Справочная информация о семействе видеокарт AMD Radeon R7 и R9
Справочная информация о семействе видеокарт Radeon X
Справочная информация о семействе видеокарт Radeon X1000
Справочная информация о семействе видеокарт Radeon HD 2000
Справочная информация о семействе видеокарт Radeon HD 4000
Справочная информация о семействе видеокарт Radeon HD 5000
Справочная информация о семействе видеокарт Radeon HD 6000
Справочная информация о семействе видеокарт Radeon HD 7000
Справочная информация о семействе видеокарт Radeon 200
Справочная информация о семействе видеокарт Radeon 300
Спецификации графических процессоров
| кодовое имя | «Fiji» | «Grenada» «Hawaii» |
«Antigua» «Tonga» |
«Trinidad» «Curacao» «Pitcairn» |
«Tobago» «Bonaire» |
| базовая статья | здесь | здесь | здесь | здесь | здесь |
| технология (нм) | 28 | ||||
| транзисторов (млрд) | 8,9 | 6,2 | 5,0 | 2,8 | 2,1 |
| универсальных процессоров | 4096 | 2816 | 2048 | 1280 | 896 |
| текстурных блоков | 256 | 176 | 128 | 80 | 56 |
| блоков блендинга | 64 | 32 | 16 | ||
| шина памяти | 4096 | 512 | 384 | 256 | 128 |
| типы памяти | HBM | DDR3 GDDR5 |
|||
| системная шина | PCI Express 3.0 | ||||
| интерфейсы | DVI Dual-Link HDMI DisplayPort |
||||
| вершинные шейдеры | 5.0 | ||||
| пиксельные шейдеры | 5.0 | ||||
| точность вычислений | FP32/FP64 | ||||
| Сглаживание | MSAA CFAA SSAA EQAA MLAA |
Спецификации референсных карт семейства Radeon 300
| карта | чип | блоков ALU/TMU/ROP | частота ядра, МГц | частота памяти, МГц | объем памяти, ГБ | ПСП, ГБ/c (бит) |
текстури- рование, Гтекс |
филлрейт, Гпикс | TDP, Вт |
| Radeon R9 Fury X | «Fiji» | 4096/256/64 | 1050 | 1000 | 4 HBM | 512 (4096) | 269 | 67 | 275 |
| Radeon R9 Fury | «Fiji» | 3584/224/64 | 1000 | 1000 | 4 HBM | 512 (4096) | 224 | 64 | 275 |
| Radeon R9 Nano | «Fiji» | 4096/256/64 | до 1000 | 1000 | 4 HBM | 512 (4096) | 256 | 64 | 175 |
| Radeon R9 390X | «Hawaii» | 2816/176/64 | 1050 | 1500(6000) | 8 GDDR5 | 384 (512) | 185 | 67 | 275 |
| Radeon R9 390 | «Hawaii» | 2560/160/64 | 1000 | 1500(6000) | 8 GDDR5 | 384 (512) | 160 | 64 | 275 |
| Radeon R9 380X | «Tonga» | 2048/128/32 | 970 | 1425(5700) | 4 GDDR5 | 182 (256) | 124,2 | 31,0 | 190 |
| Radeon R9 380 | «Tonga» | 1792/112/32 | 970 | 1425(5700) | 2–4 GDDR5 | 182 (256) | 108,6 | 31,0 | 190 |
| Radeon R7 370 | «Pitcairn» | 1024/64/32 | 975 | 1400(5600) | 2–4 GDDR5 | 179 (256) | 62,4 | 31,2 | 110 |
| Radeon R7 360 | «Bonaire» | 768/48/16 | 1050 | 1625(6500) | 2 GDDR5 | 104 (128) | 50,4 | 16,8 | 100 |
Графический ускоритель AMD Radeon R9 Fury X
| Кодовое имя | «Fiji» |
| Технология производства | 28 нм |
| Количество транзисторов | 8,9 млрд. |
| Архитектура | Унифицированная, с массивом общих процессоров для потоковой обработки многочисленных видов данных: вершин, пикселей и др. |
| Аппаратная поддержка DirectX | Уровень возможностей Feature Level 12_0 и шейдерной модели Shader Model 5.0 |
| Шина памяти | 4096-битная: восемь контроллеров памяти с поддержкой стандарта High Bandwidth Memory |
| Частота графического процессора, МГц | 1050 |
| Вычислительные блоки | 64 вычислительных блока GCN, включающих 256 SIMD-ядер, состоящих в общем из 4096 ALU для расчетов с плавающей запятой (поддерживаются целочисленные и плавающие форматы, с точностью FP32 и FP64) |
| Блоки текстурирования | 256 текстурных блоков, с поддержкой трилинейной и анизотропной фильтрации для всех текстурных форматов |
| Блоки растеризации (ROP) | 64 блока ROP с поддержкой режимов сглаживания с возможностью программируемой выборки более чем 16 сэмплов на пиксель, в том числе при FP16- или FP32-формате буфера кадра. Пиковая производительность до 64 отсчетов за такт, а в режиме без цвета (Z only) — 256 отсчетов за такт |
| Поддержка мониторов | Интегрированная поддержка до шести мониторов, подключенных по интерфейсам DVI, HDMI и DisplayPort |
| Спецификации видеокарты Radeon R9 Fury X | |
|---|---|
| Частота ядра, МГц | 1050 |
| Количество универсальных процессоров | 4096 |
| Количество текстурных блоков | 256 |
| Количество блоков блендинга | 64 |
| Эффективная частота памяти, МГц | 1000 (2×500) |
| Тип памяти | HBM 4096-бит |
| Объем памяти, ГБ | 4 |
| Пропускная способность памяти, ГБ/с | 512 |
| Вычислительная производительность (FP32), Терафлопс | 8,6 |
| Теоретическая максимальная скорость закраски, Гигапикселей/с | 67,2 |
| Теоретическая скорость выборки текстур, Гигатекселей/с | 268,8 |
| Шина | PCI Express 3.0 |
| Разъемы | один HDMI 1.4a и три DisplayPort 1.2a |
| Типичное энергопотребление, Вт | 275 |
| Дополнительное питание | Два 8-контактных разъема |
| Число слотов, занимаемых в системном корпусе | 2 |
| Рекомендуемая цена | для рынка США — $649 |
Этой моделью компания AMD открыла новое подсемейство элитных видеокарт Fury, номинально входящих в линейку Radeon 300. Топовое решение подсемейства получило наименование Fury X — суффикс «X» указывает на экстремальное (в данном случае — одночиповое) решение. Выбор имени Fury компания не пыталась как-то обосновать. Вероятно, это имя взяли от успешных в свое время видеокарт семейства ATI Rage Fury, вышедших в конце 1990-х годов. Кроме того, Фурии — это богини мести в древнеримской мифологии, а Титаны — боги из древнегреческой мифологии.
Модель Radeon R9 Fury X заняла свое положение в самой верхней части продуктовой линейки компании, а установленная рекомендованная цена Radeon R9 Fury X равна $649 — ровно на уровне прямого конкурента в лице GeForce GTX 980 Ti от Nvidia, который был анонсирован в конце мая в виде превентивного удара по будущему (на тот момент) решению AMD. Конкурирующее решение предложило производительность, близкую к той, что имеет элитная модель GeForce GTX Titan X, за куда меньшие деньги, и Fury X теперь приходится соперничать именно с игровой GTX 980 Ti.
Один из самых спорных моментов в характеристиках новой модели — наличие лишь 4 ГБ видеопамяти, чего пока что хватает даже для высоких разрешений при максимальных настройках качества, но в ряде современных игр при 4K-разрешении рендеринга, а также включении полноэкранного сглаживания и высоких настройках качества, уже сейчас требуется еще больший объем. И AMD была бы рада предложить вариант с 8 ГБ, но увы — первое поколение HBM-памяти просто не позволяет сделать его. Подробнее обо всех тонкостях, связанных с HBM-памятью, читайте ниже.
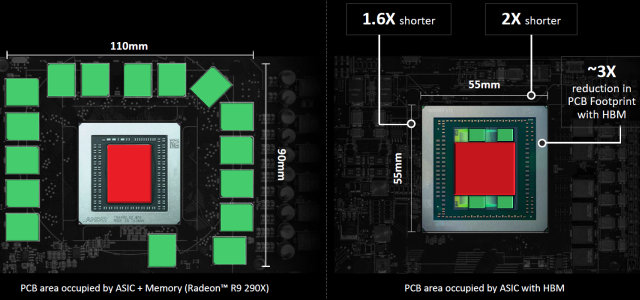
Сама по себе видеокарта очень компактна по размерам — длина печатной платы Radeon R9 Fury X равна всего лишь 7.5 дюймов (около 190 мм), что значительно меньше типичных референсных карт верхнего ценового диапазона. Небольшая плата сочетается с большим радиатором системы водяного охлаждения. Сочетание СВО с HBM-памятью позволило уменьшить физические размеры и число компонентов на плате (в схеме питания, в частности). Можно сравнить площади GPU и RAM на Radeon R9 290X и R9 Fury X:
В типичных игровых условиях видеокарта Radeon R9 Fury X потребляет около 275 Вт, но так как она оснащена парой 8-контактных разъемов питания PCI-E, то может получать от блока питания до 375 Вт, то есть, намного больше. С точки зрения интерфейсов ввода-вывода, Radeon R9 Fury X способен выводить информацию на шесть дисплеев (при использовании хаба DisplayPort 1.2 MST), подключенных по разъемам DVI (требуется переходник), HDMI 1.4a и DisplayPort 1.2a.
Среди разъемов на плате есть один видеовыход формата HDMI и три DisplayPort. От устаревшего разъема DVI решили избавиться совсем, хотя в Radeon HD 7970 и Radeon R9 290X они ещё были, а иногда и по два. И пользователям старых мониторов с DVI-интерфейсами теперь придется использовать переходники: пассивные, если достаточно Single Link, и более дорогие для Dual Link соединений.
Увы, но по причине отсутствия поддержки HDMI 2.0, новинка поддерживает вывод изображения в разрешении 4K при 60 Гц только по DisplayPort. Вероятно, со временем также появится возможность применения активных переходников с DisplayPort на HDMI 2.0, но пока что такие конфигурации не работают.
Архитектурные и функциональные особенности
Так как модель Radeon R9 Fury X основана на графическом процессоре Fiji, который принадлежит к давно известной архитектуре Graphics Core Next (GCN), то о многих деталях вы можете узнать из наших ранних материалов. Указанная архитектура лежит в основе всех современных решений компании AMD, и даже последние GPU отличаются лишь некоторыми модификациями в вычислительных способностях и дополнительными графическими возможностями, важными для поддержки DirectX 12.
Как и предыдущий топовый чип Hawaii, новый GPU не является первенцем полностью новой архитектуры, а лишь использует последнюю версию нынешней Graphics Core Next (ее можно назвать GCN 1.2 или GCN третьего поколения). В Fiji было сделано небольшое количество изменений по сравнению с тем же прошлогодним Tonga, и новинку вполне можно отнести к поколению GCN 1.2. Из базовых изменений, появившихся в Fiji, основанном на последней версии архитектуры Graphics Core Next, можно отметить все то, что мы уже видели в чипе Tonga, на котором базируется видеокарта модели Radeon R9 285.
Новый топовый графический процессор включает в себя все доработки GCN 1.2, в том числе улучшенную производительность обработки геометрии и тесселяции (по этим показателям Fiji на уровне с Hawaii и Tonga и быстрее чем Tahiti), новые методы сжатия данных без потерь в кадровом буфере, некоторые мультимедийные 16-битные инструкции, а также увеличенный объем кэш-памяти второго уровня до 2 МБ. С точки зрения вычислительных возможностей, новый GPU получил улучшенное планирование и распределение задач и несколько новых инструкций для параллельной обработки данных.
Наиболее «громким» архитектурным улучшением является появление значительно улучшенных алгоритмов сжатия данных кадрового буфера без потерь — для этого блоки ROP были специальным образом модифицированы. Именно операции (в основном записи) с кадровым буфером являются наиболее требовательными к пропускной способности памяти, ведь GPU записывает в буфер очень большое количество пикселей каждый кадр. Так что увеличение эффективности этой работы приводит к меньшей требовательности к ПСП и увеличивает так называемую эффективную ПСП.
В случае чипов архитектуры GCN 1.2, новые методы сжатия данных буфера кадров обеспечивают степень сжатия до 8:1, а в среднем это выливается в 40% улучшения по эффективности использования ПСП. Так, Radeon R9 285 с 256-битной шиной имеет схожую эффективную ПСП с Radeon R9 280, имеющим 384-битную шину памяти. Ну, а в случае топового чипа Fiji, эффективная ПСП выросла до сверхвысоких значений, так как чип содержит 4096-битную память стандарта HBM, но об этом — чуть позже.
Также в рамках архитектуры GCN 1.2 были сделаны некоторые изменения и в вычислительных блоках: улучшения планирования и распределения задач между исполнительными блоками в рамках гетерогенной архитектуры HSA, внедрение новых 16-битных инструкций, позволяющих повысить скорость и снизить энергопотребление, а также улучшения по параллельной обработке данных, что наиболее важно в случае топового графического процессора Fiji. Как и другие продукты архитектуры GCN 1.2, новый GPU имеет возможность ограниченного обмена данными между разными линиями SIMD, открывающую возможность для новых эффективных алгоритмов в OpenCL-программах.
Ну, а для простых энтузиастов самыми важными архитектурными изменениями стали уже упомянутое сжатие данных кадрового буфера и ускорение геометрической обработки и тесселяции. Это улучшение было сделано еще в Hawaii, ничего не изменилось и в Tonga. А вот теперь в случае Fiji работа геометрического конвейера была дополнительно оптимизирована, что должно положительно сказаться в задачах с большим количеством геометрии и с применением тесселяции.
Общая схема графического процессора Fiji весьма схожа с той, что мы видели еще в чипе Hawaii, вышедшем в далеком уже 2013 году. Оба этих GPU разделены на четыре шейдерных движка Shader Engine, каждый из которых имеет свой собственный процессор для обработки геометрических данных и растеризатор, а также по четыре укрупненных блока ROP, способных обработать по 16 пикселей за такт (всего получается 64 блока ROP в каждом из этих чипов). GPU имеет единый командный процессор и восемь движков асинхронных вычислений Asynchronous Compute Engine, которые были модифицированы с учетом изменений в GCN 1.2.
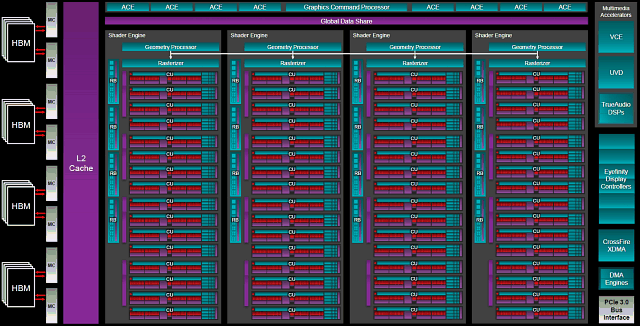
По сравнению с Hawaii, в плане организации инженеры компании AMD в чипе Fiji не тронули ничего, просто разместив большее количество вычислительных блоков Compute Unit в каждом движке Shader Engine (16 вместо 11), но оставили без изменений количество самих движков (вероятно, это — архитектурное ограничение GCN в ее нынешнем виде) и количество других исполнительных блоков в их составе.
С учетом того, что каждый CU содержит по 64 ALU, получается 1024 ALU на каждый Shader Engine и 4096 потоковых процессора на весь Fiji. Соответственно же было увеличено и количество текстурных блоков, ведь на каждый CU в видеочипах архитектуры GCN приходится по четыре блока TMU, поэтому всего в новом GPU их стало 256 штук, в отличие от 176 TMU в Hawaii.
Соответственно, теоретические значения скорости вычислений и обработки текстур в Fiji выросли, а вот пиковые значения скорости обработки геометрии и скорости заполнения (филлрейт, производительность блоков ROP) остались практически на том же уровне, с поправкой лишь на разную частоту GPU. Возможно, в некоторых случаях может наблюдаться упор общей производительности в скорость заполнения сцены или обработки геометрии, но это сильно зависит от условий (сложности сцены и значения overdraw для нее, а также разрешения и полноэкранного сглаживания и т.д.).
Но представители AMD уверяют, что в случае Hawaii ограничителем чаще всего служит пропускная способность памяти (ПСП), а производительности блоков ROP вполне достаточно в большинстве случаев, и скорость рендеринга в их возможности упирается крайне редко. Но ведь в Fiji применяется более быстрая HBM-память с широкой шиной, а также внедрены новые методы сжатия данных в экранном буфере, да и сами блоки ROP в Fiji получили более широкие возможности по работе с данными формата 16-бит на цвет. Так что, скорее всего, количество случаев упора общей производительности в возможности блоков ROP только увеличится. А повысить количество блоков ROP в новом чипе не представлялось возможным, так как GPU и так получился достаточно крупным.
Исходя из количества ALU в 4096 штуки, а также максимальной частоты GPU, равной 1050 МГц, можно получить теоретическую производительность вычислений одиночной точности (FP32) в 8,6 терафлопс. А вот с вычислениями двойной точности в новом чипе дела обстоят значительно хуже, чем в том же Hawaii — тут AMD пришлось пойти примерно в том же направлении, что выбрала Nvidia для своего старшего Maxwell, сместив акцент в сторону игрового применения в ущерб профессиональным вычислениям.
Хотя разные чипы архитектуры GCN умеют исполнять FP64-вычисления с темпом от ½ до 1/16 от скорости FP32-вычислений, для Fiji компания AMD выбрала минимальное значение (1/16), что дает скорость FP64 около 538 мегафлопс. Сравните это с возможностями Hawaii, который выполняет вычисления с двойной точностью лишь вдвое медленнее вычислений одинарной точности. Даже менее сложные дешевые чипы GCN имеют темп в 1/8! Так что Fiji стал таким же «игровым», как и GM200. Похоже, что AMD взяла пример (хороший или нет — зависит от точки зрения) с Nvidia, обрезавшей свой топовый GPU еще сильнее. И в итоге, оба топовых игровых чипа от AMD и Nvidia являются больше игровыми, чем профессионально-вычислительными.
Да и в остальном графический процессор Fiji является не совсем типичным видеочипом для AMD. В этот раз компания выпустила довольно большой GPU — площадью почти 600 мм2! А ведь они вот уже несколько лет стараются избегать подобных больших и сверхгорячих видеочипов, так как они слишком дороги в разработке и производстве, да и времени от начала разработки до выхода на рынок требуют больше из-за сложностей и проектирования и сниженного выхода годных чипов. Не говоря уже о том, что с большими GPU и риск неудач выше. Хотя, конечно же, сейчас 28 нм техпроцесс уже отлично отработан и особых проблем производителям видеочипов не доставляет.

Но даже Hawaii в свое время уже был немаленьким с его 438 мм2, а уж в виде Fiji впервые за несколько лет у AMD получился GPU, лишь незначительно менее сложный, по сравнению с конкурирующим чипом Nvidia по количеству транзисторов и размеру кристалла. Так, Fiji имеет размер ядра в 596 мм2, что лишь на 5 мм2 меньше размера GM200 разработки компании Nvidia. Кстати, цифра около 600 мм2 весьма интересна — похоже, что тайваньская TSMC просто не способна массово производить еще большие чипы, и обе компании рассчитывали получить максимум с учетом этого ограничения. Тем более интересно, каких успехов они достигли в итоге по скорости и функциональности по сравнению друг с другом.
Снижение темпа FP64-вычислений позволило значительно упростить вычислительные блоки в Fiji, и количество блоков CU увеличилось с 44 до 64, поэтому вместо 2816 вычислительных блоков ALU в новом GPU их стало ровно 4096. С ростом вычислительной и текстурной производительности, по сравнению с Hawaii, остальные параметры производительности изменились не сильно. К примеру, количество геометрических движков, равно как и теоретическая скорость обработки геометрии, остались прежними (чуть больше из-за повышенной частоты видеочипа в Radeon R9 Fury X по сравнению с Radeon R9 290X). Но в архитектуре GCN 1.2 также были сделаны улучшения, предназначенные для ускорения обработки геометрии, и Fiji по этому показателю должен быть быстрее Hawaii даже при равных пиковых показателях. Мы обязательно проверим это в наших синтетических тестах.
Хотя сам по себе GPU архитектурно изменился очень мало, в нем есть несколько изменений, связанных с применением нового типа памяти. Графический процессор Fiji включает восемь контроллеров памяти HBM, каждый из которых обслуживает половину HBM-стека (всего их на чипе четыре), и каждый контроллер связан со своими восемью блоками ROP и разделом кэш-памяти второго уровня объемом 256 КБ.
Fury X получил на 60% большую пропускную способность видеопамяти, по сравнению с R9 290X (4096-битная шина с 512 ГБ/с против 512-битной шины с 320 ГБ/с). Вместе с улучшениями по сжатию цветовой информации кадрового буфера, это дает вдвое большую эффективную ПСП —, а этот показатель является одним из ключевых для современных графических процессоров в рамках реальных приложений. Конечно, сжатие будет хорошо работать в 3D-рендеринге, но вряд ли в вычислительных задачах, но в любом случае применение HBM-памяти дает неплохой прирост в ПСП. Но даже при такой высокой ПСП, кэш-память все равно в разы быстрее, и поэтому в новом GPU был увеличен и объем кэш-памяти второго уровня: Fiji имеет 2 МБ L2-кэша, по сравнению с 1 МБ у предшествующего топового решения.
Важные изменения произошли в плане обработки видеоданных — соответствующий блок Unified Video Decoder (UVD) имеет те же возможности, что и блоки APU семейства «Carrizo» и умеют аппаратно ускорять декодирование видеоданных в формате H.265 (HEVC). По части кодирования видеоданных, возможности блока VCE в Fiji не изменились, он все также умеет кодировать визуальный ряд в формат H.264, а вот блок декодирования видео получил полную аппаратную поддержку декодирования видеоданных в формате H.265, став первым дискретным GPU с подобной поддержкой.
Также AMD отмечает улучшенный скейлер и технологию Eyefinity — возможность вывода картинки на шесть устройств вывода изображения. К сожалению, ожидаемая многими поддержка HDMI 2.0 в новом GPU отсутствует. И это — довольно существенный недостаток, ведь самые доступные устройства с 4K-разрешением — это телевизоры, в которых чаще всего есть HDMI 2.0 порты и нет DisplayPort. Напомним, что конкурирующие видеокарты Nvidia получили поддержку HDMI 2.0 во всех GPU второго поколения архитектуры Maxwell.
Среди достоинств Fiji остается отметить поддержку технологии TrueAudio, которой также обладает чип Fiji. Эта технология появилась в графических процессорах семейства GCN 1.1, она предлагает аппаратное ускорение обработки аудиоданных на нескольких DSP от Tensilica, аналогичных тем, что включены в состав основного чипа консоли Sony PlayStation 4. Несмотря на все прелести аппаратной обработки звука в виде разгрузки основного CPU от этих задач, поддержка TrueAudio в играх ограничивается несколькими играми, вышедшими под эгидой специальной технической и маркетинговой программы AMD, а вероятность увидеть ее в других играх не слишком велика.
Конструктивные особенности и система охлаждения
Неудивительно, что компания AMD решила использовать при создании Radeon R9 Fury X такие же высокие стандарты для своей элитной серии Fury, как и Nvidia в Titan. Корпус видеокарты выполнен из нескольких частей, собранных вокруг печатной платы, а при его изготовлении применяются алюминиевые сплавы с разной обработкой поверхности, в итоге она выглядит и ощущается солидно, как и требуется от топового решения.
Фронтальная панель платы Radeon R9 Fury X, закрывающая компоненты на плате — съемная. Она закреплена четырьмя винтами и может заменяться панелью, сделанной из другого материала и с собственным рисунком — для возможности придания карте персонализированного вида. В случае видеокарты, которая обычно помещена внутрь корпуса так, что ее фронтальная поверхность не будет видна, это не так уж важно, но в целом — идея оригинальная и интересная.
Для большего визуального эффекта на плату решили поместить несколько светодиодов, а также красный светящийся логотип — аналогично двухчиповой модели прошлого поколения Radeon R9 295×2, новинка имеет на борту красную светящуюся надпись RADEON. Также новая топовая видеокарта компании AMD содержит несколько светодиодов, сигнализирующих о режиме работы GPU и размещенных над разъемами дополнительного питания PCI Express.

Линейка из восьми светодиодов GPU Tach показывает интенсивность загрузки графического процессора работой в данный момент. То есть, в игровом режиме все восемь светодиодов будут гореть, а в режиме рабочего стола горит лишь один из них. Цвет этих светодиодов выбирается пользователем из красного или голубого при помощи переключателя на задней стороне платы. А еще один зеленый светодиод, расположенный рядом с ними, показывает активность режима пониженного энергопотребления AMD ZeroCore.
Для обеспечения охлаждения мощнейшего графического процессора компании AMD было решено применить систему водяного охлаждения, которая обеспечивает работу GPU при типичной игровой нагрузке при температуре около 50 градусов. Системы водяного охлаждения уже давно стали нормой в системах, предназначенных для энтузиастов, а модель Radeon R9 295×2 стала первой видеокартой с референсным кулером такого типа — с системой водяного охлаждения замкнутого цикла.
Так как новый GPU очень требователен к питанию и выделяет много тепла, то немудрено, что и для Radeon R9 Fury X была выбрана аналогичная система производства компании Cooler Master. Кулер имеет радиатор и вентилятор размера 120 мм, а их совместная толщина равна 60 мм, что довольно много. В результате, СВО спокойно отводит до 500 Вт тепла, что намного превышает указанную цифру типичного энергопотребления для Fury X, равную 275 Вт — запас оставлен очень большой.

Хотя ранее мы уже видели не одну видеокарту с системами водяного охлаждения, но именно сочетание ее с памятью типа HBM позволило заметно уменьшить физические размеры печатной платы и корпуса видеокарты. Новая память также позволила снизить число компонентов в системе питания платы. Поэтому новинка сильно отличается от привычных топовых видеокарт с воздушным охлаждением, занимающих пару-тройку слотов по всей длине. Длина печатной платы Radeon R9 Fury X равна всего лишь 7.5 дюймов (порядка 190 мм), что значительно меньше типичных референсных карт верхнего ценового диапазона.
Все компоненты на плате (GPU, VRM и чипы памяти) охлаждаются единой системой, укомплектованной 120 мм радиатором и качественным вентилятором соответствующего размера производства Nidec. Кулер охлаждает сам GPU и соответствующие компоненты, в том числе MOSFET в модуле регулятора напряжения (VRM) — для этого проложена специальная трубка. Сам видеочип с помещенными на него микросхемами HBM охлаждается основным блоком помпы.
Применяемый кулер способен отвести до 500 Вт тепла, хотя модель получает питание по паре 8-контактных разъемов PCI-E, позволяющих передать до 375 Вт, а шестифазный модуль регулятора напряжения VRM способен обеспечить схемы током до 400 А — здесь виден большой запас для энтузиастов разгона, так как типичная величина энергопотребления платы Fury X, указанная компанией AMD, гораздо ниже — всего лишь 275 Вт.
Так как в системе охлаждения Radeon R9 Fury X применяется качественный вентилятор большого размера, то кулер обеспечивает довольно низкий уровень шума в 32 дБА — это значительно меньше, чем у воздушного охлаждения с типичными 40–45 дБА. Хотя от первых пользователей видеокарт Fury X появились претензии к шуму, исходящему от помпы, а не вентилятора —, но эту проблему AMD обещала решить в следующих партиях производимых для рынка плат.
Большинство энтузиастов, покупающих подобные видеокарты, интересуются разгоном, в том числе и экстремальным. И компания AMD облегчила часть задачи, укомплектовав свою топовую одночиповую карту мощным кулером и системой питания с большим запасом. Чаще всего разгон ограничивает именно недостаток охлаждения или питания, а Radeon R9 Fury X была спроектирована так, чтобы минимизировать эти ограничения, что должно порадовать любителей разгона.
Используя страницу AMD Overdrive в панели управления AMD Catalyst Control Center, пользователю дается возможность установки тактовых частот, целевой температуры, скорости вращения вентилятора и пределов по питанию — чтобы регулировать скорость видеокарты. Пока что с разгоном видеопамяти нового стандарта HBM не все понятно, но зато ее разгон с 500 до 600 МГц дает ощутимое ускорение в играх:
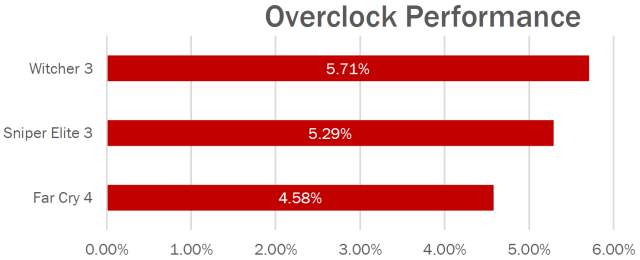
Надо сказать, что на момент выхода карты ее возможности для оверклокинга были серьезно ограничены, компания AMD не дала возможности повышения напряжения и разгона HBM-памяти, можно повысить только частоту GPU и предел общего потребления энергии, но задел имеется весьма серьезный. Этому поможет и переключатель Dual BIOS, как и в топовых картах предыдущего поколения, позволяющий выбирать между фиксированным референсным образом BIOS и модифицированным.
Новый стандарт памяти High Bandwidth Memory
Как мы уже упоминали, главным нововведением видеокарты AMD Radeon R9 Fury X стало применение видеопамяти нового стандарта — High Bandwidth Memory (HBM). До сих пор в видеокартах применялась лишь GDDR5-память, которая является эволюционным развитием давно известных стандартов, и хотя и имеет улучшенные характеристики по производительности и энергопотреблению по сравнению с GDDR3/GDDR4, но улучшения эти не столь значительны.
Основам ранее применяемых стандартов DRAM уже много лет, и модификации позволили повысить пропускную способность далеко не настолько, насколько выросла производительность GPU за это время. За двадцать лет улучшения стандартов позволили поднять пропускную способность памяти (ПСП) всего лишь примерно в 50 раз, в то время как скорость вычислений графических процессоров за это время выросла много больше. Поэтому индустрии потребовались новые типы памяти, которые дадут совершенно иные возможности.
В стандарте GDDR5 тот тип памяти достиг своего предела, и хотя небольшие возможности для роста ПСП еще есть, но они требуют больших усилий и не изменят ситуацию кардинально. При этом вопрос высокого потребления не решится, а ведь энергоэффективность — главный параметр для любого современного чипа. Уже текущие поколения GDDR5-памяти потребляют слишком много энергии из-за сложных механизмов тактования и работы на очень высокой частоте, а любые улучшения производительности GDDR5 связаны с дальнейшим повышением частоты и сложности, а значит, и энергопотребления.
Также GDDR5-чипы занимают слишком много места на плате и требуют применения нескольких каналов памяти, что усложняет и сам графический процессор. Особенно если говорить о топовых GPU с 384-битной или даже 512-битной шиной памяти. Хотя сам по себе размер видеокарт не имеет слишком большое значение для игровых ПК, но в последнее время появляется много компактных корпусов в новых форм-факторах, применять в которых нынешние видеокарты не получится.
Чтобы решить все эти проблемы, компании AMD и Hynix еще в 2011 году анонсировали совместные планы по разработке и внедрению нового стандарта памяти — High Bandwidth Memory. Новый тип памяти стал огромным шагом вперед по сравнению с применяющейся до сих пор GDDR5-памятью, и среди главных преимуществ HBM значатся серьезное увеличение пропускной способности и увеличение энергетической эффективности (снижение потребления вместе с ростом производительности).
Напомним, что компания AMD, как и компания ATI в прошлые годы, в последнее время является лидером по освоению новых типов графической памяти. Хотя продукты с поддержкой GDDR2 и GDDR3 первыми выпустили не они, именно эта компания первой оснастила свои решения видеопамятью последних двух существующих стандартов: GDDR4 и GDDR5. Соответственно, в 2011 году в партнерстве с Hynix они решили продолжить инициативу по приоритетной разработке и внедрению новых стандартов видеопамяти в будущих GPU. И вот, после четырех лет разработки компании наконец-то представили графический процессор, оснащенный совершенно новым типом графической памяти.
Стандарт HBM отличается тем, что вместо массива очень быстрых чипов памяти (7 ГГц и выше), соединенных с графическим процессором по сравнительно узкой шине от 128 до 512 бит, применяются очень медленные чипы памяти (порядка 1 ГГц эффективной частоты), но ширина шины памяти при этом получается шире в несколько раз. Как и в случае с GDDR5, ширина шины для различных GPU будет разной и она зависит как от поколения стандарта HBM (первого или второго на данный момент), так и конкретного воплощения.
В случае Radeon R9 Fury X применяются четыре стека (stacks, стопок или пачек) чипов памяти, каждый из которых состоит из четырех микросхем и дает 1024-битный интерфейс памяти. То есть в итоге на GPU получаются широченная по меркам GDDR5-памяти шина в 4096 бит. Естественно, что при этом чипам памяти не обязательно работать на таких же высоких частотах, как в случае GDDR5 — сравнительно низкой частоты будет достаточно, чтобы по полосе пропускания памяти (ПСП) обойти привычные интерфейсы.
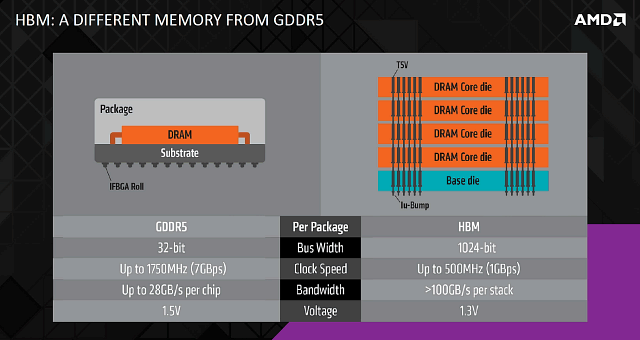
4096-битная шина памяти требует значительно большее количество соединений, по сравнению с привычной GDDR5, и все они должны поместиться физически, чтобы такая шина работала. Именно эти параллельные соединения и являются главной проблемой в соединении GPU с HBM-памятью, и для успешного решения задач по их размещению в новом типе памяти применяется несколько новых технологий.
Самым важным вопросом является эффективная разводка 4096-битной шины памяти. Ведь даже самые последние технологии производства чипов имеют свои ограничения, и графические процессоры никогда не переходили предел в 512 бит, даже в самых последних топовых графических чипах вроде Hawaii. Организовать еще более широкую шину памяти на больших GPU теоретически возможно, но решение этой сложной задачи будут ограничивать физические возможности по размещению такого количества соединений и на печатной плате и в самом чипе, не говоря уже о необходимом количестве контактов на корпусах типа BGA.
Решением части этой задачи стала разработка специального слоя, который способен вместить соединения большой плотности — кремниевой подложки (interposer). Этот слой похож на обычный кремниевый кристалл, в котором вместо некоей внутренней логики размещены металлические слои для передачи сигналов и питания между различными компонентами — получается некий переходник. При производстве interposer используются возможности современных литографических процессов, позволяющих разместить очень тонкие проводники, которые практически невозможно вместить на традиционных печатных платах.
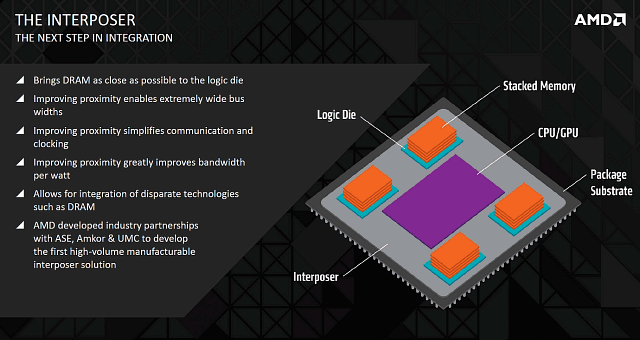
Использование слоя-переходника решает часть фундаментальных проблем по размещению широкой шины памяти, а также дает и другие преимущества. Так, вместе с решением проблемы маршрутизации проводников, эта кремниевая подложка позволяет разместить чипы памяти очень близко к GPU, но не прямо на кристалле, как применяется в случаях некоторых мобильных систем-на-чипе. А если поместить микросхемы памяти близко к графическому чипу, то и длинных соединений между ними не требуется, что упрощает конструкцию и предъявляет менее жесткие требования по питанию.
Помещение чипов памяти вместе с основной логикой также выигрывает в повышении степени интеграции — большее количество функциональной логики можно собрать в одной упаковке, что уменьшает количество необходимой внешней обвязки. В итоге, компания AMD выпустила первый массовый продукт, использующий слой interposer, и стала первой компанией, выпустившей решение с применением stacked DRAM и интеграцией чипов HBM и GPU.
Конечно, у решения с промежуточным слоем есть и свои недостатки — усложнение конструкции и повышение себестоимости производства. Естественно, что никто из AMD не говорит о стоимости производства первых чипов с HBM, но очевидно, что добавление дополнительного слоя, а также его соединение и тестирование всего продукта, включающего сложнейшую логику, может лишь увеличить его себестоимость, особенно в самом начале его производства. И особенно — по сравнению с давно отработанными технологиями производства
Полный текст статьи читайте на iXBT
