NoSQL – коротко о главном

Основные понятия и типы данных NoSQL. Примеры использования.
Дата публикации: 24.01.2017 
|
Сергей Туленцев (TextMaster) |
 |
Меня зовут Сергей Туленцев, я уже несколько лет интересуюсь NoSQL базами данных и сегодня попытаюсь поделиться с вами знаниями и опытом.
Кому будет полезен этот доклад? Это обзорный доклад с претензией на структурированность. Если вы что-то где-то когда-то слышали про NoSQL, то через 40 минут вы будете знать гораздо больше, вы будете легче ориентироваться в терминах и более уверенно выбирать базы данных для своего проекта.
Поговорим также про типичные примеры применения и как не надо применять NoSQL базы данных.
Немного истории.

Впервые термин появляется в 1998 году — так чувак по имени Carlo Strozzi назвал свою реляционную базу данных. Она, однако, не предоставляла SQL-интерфейса для работы с собой, а вместо этого представляла из себя набор bash-скриптов, которые колбасили XML-файлы. Если верить википедии, то последний релиз этой базы данных вышел в 2010 году, и она как-то успешно работала. Я про нее узнал только в процессе подготовки к докладу, и, думаю, это хорошо, что я раньше про нее не узнал.
В 2009 году другие чуваки из Сан-Франциско организовывали конференцию для обсуждения новых распределенных баз данных, и им нужен был хэш-тег для твиттера, емкий короткий хэш-тег. Кто-то придумал хэш-тег NoSQL, чтобы подчеркнуть, что есть базы данных, в которых есть SQL, есть ACID и всякие крутые штуки, но мы будем говорить про другие базы данных, у которых ничего этого нет. Народу хэш-тег понравился, он вышел из-под контроля и до сих пор гуляет по интернету.
Термин NoSQL. Есть две трактовки: одна старая, другая новая. Оригинальная — это NoSQL, т.е., вообще, никакого SQL-а нет, а есть какой-то другой механизм, для работы с этой базой данных. И более новая трактовка — это «Not only SQL» — это не только SQL, т.е. может быть SQL, но есть что-то помимо.
Есть такой сайт nosql-database.org — это список разных баз данных NoSQL. Содержит описание, тип, ссылку на официальный проект, какие-то краткие важные вещи, которые стоит знать. Можете на досуге залезть почитать, но я про самые популярные сейчас расскажу.
Наиболее популярная классификация баз данных — это по типам данных.
Важный тип — это key/value store, или хранилище пар «ключ-значение».

Это самый густонаселенный тип, и он одновременно самый простой — обладает самым примитивным интерфейсом из всех. И, по идее, минимальный интерфейс для такой базы данных состоит всего из 3-х операций — get, set и delete. Наверное, есть какие-то базы данных, которые удовлетворяют этому интерфейсу, но обычно современные распространенные базы данных предоставляют больше плюшек, например, можно получить много ключей за раз, установить время жизни ключа, ну, соответственно, получить время жизни ключа, какие-нибудь сервисные команды для проверки статуса сервера…
Яркий представитель этого класса — это Memcashed. И сюда можно отнести с натяжкой Redis. Почему с натяжкой? Потому что у него на самом деле есть своя отдельная категория, в которой есть он один, эта категория называется «серверы структур данных». Он в этой категории находится, потому что у него несколько типов ключей и очень богатый набор команд (150 или больше), с помощью которых можно творить невообразимые вещи, но если эту категорию не учитывать, то так его можно отнести сюда — в key/value. Есть ещё Riak.
Документ-ориентированная база данных.

Это сильно усложненный вариант предыдущей категории. Эта добавленная сложность — она дает ещё и бонусы: теперь значения — это не какой-то непрозрачный текстовый блоб, с которым ничего нельзя делать, кроме того, что целиком прочитать или удалить, а теперь можно работать более тонко со значением. Если нам нужна только часть документа, можем ее прочитать или обновить только часть.
Обычно в базах данных такого типа присутствует богатая структура документа, т.е. дерево. Если грубо представить произвольный JSON, то любой JSON, который можно вообразить себе, можно записать в такую базу данных. И обычно реклама, пресс-релизы говорят — берете любой JSON, кладете в нашу базу данных и потом можно их анализировать. Обычно проблем не возникает только с первым пунктом, собственно с помещением JSON«а в базу данных, а дальше уже начинаются нюансы.
Типичные представители — MongoDB, CouchDB, ElasticSearch и др.
Колоночные базы данных.

Их сильная сторона в способности хранить большое количество данных с большим количеством атрибутов. Если у вас есть пара-тройка миллиардов записей, у каждой из которых по 300 атрибутов — это вам в колоночные базы данных.
Они немного по-другому хранят данные, нежели, например, реляционные базы данных — реляционки хранят по строкам, т.е. все атрибуты одной строки лежат рядом. Эти делают наоборот, они хранят отдельно колонки.
Есть файл — в нем хранятся все поля данной колонки из всех 3-х млрд. записей, хранятся все рядом. Соответственно, другая колонка хранится в другом файле. За счет этого они могут применять улучшенное сжатие за счет использования информации о типе данных колонки. Также это может ускорять запросы, если, нам, например, нужны 3 колонки из 300, то нам не обязательно грузить остальные 297.
Представители — это HBase, Cassandra, Vertica. У Vertica, кстати, SQL интерфейс, но это все равно колоночная БД.
Графовые базы данных.
Предназначены для обработки графов. На всякий случай напомню, что граф — это такая штука из дискретной математики — набор вершин, соединенных ребрами. Если посмотреть на любую интересную сложную задачу, то велик шанс, что мы там найдем граф. Например, социальные сети — это один большой граф. Дорожная сеть и прокладка маршрутов, рекомендация товаров.
Сила этих баз данных в том, что за счет своей специализации они могут эффективно выполнять всякие операции над графами, но также в силу той же специализации они не сильно распространены.
Все-таки не в каждой задаче есть граф, а если он там есть, то наверняка не очень большой и по ресурсам чаще всего бывает дешевле закодить на коленке какую-то обработку графов в приложении, нежели тащить в проект целую новую базу данных, за которой надо следить. Да и новая база данных доставляет целый ворох проблем. В моей практике так и было.
Мультимодельные базы данных.

Это такие базы данных, в которые одновременно входит две или более категорий из предыдущих.
Хочешь — пиши документы, хочешь — графы. FoundationDB, например, у нее основной слой — key/value и поверх этого слоя как-то прилажен SQL-слой. Я скачал себе дистрибутив и подписался на рассылку, они мне слали e-mail«ы каждую неделю, но так и не удалось мне поставить и запустить, пощупать как оно работает. И теперь уже не удастся, потому что пару месяцев назад, в марте, этих ребят купила компания Apple и сразу удалила все ссылки на скачку дистрибутива с сайта и теперь, видимо, этот продукт не будет в открытом доступе. Наверное, она работала неплохо, раз их купили.
Есть ещё две, которые у нас есть возможность пощупать, пока их кто-нибудь тоже не купил.
Еще есть классификация по способу хранения данных.

Есть базы данных, которые вообще никак данные не хранят, у них все хранится в памяти. Соответственно, любая перезагрузка процесса влечет за собой потерю данных. Здесь выхода два: либо не хранить там важные данные, которые нельзя восстановить, либо агрессивно применять репликацию. Из неважных данных — это, например, кэш, если у нас кэш куда-то пропадает, то приложение у нас не упадет, оно будет тормозить, пока кэш обратно не поднимется, не разогреется, но ничего смертельного не случится.
Иногда этот режим применяют для ускорения производительности. Взять, например, Redis. Он может обрабатывать десятки, сотни тысяч операций в секунду. И некоторые люди, конечно же, этим пользуются и нагружают его на всю катушку, но если он работает в режиме сохранения данных, т.е. либо сбрасывает снепшоты, либо лог пишет, то никакой диск с этим не справится, и работа с диском будет тормозить работу сервера. Поэтому можно применить такой трюк — берем систему из трех Redis«oв, один мастер, два его слейва. На мастере мы отключаем всю персистентность, и он вообще не касается диска, и туда мы пишем, потому что это мастер. На первом слейве мы тоже отключаем персистентность, и с него читаем. И на последнем слейве — его никто не трогает, не читает, и на нем мы включаем персистентность. И он, согласно настройкам, сохраняет данные на диск. В случае какой-то катастрофы, на нем будет копия данных, из которой можно восстановиться.
У Redis«a есть две модели, по которым он может сохранять данные на диск. Во-первых, он может сохранять снепшоты — это такой слепок базы данных на текущий момент. Чтобы этот слепок получился хороший, Redis форкается, создает копию своего процесса, чтобы слепок не был попорчен записями, которые происходят с мастером. И этот форк уже сохраняет этот снепшот, потому что в него никто не пишет.
Этот способ очень хорош, кроме того, что он требует дополнительной памяти. В зависимости от активности, которая происходит на сервере, вам может понадобиться до двукратного запаса памяти. Если у вас база данных 2 Гб, то вам надо держать ещё 2 Гб свободных для сохранения снепшотов.
Ещё можно настроить, чтобы он писал данные в лог — это другая техника. Т.е., когда ему приходит команда на запись, он ее быстро пишет сразу в лог и продолжает работу, т.е. эти 2 режима — снепшот и лог — они независимы, но можно настроить либо один, либо другой, либо оба вместе. В общем, этот лог тут только дописывается — в этом его плюс, а данные, которые уже попали в лог, они не изменяются и не могут быть поломаны. Поэтому, что обычно люди этот лог кладут на отдельный диск с отдельной головкой, и на этом диске никто, кроме Redis«а, ничего не делает и не трогает головку диска. И эта головка всегда показывает на конец файла. И запись новых операций в конец файла гораздо быстрее, чем если бы это происходило на обычной системе, где происходит другая активность.
Другие базы данных, например, MongoDB, — у них другая модель, называется in-place updates. У них есть одна копия базы данных, файлов данных, и они прямо «на живую» их изменяют. Это не очень безопасная практика, и если во время изменения, например, отключилось питание, то у вас база данных скарапчена, и сами виноваты. Поэтому несколько версий назад они приделали журналирование — так они называют контрольный лог, и даже сделали его включенным по умолчанию. Поэтому теперь Mongo можно запускать без двух реплик, и будет шанс, что она не попортит ваши данные.
Говоря про NoSQL нельзя упомянуть про CAP-теорему, это как 2 сапога — пара.
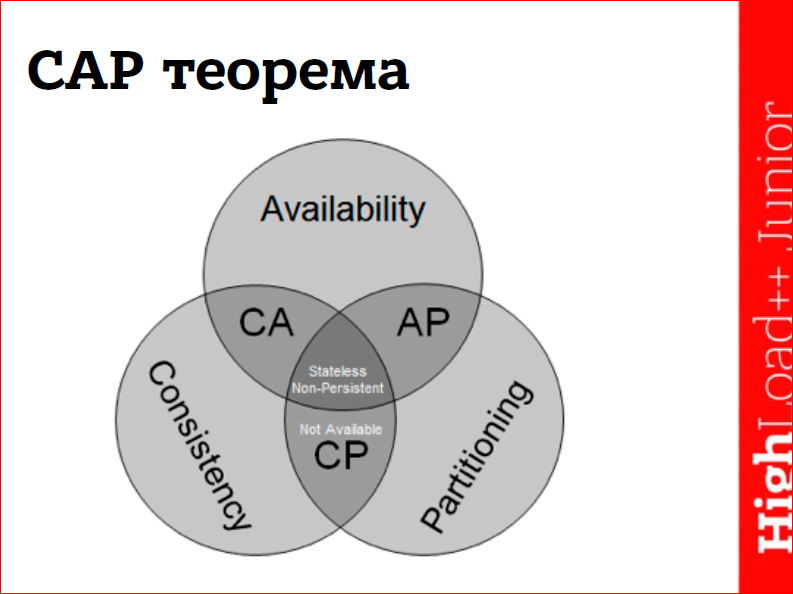
Теорема была сформулирована в году 2001-м, и некоторые считают, что она утратила актуальность и вообще не стоит про нее говорить, но упомянуть стоит. Она звучит так: распределенная система не может одновременно обладать более чем двумя из следующих трех характеристик — это доступность (availability), согласованность (consistency) и устойчивость к разрывам сети (partition tolerance).
На самом деле, выбор у нас только из двух вариантов — либо доступность, либо согласованность, потому что partition tolerance у нас везде есть по умолчанию. Мне не известны системы, которые не могли бы пережить разрыв сети, которые при разрыве сети самоуничтожались бы.
Доступность — это если у нас есть распределенная система, и мы обращаемся на любой ее узел и гарантированно получаем ответ. Если мы запрашиваем какие-то данные, то можем получить устаревшие версии этих данных, но мы получим данные, а не ошибку, или мы могли бы не достучаться до этого сервера. Если мы получили данные, то система доступна.
В противоположность этому система может быть согласована. Что означает согласованность? Если мы на одном узле записали какие-то данные и спустя некоторое время на другом узле пытаемся прочитать эти данные, если система согласована, мы получим новую версию данных, которую мы записали в другом месте.
Соответственно, распределенные системы любят относить себя к одному из двух лагерей либо на AP, либо на CP.

На самом деле есть третий секретный класс — это просто P, но ни один производитель базы данных не любит признаваться, что его система такая, а не из этих двух. То есть, если она просто P — она не обладает ни доступностью, ни согласованностью.
Соответственно, если система называет себя CP (т.е. consistency и partition tolerance), то при разрыве (если у нас есть кластер, и он разнесен, например, по двум дата-центрам, и связь рвется между дата-центрами) как ведет себя консистентная система? Она, если мы обращаемся на узел, и узел видит, что он не может надежно обеспечить эту запись, что у него нет, например, связи с большинством узлов системы, то он просто откажет приложению в этой записи, и она не удастся. Когда потом связь восстановится, приложение может попробовать снова и у него может получится.
А если система называет себя AP, то она будет всеми силами стараться удовлетворить запросы приложения путем отдачи ему устаревших данных, она может принять себе запрос на запись и куда-то ее себе записать, чтобы потом выполнить на всем кластере. Здесь есть нюансы. Например, если у нас разделился кластер надвое, и мы пишем в обе части, то есть шанс, что мы получим конфликты, т.е. мы в одной части записали в один ключ одни данные, а в другом — другие, а когда связь восстанавливается, то возникает проблема — какая версия данных корректная?
Специально для AP систем придумали термин — Eventual consistency — в грубом переводе на русский это означает, если не было конфликтующих записей, то когда-нибудь попозже кластер придет в согласованное состояние, при этом не дается каких-то гарантий по конкретным промежуткам — когда-нибудь.
Но в реальной жизни не приходится рассчитывать на отсутствие конфликтов и надо заранее думать, как мы будем с ними бороться.
Самый простой вариант, если у нас есть 2 конфликтующие записи — это разрешить конфликт по времени, грубо говоря, последняя, сделанная позже всех запись выигрывает.
Ещё некоторые системы сваливают все это дело на приложения. Когда приложение пытается прочитать данные, и база данных видит, что есть конфликты, она возвращает приложению все конфликтующие версии, и приложение само, руководствуясь своей логикой, должно будет выбрать правильную версию и отдать ее базе данных.
Более умный подход — это использовать типы данных, при использовании которых возникновение конфликтов, если не невозможно, то очень сложно. Например, тип данных — множество. Если у нас есть разорванные кластеры, и мы в одной половине во множество добавляем член А, и в другой половине добавляем B и С. Когда связь восстанавливается, то смерживать эти записи очень легко, мы просто делаем объединение этих множеств, и у нас получается одно результирующее множество (A, B и С).
Ещё пример — счетчики. Мы можем независимо инкрементировать счетчики, и когда связь восстановится, то мы просто сложим их и получим результирующий счетчик. В базе данных Riak есть специальный термин — CRDT — расшифровывается как бесконфликтные реплицирующиеся типы данных. По аббревиатуре можете загуглить, если интересно.
Поговорим про использование NoSQL. Когда надо использовать?
-
Если вам нужна высокая масштабируемость.
Это одна из самых главных, если не самая главная причина использования такого типа баз данных, потому что за счет своей пониженной сложности они легче масштабируются. Если ранее основные тяготы по масштабированию ложились на приложение, например, у нас есть 20 мемкэшей, и приложение собирает их в один хэшринг, чтобы обеспечить безотказность и масштабируемость, то современные базы данных все делают за тебя, в некоторых не надо даже ничего настраивать. Просто запускаешь ноду, она сама находит кластер, вступает в него, скачивает часть данных и начинает отдавать часть данных. Таким образом мы достигаем желанной линейной масштабируемости — это тоже один из святых граалей мира NoSQL.
Линейная масштабируемость — это когда мы путем увеличения ресурсов кластера получаем пропорциональное увеличение характеристик кластера. Удвоили количество серверов — получили в два раза больше производительность. Если мы линейно масштабируемся — мы очень крутые.
-
Прототипирование — тоже важный пойнт.
Традиционно реляционные базы данных требуют некоторое количество обслуживания, как до начала, так и во время проекта. Т.е. до начала проекта нам желательно продумать схему базы данных, ее создать, запустить с ней базу данных, а потом, когда проект запущен и работает, могут прийти новые бизнес-требования, или мы обнаружим, что мы как-то ошибались, нам надо добавить колонку… Часто это блокирующая операция. Что это означает? Нам либо нужно класть приложение, т.е. выключать его на минутку, на несколько дней, зависит от сложности ситуации, либо вручную дирижировать процессом обновления схемы. Т.е. накатываем схему на слейв, апгрейдим его до мастера, переключаем на него всех остальных слейвов и на них по очереди тоже накатываем схему. А перед этим надо не забыть выкатить код, который умеет одновременно работать с новой и старой версией базы данных, чтобы ошибки из приложения не летели. Это все делается, но это морока. Зачем делать, когда можно не делать? Поэтому бессхемные базы данных, документ-ориентирование особо, они этим и привлекают, что можно просто начать использовать новую схему данных, и она просто появится в ваших файловых данных. Совсем безболезненно это пройдет в случае, если мы добавляем поля, грубо говоря. Если мы изменяем структуру старых полей, то частенько придется сделать миграцию данных, но все равно это сильно ускоряет и упрощает создание прототипа продукта. Можно за несколько часов на MongoDB накодить минимальный продукт, и когда получим первый раунд финансирования нормально на Postgres писать все это.
-
Высокая доступность — тоже классическая причина.
Мы разносим нашу базу данных по нескольким датацентрам: в Америке, в Европе, Японии, если вдруг в какой-то из них бьет молния, и он исчезает, то мы можем писать в другие датацентры, и доступная база данных нам это позволит.
-
Кэширование.
Здесь нечего говорить, про мемкэш все знаем, применяем. Некоторые товарищи извращаются и ставят Mongo как кэш перед реляционкой, т.е. у нас в реляционной базе данных хранятся данные, все такие нормализованные, а тут приложение делает запрос с 20-тью join«ами, получает результат и кладет его в Mongo, и далее отдает из Mongo. Profit.
-
Родственный случай с кэшированием — это буферизация.
Например, у нас в приложении льется огромный поток просмотров страниц, и нам надо их быстро считать. Если этот потом мы будем лить в реляционные базы данных, то любая база данных не выдержит, поэтому имеет больше смысла направить этот поток в Redis. Он очень быстро умеет работать со счетчиками и будет быстро считать. И уже из Redis«а можно раз в секунду, в 10 или в минуту, в зависимости от вашей самоуверенности, можно скидывать данные для сохранности в основную базу данных.
-
Очередь заданий — это сестра буферизации.
Если у нас есть на сайте форма регистрации пользователя, и во время регистрации пользователя нам надо отправить приветственный e-mail. Совершенно необязательно делать это во время обработки формы. Пользователю незачем ждать, пока мы отправим ему e-mail. Поэтому, когда мы получаем форму, мы кладем задание на отправку e-mail«а в очередь и возвращаем форму пользователю. Он продолжает пользоваться сайтом, а у нас в фоновом режиме какой-нибудь worker достанет это задание из очереди и отравит e-mail.
-
Хранилище бинарников.
Например, нам надо хранить фотки — это на самом деле очень сложная проблема, если у вас фоток очень много, а все социальные сети изобрели свой велосипед для хранения фоток. Но если мы ещё не facebook, а хранить файлы на локальной файловой системе мы не хотим или не можем, потому что их слишком много, то у нас есть несколько выходов. Например, можно воспользоваться сервисом по типу Amazon S3 и просто лить файлы туда. Или можно поднять локальный кластер с Riak«ом или Mongo и хранить файлы там.
Здесь надо смотреть на ограничение конкретных продуктов. Если я правильно помню, то у Riak«а рекомендации — не класть файлы больше 2–3-х Мб, у Mongo — жесткое ограничение в 16 Мб на документ, но у нее есть специальный механизм для хранения больших файлов, которые бьет файлы по 16 Мб и хранит эти части.
-
Про счетчики мы уже несколько раз говорили.
Если нам надо что-то быстро считать берем Redis, Riak или Casandra и считаем.
-
Эффективная оценка кардинальности множеств или в простонародьи — «считаем уников».
Если у нас есть лог просмотров страницы или действий пользователей, как нам узнать, сколько уникальных пользователей здесь участвует? Если эти данные лежат, например, в реляционной базе данных, мы делаем SELECT COUNT (DISTINCT) — и это сработает. Если это не в базе лежит, а просто лог веб-сервера, то мы можем либо какие-то скрипты натравить, либо положить в Hadoop и Hadoop«ом это посчитать.
У всех этих способов есть один недостаток — производительность просаживается пропорционально увеличению количества данных. Но не стоит отчаиваться на помощь нам придет математика. Есть алгоритм — называется HyperLogLog. Он позволяет радикально уменьшить время и память, требуемые на выполнение этой операции. По ссылке на слайде можете прочитать статью Salvatore (автора Redis«а), который рассказывает про этот алгоритм. Этот алгоритм предполагает, что нам не нужно знать с абсолютной точностью цифру, а мы можем допускать некоторую погрешность, и в этом алгоритме мы можем, используя всего 12 Кб памяти по умолчанию, оценивать кардинальность множеств с миллиардами членов с погрешностью 0,8%. Это константная память — она не будет больше, т.е. если у нас 2 млрд или 7 — она 12 Кб. Размер буфера влияет на точность, чем можно увеличить буфер и уменьшить погрешность. Детали по ссылке (на слайде).
-
Ещё один пример — это система управления контентом.
Для документных баз данных. Можно взять статью с контентом, с флажками и с настройками и записать ее, и использовать.
-
Полнотекстовый поиск.
В некоторых реляционных базах данных он встроен и базовые нужды он может удовлетворять, но если вам нужно что-то большее, то нужно брать Sphinx или ElasticSearch.
Как не надо использовать NoSQL базы данных?
-
Не надо в них хранить реляционные данные.
Если мы делаем социальную сеть или блог с системой комментариев, или систему с параллельными проектами, у этих систем нет единого фокуса точки зрения на данные. Мы можем смотреть на данные с разных сторон, можем сказать: «дай мне все проекты этого пользователя» или «дай мне всех участников этого проекта, или кто и когда изменял эти страницы», т.е. запросы могут быть совершенно различны, и бизнес-требования могут совершенно внезапно измениться. Хорошо бы, чтобы база данных была достаточно универсальна, чтобы обеспечить эти запросы. Можно постараться и блог или аналог Hacker News написать на Redis«е, но, мне кажется, это очень хрупкая структура, и любое дуновение бизнес-требований порушит все это.
-
В интернетах есть статья, называется «Почему вы никогда не должны использовать MongoDB» — автор Sarah Mei.
Она описывает идеальнейшее приложение для MongoDB — это база данных фильмов. Там есть сериалы, в сериалах — сезоны, в сезонах — эпизоды, в эпизодах — набор актеров, все это друг в друга вложено, хранится в одном документе, мгновенно достается — красота! И оно так было несколько месяцев, пока на одном из митингов заказчик не попросил её сделать возможность просмотра фильмографии актера, посмотрев все эпизоды, в которых он участвовал. Для реляционных баз данных — это тривиальная задача, но для структуры, которую они имели, это было невыполнимо, потому что актер — не самостоятельный объект, а он вложен в сериалы на 5 уровней вниз — достать его никакой возможности нет.
Можно переколбасить структуру данных и поднять актера на верхний уровень, а в объекте сезона хранить ссылки, но тогда мы теряем все прелести документной базы данных, потому что мы можем одним запросом поднять все данные, которые нам нужны. Теперь мы поднимаем ID«шники, и по этим ID«шникам надо дополнительно идти искать авторов. Этот один запрос им все сломал, всю радость.
-
Embedding — это когда документ может включать другие документы или массивы документов.

Здесь у нас гипотетический пример — документ статьи или поста в бложек. У поста есть автор, у автора есть e-mail, у поста есть комментарии, у комментария есть контент и автор. Там ещё можно многое наворотить — есть лайкеры… наворотить можно многое — было бы желание.
Это все выглядит хорошо на бумаге, но это сломается в тот же момент, когда ваш бложек попадет на крупный СМИ, например, на Хабр (не знаю насколько он крупный СМИ) — ваш бложек сломается сразу же, когда вам под пост нафигачат 10 тыс. комментов за 5 минут.
У нас в приложении в TextMaster«е была похожая ситуация. У нас есть сущность проекта, у проекта — документ, у документа — атрибуты. Изначально у нас все это хранилось вложено друг в друга, т.е. документы были вложены в проект и все это хранилось. Главной сущностью был проект. Все было хорошо пару недель.
Через 2 недели после начала эксплуатации у нас все это сломалось, мы вылезли за пределы лимита документов, и у нас появились новые запросы, которые эта структура не удовлетворяла. Нам в срочном порядке нужно было менять структуру данных и поднимать документ, т.е. выдирать его из проекта, поднимать его на верхний уровень и ещё несколько структур нам пришлось выдрать. Т.е. усердствовать с Embedding«ом не надо.
-
В противоположность излишнему Embedding-у — недостаточный Embedding.
Возьмем 1-ую строчку — это классический пример из туториалов по MongoDB — это теги к какому-нибудь посту. Эта структура, когда значением является массив, Mongo очень хорошо умеет с ним работать, мы можем эффективно искать все посты, например, «дай мне все посты с тегом «ruby», с тегом «ruby» и «nosql» или «ruby», у которого нет тега «nosql» — все что хочешь можно делать. Но присутствует избыточность данных, у нас один и тот же текст повторяется много раз, но теги — это вещь, в которой это не страшно. Если мы вышли из мира реляционных баз данных и решили делать все по-старому, то мы сделаем как во 2-ой строчке, мы будем хранить ID«шники тегов, а сами теги будут объектами верхнего уровня, в своей коллекции.

Здесь нет избыточности данных, но вместе с ней мы выплеснули и ребенка, т.е. мы теперь не можем искать посты по тексту тегов за один присест. Нам нужно вначале отдельно найти ID«ишники тегов по тексту и только после этого мы можем искать посты, т.е. минимум два запроса.
-
Неверно выбранный тип данных.
Это из серии «давай возьмем этот JSON, засериализуем его в строку и положим в строку». Положили — ок. Теперь мы не можем с ним ничего делать, потому что это не прозрачный блоб, и мы можем только целиком его вычитать, целиком перезаписать или целиком удалить.
-
Недостаточно продуманная схема данных.
На Stack Overflow (есть такой сайт для программистов) не счесть вопросов типа «у меня есть массивы 5-ти уровней вложенности, как мне теперь делать запросы по ней?». Каждый день такие вопросы встречаются. И ладно только запросы, потому что следующий вопрос «А как мне теперь менять эту структуру?». Т.е. люди, не думая, нафигачили каких-то данных и теперь не знают, что с ними делать. То, что по бумагам MongoDB — это бессхемная база данных — не значит, что над схемой думать не надо. Чуть-чуть надо.
Подытожим.

Очень полезно знать свою предметную область и пытаться предвидеть будущие запросы, которые могут возникнуть. В примере про сериалы, для заказчика — это было очевидно, что есть ценность в возможности видеть фильмографию актера. Если бы разработчики видели это тоже, то история сложилась бы по-другому. Полезно следить за новостями в мире баз данных. Технологии развиваются очень быстро, и буквально за несколько дней может возникнуть какая-нибудь штука, которая серьезно облегчит вам жизнь. В моем случае — это был тот алгоритм для подсчета уников. И не надо слишком доверять пресс-релизам и рекламе — везде все идеально, надо смотреть ещё на недостатки, здесь возможны варианты, кто-то ищет негативные отзывы по форумам, кто-то читает код, кто-то ждет 3-го service pack«a. Главное выбирать базу данных, исходя не только из достоинств, но и также из недостатков.
Контакты
Этот доклад — расшифровка одного из лучших выступлений на обучающей конференции разработчиков высоконагруженных систем HighLoad++ Junior.
Также некоторые из этих материалов используются в обучающем онлайн-курсе по разработке высоконагруженных систем HighLoad.Guide — это цепочка специально подобранных писем, статей, материалов, видео. Уже сейчас в учебнике более 30 уникальных материалов. Подключайтесь!
Ну и главная новость — начата подготовка весеннего фестиваля «Российские интернет-технологии», в который входит восемь конференций, включая HighLoad++ Junior. Будет ли обсуждаться NoSQL в этом году? Наверняка!
Полный текст статьи читайте на CMS Magazine
