битная: 4 независимых 64-битных контроллера памяти с поддержкой GDDR6 |
| Частота графического процессора | до 2250 МГц |
| Вычислительные блоки | 72 (из 80) вычислительных блока CU, состоящих в целом из 4608 (из 5120) ALU для целочисленных расчетов и расчетов с плавающей запятой (поддерживаются форматы INT4, INT8, INT16, FP16, FP32 и FP64) |
| Блоки трассировки лучей | 72 (из 80) блока Ray Accelerator для расчета пересечения лучей с треугольниками и ограничивающими объемами BVH |
| Блоки текстурирования | 288 (из 320) блоков текстурной адресации и фильтрации с поддержкой FP16/FP32-компонент и поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растровых операций (ROP) | 16 широких блоков ROP на 128 пикселей с поддержкой различных режимов сглаживания, в том числе программируемых и при FP16/FP32-форматах буфера кадра |
| Поддержка мониторов | поддержка до шести мониторов, подключенных по интерфейсам HDMI 2.1 и DisplayPort 1.4a |
| Спецификации референсной видеокарты Radeon RX 6800 XT | |
|---|---|
| Частота ядра (игровая/пиковая) | 2015/2250 МГц |
| Количество универсальных процессоров | 4608 |
| Количество текстурных блоков | 288 |
| Количество блоков блендинга | 128 |
| Эффективная частота памяти | 16 ГГц |
| Тип памяти | GDDR6 |
| Шина памяти | 256-бит |
| Объем памяти | 16 ГБ |
| Пропускная способность памяти | 512 ГБ/с |
| Вычислительная производительность (FP16) | до 41,5 терафлопс |
| Вычислительная производительность (FP32) | до 20,7 терафлопс |
| Теоретическая максимальная скорость закраски | 288 гигапикселей/с |
| Теоретическая скорость выборки текстур | 648 гигатекселей/с |
| Шина | PCI Express 4.0 |
| Разъемы | один HDMI 2.1, два DisplayPort 1.4a и один USB Type C |
| Энергопотребление | до 300 Вт |
| Дополнительное питание | два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2,5 |
| Рекомендуемая цена | $649 (59 990 рублей) |
Наименование новой модели видеокарты соответствует принятому ранее принципу наименования решений компании — это следующее поколение после Radeon RX 5000, поэтому поменялась первая цифра, и это более высокий уровень производительности, поэтому вторая цифра — 8. Конкретно у модели RX 6800 XT есть как младшая сестра на том же чипе — RX 6800, так и старшая RX 6900 XT на полной версии Big Navi, которая заодно станет и топовой видеокартой AMD, когда выйдет 8 декабря.
Рекомендованная цена для Radeon RX 6800 XT составляет $649, а ценовая рекомендация для российского рынка — 59 990 рублей, что кажется выгодным предложением, но… судя по всему, новинку не минуют проблемы с дефицитом, как из-за повышенного интереса покупателей, так и не слишком больших поставок в розницу. Так что вполне вероятно, что доступность и у Radeon RX 6800 XT будет низкой, а цены останутся высокими как минимум еще какое-то время. Как и у конкурирующей GeForce RTX 3080, впрочем.
К слову о конкуренции. Именно RTX 3080 и представляется прямым конкурентом для новинки, хотя и имеет на несколько тысяч рублей большую цену. Но речь идет о рекомендованных производителями ценах, а что происходит на рынке в реальности, вы и сами наверняка знаете. RTX 3080 если и находятся в продаже, то заметно дороже рекомендованной цены. А RX 6800 XT в продаже пока что и вовсе не замечена. Но мы будем считать их прямыми ценовыми конкурентами, учитывая потенциально чуть более низкую цену видеокарты AMD.
Есть довольно важная разница между Radeon RX 6800 XT и конкурирующей GeForce RTX 3080 — объем видеопамяти. У видеокарты AMD ее 16 ГБ, а у Nvidia только 10 ГБ, что может быть потенциальным недостатком, если рассчитывать на несколько лет вперед. Пока что игры даже в 4K-разрешении при максимальных настройках и с трассировкой лучей не требуют большего объема памяти. Они могут занимать его, но ускорения при увеличении объема от 8–10 до 16 ГБ обычно не наблюдается. Правда, уже вышли консоли нового поколения с большим объемом памяти и быстрыми SSD, и в будущем некоторые мультиплатформенные или портированные с консолей игры могут начать требовать большего, чем 10 ГБ локальной видеопамяти, и по этому параметру новые видеокарты AMD явно имеют некий запас прочности.
Референсный дизайн карты RX 6800 XT выгодно отличается от карт предыдущих поколений, длина печатной платы составляет стандартные 267 мм и карта занимает два с половиной слота в корпусе. Предлагается весьма эффективная система охлаждения с большим радиатором и тремя большими вентиляторами. Новый кулер тише на 6 дБА, по сравнению с решением в Radeon RX 5700 XT. Общее потребление энергии платой ограничено значением в 300 Вт, а для подведения питания используются два стандартных 8-контактных разъема питания, в отличие от конкурента, который представил разъем собственного стандарта.

Стоит добавить немного слов и о нововведениях, связанных с разгоном. В настройках драйвера Radeon Software Adrenalin 2020 Edition есть три профиля работы видеокарты: Quiet, Balanced и Rage — тихий, сбалансированный и авторазгон соответственно. Эти профили автоматически меняют уровни питания и работы вентиляторов для достижения более тихой или быстрой работы GPU. Режим Rage доступен для RX 6800 XT и RX 6900 XT, но не для RX 6800.
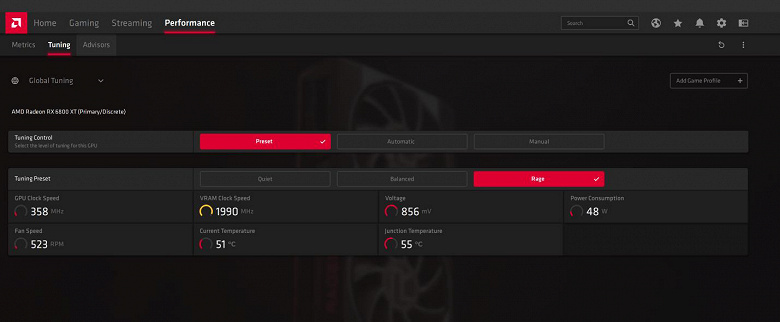
Сбалансированный режим используется по умолчанию, а тихий вариант снижает энергопотребление и шум от кулеров (на 6%-9%) при незначительном ухудшении производительности (всего на 1%-2%). Режим разгона Rage повышает лимиты потребления и частоту вращения кулеров, чтобы получить небольшой прирост в скорости — также порядка пары процентов. Ничего особенно это не изменит, но в условиях близости показателей производительности с конкурирующими решениями каждый процент прироста FPS на счету.
Частотные характеристики Radeon RX 6800 XT в соответствующих режимах меняются от менее чем 2000 МГц до 2310 МГц, и разница по возможным частотам достигает 6%, хотя общая производительность чаще всего упирается в потребление, температуру GPU и другие показатели, а достичь подобной рабочей частоты не так уж просто, и графический процессор чаще всего работает на меньшей частоте.
Архитектурные особенности
При производстве графического процессора Big Navi используется уже известный нам техпроцесс 7 нм компании TSMC, который мы знаем по предыдущим решениям AMD. Чип содержит 26,8 миллиарда транзисторов и имеет площадь 519,8 мм² — сравните это с GA102 у Nvidia, для производства которого применяется техпроцесс 8 нм Samsung и который имеет 28,3 млрд транзисторов при площади в 628,4 мм² (все данные о сложности и площади — официальные числа AMD и Nvidia).

То есть при близкой сложности этих GPU техпроцесс TSMC явно выглядит получше по плотности размещения транзисторов, чем 8-нанометровый вариант Samsung, хотя разница между ними оказалась меньше ранее предполагавшейся — ведь техпроцесс Samsung является производным от более старого техпроцесса 10 нм и должен бы отставать сильнее. Тем более, что GA100, производимый на TSMC, получился еще более плотным, чем Big Navi.
Но для производительности важнее то, что по возможности достижения максимальных частот и энергопотреблению 7 нм TSMC также должен быть лучше, и тут явное преимущество у AMD. Другое дело — доступность, выход годных кристаллов, а значит и себестоимость. Для производства таких немаленьких чипов наверняка дешевле обходится продукция завода Samsung, не зря же Nvidia выбрала его для массовой продукции, хотя их большой вычислительный чип GA100 также использует производственные мощности TSMC.
Графический процессор Navi 21 (Big Navi) основан на архитектуре RDNA второго поколения (далее — RDNA 2), основной задачей при разработке которой было достижение максимально возможной энергоэффективности и внедрение всех необходимых функциональных возможностей. Базовые блоки чипа — все те же вычислительные блоки Compute Unit (CU), из которых собраны все графические процессоры AMD последних лет. Каждый CU имеет выделенное локальное хранилище данных для обмена данными или расширения локального регистрового стека, а также кэш-память и полноценный текстурный конвейер с блоками выборки и фильтрации. Каждый из таких блоков самостоятельно занимается планированием и распределением работы.
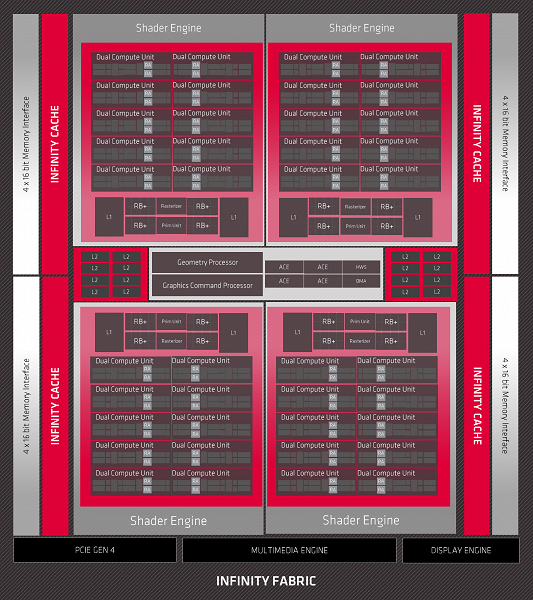
Как видите, архитектура RDNA 2 очень похожа на RDNA 1, хотя она и была серьезно переделана и обновлена. Полная версия Navi 21 содержит 80 вычислительных блоков CU (ровно вдвое больше, чем у Navi 10), которые состоят из 5120 блоков ALU, 320 блоков TMU, 128 блоков ROP и четырех асинхронных вычислительных движков. В версии Radeon RX 6800 XT их чуть меньше — отключены 8 блоков CU, поэтому осталось 4608 ALU и 288 TMU, а вот по ROP урезаний нет.
В общем, новый графический процессор Big Navi выглядит как удвоенный практически по всем блокам чип Navi 10, известный нам по Radeon RX 5700 (XT), так что подробности об особенностях вычислительных блоков RDNA (и 1 и 2) вы можете прочитать в соответствующем обзоре, а сегодня мы будем говорить об отличиях, вроде новых блоков для поддержки трассировки лучей и прочего.
Итак, важнейшей задачей компании, кроме добавления функциональности DX12 Ultimate, стало повышение энергоэффективности RDNA 2. Ведь если Radeon RX 5700 XT уже потребляет до 225 Вт, то вдвое более жирный GPU явно не впихнуть в рамки 300—350 Вт. Для улучшения энергоэффективности специалисты AMD переделали все блоки, перебалансировали конвейер, нашли и устранили все узкие места, переделали линии передачи данных, обработку геометрии внутри чипа, а также использовали опыт проектирования CPU с высокой рабочей частотой и в результате всей этой кропотливой работы получили действительно потрясающие результаты.
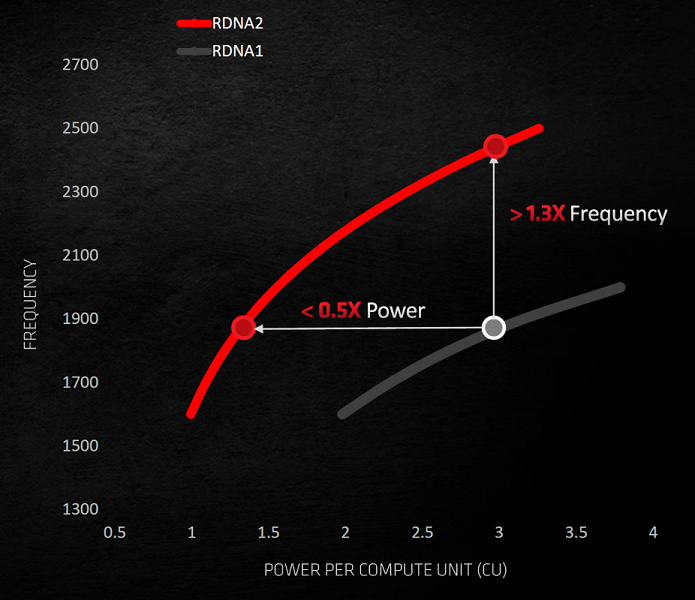
Новинка AMD до двух раз быстрее Radeon RX 5700 XT в 4K-разрешении, имеет на 30% бо́льшую тактовую частоту при том же потреблении энергии на каждый блок CU, что дает нам даже более чем обещанные +50% улучшения энергоэффективности — реальный прирост в определенных условиях составил, по оценке компании, 54%, что весьма неплохо и даже немного неожиданно после не слишком то энергоэффективной RDNA 1. Мы далее проверим эти данные, но за физическую реализацию GPU уже в любом случае можно похвалить AMD — проведена отличная работа!
Что касается более высокого уровня, то в вычислительных блоках RDNA 2 явно просматриваются корни предыдущей версии архитектуры, и улучшены они были скорее в смысле физической реализации, чем логической, которая слабо изменилась с первой версии RDNA. Хотя новые функциональные блоки для ускорения трассировки лучей и новый уровень кэша Infinity Cache также стали довольно важными изменениями.
О новом кэше и реализации блоков трассировки мы еще поговорим ниже, а из других отмеченных нами изменений — переделка блоков ROP. Каждый укрупненный блок ROP теперь обрабатывает по восемь 32-битных пикселей за такт, что вдвое больше того, что было раньше — вполне возможно, что это потребовалось из-за увеличения эффективной пропускной способности из-за большого кэша Infinity Cache. Добавили также и возможность использования переменной частоты затенения VRS, что стало дополнительной причиной переделки ROP, по всей вероятности.
Поддержка аппаратной трассировки лучей
Для аппаратного ускорения трассировки лучей, которая уже получила поддержку в играх, в RDNA 2 пришлось внедрять специализированные блоки Ray Accelerator. Хотя трассировку можно делать и полностью в шейдерах, но это очень сложная задача и без очень быстрой аппаратной обработки хотя бы части вычислений, общая скорость будет слишком низкой. На аппаратные блоки можно перенести хоть всю работу по трассировке лучей, но это будет дорого с точки зрения расходуемой площади чипа, и не всегда эффективно. Чаще всего лишь часть работы при трассировке лучей отдается специализированным блокам, но объем этой работы может быть разным в каждой конкретной реализации.
В случае RDNA 2 аппаратные ускорители трассировки занимаются поиском пересечений лучей и геометрии, и каждый из этих блоков способен за такт вычислить до четырех пересечений луча и ограничивающих объемов или одно пересечение луча и треугольника. Эти блоки достаточно эффективно вычисляют пересечения лучей и геометрии сцены, представленной в виде ускоряющих структур Bounding Volume Hierarchy, о которых мы вам неоднократно рассказывали в обзорах видеокарт GeForce RTX, и возвращают информацию шейдерам для дальнейшего обхода сцены или шейдинга.
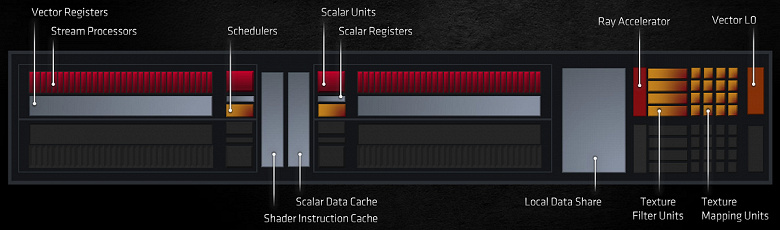
Такой подход позволяет ускорить обработку пересечений лучей и геометрии в разы (AMD заявляет о более чем 10-кратной разнице), по сравнению с полностью программным методом, но это уступает решению Nvidia, в котором несколько бо́льшая часть работы делается в специализированных MIMD-блоках, а не обычными шейдерными SIMD, как в случае Radeon. То есть Ray Accelerators в RDNA 2 хоть и аппаратно выделенные блоки, но они несколько проще RT-ядер в графических процессорах семейств Ampere и Turing у конкурента. Зато такие упрощенные блоки занимают меньше места в GPU, хотя и должны несколько медленнее справляться с работой, особенно в случае большого количества некогерентных лучей. Ведь отдельные MIMD-ядра для трассировки подходят для этого куда лучше.
Трассировка лучей работает на RDNA 2, используя шейдерные SIMD-ядра, и хотя это не блокирует параллельное исполнение других вычислений, но свободных мощностей под операции затенения пикселей и другие задачи остается меньше. Та же трассировка лучей пока что использует малое количество лучей на пиксель и поэтому требует активного шумоподавления, а такие постфильтры весьма ресурсоемки и требуют немалых вычислительных мощностей.
Если подводить некий теоретический итог, то можно сказать, что RT-ядра у Nvidia сложнее и универсальнее (не требуют предварительной сортировки лучей для эффективной обработки, например), а у AMD они выполнены практичнее на сегодняшний день, так как занимают в GPU меньше места, что особенно важно с учетом ограниченности применения трассировки лучей на консолях и в будущих мультиплатформенных играх. Также, в AMD наверняка будут проводить работу с разработчиками игр для оптимизации трассировки под их решения, и хорошо бы это не вылилось в упрощение эффектов, в которых применяется трассировка.
К слову, большой кэш Infinity Cache способен вместить большую часть ускоряющей структуры BVH, что в теории должно позволить выполнять сложную трассировку более эффективно, с меньшими задержками при получении данных. Даже несмотря на то, что в играх BVH-структуры занимают от полугигабайта до нескольких гигабайт видеопамяти, не обязательно весь BVH помещать в кэш, и даже если ускорить доступ лишь к наиболее часто требуемым данным этой ускоряющей структуры, то быстрый кэш все равно должен помогать.
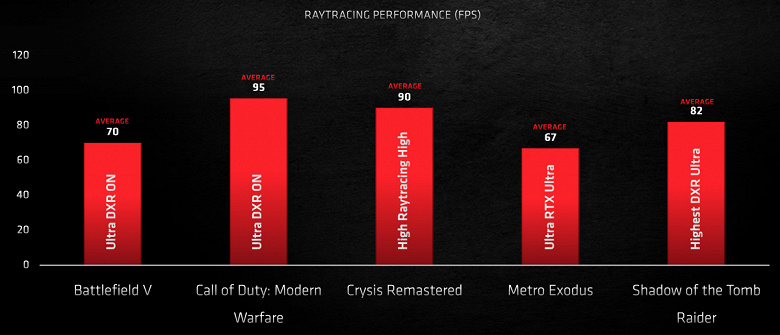
Мы проверим все это далее в синтетических и игровых тестах, а пока что посмотрите на данные самой AMD для рассматриваемой сегодня модели Radeon RX 6800 XT в нескольких играх с эффектами, выполненными с трассировкой лучей при разрешении рендеринга в 2560×1440 пикселей. Судя по этим результатам, получается, что Radeon RX 6800 XT вполне справляется с обеспечением комфортной игры при средней частоте кадров более 60 FPS при гибридном рендеринге. При этом настройки качества выбраны максимальные, хотя в представленных играх трассировка используется для одного из эффектов, а не сразу нескольких. То есть в других проектах мощи Big Navi может и не хватить.
Полная поддержка DirectX 12 Ultimate
Продолжая тему новых возможностей, отметим, что в Radeon RX 6000 появилась полная поддержка DirectX 12 Ultimate — нового стандарта качественной графики для ПК и консолей нового поколения, включающей уже упомянутую трассировку лучей через DirectX Raytracing, увеличение производительности при помощи переменной частоты затенения Variable Rate Shading, более эффективной поддержки стриминга текстур при помощи Sampler Feedback, а также возможности создания более детализированных игровых миров с новым геометрическим конвейером Mesh Shaders. Также ожидается поддержка и DirectStorage API для быстрого и прямого доступа GPU к данным на накопителях, но это будет позже.

Так уж получилось, что обо всех новых возможностях DirectX 12 Ultimate мы уже подробно рассказывали ранее в своих статьях о решениях Nvidia, и не видим смысла повторяться — кто заинтересуется, тот легко найдет наши объяснения того, как все это работает. Но вкратце все же расскажем. Например, еще одной интересной технологией, поддержку которой получила архитектура RDNA 2, стала переменная частота затенения Variable Rate Shading, которая уже поддерживается конкурирующими решениями с поколения Turing.
Эта возможность позволяет использовать отличающееся качество затенения для разных фрагментов изображения — там, где изображение не обязательно должно быть четким (например, применяется motion blur или эффект глубины резкости) вполне можно снизить качество расчетов шейдинга без видимых потерь, и наоборот — в важных местах оставить нормальное затенение с максимальным качеством и четкостью.

VRS в варианте AMD предполагает возможность выбора переменных частот затенения: 1×1, 2×1 и 1×2, а также 2×2 — отдельно для каждого из блоков 8×8 пикселей. Это позволяет достаточно подробно определить, какие участки кадра будут отрисовываться с меньшим качеством и большей производительностью. То есть затенение указанных участков производится с вдвое или вчетверо сниженным качеством, но повышенной скоростью. Проще всего визуализировать работу этого алгоритма на примере гоночных игр с эффектом motion blur на периферии кадра, но VRS можно использовать и иначе:

Красным на скриншоте показаны фрагменты с полным затенением, желтым — с половинным, а зеленым — с вчетверо меньшим качеством. Эта возможность уже используется в некоторых играх, включая совсем свежий проект Dirt 5, и это позволяет повысить производительность при шейдинге в теории до четырех раз для каждого из блоков 8×8 пикселей, но в целом для игрового кадра это будет несколько процентов снижения времени рендеринга кадра, и все это при незаметной для глаза потере в качестве.
Раз уж мы заговорили об аппаратно-программных особенностях, появившихся в RDNA 2, то отметим и пакет технологий с открытым кодом AMD FidelityFX, входящий в инициативу GPUOpen. Он помогает разработчикам игр внедрять хорошо оптимизированные эффекты в игры, для обеспечения отличного баланса качества и производительности. Первым таким эффектом стал фильтр улучшения четкости Contrast Adaptive Sharpening (CAS), полезный для игр, использующих сглаживание методом TAA, теряющим детали, а в текущем году были добавлены в пакет еще четыре эффекта: Ambient Occlusion, Screen Space Reflections, HDR Mapper и Downsampler (для ускорения генерации мип-уровней текстур шейдерами).

На видеокартах серии Radeon RX 6000 для расчета некоторых из них может применяться и трассировка лучей, а в качестве запасной опции всегда можно применить отражения в экранном пространстве или привычный расчет Ambient Occlusion, работающий также в экранном пространстве. С появлением на рынке решений нового семейства, добавляются еще два новых эффекта: Variable Shading и Denoiser, они используют новые возможности архитектуры RDNA 2 и помогают оптимизировать производительность и качество картинки.
Эти эффекты уже добавлены в такие игры, как Dirt 5 и The Riftbreaker, и скоро появятся на GPUOpen. Про Variable Shading мы уже писали, а шумоподавление при помощи Denoiser очень важно для гибридного рендеринга с трассировкой лучей, так как из-за большой ресурсоемкости используется малое количество лучей на пиксель, что вызывает очень шумную картинку, которую нужно серьезно улучшать.
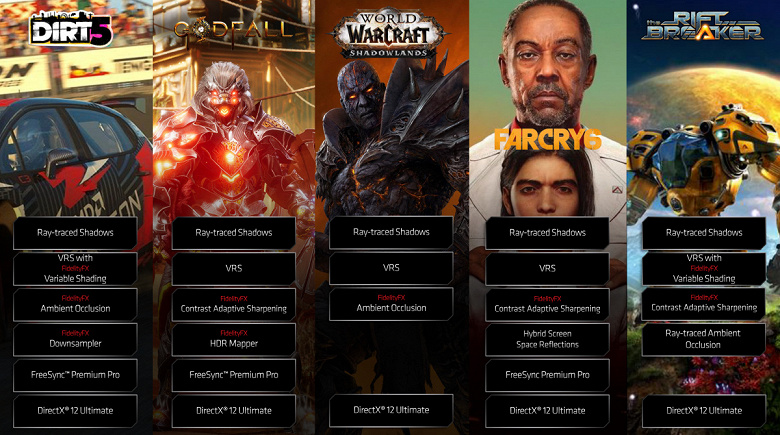
Эффекты AMD FidelityFX уже используются в 35 играх, а самые новые или появились или вот-вот появятся в выходящих проектах, включая трассировку лучей и VRS в пяти играх. Также в будущем планируется добавить FidelityFX Super Resolution — вероятно, некий аналог Nvidia DLSS, особых подробностей о реализации которого пока что мало что известно. Технология важна уже потому, что многие игры последних лет в любом случае используют тот или иной метод повышения производительности в высоких разрешениях, включая временную реконструкцию, шахматный рендеринг, динамическое изменение разрешение рендеринга и т. д. Иногда это вызывает визуальные артефакты и точно увеличивает сложность внедрения подобных алгоритмов.
Для решения таких проблем и разрабатывается технология Super Resolution, которая точно будет использовать информацию из нескольких предыдущих кадров, аналогично DLSS, но как именно затем будет перестраиваться изображение в более высоком разрешении — мы пока что не знаем. Возможно, AMD применит открытый стандарт DirectML для работы умной нейросети, но им будет непросто обеспечить требуемую производительность без выделенных ядер, исполняющих тензорные вычисления, как у Nvidia. Ведь если на универсальные SIMD-ядра будут покушаться традиционные задачи растеризации и вычислений, к ним прибавятся вычисления, связанные с трассировкой лучей и повышением разрешения Super Resolution, то этих самых ресурсов может и не хватить.
Новая подсистема кэширования — Infinity Cache
Пожалуй, самой интересной особенностью семейства Radeon RX 6000 стал абсолютно новый уровень кэша, находящийся перед видеопамятью, позволяющий обеспечить быстрый доступ к данным и увеличивающий эффективную пропускную способность. В остальном все более-менее так же, как и у других GPU, L0-кэш расположен в каждом блоке CU, L1-кэш размещен в каждом движке шейдинга Shader Engine, и имеет эксклюзивный доступ к L2-кэшу, общий объем составляет 1 МБ, а L2-кэш объемом в 4 МБ, который расположен между движками Shader Engine и командным процессором.
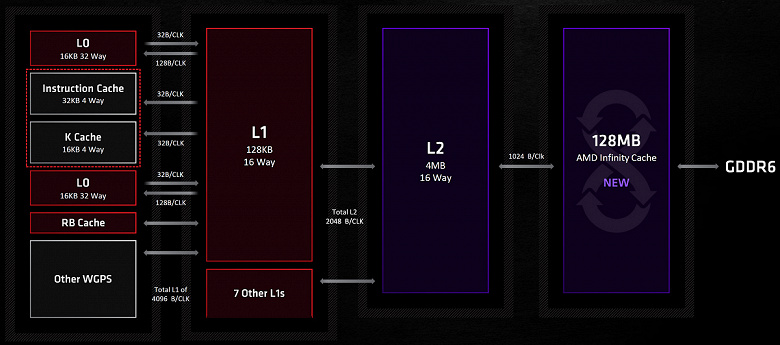
На схеме сразу же выделяется очень большой Infinity Cache объемом в 128 МБ, который присоединяется к четырем 64-битным контроллерам памяти. Это новый тип кэш-памяти, которого ранее не было в GPU. Давайте разберемся, зачем он нужен и почему появился именно сейчас. Инженеры AMD стояли перед задачей обеспечения высокой пропускной способности, ведь в графическом процессоре Big Navi было удвоено число потоковых вычислительных блоков CU при увеличенной на треть частоте, по сравнению с Radeon RX 5700 XT, а пропускную способность видеопамяти так сильно повысить непросто.
Как прокормить все эти блоки данными? Нужно или расширять шину памяти до 512-битной или хотя бы 384-битной шины с одновременным увеличением частоты работы памяти. Но возможности GDDR6 почти полностью исчерпаны, у AMD нет доступа к более производительному типу памяти GDDR6X, который был разработан Micron и Nvidia, как минимум пока что, а HBM2 слишком дорога и ее применение вряд ли будет оправдано с экономической точки зрения.
В целом, повысить ширину шины памяти было вполне возможно, но не так просто с учетом более тонкого техпроцесса и меньшей площади чипа, но самое главное — при этом был бы сильный рост потребления энергии, и добиться заявленного прироста в энергоэффективности у инженеров бы просто не получилось. Поэтому в AMD и решили сделать еще один уровень кэш-памяти — последний уровень, стоящий прямо перед видеопамятью.
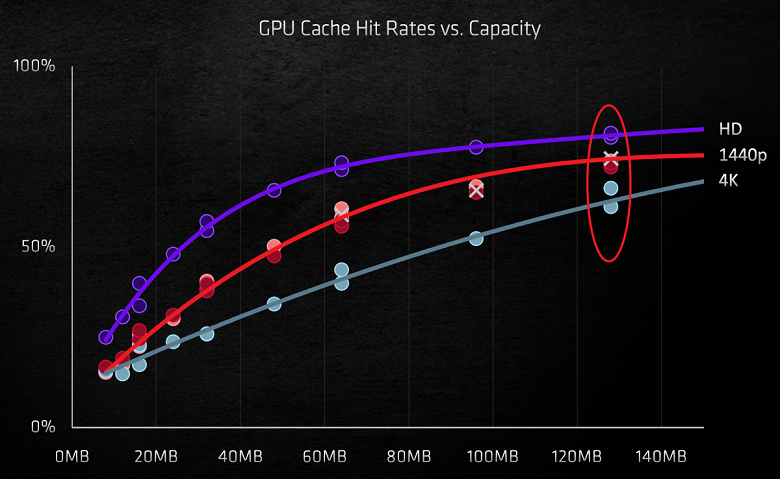
Кэширование решает вопрос пропускной способности, но это всегда компромисс, и обычно L2-кэши в GPU имеют небольшой объем в 2–4 МБ — в таком случае будет много промахов при доступе к данным, большинство их придется доставать из медленной видеопамяти, и только увеличение кэша до 64 МБ и более способно помочь в деле достаточного повышения эффективной ПСП. Но внедрение статической памяти такого объема обойдется слишком дорого в смысле занимаемой типичной кэш-памятью площади на кристалле.
Помогло то, что у AMD уже есть опыт по размещению большого объема статической памяти в серверных процессорах EPYC, в которых 32 МБ L3-кэша упакованы в 27 мм² —, а это вчетверо больший объем на единицу площади, по сравнению с типичным кэшем второго уровня в GPU. Соответственно, AMD использовали разработки другого подразделения и разместили в Big Navi оптимизированный для нужд GPU кэш объемом аж в 128 МБ.
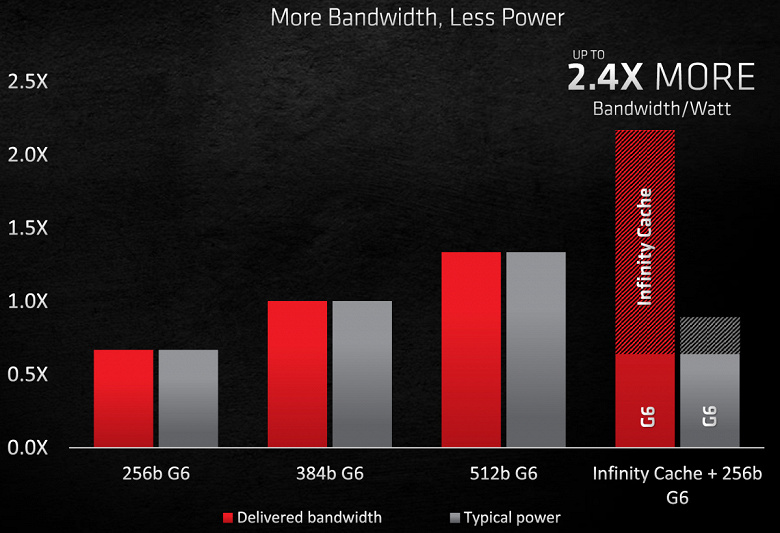
Передача данных происходит по 16 каналам шириной 64-бит (всего 1024-бит) на частоте до 1,94 ГГц, что дает почти вчетверо большую ПСП, чем у типичной GDDR6, присоединенной по 256-битной шине. В результате получили более чем вдвое большую эффективную ПСП, по сравнению с 384-битной шиной, и при этом улучшили энергоэффективность, ведь доступ к кэш-памяти требует в 5–6 меньших затрат энергии. В общем, по оценкам AMD получилась более чем вдвое лучшая энергоэффективность для 4К-разрешения в типичных играх, по сравнению с обычной 384-битной шиной.
Подобная подсистема памяти потребляет где-то на 10% меньше энергии при более чем вдвое большей эффективной ПСП. Внедрение подобного быстрого и объемного кэша не только позволило решить проблемы с ПСП, но и привело к раскрытию потенциала высокопроизводительных GPU — с ростом частоты работы графического процессора толк от Infinity Cache лишь увеличивается. Большинство необходимых данных при рендеринге достается из кэша, имеющего более высокую ПСП, что обеспечивает в среднем на треть меньшие задержки, по сравнению с доступом к GDDR6.
Также интересно то, что частота Infinity Cache изменяется в зависимости от потребности приложения в каждый момент времени. Когда оно требовательно к ПСП, частота работы кэша может расти, аналогично частоте GPU. В общем, подобная инновационная подсистема памяти приводит как к повышению пропускной способности и снижению задержек, так и одновременному снижению потребления энергии, что весьма важно для мощных GPU.
Внедрение Infinity Cache полезно для эффектов, требующих высокой частоты заполнения, вроде объемного освещения — вполне возможно, что таких эффектов в играх будущего станет больше, по крайней мере в играх с поддержкой AMD. Но сразу же возникает вопрос —, а можно ли управлять этим большим кэшем? Например, жестко закрепить какие-то данные в определенном его участке, чтобы доступ к ним всегда был быстрым. AMD пока что подобных возможностей открывать не планирует, хотя видеодрайвер, конечно же, может управлять кэшем в целях оптимизации.
Для разработчиков приложений же этот кэш полностью прозрачный и автоматический, а управление им возможно разве что как в CPU — при помощи префетчей и т. д., что дает меньше контроля, но более универсальное. Ведь существуют GPU вообще без кэша, вышли с 128 МБ, а в будущем может появятся и с другим объемом — писать для всех отдельный код не кажется правильным решением, это же не консоли с фиксированной конфигурацией. Но AMD не отвергает возможности появления некоего контроля над кэшем для разработчиков ПО в будущем.
Начало ли это внедрения кэш-памяти последнего уровня во многие GPU, или просто костыль для нивелирования меньшей ПСП при 256-битной шине и GDDR6-памяти? Пойдет ли индустрия в эту сторону, будет ли Infinity Cache развиваться самой AMD, появится ли аналог в будущих решениях Nvidia? И что было бы лучше, потратить большую площадь GPU на подобный кэш или на большее количество функциональных блоков разного назначения (например, более сложные RT-ядра или тензорные ядра) и более производительную память? Увы, ответы на все эти вопросы мы пока не знаем. Любой кэш — это компромисс, всегда ведь лучше иметь доступ максимально быстрый и с минимальными задержками сразу ко всем данным. Но это невозможно, поэтому и приходится делать кэши из нескольких уровней. CPU прошли по этому пути, идут и GPU.
Smart Access Memory — улучшенный доступ к памяти
Еще одной из интересных новых возможностей стала технология Smart Access Memory — она позволяет системе получить полный доступ к видеопамяти по шине PCI Express. Ранее давался доступ лишь к куску 256 МБ видеопамяти, чего явно недостаточно для современных условий, а SAM позволяет расширить этот кусок до полного объема видеопамяти Radeon RX 6000 — до 16 ГБ. В некоторых играх это дает очень приличный прирост производительности, но в среднем это примерно 3%-5%.
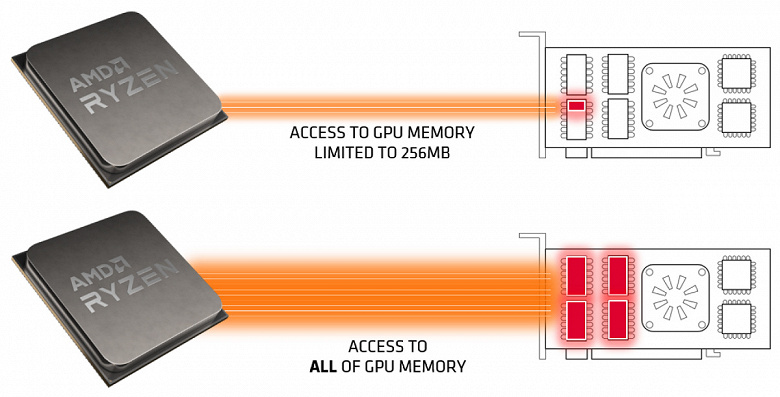
Возможность изменения объема видеопамяти, к которой получает доступ система, существует в стандарте PCI Express уже давно. Она называется «Resizable BAR» (изменяемый Base Address Register) и доступна в драйверной модели WDDM 2 много лет, так что не очень понятно, почему AMD решили вытащить ее именно сейчас и так жестко ограничить возможность ее включения исключительно своей платформой, предоставив ее только редким владельцам процессоров Zen 3.
AMD говорит, что хотя Resizable BAR действительно доступна для широкого круга решений, но на данный момент они сосредоточились на оптимизации и проверке работы их собственного программного и аппаратного обеспечения из конкретного списка — только видеокарты Radeon RX 6000, процессоры серии Ryzen 5000 и чипсе
Полный текст статьи читайте на iXBT
