Continuous integration 1C-Bitrix

Особенности поддержки проектов по технологии непрерывной интеграции в CMS 1C-Bitrix
Дата публикации: 02.10.2017 
Процесс разработки сайта у всех web-студий обычно состоит из четких и понятных шагов: бриф, ТЗ, дизайн, верстка, программирование, тесты. После того, как сайт сдан, кажется, можно расслабиться и приниматься за другую работу, но многие студии всегда смотрят в будущее —, а что будет с проектом после окончания работ? Будет ли проект развиваться? Ведь сайт, как ребенок, постоянно растет, учится чему-то новому, предлагает пользователям новые возможности. И каждому сотруднику хочется продолжать работать над интересными проектами вдолгую. После сдачи, проект переходит в стадию «поддержки» или/и «развития».
Поддерживать проект — достаточно кропотливая и непростая задача: много коротких задач, желание заказчика видеть изменения на сайте как можно чаще, большое количество специалистов, задействованных в работе над проектом. Чтобы проект не превратился в сбор хлама и разрозненного кода, существует философия разработки — Continuous Integration (Непрерывная интеграция, CI).
Непрерывная интеграция (CI, англ. Continuous Integration) — это практика разработки программного обеспечения, которая заключается в слиянии рабочих копий в общую основную ветвь разработки несколько раз в день и выполнении частых автоматизированных сборок проекта для скорейшего выявления и решения интеграционных проблем (wikipedia.org).
Статей о непрерывной интеграции web-приложений написана масса. Я же хочу поговорить о CI в CMS 1С Битрикс.
Философия. CI vs Bitrix
Для начала нужно понять что мы хотим иметь на практике? Основная философия CI заключается в следующем:
-
Версионность кода;
-
Версионность БД;
-
Автоматические сборки новых версий проекта.
На практике это означает:
-
Один и тот же код на production и develop версиях сайта;
-
Одна и та же структура БД на production и develop;
-
Автоматический перенос изменений на production (желательно вообще без участия специалиста) по расписанию или по событию.
Что же касается Битрикса, то важные особенности CMS это:
-
Неприкосновенность ядра;
-
Неприкосновенность структуры БД;
-
Возможность обновления ядра без последствий;
-
Технология «эрмитаж», позволяющая администратору сайта создавать разделы/страницы на бою с помощью визуального редактора;
-
Настройки компонентов (читай разделов сайта) хранятся в файлах.
Что имеем на практике при работе с 1С-Битрикс? Заказчик может менять тексты на контентных страницах сайта самостоятельно. Может менять настройки компонентов. Может обновить ядро. Да вообще все может, если захочет. Путь запрещения: «Не трогай, а то сломаешь!» — нам не подходит. Как нам отследить все, что делает заказчик на сайте, и не потерять своих изменений? Давайте посмотрим, что нам предлагает сам Битрикс.
Поддержка .git
Давным давно, когда Битрикс был молодым и неопытным, публичные файлы проекта лежали рядом с ядром, что очень осложняло работу — приходилось писать километровые .gitignore для исключения файлов, постоянно следить за новыми модулями. Но наступил 2013 год и в Битриксе появилась поддержка папки /local/, которая имеет преимущество перед папкой /bitrix/ (ядро проекта). В этой папке мы можем хранить все публичные файлы сайта:
-
/local/templates — шаблоны сайта;
-
/local/php_interface — init.php;
-
/local/modules — модули сторонних разработчиков;
-
/local/components — компоненты сторонних разработчиков;
-
/local/include/ — папка для своих доставок и платежных систем.
Отлично! Теперь можно не бояться «затереть» что-нибудь не свое. После долгих экспериментов мы пришли к такой структуре проекта:
...www/site/
/bitrix/ — ядро сайта
/gitignore/ — мы не хотим, чтобы файлы от сюда попадали в репозиторий
/current/ — символьная ссылка на папку /last_release/, DOCUMENT ROOT сайта
/last_release/ — корень сайта
/about/ — публичная папка
/bitrix/ — символьная ссылка на ядро
....
/local/ — папки с шаблонами, компонентами и т.д.
/upload/ — символьная ссылка на папку загрузки файлов
/upload/ — папка загрузки файлов
При этом .gitignore наш выглядит следующим образом:
/nbproject/ *.swp *.swo .idea /bitrix /upload /sitemap* *.tst *.zip *.log *.pdf *.xls *.txt *.html *.old gitignore gitignore/*
Доставку заказывали?
Ок, с репозиторием разобрались, но как нам доставлять изменения на develop и production сервера? Если с dev сервером проблем не возникает (git pull), то на production могут возникнуть проблемы — не всегда есть поддержка .git, заказчик вносит изменения в код сайта (через визуальный редактор), как следствие — масса конфликтов, каждый коммит превращается в ад. На помощь приходят автоматические сборщики кода.
Автоматический сборщик кода в вакууме представляет собой некую службу, которая умеет:
-
Отслеживать изменения в репозитории;
-
Делать git pull нужной ветки;
-
Архивировать файлы;
-
ssh.
Примеров таких сборщиков в сети масса: Travis, Piplines from Bitbucket, TeamCity, Jenkins, Bamboo. Можно выбрать то, что подходит именно вам.
Мы пошли еще дальше и решили автоматизировать и процесс слияния веток.
У нас есть 2 основные ветки кода: master для production и ветка develop для develop версии сайта.
Мы в итоге пришли к следующей схеме: программист Саша и верстальщик Вова работают над одним проектом. Программист Саша переписывает каталог, Вова «наверстывает» новую форму обратной связи. Каждый из них работает в своей ветке. Вова быстрее справился с задачей, коммитит стилевые файлы и выталкивает свою ветку в репозиторий. Его ветка в репозитории изменяется, срабатывает триггер, его ветка автоматически сливается с веткой develop.
Develop ветка изменяется, срабатывает триггер — сборщик запускает процесс деплоя: вытягивает ветку develop в свою папку текущего билда, архивирует все полученные файлы и заливает архив на сервер в папку сайта. После этого подключается по ssh, создает папку на сервере выше корня сайта с названием «release» и распаковывает в эту папку все файлы из архива. После этого в этой же папке создает все символьные ссылки, которые необходимы для работы проекта (ссылка на ядро bitrix, на папку upload и т.д.). На данный момент document root сайта смотрит на символьную ссылку «current», т.е. работа сайта не останавливается ни на секунду! После того, как ссылки проставлены, сборщик переименовывает папку «last_release» в «old_release», а папку «release», где лежит наш свежий код — в папку «last_release».
И вот Вова уже через несколько минут (процесс деплоя даже на больших проектах занимает 2–3 минуты) любуется новой формой на develop сайте и закрывает задачу. Но невидимый глазу сборщик продолжает свою работу. После успешного деплоя на сервер, сборщик сливает ветку develop со всеми другими ветками разработчиков.
Программист Саша наконец-то закончит задачу, закоммитит свои изменения и попытается вытолкнуть ветку. Но удаленный репозиторий не разрешит ему этого сделать. Сначала попросит вытянуть его свежую ветку. Что Саша с радостью и сделает: сольет ветки на локали, решит конфликты, если таковые будут, и с чистой совестью вытолкнет свою ветку — процесс деплоя начнется с самого начала.
Тут еще стоит сказать о встроенной поддержке .git в современных IDE, например, таких, как NetBeans. Саша вообще не переключается между окнами — все происходит в одной среде, ничего не нужно запускать, нажимать.
После того, как заказчик проверил изменения и ему все понравилось, ветка develop сливается с веткой master и начинается процесс деплоя уже на боевой сервер (за исключением слияния рабочих веток). Profit! Все счастливы, все довольны.
А где же тут Битрикс?
Включаемые области
Первая проблема, с которой мы столкнулись, — включаемые области: номера телефонов, ссылки на социальные сети, промо-тексты. Для всего этого используются включаемые области (bitrix: main.include). Неужели придется все эти области выносить в .gitignore? Чтобы этого не делать, мы написали модуль — включаемые области через БД. Принцип работы сохраняется — администратор сайта может править включаемые области через визуальный редактор, но информация сохраняется не в файл, а в БД, дополнительно указывается символьный код в настройках компонента, по которому мы однозначно определяем включаемую область. Теперь администратор может управлять включаемыми областями, изменения сохранятся на сайте.
Контентные страницы, меню
Вторая проблема — построение меню и организация контентных страниц на сайте. Как известно, меню в Битрикс строится на основе специальных файлов .*.menu.php — если заказчик добавит в файл пункт меню, а мы об этом не узнаем, при следующем билде мы просто затрем его изменения.
Проблему мы решили подключением файлов .*menu_ext.php, в которых структуру меню строим исходя из структуры разделов и элементов специального «контентного» инфоблока. Раздел инфоблока = раздел сайта, элемент инфоблока=страница на сайте.
Заказчику говорим создавать страницы и пункты меню не через «сайт», а через инфоблок. Тем более для него это привычнее: товары, меню, новости — все создается по одному принципу, не нужно запоминать несколько разных алгоритмов действий.
Контент выводим на сайте посредством компонента bitrix: catalog с настроенным ЧПУ от корня сайта:
"SEF_URL_TEMPLATES" => array(
"sections" => "",
"section" => "#SECTION_CODE_PATH#/",
"element" => "#SECTION_CODE_PATH#/#ELEMENT_CODE#/",
"compare" => "",
"smart_filter" => "#SECTION_CODE_PATH#/#ELEMENT_CODE#/#SMART_FILTER_PATH#/",
)
А в urlrewrite.php:
array(
"CONDITION" => "#^/#",
"RULE" => "",
"ID" => "bitrix:catalog",
"PATH" => "/pages/index.php",
),
Таким образом, все страницы, которые физически не находятся на сервере будут отправляться в этот компонент.
Но как нам быть со страницами типа /about/news/ ? Страница /about/ это обычная текстовая страница, а /about/news/ — раздел с новостями сайта из инфоблока новостей. Для таких случаев нами написано свойство инфоблока, которое позволяет определить тип контентной страницы: текстовая страница, внешняя ссылка или компонент:
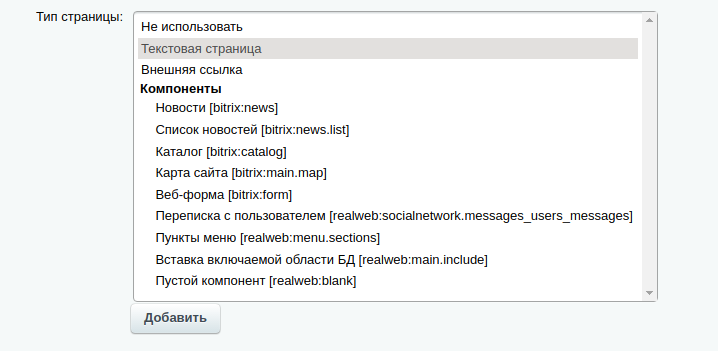
При этом, дважды кликнув на какой-либо компонент, администратор получает доступ к форме настройки компонента также, как и в визуальном редакторе на страницах сайта:
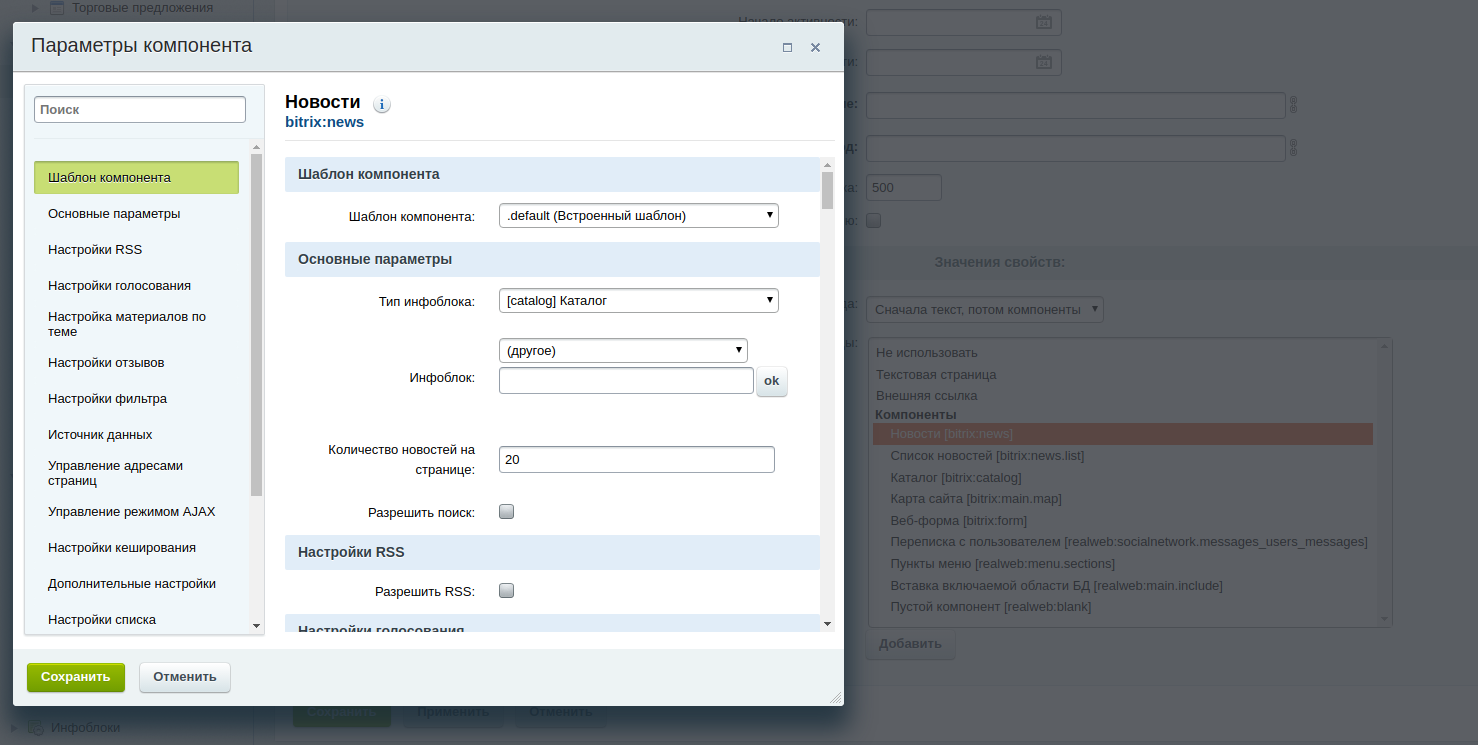
Параметры компонента сохраняются в виде сериализованного массива в БД, а в шаблоне компонента bitrix: catalog в component_epilog.php выводим сохраненный в БД компонент.
Структура БД
Вернемся к нашему проекту. Изначально программист Саша работал над проектом не один — ему помогал программист Рома. Рома внедрял новости, акции, текстовые страницы, Саша занимался каталогом и магазином. Работы велись одновременно. В процессе работы и Саша и Рома должны создать инфоблоки, свойства этих инфоблоков и т.д. Изначально мы решали проблему «одинаковости» БД для обоих программистов удаленным подключением к серверу, где лежит база данных. У каждого программиста свой код на локале, а вот БД одна. Но оказалось, не все так гладко: такой подход хорош при разработке сайта — потом сделаем дамп и все выльем на production. Когда проект уже находится на бою, такой номер не пройдет, придется руками создавать все новые инфоблоки и свойства. Решение, на самом деле, очевидно — миграции БД. Каждый программист работает со своей локальной БД, а изменения доставляет на сервер в виде файлов-миграций. Мы выбрали решение от наших коллег из компании WorkSolutions — модуль миграции БД. Этот модуль отлично нам подошел: миграции создаются легко, все четко и понятно. Есть поддержка консоли (наш сборщик проектов очень рад, так как ему добавляется дополнительное задание в каждом билде на миграцию базы данных).
Теперь процесс немного изменился: как только Саша коммитит свои изменения и пытается вытолкнуть свою ветку, удаленный репозиторий просит его сначала вытянуть свою ветку и слить со своей локальной. Когда Саша это сделает, у него появятся новые файлы миграции БД. Запустив у себя на локали обновление базы данных через модуль, он получит все изменения БД, которые внес другой программист.
Казалось, все достаточно стройно и красиво, но при использовании миграций БД сразу же возникает проблема настройки компонентов. Как известно, все списковые компоненты, которые работают с инфоблоками требуют указания ID инфоблока в настройках. ID у нас автоинкрементный, поэтому когда Саша и Рома в один и тот же день в своих локальных базах создадут по инфоблоку, у обоих этих инфоблоков будет ID=1. Рома создаст страницу /news/index.php, там разместит компонент новостей с настройкой IBLOCK_ID=1, Саша сделает то же самое с каталогом, но уже в другом файле /catalog/index.php. Когда они сольют код в единую ветку, наш сборщик успешно проведет обе миграции — получится, что мы имеем на сайте 2 разных компонента, которые работают с одним инфоблоком с ID=1. Например, первым создался инфоблок новостей, а вот инфоблок каталога с ID=2 остался не у дел. Подобная ситуация получится и у каждого программиста на локали, когда они проведут миграции.
Мы нашли выход в использовании констант. На событии «OnPageStart» мы запускаем вот такой метод:
public static function Definders() {
\Bitrix\Main\Loader::includeModule('iblock');
$result = \Bitrix\Iblock\IblockTable::getList(array(
'select' => array('ID', 'IBLOCK_TYPE_ID', 'CODE'),
));
while ($row = $result->fetch()) {
$CONSTANT = ToUpper(implode('_', array('IBLOCK', $row['IBLOCK_TYPE_ID'], $row['CODE'])));
if (!defined($CONSTANT)) {
define($CONSTANT, $row['ID']);
}
}
}
Т.е. формируем константы из типа инфоблока и его символьного кода (конечно, при этом у каждого инфоблока символьный код теперь заполняется в обязательном порядке).
Теперь мы не используем конкретные ID в настройках компонента — указываем константу, например, IBLOCK_CONTENT_NEWS или IBLOCK_CATALOG_CATALOG. На develop версии, на production, у Саши и у Ромы все инфоблоки имеют разные ID, но это никак не влияет на работу сайта.
Конечно, мы не утверждаем, что такая схема разработки идеальна и подходит всем и каждому. В каждой студии свои особенности. Однажды мы поняли, что не хотим использовать программистов для рутинной работы — наши специалисты пишут код и логику, все остальное можно переложить на плечи автоматики. Специалист теперь думает о проекте, а не о решении проблем с «переносом». Уверен, что мы не остановимся на достигнутом, в будущем, наверняка, появятся и другие улучшения в процессе разработки, о которых мы обязательно вам расскажем.
Полный текст статьи читайте на CMS Magazine
