Конференция Nvidia GTC 2018: платформы для высокопроизводительных вычислений
Введение
Вот уже почти с десяток лет каждой весной в калифорнийском городе Сан-Хосе проходит ежегодная конференция компании Nvidia. В этом году GPU Technology Conference 2018 посетили больше 8500 участников со всего мира, из них более 300 — представители прессы и аналитики. Экспозиции выставки содержат полторы сотни выставочных стендов, а в рамках конференции проводилось более 600 часов разнообразных выступлений на тему применения решений Nvidia в различных сферах.
В 2018 году конференция празднует свое девятилетие, и за прошедшее время она стала одним из наиболее заметных событий в индустрии, связанной с различными сферами, в которых применяются высокопроизводительные вычисления, вроде искусственного интеллекта, реалистичной графики и автопилотируемых автомобилей.

Наши читатели в курсе, что компания Nvidia вот уже несколько лет занимается далеко не только традиционным для них рынком игровых и профессиональных графических процессоров, они постоянно пробуют выходить и на другие рынки, открывая новые ниши. К примеру, в сфере процессоров для высокопроизводительных вычислений дела компании продвигаются очень неплохо, и этот рынок оказывает все большее влияние в том числе и на финансовые показатели компании. Ну, а решения для самоуправляемых автомобилей хоть пока и не получили должного распространения, но лишь по той причине, что до массового выпуска таких машин просто еще никто из производителей не дошел.
Тема графических применений продукции Nvidia на конференции GTC давно перестала быть главной, хотя немалую часть выставки и даже выступления главы компании и в этом году занимала трассировка лучей в реальном времени, но все же основной темой для Nvidia на GTC сейчас является применение ее решений в системах искусственного интеллекта и глубокого обучения, в частности. Технологии калифорнийской компании шагнули далеко за рамки ускорения рендеринга и обработки визуальных данных, и главной для них сейчас именно является вычислительная платформа для ускорения глубокого обучения. Об этом говорят и выставленные на входе самоуправляемые автомобили.

В прошлогоднем материале с GTC 2017 мы подробно писали о том, почему это важно именно сейчас. Вычислительные возможности серверов, компьютеров и смартфонов становятся все более впечатляющими, но это лишь теоретические возможности. Нужно научиться использовать их, сделав компьютеры умнее, чтобы они лучше распознавали голос и смысл, понимали обычную человеческую речь, точно определяли и распознавали образы, и делали многое другое. На GTC 2018 компания Nvidia, в лице ее бессменного президента Дженсена Хуанга, в очередной раз представила целую серию важных анонсов, увеличивающих возможности вычислительных платформ компании.
Nvidia каждый год улучшает производительность и функциональность своих решений, предназначенных для глубокого обучения, открывая все новые возможности по применению платформ, которые должны привести к изменениям в различных сферах: медицине, транспорте, науке и других. За прошедший почти десяток лет произошло два существенных изменения в политике Nvidia. Если раньше они были компанией, выпускающей в основном графические процессоры, пусть в том числе и для профессиональных задач, то затем они перешли к вычислительным решениям, анонсировав программно-аппаратную платформу CUDA, а позже стали компанией, которая занимается еще более высоким уровнем — искусственным интеллектом и полноценной платформой для автопилотирования.
Важно, что указанные нами рынки куда больше застоявшегося рынка игровых GPU, и потенциал для роста на них просто огромен. Можно взять автомобили, большинство которых в будущем должны стать автопилотируемыми, или другие решения с применением искусственного интеллекта — во всех них нужны вычислительные решения, максимально производительные и энергоэффективные. Посмотрев на финансовые отчеты Nvidia на протяжении нескольких лет, можно отметить несколько трендов, на которые мы указывали еще в прошлых годах. В сфере автомобильных решений есть не слишком большой, но все же прирост, а вот продажи решений для высокопроизводительных вычислений (серверов, дата-центров и других аналогичных применений) растут постоянно и уже выросли в несколько раз. Вполне понятно, что Nvidia вкладывает максимум ресурсов именно в эти сферы.
Искусственный интеллект уже сейчас в некоторых областях способен выполнять многие задачи точнее и быстрее человека, а дальше будет больше. В ближайшие годы должен продолжиться взрывной рост применения искусственного интеллекта во многих сферах. В медицине должен произойти рывок в повышении эффективности и точности диагностики с применением систем обработки данных, использующих искусственный интеллект. В установке правильных диагнозов и в процессе лечения системы ИИ должны серьезно облегчить и улучшить труд врачей. Добавим к медицине многочисленных роботов, автопилоты и многое другое, и получим новый дивный мир. Конечно же, переход этот будет плавным, но мы должны увидеть множество изменений еще при нашей жизни.
Почему все вообще происходит именно сейчас? Дело в том, что раньше содержать нейронные сети достаточных размеров было слишком дорого или даже невозможно, но вычислительные мощности современных систем растут, и немалый вклад в это внесла в том числе и Nvidia со своими вычислительными процессорами с весьма эффективными для этих задач блоками. Поэтому сейчас глубокое обучение и нейронные сети для решения своих задач может позволить себе уже куда больший круг компаний, даже небольших. Взрывной рост вычислительных возможностей дал возможность применения нейросетей во все большем количестве сфер и применений. А ведь сложность задач, которые ставят перед собой исследователи, постоянно растет, и каждый год требуется в несколько раз больше производительности.
Эксперты прогнозируют рост как внедрения технологий с использованием искусственного интеллекта, так и прибыли от продажи таких решений. Конечно, далеко не только продукты Nvidia будут применяться в высокопроизводительных системах, многие крупные компании выпустили собственные решения для ускорения задач глубокого обучения, но практика показывает, что у Nvidia сейчас весьма сильные позиции на этом рынке, и они даже еще не раскрыли весь свой потенциал. Компания занялась этой темой одной из первых, у них есть не просто отличный набор аппаратного обеспечения, но и полноценные платформы и продукты, готовые к применению и весьма эффективные в задачах с применением искусственного интеллекта.
А конференция GTC интересна тем, что это сейчас главное мероприятие для компании Nvidia и именно на нем делаются основные анонсы компании, связанные с рынком высокопроизводительных вычислений и искусственного интеллекта. К примеру, на прошлогодней выставке GTC 2017 были представлены: новая архитектура Volta и ускоритель Tesla V100 на его основе, линейка суперкомпьютерных систем Nvidia DGX, платформа для автомобилей Drive PX Xavier, применение возможностей искусственного интеллекта при трассировке лучей, институт глубокого обучения, платформа для умных городов Metropolis, имитатор роботов Isaac и референсные платформы для роботов. Все это довольно важно для индустрии, было хорошо ей воспринято и широко используется. А чем же порадовала GTC 2018? Сейчас расскажем.
Новости высокопроизводительных вычислений и глубокого обучения
Ученые, занимающиеся вычислениями, связанными с медициной, изучением климата, геологией и многим другим, предъявляют все более высокие требования к вычислительной мощности серверов, ведь расчеты в их задачах занимают по несколько дней даже на самых мощных серверах из ныне существующих. Им очень помогает не прекращающийся рост вычислительной мощи GPU, которые во многих задачах, поддающихся распараллеливанию, оказываются гораздо эффективнее систем на основе универсальных CPU, рост производительности которых несколько замедлился в последние годы. Неудивительно, что количество разработчиков ПО, использующих графические процессоры, за 5 лет увеличилось в 10 раз, а производительность самых быстрых 50 суперкомпьютеров в мире, использующих GPU, выросла в 15 раз.
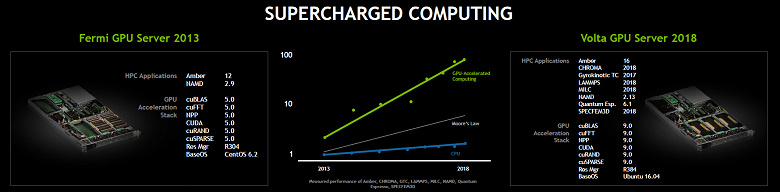
Если говорить о временном отрезке в пять лет, то в 2013 году Nvidia предложила рынку сервер на основе графических процессоров архитектуры Fermi, которые для своего времени были весьма неплохими и получили поддержку со стороны разработчиков ПО, а выход на рынок вычислительных процессоров на основе архитектуры Volta сопровождается как очередным ростом производительности, так и расширением поддержки со стороны разработчиков.
Применений для Volta придумано и разработано уже куда больше, а если сравнивать серверы на основе GPU с традиционными системами на основе CPU, то давайте приведем любимый фокус главы Nvidia, который любит сопоставлять их по энергоэффективности, стоимости и занимаемому в серверных помещениях физическому месту.

В частности, сравнимую производительность обеспечивают: сервер из 600 двухпроцессорных систем на основе CPU, потребляющий 360 кВт, и 40 систем с четырьмя Volta каждая, потребляющих совместно лишь 48 кВт. Получается, что схожие возможности и производительность в задачах, где GPU может заменить CPU, можно получить за 20% цены серверов на основе CPU, при в разы лучшей энергоэффективности и лишь при 1/7 от занимаемого CPU-серверными стойками места.
Так как GPU хороши в массовых вычислениях, то особенно высок спрос на их вычислительные мощности со стороны разработчиков, занимающихся системами искусственного интеллекта: нейросетями и т. д. Для них Nvidia предлагает полноценную ИИ-платформу, состоящую из вычислительных процессоров Tesla V100, готовых систем DGX-1 и DGX Station на основе этих GPU, имеющих разный уровень производительности, менее дорогих решений Titan V, обладающих поддержкой TensorRT и облачных платформ известных компаний.

Одним из самых интересных «аппаратных» анонсов на GTC 2018 стало объявление нового вычислительного решения Tesla V100, использующего удвоенный до 32 ГБ объем начиповой HBM2-памяти, который актуален в большом количестве требовательных к объему и скорости памяти задач глубокого обучения. Удвоенный объем памяти позволит тренировать большие по размеру модели нейросетей и получать преимущество в задачах, которые были ограничены ранее памятью объемом в 16 ГБ.
Новое вычислительное решение Tesla V100 32GB доступно сразу со дня анонса, а такие известные производители как Cray, Hewlett Packard Enterprise, IBM, Lenovo, Supermicro и Tyan начнут распространять системы на основе Tesla V100 32GB во втором квартале текущего года. Сервис Oracle Cloud Infrastructure также уже анонсировал планы по предложению своим клиентам возможностей новой Tesla V100 32 ГБ в облаке во второй половине года.

Но даже четырех топовых GPU в системе DGX-1 для некоторых применений оказалось мало, исследователи не отказались бы и от более мощных систем, так как «лишнюю» производительность им всегда есть куда потратить. Именно для них Nvidia анонсировала мощнейшую систему на основе графических процессоров Volta — DGX-2, в которой объединены возможности сразу 16 процессоров Tesla V100 с 32 ГБ памяти каждый.
Совместно с новой технологией межчиповых соединений NVSwitch, соединяющей до 16 ускорителей Tesla V100 в единое устройство с производительностью подсистемы памяти в 2,4 терабайта/с, возможности таких систем и вовсе будут казаться почти безграничными. NVSwitch расширяет возможности NVLink и предлагает в 5 раз большую пропускную способность по сравнению с лучшими из свитчей PCI Express и позволяет создавать системы с большим количеством соединенных друг с другом GPU в них.

Для того, чтобы объединить 16 графических процессоров, потребовалось создание специального чипа NVSwitch, который и обеспечивает подключение GPU друг к другу. Всего для объединения 16 GPU требуется 12 таких чипов. Кристалл NVSwitch достаточно сложен, он содержит 18 высокопроизводительных линий связи NVLink, состоит из 2 млрд. транзисторов и производится по техпроцессу 12 нм на тайваньской фабрике TSMC.
Нейросети становятся все более сложными и требуют обработки в разы больших объемов данных с каждым годом. Также появились некоторые новые техники, требующие большего количества GPU, соединенных друг с другом для обмена данными и синхронизации. Такие операции требуют передачи большого объема данных и высокой пропускной способности. Объединение мощи 16 GPU быстрой связью с пропускной способностью в 2,4 ТБ/с позволяет добиться в разы большей производительности.
Использование DGX-2 позволяет обойти ограничения по сложности и размерам модели, имеющиеся у традиционных вычислительных архитектур, убирает предыдущие ограничения по скорости передачи данных между чипами, и позволяет использовать наборы данных большего размера при все более ресурсоемких нагрузках, включающих параллельную тренировку нейросетей. ИИ-суперкомпьютер DGX-2, состоящий из 16 самых производительных вычислительных процессоров с ускорением ИИ, дает возможность тренировки вчетверо более крупных моделей при многократном ускорении, по сравнению с аналогичными системами, существующими сегодня.

Каждый из NVSwitch содержит 18 портов NVLink (50 ГБ/с на порт), на базовой плате их шесть штук вместе с восемью GPU Tesla V100, и две такие базовые платы могут объединяться в одно целое. Каждый из восьми GPU на одной плате соединен с каждым из шести NVSwitch одиночным NVLink каналом, а восемь портов каждого чипа NVSwitch используются для обмена данными с другой базовой платой. Соответственно, каждый из восьми GPU на плате с другими процессорами «общается» на скорости в 300 ГБ/с.

DGX-2 — наиболее производительное готовое решение на основе Tesla V100 и NVSwitch, предназначенное для задач глубокого обучения. Это первый одиночный сервер с вычислительной производительностью до двух петафлопс, заменяющий 300 обычных серверов, занимающих 15 стоек в дата-центрах при в 60 раз меньшем размере и в 18 раз большей энергоэффективности. Выглядит он как сравнительно небольшой ящик:

В целом получается система с 81 920 вычислительными ядрами, 512 ГБ быстрой HBM2-памяти с общей пропускной способностью в 14,4 ТБ/с и высочайшей производительностью в задачах, связанных с нейросетями — 2000 терафлопс для операций на тензорных ядрах. Скорость обмена данными между процессорами составляет 300 ГБ/с. Вот так выглядит DGX-2 в разобранном состоянии:

Хорошо видны 16 блоков с графическими процессорами и 12 блоков с NVSwitch. Остается добавить, что DGX-2 отличается энергопотреблением в 10 кВт и весит этот шкаф под 160 кг. По сравнению с системой DGX-1 на основе 16-гигабайтных версий V100, в некоторых задачах, где нужен большой объем памяти, переход на DGX-2 обеспечивает прирост скорости до 10 раз.
С ценой получилось довольно забавно — сначала Дженсен Хуанг показал публике слайд с ценой в 1,5 млн долларов, и когда все охнули, он быстренько поменял слайд уже на правильный, с перечеркнутой «ошибочной» ценой и указанной настоящей — 399 тысяч долларов, что уже куда приятнее полутора миллионов.

Публика не осталась без сравнения с традиционными серверами на основе CPU и в этот раз. Nvidia сравнивает DGX-2 с кластером из 300 двухпроцессорных серверов, стоящих 3 миллиона долларов и имеющих энергопотребление в 180 кВт. Неудивительно, что DGX-2 со значительно лучшей энергоэффективностью и в разы меньшей ценой имеет преимущество. Правда, это сравнение справедливо только для конкретных задач глубокого обучения, а не для всех подряд. Но такая мощь позволит тратить в несколько раз меньше времени и денег на обучение нейросетей, что бывает критично.
Поставки готовых DGX-2 систем ожидаются в третьем квартале этого года. Но и DGX-1 никуда не пропадет, вся линейка высокопроизводительных систем на основе GPU продолжает существовать. Более того, все «старые» системы получат новые ревизии с апгрейдом до 32-гигабайтных V100 и будут поставляться уже в обновленном виде.

DGX-2 — это первая система, использующая NVSwitch и позволяющая 16 процессорам системы использовать общую память. На такой системе разработчики могут тренировать нейросети на более сложных и больших массивах данных, используя более комплексные модели глубокого обучения. В результате новая система DGX-2 в некоторых задачах может быть в несколько раз быстрее DGX-1 на основе все той же архитектуры Volta, представленной в сентябре. Новинка включается в линейку продуктов DGX и становится на вершину этой серии вычислительных систем Nvidia.
Самое важное в DGX-2 то, что это — самое производительное готовое решение для ускорения задач, связанных с использованием возможностей искусственного интеллекта. Эта система упрощает масштабирование ИИ-задач построением самых крупных вычислительных кластеров для задач глубокого обучения, также с богатейшими возможностями для визуализации результатов. Использование готовой системы позволяет тратить меньше времени на решение задач по обеспечению работоспособности аппаратной и программной инфраструктуры, и решать задачи, напрямую связанные с искусственным интеллектом. Платформа Nvidia обеспечивает высокую надежность, а кроме этого, работоспособность DGX-2 поддерживается компанией Nvidia, имеющей богатый опыт по построению, разворачиванию и поддержке подобных систем.
Интересно, что такую систему клиенты не просили у компании, а ее задумали в Nvidia самостоятельно, чтобы создать новый сегмент рынка. На данный момент этот сегмент совсем небольшой, но разработка DGX-2 на основе NVSwitch — это помощь тем исследователям, кто заинтересован в разработке новых алгоритмов и приложений будущего. Вероятно, в Nvidia надеются на появление различных приложений на основе нейросетей, которые будут востребованы массами и потребуют больших вычислительных мощностей, которую Nvidia и предоставит в конечных продуктах.
Для задач глубокого обучения с применением нейросетей довольно важен и анонс по программной части — с апреля 2018 года решения Nvidia получили поддержку TensorRT 4, ONNX и WinML. А для того, чтобы получить возможность удобного использования нескольких объединенных систем, Nvidia объявила поддержку открытого ПО для автоматизации развертывания и масштабирования Kubernetes.
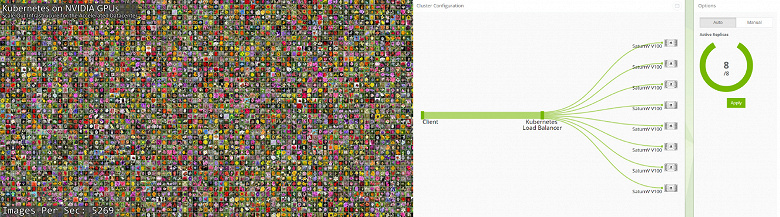
Оно позволяет использовать несколько физических или виртуальных вычислительных систем для одновременного выполнения одной задачи с балансировкой загрузки и автоматическим управлением кластером. На GTC было показано применение сразу восьми систем на основе процессоров Tesla V100 для определения нейросетью видов цветов на изображениях. Объединение вычислительных возможностей GPU с помощью Kubernetes позволило ускорить эту задачу в разы.
Вообще, платформа Nvidia AI Inference уже получила широчайшую поддержку в индустрии, самые известные компании используют эти решения в своих нейросетях для различных задач: здравоохранение, умные города, роботы, автопилоты, производство, распознавание изображений и речи и т. д.

И это совсем неудивительно, учитывая ускорение определения нейросетями в разы, десятки раз и сотни, по сравнению с универсальными процессорами. Все перечисленные компании используют решения Nvidia и это еще далеко не полный их список. Похоже, по крайней мере в ближайшем будущем Nvidia в сфере «ускорителей искусственного интеллекта» ждет вполне закономерный успех.
Трассировка лучей в реальном времени
Мы уже рассказывали об анонсе технологии трассировки лучей в реальном времени, исполняемой на графических процессорах Nvidia и получившей название RTX. Фактически, технологию анонсировали еще на игровой конференции Game Developers Conference, которая прошла неделей раньше GTC, но тогда говорили в основном про игровые ее применения в рамках нового графического API компании Microsoft — DXR. Но ведь эту технологию также можно использовать и в приложениях на основе Vulkan и Nvidia OptiX.

Многие разработчики с энтузиазмом восприняли новую технологию и сразу же выпустили несколько демонстрационных программ, показывающих возможности гибридного рендеринга, использующего растеризацию и трассировку лучей: физически точные отражения и преломления, а также тени не только от точечных источников света, реалистичное глобальное освещение и затенение, учитывающие особенности распространения света в природе.
Одной из самых впечатляющих оказалась демонстрация на тему популярного киносериала Star Wars, созданная на основе движка Unreal Engine, и исполняющаяся на четырех ускорителях Volta, имеющихся в составе DGX Station (мы попросили включить режим wireframe, чтобы убедиться в том, что нам показывают именно рендеринг в реальном времени):


Возможности трассировки лучей в реальном времени открывают множество новых алгоритмов, выдающих фотореалистичный результат, и в целом являются одним из важнейших шагов в компьютерной графике за последние годы. Это относится далеко не только к игровым приложениям, но и многим сферам профессиональной графики.
Именно для таких применений компания Nvidia и анонсировала на конференции GTC 2018 новое решение для профессиональной среды — Quadro GV100 GPU с поддержкой технологии Nvidia RTX, обеспечивающей трассировку лучей в реальном времени для разработчиков и дизайнеров.

Многие профессионалы в сфере развлечений и медиа нуждаются в точном расчете освещения, затенения и прозрачности. А еще лучше, чтобы это делалось как можно быстрее и ближе к реальному времени. Сочетание возможностей технологии RTX с мощнейшим аппаратным решением Quadro GV100 делает вычислительно интенсивные задачи трассировки лучей для профессиональных приложений возможными в реальном времени — как программируемые пиксельные шейдеры несколько лет назад. И оптимизация трассировки лучей RTX под архитектуру Volta помогла добиться ускорения сложного рендеринга до 10 раз, по сравнению с лучшими из многоядерных центральных процессоров.
Это важно потому, что профессиональные графические решения Nvidia Quadro применяются при создании сотен игровых проектов и видеороликов к ним, в теле- и киноиндустрии, а также других сферах развлечений, и при создании дизайна различных товаров и в архитектурных задачах. И все эти специалисты по графике, дизайнеры и архитекторы теперь смогут создавать еще более сложные и интерактивные сцены в фотореалистичном качестве с использованием рендеринга в реальном времени или близком к этому.

Новая Quadro GV100 использует обновленный чип архитектуры Volta, имеющий уже 32 ГБ локальной памяти стандарта HBM2 с коррекцией ошибок ECC, шириной шины в 4096 бит и пропускной способностью в 870 ГБ/с. GPU содержит 5120 вычислительных ядер и 640 тензорных ядер, что обеспечивает производительность в 14,8/7,4 терафлопс при одинарной/двойной точности вычислений. А для быстрой работы системы шумоподавления OptiX AI, встроенной в Nvidia RTX, обеспечивается скорость вычислений в 118,5 терафлопс, что в десятки, а то и сотню раз выше, чем у любого CPU. Максимальное потребление энергии при этом составляет 250 Вт.
Удобно, что можно объединить две Quadro GV100 при помощи интерфейса Nvidia NVLink второго поколения, обеспечивающего работу пары процессоров в виде одного устройства. Тогда в объединенной системе будет 10240 вычислительных ядер, обеспечивающих 236 терафлопс специализированных операций глубокого обучения. Мосты NVLink для соединения двух плат Quadro продаются отдельно и они позволяют объединить мощь пары GV100 для увеличения производительности и объема локальной видеопамяти — при поддержке этой технологии со стороны приложения, видеоподсистема на основе двух GV100 будет иметь 64 ГБ общей видеопамяти. Естественно, ПСП ко второй половине памяти будет несколько ниже —, но благодаря NVLink второго поколения обеспечивается вполне приличная скорость передачи до 200 ГБ/с.
Новая плата Quadro предлагает четыре разъема DisplayPort 1.4 с поддержкой передачи звука и HDCP 2.2, поддержку стереовывода, поддержку технологий GPUDirect, NVLink (для соединения пары Quadro в единую систему) и Quadro Sync II. К карте можно одновременно подключить четыре дисплея с разрешением 4096×2160 пикселей и частотой обновления до 120 Гц или четыре дисплея с разрешением 5120×2880 пикселей и частотой 60 Гц или два дисплея с разрешением 7680×4320 при 60 Гц.
Из других достоинств Quadro GV100 выделим широкую поддержку различных API — разработчики могут воспользоваться возможностями трассировки лучей RTX через интерфейс Nvidia OptiX, новый API для трассировки лучей Microsoft DirectX Raytracing, а в будущем и еще один новый API Vulkan (расширения для поддержки RTX пока находятся в разработке). Реалистичное освещение, отражения, преломления и тени, рассчитываемые при помощи трассировки лучей, использующей шумопонижение с использованием искусственного интеллекта из OptiX, обеспечивает высокую производительность при фотореалистичной картинке, а также отличную масштабируемость при поддержке 64 ГБ памяти, необходимых для рендеринга самых сложных сцен.

В своем ключевом выступлении Дженсен Хуанг снова не обошелся без излюбленного сравнения серверов на GPU с системами на CPU — в этот раз в задаче трассировки лучей. Традиционную ферму с 280 двухпроцессорными серверами в 14 стойках и потреблением в 168 кВт по производительности в этой специализированной задаче он приравнял к паре стоек из 14 серверов с четырехпроцессорными GPU-системами, потребляющих всего 24 кВт. То есть, в графических задачах, где вместо CPU применимы GPU, можно получить ту же скорость при 1/7 энергопотреблении и 1/7 занимаемого серверами физического места. А главное — всего лишь при 20% от стоимости аналогичной CPU-системы.
Хотя сама по себе технология Nvidia RTX была анонсирована на игровой конференции GDC, на GTC компания анонсировала ее поддержку в более чем двух десятках приложений профессиональной графики, которые используют миллионы пользователей серьезного ПО. Неудивительно, что у Nvidia уже есть куча партнеров по применению RTX в игровых движках, профессиональных приложениях, утилитах и т. п. И особенно довольны таким сотрудничеством компании, работающие с графикой для киноиндустрии, ведь они могут получить прирост скорости в несколько раз, пусть даже и не в финальном рендеринге. Среди компаний и их продуктов можно выделить Autodesk, Blender, V-Ray, Octane Render, Renderman и другие.

Доступность нового профессионального решения Quadro GV100 объявлена прямо со дня анонса — приобрести новинку можно на сайте компании, а в течение месяца эта модель появилась и у известных производителей рабочих станций, включая Dell EMC, HP, Lenovo и Fujitsu, а также авторизованных дистрибьюторов: PNY Technologies для Северной Америки и Европы, ELSA/Ryoyo для Японии и Leadtek для Азии. Рекомендованная цена решения составляет $9000.
Почему Nvidia заговорила о трассировке лучей для профессиональных и для игровых применений именно сейчас, ведь до реального времени еще далековато — если целиться на качественную картинку, то даже для игрового применения (на примере демки Star Wars) нужно несколько самых мощных видеокарт. Все дело в том, что решения архитектуры Volta не только аппаратно оптимизированы в том числе для задач трассировки лучей, но и могут выполнять очень быстрые алгоритмы шумоподавления, использующие искусственный интеллект и очень быстро выполняющиеся именно на тензорных ядрах, впервые появившихся в GV100.

Удаление шума при помощи алгоритма с применением искусственного интеллекта позволяет гораздо быстрее получить картинку приемлемого качества — хорошо натренированная нейросеть «дорисовывает» недостающие (еще не рассчитанные при помощи трассировки лучей) значения пикселей довольно точно, и человеческий глаз с трудом найдет в изображении изъяны. Даже в 10 раз меньшее количество трассировок лучей при использовании AI Denoiser делает картинку очень близкой к совершенству.

На выставочном стенде компании Nvidia был показан в том числе и пример с рендерингом при помощи бета-версии рендерера V-Ray, использующего новые возможности Volta по ускорению трассировки лучей — сцена из трейлера Destiny 2 предоставлена компаниями Activision и Bungie. И автор материала лично убедился в том, что отрисовка на GPU с использованием шумоподавления при помощи ИИ делает картинку довольно качественной буквально за пару-тройку секунд, тогда как CPU за это время отрисовывает лишь очень малую часть пикселей. И это стало доступным для всех желающих вместе с Quadro GV100.
Обучение автопилотов в виртуальном мире
Известно, что компания Nvidia давно занимается разработкой решений, предназначенных для автопилотируемых транспортных средств, и даже является одним из лидеров в этой сфере, если рассматривать независимые компании, предлагающие свои разработки всем заинтересованным сторонам. Естественно, что на GTC 2018 не могли обойти вниманием тему автопилотирования, ведь в не таком уж далеком будущем практически все движущиеся по дорогам (а еще наверняка и в воздухе и на воде) средства обретут возможность самостоятельного управления при помощи искусственного интеллекта: личные автомобили, роботакси, грузовики, автобусы, тракторы и многое другое. Очень много информации на эту тему мы дали в отчете с европейской GTC 2017, прошедшей в Мюнхене.
Компания Nvidia играет значимую роль в глобальном развитии автопилотов, предоставляя заинтересованным разработчикам полноценную платформу Drive, которая способна собирать и обрабатывать необходимые данные, тренировать нейросети, проводить симуляции и, собственно, управлять транспортным средством. Платформа для автопилотирования в процессе работы занимается решением множества задач, включая определение объектов, расстояния до них, скорость и направление их движения, нахождение свободного места и прокладывание маршрута, создание карты объектов по данным с камер, лидаров и других датчиков, учет погодных условий и многих других.

Все эти задачи требуют обработки просто огромного количества тестовых данных, и автопилот учится на их основе: чем больше — тем лучше будет его качество. Получение четких и верных исходных данных для нейросетей жизненно необходимо, ведь они основаны не на четком следовании программе, а действуют на основе изученных ранее данных. Как было метко сказано Дженсеном на конференции: «Данные — это новые исходные коды», и это действительно так. Чем больше у исследователя качественных данных для обучения, тем «умнее» будет искусственный интеллект, обученный на их основе.

Поначалу Drive Xavier будет единственным решением с высшим уровнем безопасности ASIL D (Automotive Safety Integrity Level D), определяющим параметры серьезности риска, вероятности воздействия и управляемости. Но Nvidia также уже представила и решение для автопилотов будущего, которое получило кодовое наименование Orin.
Если Xavier — это уменьшенный в размерах аналог Drive PX 2, то Orin — это аналог Pegasus по уровню производительности и возможностей, но на основе лишь двух чипов, в отличие от четырех в Pegasus (два графических процессора Volta и два мобильных процессора Xavier). Главное, что Orin будет иметь ту же вычислительную архитектуру, что и предыдущее решение, что позволит очень легко и просто перенести на него все уже существующие разработки. И в этом — сила Nvidia, ведь они постепенно развивают свои продукты, не меняя общего подхода.
К слову, чипы Xavier содержат девять миллиардов транзисторов, на их основе можно создавать роботакси с высшим пятым уровнем автономности. Поставляются пока что инженерные образцы этих чипов, а массовое производство должно начаться лишь в следующем году. Еще более новый Orin будет компактнее и экономичнее, позволит получить еще большую производительность, но когда он станет доступным для заказчиков — пока что неизвестно.

Естественно, раз конференция проходила после не самого приятного случая с автопилотируемым автомобилем компании Uber, насмерть сбившим переходящую дорогу в темное время суток пожилую женщину с велосипедом, не обошлось без затрагивания этой темы. Еще до того, как Дженсена спросили об этом случае журналисты, он сам решил пояснить, что хотя Nvidia и предоставляет Uber оборудование для автопилота, эта компания не использует программное обеспечение Nvidia для работы автопилота, у них собственные разработки. А уж аппаратные средства никак не могут быть виноваты в случившемся, и скорее всего, их просто неверно настроили.
И хотя многие компании временно перестали тестировать автопилотируемые автомобили на дорогах общего пользования после первого смертельного случая с пешеходом (хотя сколько их ежедневно погибает от рук живых водителей?), никто не остановил разработки полностью, продолжая улучшать ПО на&n
Полный текст статьи читайте на iXBT
