Новые горизонты AMD: рассказ о решениях компании для усиления позиций в дата-центрах
Все в дата-центры
В последнее время все большее внимание производителей аппаратного обеспечения привлекает рынок высокопроизводительных вычислений и центров хранения и обработки данных (далее для краткости — ЦОД или дата-центры). Оно и неудивительно, хотя в долгосрочной стратегии той же компании AMD остается на своем месте и графика: игровая, профессиональная, системы виртуальной реальности, но все большее внимание переносится на решения для систем обработки, хранения и распространения данных.
Рынок ЦОД сейчас особенно активно развивается и способен еще сильнее повлиять на то, как все устроено в нашем мире. А главное для коммерческих компаний — он имеет довольно большой объем, выраженный в денежных знаках и суммами со многими нулями. Это очень привлекательный рынок как для традиционных систем AMD на основе CPU (серверные процессоры EPYC), так и ускорителей параллельных вычислений на GPU — семейство Radeon Instinct.

По прикидкам компании AMD, общий объем этого рынка должен составить 21 млрд долларов в 2021 году, и совершенно неудивительно, что все компании вступили в плотную борьбу за этот лакомый кусок. Кто-то уже находится там и старается дополнительно укрепить свои позиции, а кто-то с боем прорывается на рынок ЦОД, предлагая более привлекательные решения.
На прошедшем в ноябре мероприятии Next Horizon, компания AMD продемонстрировала свое стремление к тому, чтобы урвать максимально возможный кусок рынка ЦОД. Ими были представлены различные вычислительные продукты, разработанные для расширения возможностей современных ЦОД: следующее поколение серверных процессоров EPYC с революционной компоновкой и новые решения для параллельных вычислений серии Radeon Instinct, основанные на улучшенном графическом процессоре, произведенном по самому совершенному техпроцессу.
Современные вычислительные задачи требуют огромных вычислительных возможностей, продвинутого искусственного интеллекта, анализа больших объемов данных, облачных решений и виртуализации ресурсов. Более того, нынешние ЦОД требуют новых подходов. Если условный десяток лет назад потребители решений были сравнительно мелкими, то теперь это крупные компании, занимающие большую часть рынка. Раньше они использовали собственное программное обеспечение, то теперь все чаще стараются ограничиваться открытым ПО, ну и многое переходит в облачные вычисления.
Для того чтобы соответствовать всем современным требованиям, нужно своевременно производить изменения в архитектуре CPU и GPU, вводить быстрые соединения между вычислительными узлами и предлагать индустрии четкие планы на будущее — как планируется менять возможности и производительность будущих решений. Тогда у партнеров и инвесторов компании будет четкое понимание того, как строить дальнейшие взаимоотношения.
Еще в прошлом году компания AMD ворвалась на рынок ЦОД со своими серверными решениями семейства EPYC, которые оказались весьма конкурентоспособными в различных ценовых сегментах, предлагая большее количество вычислительных ядер, поддержку большего объема памяти и межузловых соединений, и особенно — уникальные ценовые предложения, позволяющие снизить как начальные затраты на оборудование, так и совокупную стоимость владения (Total Cost of Ownership — TCO).

Может в AMD и слегка преувеличили преимущество по экономии средств на этом слайде, но EPYC действительно стал лучшим выбором для множества коммерческих и научных задач, вроде прогнозирования погоды и молекулярной динамики. Именно поэтому серверные процессоры EPYC выбрали в Cray для суперкомпьютеров различного назначения, включая мощную систему для одной из команд Формулы 1 — Haas, и это далеко не единственное подобное решение.
В сфере параллельных вычислительных решений неплохим выбором стал Radeon Instinct MI25, специально разработанный для высокопроизводительных и облачных систем, предлагающий довольно высокую производительность в 25 терафлопса. А для того, чтобы раскрыть возможности этого решения, была предложена первая платформа для вычислений на GPU с открытым исходным кодом — ROCm, оптимизированная для высокопроизводительных параллельных вычислений, специализированные библиотеки для глубокого обучения и т. п.

Индустрия весьма неплохо приняла решения компании AMD последнего времени, особенно EPYC, и список партнеров (OEM/ODM-производителей, системных интеграторов, облачных сервисов и т. п.) к настоящему времени довольно обширен и он лишь увеличивается. В частности, на мероприятии Next Horizon было анонсировано сотрудничество AMD с Amazon Web Services (AWS), которое предполагает использование серверных процессоров AMD EPYC в облачных решениях этой компании.
Процессоры EPYC появятся в Amazon Web Services
На недавнем мероприятии компании AMD и Amazon Web Services объявили о том, что процессоры AMD EPYC скоро будут доступны в Amazon Elastic Compute Cloud (EC2) в трех конфигурациях. Предложения на основе EPYC дополнят популярные семейства инстансов AWS уникальными характеристиками с лучшей плотностью ядер и пропускной способностью памяти, обеспечивая высочайшую производительность на доллар при различных видах нагрузок.
Основное преимущество таких систем достигается за счет высокого количества ядер в процессорах EPYC, которые предложат заказчикам инстансов M5 и T3 сбалансированную вычислительную мощность, объем памяти и сетевых ресурсов для серверов, инфраструктуры корпоративных приложений и сред тестирования и разработки с прозрачными механизмами миграции приложений. Высокая пропускная способность памяти у EPYC также отлично подходит для анализа данных и динамической обработки информации и является важным преимуществом инстансов R5.

Появление сразу нескольких инстансов Amazon EC2, основанных на процессорах EPYC, является важным шагом для AMD на пути внедрения серверных процессоров компании в центры обработки данных столь известных компаний, которые оценили комбинацию из большого количества ядер, высокой пропускной способности памяти и большого количества линий ввода-вывода. Все это позволило создать решение, способное обеспечить снижение совокупной стоимости владения для заказчиков (в лице AWS) и соответственное снижение цен на услуги для конечных пользователей. По данным компании AMD, их решения оказались примерно на 10% выгоднее, по сравнению с конкурирующими при типичных нагрузках.
Инстансы M5 и R5 доступны в шести вариантах: с числом vCPU до 96 и оперативной памятью до 768 ГБ, а инстансы T3 будут предлагаться в семи вариантах, с числом vCPU до 8 и оперативной памятью до 32 ГБ. Новые инстансы доступны в семействах Amazon EC2 в вариантах для общего использования и с оптимизацией памяти. Инстансы R5 и M5 на базе процессоров EPYC уже доступны в Восточной и Западной Америке, в Ирландии и Азиатско-Тихоокеанском регионе, но в планах компании AMD есть запуск предложений и в других регионах. Инстансы T3 на основе EPYC станут доступными в течение ноября.
Архитектура Zen 2 и серверные процессоры EPYC «Rome»
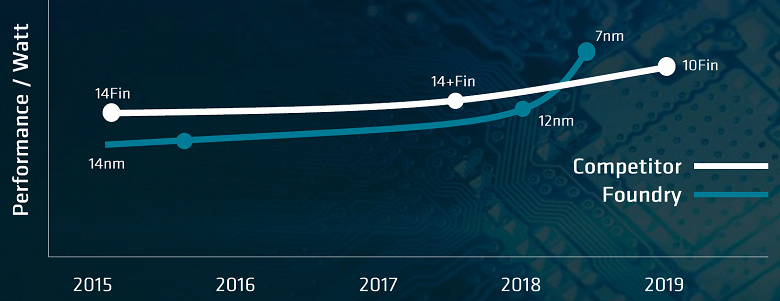
На своем мероприятии, посвященном высокопроизводительным системам и дата-центрам, компания AMD впервые раскрыла некоторые интересные подробности о своей грядущей высокопроизводительной x86-совместимой архитектуре для универсальных процессоров — Zen 2. Самое очевидное его преимущество состоит в том, что этот многоядерный процессор будет выпускаться по самому совершенному на данный момент техпроцессу 7 нм.

Этот техпроцесс — довольно большой шаг вперед для глобального полупроводникового производства, потребовавший очень больших инвестиций. Новый техпроцесс позволяет получить заметно лучшие характеристики по плотности транзисторов (до двух раз) при меньшем энергопотреблении (вполовину при той же производительности) и более высокой частоте и производительности — до 25% прироста при сохранении того же потребления.
Получается, что компания AMD впервые даже немного обогнала своего конкурента Intel в подготовке новых CPU, использующих самые продвинутые техпроцессы. Если раньше они все время хоть и чуть-чуть, но все же отставали от конкурента, имеющего собственные фабрики, то теперь перехватили преимущество за счет успехов тайваньского производителя TSMC по освоению техпроцесса 7 нм и неудач конкурирующей с ними компании Intel по освоению их варианта — техпроцесса 10 нм (несмотря на приличную разницу в цифрах, по характеристикам эти техпроцессы близки).
Но далеко не только переходом на 7 нм интересен Zen 2, его отличия от предыдущего поколения намного более впечатляющи. Так, в новых процессорах применяется революционная модульная конструкция, использующая улучшенную версию Infinity Fabric для соединения отдельных элементов кремния («чиплетов») в едином процессоре.
То есть, в отличие от первого поколения Zen, в следующем семействе универсальных процессоров компании AMD сами вычислительные ядра отделены от всей логики ввода-вывода (контроллеров памяти и т. п.), но все они соединяются с центральным ядром ввода-вывода, который и содержит все «недостающие» блоки:
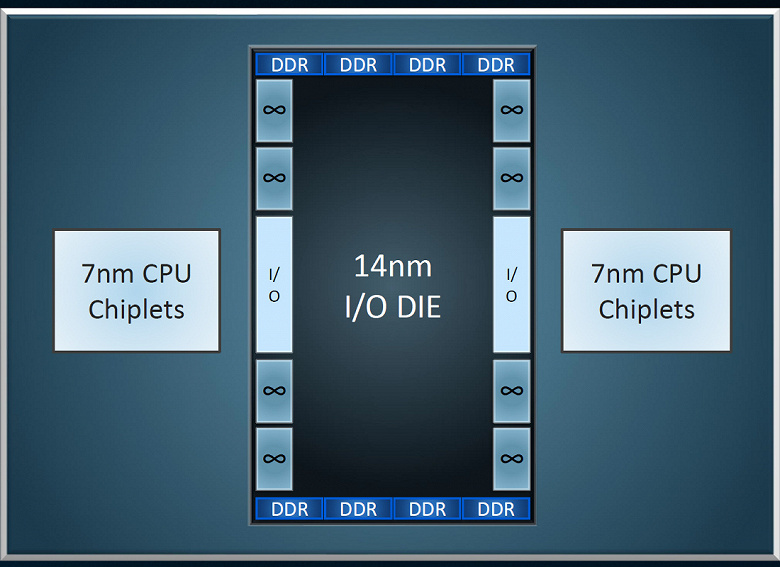
К примеру, на картинке показан вариант с одним центральным ядром и двумя чиплетами, но их может быть и больше. Такой универсальный подход обеспечивает и более высокую производительность — большее количество ядер CPU при таком же энергопотреблении (впрочем, это заявление AMD еще нуждается в проверке). Главное, что такая модульная конструкция обеспечивает меньшие затраты на производство, по сравнению с традиционными монолитными чипами, которые бы имели просто огромный размер кристалла при большом количестве вычислительных ядер.
Каждая часть CPU использует наиболее подходящую технологию производства — высокопроизводительные ядра хорошо масштабируются и требуют максимально «тонкого» техпроцесса, а ядру ввода-вывода будет вполне достаточно и менее продвинутого 14 нм —, но с улучшенными характеристиками по потреблению и задержкам. И если сами высокопроизводительные ядра Zen 2 получают преимущества использования новой технологии 7 нм TSMC, то для части процессора, отвечающей за ввод-вывод данных, используется куда более простой техпроцесс 14 нм GlobalFoundries.
Это — очень интересное решение, объединяющее кристаллы, произведенные не только с разными техпроцессами, но даже разными заводами! Оно дает производителю необходимую гибкость, позволяя получить оптимальный результат для каждого типа кристаллов в составе единого процессора. В теории, подобным образом можно будет в будущем объединить на одной подложке сразу и CPU и GPU. Хотя до этого пока что не дошли, но уж очень такое решение напрашивается, хоть и не для серверных продуктов — им и так нужно очень много тепла отводить. А вот для ноутбуков и других компактных систем (игровых консолей?) вполне можно.

Вот так выглядит модульный вариант Zen 2 с восемью чиплетами и одним центральным ядром. Все контроллеры памяти расположены на ядре ввода-вывода, а не разбросаны по ядрам, как в Zen 1. С одной стороны, это снизит ПСП для части данных, с другой — такой унифицированный подход сблизит задержки для всех ядер процессора. AMD говорит об улучшениях, как задержек, так и пропускной способности. Видимо, речь идет о средних значениях, так как подобная архитектура позволяет сблизить задержки для всех ядер и сделать их более предсказуемыми.
Уже сочетание столь необычного дизайна и преимуществ технологии производства, дает Zen 2 значительные улучшения по производительности, энергопотреблению и плотности транзисторов по сравнению с предыдущим поколением Zen. Такая модульная конструкция также может сократить операционные затраты на поддержку ЦОД и снизить потребность в охлаждении. Впрочем, есть и потенциальные недостатки — внутричиповые соединения в большом кристалле всегда будут быстрее, чем та же Infinity Fabric, пусть и улучшенная. Но обо всем этом мы подробно поговорим уже при практическом исследовании возможностей Zen 2, когда будут известны все детали организации подсистемы памяти, кэширования данных и т. д.
В числе других преимуществ Zen 2, по сравнению с архитектурой первого поколения, можно отметить: улучшенный конвейер, эффективнее поставляющий данные вычислительным движкам, усовершенствования по предсказанию ветвлений и предварительной выборке данных, оптимизированный кэш инструкций и увеличенный объем кэш-памяти.

Также специалисты AMD не обошли вниманием и один из главных недостатков Zen — производительность вычислений с плавающей запятой. Во втором поколении микроархитектуры они удвоили емкость и увеличили пропускную способность загрузки и хранения для операций с плавающей запятой до 256-бит, а также увеличили пропускную способность внутренних потоков данных во всех режимах работы CPU.
Прирост производительности у новых процессоров ожидается как от повышения количества исполняемых операций за такт на каждом ядре, так и от увеличения количества ядер на сокет. AMD говорит чуть ли не о четырехкратном увеличении общей производительности новых серверных процессоров в вычислениях с плавающей запятой, по сравнению с первым поколением EPYC.

Обязательно нужно отметить и продвинутые функции безопасности новых процессоров: аппаратные модификации, противодействующие уязвимостям типа Spectre, миграция ПО на уровне дизайна и расширенные возможности по шифрованию данных в памяти.
Кроме рассказа о некоторых (далеко не всех интересующих нас!) особенностях Zen 2, представители компании AMD рассказали и о грядущем обновлении семейства серверных процессоров EPYC. Компания впервые продемонстрировала процессор нового поколения вживую и раскрыла первые подробности о производительности EPYC нового поколения, известных под кодовым именем «Rome».
Новая линейка EPYC будет состоять из моделей, имеющих до 64 ядер Zen 2 (восемь CPU-чиплетов по восемь ядер), имеющих увеличенную производительность (до четырех раз быстрее в операциях с плавающей запятой в пересчете на сокет), имеющих доступ к памяти при помощи восьмиканального контроллера DDR4-памяти с поддержкой до 4 ТБ на сокет и увеличенную пропускную способность подсистемы ввода/вывода.
Также это будет первый в отрасли x86-совместимый процессор, предназначенный для серверов, имеющий поддержку PCI Express 4.0 с удвоенной пропускной способностью, что позволит увеличить производительность дата-центров — в них также можно использовать ускорители вычислений Radeon Instinct MI60 для дополнительного ускорения некоторых типов вычислений.

Первые образцы семейства «Rome» уже предоставляются заказчикам, а массовая доступность обещана на 2019 год, эти CPU станут первыми в мире высокопроизводительными x86-совместимыми процессорами, произведенными по техпроцессу 7 нм.
Что еще более важно, компания объявила о совместимости с существующими платформами AMD EPYC первого поколения. Процессоры семейства «Rome» совместимы по разъему с существующими платформами EPYC «Naples» и будут совместимы также и с будущим поколением EPYC «Milan» на основе архитектуры Zen 3, что серьезно упрощает разработку серверов, основанных на решениях AMD, позволяя использовать существующий дизайн в будущем, сократив затраты. Для обновления существующих серверов будет достаточно сменить лишь сами процессоры. Подобный подход очень поможет AMD забрать некоторую часть рынка у Intel. Жаль, что более-менее точных дат доступности новых EPYC нет, было озвучено только их появление в 2019 году.
Зато компания AMD впервые предложила оценить производительность своих процессоров EPYC следующего поколения. Журналистам показали сравнение производительности двухсокетной системы Intel Xeon Platinum 8180M, которая позволяет использовать до 3 ТБ памяти и предоставляет 96 линий PCIe 3.0, тогда как односокетная «Rome» позволяет использовать 4 ТБ памяти и дает до 128 линий PCIe 4.0 с вдвое большей пропускной способностью.
В итоге, предсерийная версия процессора EPYC нового поколения в ходе выполнения интенсивной вычислительной нагрузки в стандартном тесте C-Ray пусть и немного, но все же обошла систему с двумя топовыми процессорами Intel Xeon. То есть, предложение компании AMD на одном сокете даже лучше предложения конкурента на двух сокетах — неплохой результат!
Сейчас компания активно работает для обеспечения выхода семейства серверных процессоров EPYC под кодовым именем «Rome» на рынок. После этого, AMD планирует выпустить процессоры на архитектуре Zen 3, при производстве которых будет использоваться уже улучшенный техпроцесс 7 нм с применением EUV-литографии. Они должны появиться где-то в 2020 году. А затем настанет время и Zen 4, которые, возможно, будут рассчитаны уже на совершенно другой тип памяти. Но вот о них еще точно очень рано рассуждать.
Ускорители вычислений Radeon Instinct на основе Vega 7 нм
С выпуском Radeon Instinct MI25, компания AMD ранее уже вступила в борьбу за место под солнцем в сфере применения графических процессоров в системах облачных и высокопроизводительных вычислений, применениях искусственного интеллекта и т. п. К 2021 году, по оценкам AMD, объем рынка использования GPU в ЦОД составит порядка 12 млрд долларов, поэтому всем очень хочется отхватить максимальную его часть. На данный момент Nvidia является явным лидером на этом рынке, и даже Intel решилась разработать новый дискретный GPU, что тоже показывает перспективность рынка.
На мероприятии Next Horizon, компания AMD анонсировала новые ускорители вычислений AMD Radeon Instinct моделей MI60 и MI50, которые основаны на первом в мире GPU, также созданном при помощи техпроцесса 7 нм — новом варианте чипа Vega. Эти решения специально созданы для применения в области глубинного обучения, высокопроизводительных вычислений и профессиональной визуализации. Они обеспечат максимальную вычислительную производительность в новом поколении задач: масштабных симуляциях, исследованиях изменения климата, вычислительной биологии, медицинских задачах и многих других.

Как мы ранее уже говорили, новая технология производства с технологическими нормами 7 нм позволяет увеличить плотность транзисторов до двух раз по сравнению с ранее освоенными техпроцессами компании TSMC. Благодаря более совершенному техпроцессу, новый GPU получился значительно меньше по размеру, по сравнению с предшественником: 331 мм² против 484 мм², и это — при явном улучшении его возможностей и характеристик. Вот наглядное сравнение площади чипов Vega прошлого и нового поколений:

Новый вариант графического процессора компании AMD имеет площадь 331 мм² при 13,2 млрд транзисторов (сравните с 13,6 млрд транзисторов при 545 мм² у TU104 их конкурента, который использует техпроцесс 12 нм той же самой TSMC). Разница по плотности транзисторов на практике получилась может и не в два раза, но все равно весьма значительной.
Также нас сильно интересует увеличение производительности и улучшение энергоэффективности. AMD обещают до 25% прироста в скорости при том же потреблении энергии при переходе на 7 нм, что не очень впечатляет. Зато можно добиться вдвое меньшего потребления при той же производительности, что уже повеселее. Явно бы нужен конкурент для компактной Tesla T4, потребляющей очень мало энергии, но пока что такой вариант Radeon Instinct не был анонсирован.
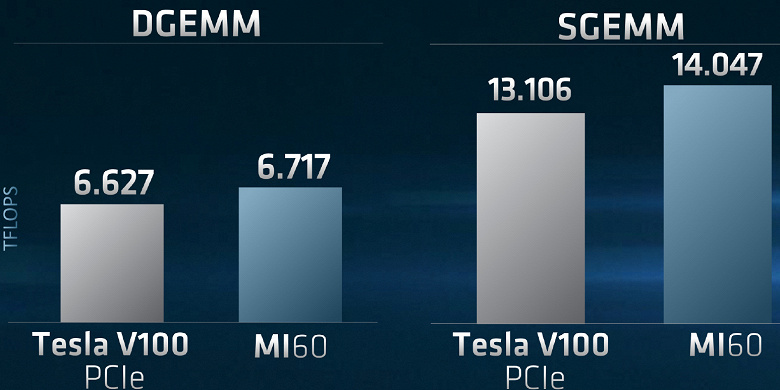
Архитектурно графический процессор Vega при переходе на техпроцесс 7 нм практически не изменился, хотя некоторые модификации в нем все же сделали — и они предназначены именно для использования этого GPU в ЦОД и при прочих высокопроизводительных вычислениях. По FP64- и FP32-производительности AMD называет новинку быстрейшим GPU в мире, и с подобной оговоркой по точности вычислений это действительно так, вот подтверждение в реальных тестах:
Улучшенная архитектура Vega специально предназначена для различных вычислений, включая столь модное сейчас глубокое обучение. Нет, специализированных блоков, вроде NPU или тензорных ядер в Vega не добавили, зато новый графический процессор умеет увеличивать производительность вычислений при сниженной точности, в отличие от предыдущего варианта этого GPU.
Ускорители Radeon Instinct MI60 и MI50 обладают более гибкими возможностями вычислений с различной точностью, что расширяет спектр их применения, включая HPC и приложения для глубокого обучения. Vega 7 нм специально сделали для того, чтобы эффективно справляться с такими задачами, как тренировка и инференс нейронных сетей при обеспечении более высокой производительности в вычислениях с плавающей запятой с улучшенной эффективностью.

Вариант Vega 7 нм получил значительно более высокую производительность FP64-вычислений — с половинной скоростью относительно FP32 (его предшественник имеет лишь 1/16 темп), а также поддержку новых типов вычислений с пониженной точностью: INT8 и INT4, важных для обучения и инференса нейронных сетей, когда не нужна более высокая точность. Соответственно, новые Radeon Instinct способны выполнять INT4-операции с вчетверо большей производительностью, по сравнению с FP16/INT16, но гибкость этих возможностей пока не раскрывается.
Все, что известно на данный момент, это пиковые значения производительности: 7,4 терафлопс для FP64, 14,7 терафлопс для FP32 и 118 TOPS для INT4. В итоге, MI60 стал самыми быстрым в мире ускорителем при вычислениях с двойной точностью, и эти возможности позволят исследователям более эффективно работать в приложениях HPC широкого спектра, включая энергетику, финансы, автомобилестроение, аэрокосмическую отрасль и т. д.
В свою очередь, младшая модель Radeon Instinct MI50 обладает лишь чуть меньшей скоростью вычислений, обеспечивая пиковую производительность FP64-операций на уровне 6,7 терафлопс, также являясь эффективным решением для широкого спектра задач глубокого обучения, которое подходит и для поддержки виртуальных рабочих столов, конфигураций Desktop-as-a-Service и облачных сред.

Что касается реальной производительности, то AMD привели несколько результатов в общепринятых тестах, синтетических и приближенных к реальности. Так в синтетике было наглядно показано преимущество новинок по FP64-вычислениям — MI60 оказался более чем в 8 раз быстрее предыдущего ускорителя компании MI25.

А в столь важных в современном мире задачах глубокого обучения с применением нейросетей разница пусть и не такая впечатляющая, но преимущество над MI25 в 2,8 раз нельзя назвать низким. Оговоримся, что в данном конкретном тесте речь идет о FP16-вычислениях, с которыми Vega 7 нм справляется вдвое быстрее предшественницы при равной тактовой частоте.
Кроме этого, системы на новых Radeon Instinct MI60 хорошо масштабируются — при объединении возможностей восьми GPU в таких задачах, прирост производительности составляет 7,64 раза — почти линейный. Но пока что AMD все время сравнивает новинку с MI25, а что если сравнить производительность в подобных задачах со злостным конкурентом в виде Nvidia Tesla V100?

Вроде бы все хорошо — значительно менее сложный чип Vega 7 нм показывает почти такую же скорость, что и топовый GV100, да еще на поле последнего — в задаче глубокого обучения. На слайде AMD указано, что производительность Tesla V100 в этой задаче составляет 350 изображений в секунду при тренировке ResNet-50. А у MI60 лишь чуть меньше — 334 изображения/сек.
Вроде бы неплохо — лишь чуть ниже, но ведь если использовать возможности тензорных ядер на GV100, то результат конкурента превысит 1000 изображений/сек. Да, представители AMD уточняют, что они рассматривали в данном случае только FP32-операции для достижения более высокой точности, но ведь на практике для подобной обработки изображений вполне хватает и FP16 — в очень большом количестве случаев. Более того — чуть выше они же сравнивали MI25 и MI60 именно при такой точности!
Оставим это на совести подготовивших слайды, и поговорим об энергоэффективности. В решениях для суперкомпьютеров и ЦОД это зачастую важнее даже чем пиковая производительность. Получается, что даже применение техпроцесса 7 нм не позволило AMD получить преимущество перед Tesla V100, потребляющей примерно столько же энергии. Возможно, лучше было бы выпустить что-то более компактное и с меньшими частотой и энергопотреблением, чтобы улучшить энергоэффективность. В некоторых случаях, вроде задач глубокого обучения больше подошел бы иной форм-фактор — предназначенный специально для высокоплотных решений, вроде Tesla T4. Если сравнивать MI50/MI60 с T4 по энергоэффективности в таких задачах, то ускоритель Nvidia выглядит куда более интересным.
Но и для новой Vega есть своя ниша — этот GPU лучше подойдет для задач, в которых обязательно нужна FP32- и FP64-точность. Но нам кажется, для реального прорыва GPU AMD в рынок высокопроизводительных решений и ЦОД, нужен продукт, серьезно превосходящий конкурента по каким-то важным параметрам: производительности, энергоэффективности или соотношению цены и производительности. По первым двум новая Vega лишь дотянулась до конкурента, но у AMD есть шанс превзойти Nvidia по соотношению цены и скорости, если новый техпроцесс будет достаточно отлажен и позволит массовый выпуск этого продукта по сравнительно невысокой цене.
Впрочем, еще одним из важнейших преимуществ новых ускорителей Radeon Instinct MI60 и MI50 остается высокоскоростная память типа HBM2 (High-Bandwidth Memory второго поколения). Представленный в начале ноября GPU имеет четыре контроллера HBM2-памяти, в отличие от двух у предшественника, что вместе с быстрой памятью привело к росту ПСП до 1 ТБ/с, что лучше, чем у топового решения конкурента в виде GV100.
Что очень важно для высокопроизводительных вычислений, новинка поддерживает коррекцию ошибок ECC — впервые за несколько лет для компании AMD. Radeon Instinct MI60 содержит 32 ГБ памяти HBM2, а Radeon Instinct MI50 — 16 ГБ такой памяти. Оба решения поддерживают аппаратную коррекцию ошибок ECC и технологии RAS (Reliability, Accessibility, Serviceability), критически важные для получения точных результатов вычислений в HPC-средах.
Также новинка AMD является первым в мире GPU с поддержкой новой версии PCI Express 4.0, которая способна передавать данные со скоростью 64 гигабит/с в обе стороны — до двух раз быстрее, по сравнению с другими типами соединения CPU и GPU. Новый GPU поддерживает межчиповые соединения Infinity Fabric новой версии, служащие для объединения возможностей нескольких GPU со скоростью передачи данных до шести раз быстрее, чем при использовании PCI Express 3.0 — на скорости 100 гигабит/с на канал. На каждой карте есть два канала, поэтому общая пропускная способность составляет 200 гигабит/с, а объединить можно до четырех GPU.

А еще новая Vega поддерживает третье поколение аппаратной виртуализации AMD, разделяя возможности одного GPU на виртуальные машины количеством до 16, а одна виртуальная машина может использовать до восьми GPU. При этом, нет лишних затрат производительности на программную обработку, так как технология AMD MxGPU является единственной системой аппаратной виртуализации GPU, основанной на стандартной технологии SR-IOV (Single Root I/O Virtualization), обеспечивающей безопасность в виртуальных облачных средах.
Кроме аппаратной части, всегда очень важна и программная поддержка — особенно в сфере применения GPU в неграфических вычислениях. Вместе с двумя новыми Radeon Instinct, компания AMD также представила и вторую версию своей открытой программной платформы ROCm для ускоренных вычислений, разработанной для создания высокопроизводительных гетерогенных компьютерных систем.
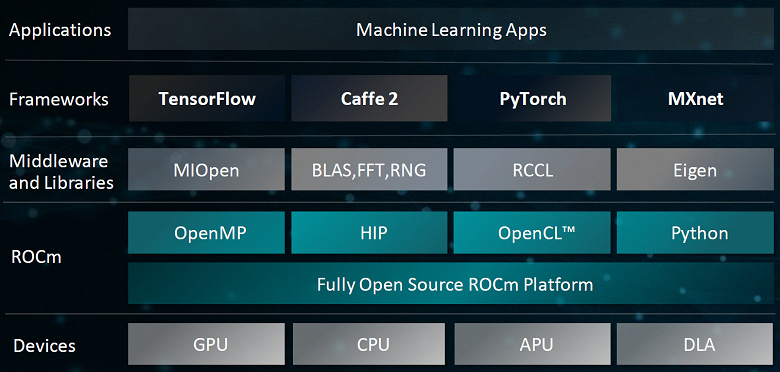
Естественно, что ROCm 2.0 поддерживает все архитектурные особенности новых ускорителей, включая оптимизированные операции глубокого обучения (DLOPS), а также отличается обновленными математическими библиотеками, поддержкой 64-битных систем Linux (включая CentOS, RHEL и Ubuntu), оптимизацией существующих компонентов и поддержкой новейших версий популярных сред глубокого обучения, включая TensorFlow 1.11, PyTorch (Caffe2) и другие.
Нам остается рассказать лишь о доступности новых продуктов. Как и было обещано представителями AMD еще в начале года, поставки ускорителей Radeon Instinct MI60 должны начаться в последнем квартале 2018 года. Новая версия открытой программной платформы ROCm 2.0 также появится в доступе в конце года. AMD пока что не обозначила цены, но при столь свежем и недешевом техпроцессе она вряд ли будет низкой. С другой стороны, им нужно сражаться с Nvidia и цена точно должна быть ниже, чем у конкурирующего решения Tesla V100. Более доступный вариант Radeon Instinct MI50 станет доступен в конце первого квартала следующего года и предложит менее дорогой доступ ко всем возможностям обновленного процессора Vega.
Новые горизонты AMD вырисовываются все более четко
Подводя итоги мероприятия, отметим, что на Next Horizon компания AMD раскрыла некоторые особенности архитектуры Zen 2, строения следующего поколения серверных процессоров EPYC, а также представила новые модели решений Radeon Instinct для ЦОД, основанные на улучшенном GPU Vega. Одним из главных преимуществ всех новых решений компании должно стать применение техпроцесса 7 нм — первыми в индустрии (для столь сложных CPU и GPU).
Сразу несколько решений компании AMD, использующие этот техпроцесс, в настоящее время находятся в разработке, в том числе следующее поколение серверных процессоров EPYC и ускорители вычислений Radeon Instinct. Обе серии продуктов были представлены компанией AMD на мероприятии и довольно скоро станут доступны для заказа. Все это явно настраивает на позитивный лад и продолжает успешный тренд AMD последних лет, когда компания укрепляет свои позиции практически по всем фронтам.
Показанные новинки предназначены для дата-центров, и это важно как для самой компании, так и для индустрии — именно у них есть определенное преимущество, ведь сейчас только AMD делает дизайн как CPU, так и GPU, предназначенных специально для дата-центров с оглядкой на возможности этих различных вычислительных процессоров при их совместной работе. И это преимущество будет нивелировано только в будущем, когда та же Intel выведет на рынок собственные графические процессоры, разработкой которых они сейчас занимаются.

Оптимизация конкретно под ЦОД важна, ведь устаревшие архитектуры GPU имеют ограниченные возможности и не могут достаточно эффективно выполнять обработку и анализ огромных объемов данных в составе дата-центров. А новые ускорители Radeon Instinct получили многочисленные улучшения, нацеленные специально на типичные задачи ЦОД. Модели MI60 и MI50 обладают повышенной вычислительной производительностью как в привычных FP32- и FP64-вычислениях, так и дополнительно ускоряют вычисления со сниженной точностью, имеют возможность высокоскоростного подключения карт друг к другу и к CPU, а также обеспечивают очень быстрый доступ к большому объему высокопроизводительной HBM2-памяти.
Аппаратная часть новых Radeon Instinct дополнена обновленной открытой программной платформой ROCm 2.0, и все это вместе обеспечивает поддержку самых требовательных приложений в сфере глубинного обучения и высокопроизводительных вычислений. Но так ли все прекрасно, как выглядит на слайдах компании?
Новая Vega действительно очень хороша тем, что в составе Radeon Instinct MI60 инженеры смогли выжать из уже немолодой архитектуры GCN столько производительности, что в FP32- и FP64-вычислениях обогнали такого сильного соперника как Tesla V100, потратив при этом аж на 40% меньше транзисторов! Хотя не нужно забывать, что GV100 содержит специализированные тензорные ядра и умеет параллельно выполнять не только 16 триллионов операций в секунду с FP32 точностью, но и столько же INT16-операций параллельно, что может быть востребовано в некоторых задачах.
Но в чисто FP32/FP64-вычислениях, Vega действительно выглядит очень сильно. Правда, выходит этот GPU где-то через полтора года после конкурента, для достижения паритета понадобилась крупная смена техпроцесса, а потребление энергии у конкурирующих решений практически одинаковое — порядка 300 Вт. При этом, у Tesla есть свои преимущества в виде тензорных ядер, обеспечивающих более высокую скорость в задачах глубокого обучения с пониженной точностью. И эту возможность конкурента в AMD забыли упомянуть при сравнении, так как точности FP16 якобы недостаточно, не забыв рассказать про ускорение INT8-операций при глубоком обучении для Vega. Да и при сравнении новинки с MI25 в AMD не гнушались FP16-точностью (иначе новая Vega просто не обошла бы старую аж в 2,8 раза).
Также, вполне логично предположить, что при неизменном количестве основных исполнительных блоков в Vega, столь высокая скорость была достигнута при помощи довольно высокой рабочей частоты GPU — порядка 1,8 ГГц, за которую нужно в основном благодарить техпроцесс 7 нм. Вполне вероятно, что AMD пришлось «тянуть» новый вариант Vega до уровня GV100, повышая частоту еще и еще, что и вызвало излишне высокое потребление энергии — оригинальная Vega скромным аппетитом никогда не отличалась, но при производстве новой версии применяется более совершенный техпроцесс, от которого мы ждали несколько большего…
Конечно, эти вопросы отнюдь не отменяют того, что Radeon Instinct MI60 является самым быстрым ускорителем по производительности FP32/FP64-вычислений на момент его объявления. Просто такие хитрости при сравнении с конкуре
Полный текст статьи читайте на iXBT
