Обзор достижений контейнерной изоляции за последние два года
Около двух лет назад на страницах OpenNet было опубликовано интервью с Павлом Емельяновым, руководителем группы разработчиков Parallels Server Virtualization, в котором Павел рассказывал о планах компании по включению кодов контейнерной виртуализации в ядро Linux и проект CRIU. Три года назад, когда проект еще был в начальной стадии, он вызвал волну интереса у пользователей Linux и скептический отзыв у Эндрю Мортона. Осенью 2013 года был анонсирован первый крупный релиз проекта — CRIU 1.0. А сегодня он де-факто стал стандартом реализации технологии checkpoint-restore в Linux. Напомним, Павел Емельянов отвечает не только за проектирование многокомпонентных систем, основанных на серверной виртуализации, но и организует процесс взаимодействия ядерной команды Parallels с сообществом разработчиков ядра Linux. Один из его любимых проектов, который получился из такой совместной работы, — CRIU: приложение, которое умеет снимать состояние выполняющихся в Linux процессов и восстанавливать в другом месте или в другое время эти процессы из полученных данных. Его целью было заменить существующую реализацию технологии сохранения и восстановления состояния контейнеров, которая, в свою очередь, необходима как база для живой миграции контейнеров.
Сегодня мы публикуем некоторые итоги работы команды Павла и ждем вопросов от сообщества, на которые Павел согласился ответить. Вопросы можно отправлять в свободной форме в комментариях к новости. Ответы будут опубликованы в ближайшие недели. Для пояснения сути контейнеров и оценки целесообразности использования таких систем, в качестве дополнения также приводится перевод статьи Джеймса Боттомли (James Bottomley), известного разработчика ядра Linux, входящего в координационный технический комитет Linux Foundation и занимающего должность технического директора по серверной виртуализации в компании Parallels.
Обзор итогов за 2 года от Павла Емельянова Недавно в жизни проекта произошло знаменательное событие — Parallels стала сотрудничать с инженерами из компаний Google и Canonical. Последняя, как известно, поддерживает дистрибутив Ubuntu. Они уже влились в проект не только как пользователи, но и как участники — в последнем релизе 1.3-rc2 есть патчи, присланные с адресов @google.com и @canonical.com. Более того, разработчики из Google и Canonical принимают активное участие в обсуждении поддержки cgroup в CRIU и успешно используют CRIU с утилитами Docker и LXC.
Кстати, о Docker и LXC. Эти два проекта в своё время завоевали огромную популярность и потеснили с олимпа проект OpenVZ в мире Linux Containers. Долгое время три проекта сосуществовали параллельно, предлагая пользователям одинаковую по сути, но разную в реализации и деталях технологию. Недавно Docker, Parallels, Canonical, Google и RedHat договорились о слиянии центральных частей своих контейнерных проектов в один — libcontainer — и совместном, согласованном его развитии.
Libcontainer — это системная библиотека, предоставляющая гибкий и достаточно абстрактный интерфейс к ядерным контейнерным компонентам. Немного технических подробностей. В ядре не существует такого понятия как «контейнер». Говоря о контейнерах, разработчики ядра подразумевают несколько разных подсистем ядра, которые позволяют, при правильном использовании, изолировать приложения в виртуальных средах. Это, главным образом, cgroups и namespaces. Прямое использование ядерных интерфейсов возможно, но весьма нетривиально.
Библиотека libcontainer призвана облегчить процедуру их использования, предоставив программистам интерфейс, в котором есть более «привычные» и «возвышенные» понятия, такие как «контейнер», «вычислительные ресурсы», «виртуальная сеть» и т.п.
Помимо развития контейнерной технологии, Parallels видит в Libcontainer ещё и способ получить эту технологию в проекте OpenStack. OpenStack — это набор программ, позволяющий разворачивать облачную инфраструктуру и управлять ею. До сих пор OpenStack работал только с виртуальными машинами, но в последнее время, с развитием контейнерной технологии, сообщество разработчиков OpenStack всё чаще и чаще вспоминает о том, что неплохо было бы создавать контейнеры и в облаках, управляемых OpenStack-ом.
Уже было предпринято несколько попыток достичь этого — RackSpace разработал расширение на основе контейнеров OpenVZ, но это решение не было принято сообществом. Docker предоставил расширение, основанное на своей технологии, но и оно не закрепилось в проекте. В качестве дальнейшего развития разработчики Parallels, Docker, Canonical и, возможно, RackSpace попробуют привнести контейнеры в OpenStack через Libcontainer.
Почему все это сейчас так важно? Дело в том, что контейнерная технология становится ключевым компонентом в большинстве дистрибутивов Linux. Более того, мы все чаще замечаем, что она становится востребованной в корпоративной среде, хотя традиционно считалась уделом хостинг-сообщества.
Поскольку рынок постепенно переходит от простых хостинговых услуг к облачным, мы считаем важным, чтобы у заказчиков были все необходимые для этого инструменты, в том числе — OpenStack и Docker. Последний, в частности, пригодится для упаковки ваших приложений в контейнер. Причины, по которым Parallels поддерживает сразу оба проекта, одинаковые: получить технологии Open Source, на основе которых можно построить дифференцированное предложение, соответствующее конкретным нуждам заказчиков. С помощью OpenStack, компонентов открытой технологии для облачных инструментов и инструментов автоматизации, с помощью Linux Foundation (и Linux в целом) в компании уже работает такое решение, как Parallels Cloud Server.
Сегодня разработчики Parallels помогают создать новое поколение docker-программ, таких как контейнеризированные приложения, и за счет этого расширить количество сценариев использования для контейнеров в вычислительной индустрии. А libcontainer как технология open source для потребления контейнерной виртуализации на уровне детализации — это согласованная (между Docker, LXC, Google и Parallels) возможность сделать это.
Джеймс Боттомли, статья «Почему сегодня так много говорят о контейнерной виртуализации?» Из всех разнообразных технологий виртуализации контейнеры еще недавно рассматривались либо как недорогой вариант создания инфраструктуры для хостинга, либо как редкая диковинка. Но сегодня, благодаря облачной революции и выходу на первый план таких свойств, как эластичность и вычислительная плотность, контейнеры стали предметом повышенного интереса. Прежде всего, потому, что они больше всего подходят для решения этих задач. Почему же о них раньше забывали, и почему вспомнили сегодня?
В общих чертах виртуализация — это искусство запуска одной операционной системы поверх другой. История ее развития довольно длинная и богатая. Задолго до гипервизоров и UNIX-систем она использовалась в мейнфреймах для разделения различных операционных систем. Широкого признания на рынках UNIX и Linux она добилась лишь где-то в 2001-ом. В этом году компания VMware выпустила серверный продукт для виртуализации на основе гипервизора, привлекший внимание корпоративного рынка. Практически в то же самое время компания Parallels выпустила Virtuozzo, решение для контейнерной виртуализации, получившее большую популярность на рынке хостинга.
Этот барьер сохранялся почти 12 лет: гипервизорная виртуализация не могла отхватить сколько-нибудь значимый кусок хостингового рынка, а контейнеры не могли проникнуть на корпоративный. Такое положение дел продлилось, по крайней мере, до 2013 года — момента появления разработчика Docker и начала роста интереса бизнеса к контейнерной технологии.
Контейнеры против гипервизоров — все дело в плотности  В двух словах, гипервизор работает следующим образом (рис. 1): операционная система хоста эмулирует аппаратное обеспечение, поверх которого уже запускаются гостевые операционные системы. Это означает, что взаимосвязь между гостевой и хостовой операционными системами должна следовать «железной» парадигме (все, что умеет делать оборудование, должно быть доступно гостевой ОС со стороны хостовой).
В двух словах, гипервизор работает следующим образом (рис. 1): операционная система хоста эмулирует аппаратное обеспечение, поверх которого уже запускаются гостевые операционные системы. Это означает, что взаимосвязь между гостевой и хостовой операционными системами должна следовать «железной» парадигме (все, что умеет делать оборудование, должно быть доступно гостевой ОС со стороны хостовой).
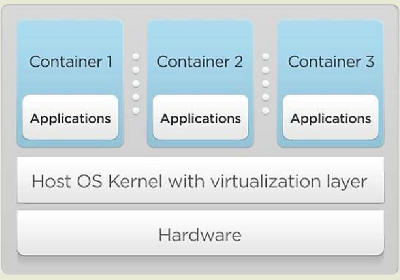 Напротив, контейнеры (рис. 2) — это виртуализация на уровне операционной системы, а не оборудования. Это означает, что каждая из гостевых ОС использует то же самое ядро (а в некоторых случаях — и другие части ОС), что и хостовая. Это дает контейнерам большое преимущество: они меньше и компактнее гипервизорных гостевых сред, просто потому, что у них с хостом гораздо больше общего. Другой большой плюс: гостевое ядро значительно эффективнее в отношении совместного использования ресурсов контейнерами, так как для него контейнеры представляют собой просто управляемые ресурсы.
Напротив, контейнеры (рис. 2) — это виртуализация на уровне операционной системы, а не оборудования. Это означает, что каждая из гостевых ОС использует то же самое ядро (а в некоторых случаях — и другие части ОС), что и хостовая. Это дает контейнерам большое преимущество: они меньше и компактнее гипервизорных гостевых сред, просто потому, что у них с хостом гораздо больше общего. Другой большой плюс: гостевое ядро значительно эффективнее в отношении совместного использования ресурсов контейнерами, так как для него контейнеры представляют собой просто управляемые ресурсы.
К примеру, если Контейнер 1 и Контейнер 2 работают с одним и тем же файлом, то ядро хоста открывает этот файл и размещает страницы из него в страничный кэш ядра. Эти страницы затем передаются Контейнеру 1 и Контейнеру 2: если оба хотят прочитать одни и те же данные, то получают одну и ту же страницу. Если же гипервизорные виртуальные машины VM1 и VM2 выполняют такую же операцию, то сначала сам хост открывает запрашиваемый файл (создавая страницы в своем страничном кэше), а затем еще и каждое из ядер VM1 и VM2 делает то же самое.
Это означает, что при чтении VM1 и VM2 одного и того же файла в памяти существует целых три одинаковых страницы (по одной в страничном кэше хоста и в ядрах VM1 и VM2) — потому, что они не умеют одновременно использовать одну и ту же страницу, как это делают контейнеры. Такое совместное использование ресурсов приводит к тому, что вычислительная плотность (это количество виртуальных сред, которые можно запустить на сервере) почти в 3 раза выше для контейнерной виртуализации, чем для гипервизорной.
Высокая плотность — одна из главных причин, по которым контейнеры стали крайне популярны на рынке хостинга виртуальных выделенных серверов (VPS). Если на одном и том же сервере можно создать в 3 раза больше VPS, то в расчете на один VPS затраты снижаются на 66%. Конечно, не все идеально в мире контейнеров. Например, при «расшаривании» ядра нельзя запускать разные ядра в рамках одного сервера. Поэтому запустить и Windows, и Linux на одном и том же сервере (что для гипервизоров — легкое дело) не получится. Но в Linux, по крайней мере, этот недостаток можно смягчить, используя интерфейсы ABI и библиотеки, что делает возможным запускать на одном сервере контейнеры с различными дистрибутивами Linux. Правда, это достигается ценой уменьшения общей для этих контейнеров части ресурсов. Максимально преимущества контейнеров проявляются в однородной среде.
История контейнеров В 2005 году компания Google решала проблемы массового предоставления веб-сервисов, а именно — искала способ эластичного масштабирования ресурсов в своем центре обработки данных таким образом, чтобы каждый пользователь получил достаточный уровень сервиса в любой момент, независимо от текущей загрузки, и чтобы использовать оставшиеся ресурсы для служебных фоновых задач.
Сотрудники Google экспериментировали с традиционной виртуализацией для решения этой задачи, но быстро пришли к выводу, что она не подходит. Главной проблемой стало то, что потеря производительности слишком высока (а плотность, соответственно, слишком низка) и отклик недостаточно эластичен для массового предоставления веб-сервисов. Последний пункт очень важен, потому что предсказать, сколько запросов — десятки, сотни или даже миллионы — будут обслуживать веб-сервисы, невозможно. Но пользователи при этом всегда ждут немедленного ответа (а это означает секундную разницу между нажатием кнопки и появлением результата на экране), независимо от того, сколько именно других пользователей в этот же момент работает с сервисом. Учитывая среднее время загрузки гипервизорной ВМ в десятки секунд, такой тип виртуализации не подходит для этой задачи.
В то же самое время группа разработчиков экспериментировала с Linux и концепцией, основанной на механизме cgroups, называющейся «контейнеры процессов». В считанные месяцы Google наняла эту группу для работы над контейнеризацией своих дата-центров в целях решения проблемы эластичности при масштабировании. В январе 2008 года часть технологии cgroup, используемой в Google, перешла в ядро Linux. Так родился проект LXC (LinuX Containers). Приблизительно в это же время компания Parallels выпустила OpenSource-версию своей виртуализации Virtuozzo под названием OpenVZ. В 2011-ом Google и Parallels пришли к соглашению о совместной работе над своими контейнерными технологиями. Результатом стал релиз ядра Linux версии 3.8 в 2013 году, в котором были объединены все актуальные на тот момент контейнерные технологии для Linux, что позволило избежать повторения болезненного разделения ядер KVM и Xen.
Контейнеры и бизнес: почему ажиотаж идет сейчас? Для хостинг-провайдеров основное преимущество — плотность. При этом корпоративным клиентам она не слишком-то нужна. Виртуализация для них предлагалась как способ решить проблему низкой утилизации серверного оборудования и найти способ использования свободных вычислительных ресурсов. Таким образом, технология, увеличивающая плотность и за счет этого уменьшающая общую утилизацию ресурсов, для этого сегмента не представляла ценности. Из-за этого контейнеры практически игнорировались корпоративным сегментом, представляющим 85% всего рынка виртуализации. Фактически — всем миром, кроме хостинг-провайдеров.
Ситуация начала меняться с 2010 года — с ростом облачного бизнеса. Облака обещали многое, но компании столкнулись ровно с теми же трудностями, что и Google — эластичное масштабирование ресурсов в дата-центрах плюс к необходимости обеспечивать хороший сервис. И здесь у гипервизоров время загрузки оказалось слишком медленным, чтобы обеспечить быстрый отклик системы, что приводило к неспособности адекватно менять объемы ресурсов. И контейнеры наконец-то начали привлекать внимание: потому что, если вы быстро масштабируетесь, то, в конце концов, истощите лимиты своей физической системы, в то время как контейнеры позволяют обслуживать больше (до 3 раз) клиентских запросов без необходимости добавлять оборудование.
Но возникли следующие проблемы: во-первых, все представления вендоров о виртуализации были искажены гипервизорами (многие просто не знали, что есть и другие варианты), во-вторых, большая часть бюджета в центрах обработки данных уже ушла на покупку и управление гипервизорными решениями. В этом случае полный переход на новую технологию — не такая уж хорошая идея.
Так продолжалось до тех пор, пока в 2013 году на рынок не пришел разработчик Docker и не показал, как легко «упаковать» контейнеризированное приложение в Linux и развернуть его в масштабе прямо в dotCloud (сервис PaaS (Platform as a Service) от Docker). Предприятия заинтересовались. Одновременно OpenStack стал обещать объединить системы управления облаками (Cloud Management) в единую платформу, содержащую обе технологии виртуализации. Тогда бизнес наконец-то увидел возможность управлять своими центрами обработки данных на основе гипервизоров с помощью единого инструмента, который может одновременно разворачивать контейнеризированные приложения в масштабе. Вот теперь шумиха вокруг контейнеров началась всерьез.
Контейнеры и Network Function Virtualization (NFV) Традиционно в NFV берется сетевая функция, экспортированная через коммутационную матрицу и проксируется в гостевое ядро с помощью средств виртуального драйвера, связанного с коммутационной матрицей. Это позволяет гостевой системе обрабатывать сетевой трафик с той же эффективностью, что и в плоскости передачи данных коммутации, но в виртуальной середе эта операция не поддается программному контролю.
Актуальная, переданная через proxy коммутационная функция появляется в гостевой системе благодаря одному (или набору) относительно стандартных сетевых интерфейсов. А можно ли подсоединить контейнеры к проксированной фукнции коммутационной матрицы с помощью средств сетевого интерфейса? Ответ — да. Дело в том, что контейнер включает в себя технологию, которую называют сетевым пространством имен (network namespace), и ее задача — заставить сетевой интерфейс из совместно используемого ядра появиться только в одном контейнере. Поэтому, до тех пор, пока можно внедрить специальный драйвер в расшариваемое ядро, сетевой интерфейс по-прежнему может быть передан через прокси в отдельный контейнер с помощью пространства имен.
Это может дать контейнеру идентичную способность обрабатывать сетевой трафик в виртуальной среде с помощью специального драйвера, хотя сейчас сетевая функция codecan взаимодействует даже с большей плотностью и эффективностью благодаря занимающей меньше объема контейнерной инфраструктуре. Можно даже подумать о будущем этой концепции: поскольку сетевое пространство имен также независимо от остальных видов контроля в контейнере, скоро можно будет взять набор приложений, запущенных в физической системе, и соединить каждое из них по отдельности с проксированной функцией коммутационной матрицы благодаря тому, что каждое приложение запускается в своем собственном пространстве имен. В этом подходе, называемом контейнеризацией приложения, достаточно, чтобы приложение само по себе лишь частично было размещено в контейнере (в зависимости от того, какие лимиты вам нужно установить). Тогда оно сможет взаимодействовать с плотностями почти в 100 раз больше, чем это возможно при традиционной виртуализации.
Ближайшее будущее: контейнеры — это ответ? Да, контейнеры — это доказанная технология для плотности, гибкости и масштабирования. Они могут помочь с пакетированием и развертыванием веб-приложений в масштабе, а использование их свойств в веб-приложениях и платформах может решить некоторые сегодняшние проблемы в предоставлении облачных услуг, такие, например, как многопользовательский доступ.
Однако контейнеры — не универсальное решение, поскольку бизнес уже проинвестировал в такие ориентированные на гипервизоры технологии, как, например, SR-IOV, VT-D и Network Function Virtualization. Большинство из них разработаны для связи гостевой виртуальной машины напрямую с аппаратной или коммутационной системой с помощью специального драйвера, установленного в гостевом ядре. Так как контейнерная технология работает на уровне операционной системы, она не может говорить на языке «железа». Хотя почти для каждой корпоративной «железной» гипервизорной технологии (например, SR-IOV или NFV) есть решение, которое может быть использовано в контейнере. Но реальность говорит о том, что если думать только в парадигме гипервизоров, то контейнерная технология не сработает. Решение в том, чтобы посмотреть, как выглядит ваш бизнес и ваша виртуализация сегодня, и спросить себя, как это могло бы работать, если бы вы выбрали контейнеры. Результаты могут вас удивить.
Полный текст статьи читайте на OpenNet
