Дайджест AI Cup. Пять стратегий Code Wizards 2016

В декабре завершился Russian AI Cup 2016 — организованный нами ежегодный чемпионат по программированию искусственного интеллекта. Чемпионат для наглядности, понятности и простоты проводится в игровом формате.
В этом году участники создавали алгоритм — игровую стратегию для MOBA-игры. Получившийся бот сражался с другими такими же, а лучший из них побеждал в раунде. Таким образом, из серии раундов получился турнир, проходящий в несколько этапов.
Расстановка по основным призовым местам на момент окончания чемпионата выглядела так:
- Антон Чумаченко (Москва, Россия). Занял первое место и выиграл MacBook Pro.
- Алексей Дичковский (@DragoonXen, Гродно, Беларусь). Второе место и MacBook Air.
- Максим Посаженников (Барановичи, Беларусь). Третье место, Apple iPad Air 2.
Двое из участников уже постили статьи на хабр по мотивам RAIC2016 — 1, 2.
Кроме того, на форуме чемпионата есть специальная ветка, где участники поделились опытом написания стратегий и рассказали о ключевых моментах своих алгоритмов. Некоторые из алгоритмов оказались очень интересными, ими мы и спешим поделиться с вами. А ещё мы подобрали для вас несколько понятных статей, объясняющих ключевые принципы, на которых строятся стратегии.
Рассматривать игровую стратегию без знания правил игры очень сложно. Если вы раньше ни разу не слышали о Russian AI Cup, то рекомендуем посмотреть нашу первую статью о нём. Или загляните в краткие правила под спойлером.
Чтобы лучше понять механику процесса, прочитайте краткие правила чемпионата. Полную версию вы можете посмотреть на нашем сайте.
Игровой мир двумерен, а все юниты в нём круглые. Игровая область ограничена квадратом, левый верхний угол которого имеет координаты (0.0, 0.0), а длина стороны равна 4000.0. Ни один живой юнит не может покинуть пределы игровой области.
Время в игре дискретное и измеряется в тиках. В начале каждого тика игра получает от стратегий желаемые действия волшебников в этот тик и обновляет состояние волшебников в соответствии с этими желаниями и ограничениями мира. Затем происходит расчёт изменения мира и объектов в нём за этот тик. Процесс повторяется опять — с обновлёнными данными. Максимальная длительность любой игры — 20 000 тиков, однако игра может быть прекращена досрочно, если достигнута командная цель одной из фракций либо если стратегии всех участников «упали». «Упавшая» стратегия больше не может управлять волшебником.
Обнаружение юнитов на карте ограничено туманом войны. Стратегия участника будет получать данные только о тех юнитах, которые находятся в пределах дальности зрения самого волшебника или любого другого юнита из его фракции.
В мире Code Wizards шесть классов юнитов, некоторые из них, в свою очередь, делятся на типы: волшебники; снаряды (магическая ракета, ледяная стрела, огненный шар и дротик); бонусы (усиление, ускорение и щит); строения (база фракции и охранная башня): миньоны (орк-дровосек и фетиш с дротиками); деревья.
Волшебники, строения, миньоны и деревья — это живые юниты. Их основные характеристики — текущее и максимальное количество жизненной энергии. В общем случае при падении жизненной энергии до нуля юнит считается погибшим и убирается из игрового мира. Волшебники — единственные живые юниты с возможностью регенерации здоровья. За каждый тик они автоматически восстанавливают некоторое количество жизненной энергии. Скорость регенерации — вещественное число, как правило, меньше единицы. Волшебник считается погибшим, если целочисленная часть его жизненной энергии падает до нуля.
Каждые 750 тиков база каждой фракции генерирует три отряда миньонов: по одному на дорожку. Каждый отряд состоит из трёх орков и одного фетиша. Отряд сразу же устремляется по своей дорожке к базе противоположной фракции, атакуя всех противников на пути. Волшебники используют миньонов как пушечное мясо, сами стараются держаться в безопасной зоне и атакуют противника на расстоянии.
В лесных зонах с некоторой вероятностью могут появляться нейтральные миньоны. Обычно они не агрессивны, однако при нанесении урона одному из них все нейтральные миньоны поблизости устремляются к обидчику, атакуя при этом любого, кто встанет у них на пути.
Каждые 2500 тиков на карте может появиться бонус. Если на карте уже есть хотя бы один бонус, то новый не возникнет. Бонус создаётся в случайно выбранной точке из двух возможных: (1200, 1200) или (2800, 2800). Если любая часть области появления бонуса уже занята волшебником, то симулятор попытается создать бонус во второй точке. При неудаче создание бонуса будет отложено до окончания очередного интервала.
Коллизия живых юнитов между собой и с границами карты не допускается игровым симулятором. Если расстояние от центра живого юнита до центра снаряда меньше или равно сумме их радиусов, то живой юнит получает урон, а снаряд убирается из игрового мира. При этом огненный шар взрывается и наносит урон всем живым юнитам поблизости. Если расстояние от центра волшебника до центра бонуса меньше или равно сумме их радиусов, то волшебник на 2400 тиков приобретает магический статус в зависимости от типа бонуса.
А дальше — интересные алгоритмы со слов самих участников:
@tyamgin — Иван Тямгин, 6-е место в финале
В моей стратегии, как и у многих, позиционирование в бою работает на потенциальных полях. Это самое простое, что могло прийти в голову. Как это выглядит:
(ускорение 4x)
На каждую точку карты действуют притягивающие (+) и отталкивающие (–) поля. Линейные функции, зависящие от расстояния до точки/отрезка. Вот основные из них:
(–) вражеские визарды
(+) вражеские визарды, которых нужно добить
(–) вражеские башни
(+) вражеские башни, которые нужно добить
(+) (–) вражеские миньоны, чтобы отходить, когда слишком близко, и подбегать для ближнего боя
(–) союзные юниты: на всякий случай, чтобы было пространство для маневров
(+) место за вражеским троном
(–) точки респауна миньонов
(+) точка, указывающая направление к бонусу: чтобы не бежать к нему сломя голову, а учитывать опасные зоны в бою
(–) лес (просто отталкивающие треугольники, чтобы лишний раз не заходить туда)
(–) стены и углы карты
(–) места, где могут зажать между стеной и башней
На каждом тике выбиралось смещение в ту точку, где больше потенциал. Лучшее, что я придумал, чтобы избежать попадания в локальные максимумы, — это учитывать не только следующий тик, но и 15 тиков вперёд (в выбранном направлении). Чем дальше предсказание, тем оно меньше влияло (экспоненциально угасало).
Для поиска пути использовался алгоритм Дейкстры, код которого переходит из года в год. Вся карта размечена сеткой размером 80 × 80. Переходить можно в восьми направлениях (смежных по диагоналям и в боковых). Ребра, на которых есть деревья, штрафовались пропорционально здоровью этих деревьев. Далее, после того как путь построен, он «сглаживается», чтобы убрать последствия разбиения на сетку, и строится список деревьев, которые нужно разрубить.
Здесь же учитывались штраф за переход на другой Lane, заход глубоко в лес, количество врагов по пути, конечная позиция (так как желательно встать на линию за своими миньонами, а не сбоку за деревьями).
Для первого раунда использовалась уже более-менее готовая версия уворотов. Перебирались 20 направлений отхода и то, нужно ли при этом поворачиваться. Тогда казалось — всё учтено, но позже я ещё раза два всё переписывал и почти каждый день находил баги и недочёты. Если летит одновременно несколько снарядов или Fireball, то выбирался отход с минимизацией суммарного урона.
Основной веткой прокачки стал Fireball. Перебирал, с каким углом он будет выпущен, и определял, какую дальность лучше ему пролететь. Также союзникам передавалась инфа о только что выпущенном фаерболе. Теоретически это можно было сделать по-нормальному, но я делал через «танцы»: округлял move.Turn до пяти знаков, остальные три десятичных знака были в моем распоряжении.
Второй веткой качал Range, но для финала сделал только RangeBonusPassive1, затем Haste.
Для финала до последнего не хотел использовать схему 0–5–0. Начал пробовать со схемой 2–2–1. В начале финальной недели оно даже стабильно выигрывало (у всех, кроме Commandos, Antmsu, Recar: с ними 50 на 50), но я понимал, что это ненадолго. Так как 0–5–0 не зашла, принял решение развивать то, что есть. В итоге в финале играла версия с 1–3–1 с перестроением «по ситуации».
→ Код
Antmsu — Антон Чумаченко, 1-е место в финале
1-й раунд. Ходил только в центр из-за того, что бонусы брать удобнее плюс линия шире. Так как стратегия была реализована через потенциальные поля, то, чтобы избежать зависания между бонусами, за 700—800 тиков до их появления начинала действовать слабая сила притяжения к каждому из них.
В зависимости от расположения миньонов, вражеских и союзных визардов, а также вражеской башни и ее кулдауна (напрямую я эти зависимости никак не учитывал), мой визард выбирал одну из сторон для взятия бонуса. И примерно за 300—400 тиков «отключался более слабый бонус».
Возле самого бонуса, когда был мой визард и ещё один союзный (если врагов оказывалось больше, то я всё равно шёл за бонусом до последнего и часто умирал, так как бонус считался более приоритетным, чем всё остальное), я использовал небольшую «киллер-фичу»: вставал в точке между бонусом и союзным визардом, и когда тот пытался меня обойти, чтобы встать ближе к бонусу перед его появлением, то я сдвигался по меньшему радиусу, чтобы снова оказаться между союзным визардом и бонусом. Если союзников было больше, то уже не получалось так сделать.
Также в первом раунде реализовал увороты, на тот момент они работали хорошо: большинство визардов стреляли ровно в центр, и можно было легко отбежать за время полёта снаряда в сторону. Бежать начинал ещё в момент выстрела, а не тогда, когда видел вражеский magic missile.
На самом деле более выгодная точка для стрельбы смещена примерно на 7—8 пикселей от центра в сторону поворота визарда (из-за разности скорости перемещения в разных направлениях). Позже, чтобы выбрать лучшую точку, куда стрелять (в пределах одного визарда), я просто перебирал углы, начиная от центра +/– пару градусов, как раз для случая, когда в момент выстрела вражеский визард стоит боком.
В какой-то момент уворачиваться стали многие в топ-30 песочницы, и также я заметил, что многие начинают уклоняться от magic missile в момент выстрела. Изначально хотел собирать статистику, кто бежит на тик раньше, чтобы увернуться, а кто нет (от этого зависит, стоит ли смещать точку стрельбы на move.speed). Но придумал более простое решение, которое и было той фишкой, дающее такое преимущество в микро. В тот момент, когда я мог выстрелить во вражеского визарда, я не стрелял, а ждал один тик. Это в большинстве случаев позволяло мне угадать направление движения в следующий момент и попадать в уклоняющихся визардов с чуть большего расстояния.
Также стоит сказать, что с самого начала я писал собственный визуализатор стратегии, без которого отладка занимала бы гораздо больше времени.
2-й раунд. У заклинания Fireball было неоспоримое преимущество с точки зрения нанесения количество урона за единицу времени, да и к тому же от него можно увернуться, только если стоять очень далеко. Также с первого раунда я реализовал ближний бой с миньонами, поэтому данная ветка была просто идеальной по сравнению с другими.
Соответственно, вражеское главное здание получалось уничтожать в среднем чуть быстрее, чем это делали враги. На момент, когда я только научился пользоваться этим заклинанием, в 35 играх из 42 одержал победу (в режиме 10×1+). Конечно, потом эту ветку стали выбирать очень многие, и преимущества почти не было.
А в остальном аккуратнее стал ходить за бонусами, чтобы реже умирать на них, плюс в начале игры выбирал линию, где меньше всего союзников, для максимально быстрого получения опыта. Микро на тот момент было ещё не доработано, поэтому выбирать другую ветку развития при численном преимуществе врага на линии я не стал, хотя это бы принесло чуть больше очков в раунде.
Основную часть времени второго раунда я потратил на симуляцию всех юнитов на карте, чтобы прогнозировать, стоит ли идти защищать базу или выгоднее уже донести вражескую, а также для определения, в кого выстрелит башня.
Симуляция работала быстро и более-менее точно, но недостаточно, и в итоге я ей воспользовался только для того, чтобы бросать Fireball с упреждением в миньонов для нанесения максимального урона.
Неточности появлялись из-за того, что я не дописал поведение визардов. Да и к тому же баланс оказался таким, что идти защищаться было редко выгодно. Также данную симуляцию можно было бы использовать для прогнозирования, стоит ли в массовом бою наступать или же отступать. На самом деле это неплохо решается с помощью менее ресурсозатратного метода — Influence map, учитывающих эффективное количество жизней, кулдауны выстрелов, ауры, характеристики персонажей, но этот метод я успел реализовать даже к финалу.
Финал. Вплоть до последнего дня не хотелось идти в 5-м по миду, поэтому пробовал 1–3–1. Против активного раша старался минимизировать время прохода по боковой стороне (тут самой выгодной была ветка ближнего боя), и получалось это сделать примерно за 6 тысяч тиков.
Буквально за сутки до финала удалось исправить несколько недочетов, которые присутствовали в стратегии с самого начала: вставать в одну линию в массовой драке, не ходить за бонусами всеми визардами, правильно передвигаться при повышенной скорости, учитывать действие аур скорости на вражеских юнитов, чтобы делать меньше промахов при выстреле, и не рубить лишние деревья.
Эти исправления позволили хорошо сражаться 5 × 5. Плюс немного улучшил микро за счёт разных коэффициентов. Также заметил одну особенность: чем шире построение, тем лучше в среднем получалось проводить сражения, но, скорее всего, это из-за того, что не был реализован командный выбор цели и одного вражеского визарда мои пять боялись точно так же, как и один (держался на расстоянии примерно enemyCastRange + 20).
«Искусственно» я повышал уровень агрессии в зависимости от количества вражеских визардов на линии со мной. Перед второй частью финала у меня никак не получалось одолеть в микро NighTurs, поэтому при соблюдении нескольких условий одним из визардов я уходил на другую линию в надежде, что он быстрее уничтожит вражеское здание, чем пять визардов оппонента продавят моих четверых по центральной линии.
Но в итоге это работало с багом, плюс удача была не на моей стороне, так как перед финалом с теми же самыми версиями против NighTurs счёт был 5: 0 в мою пользу, а во время финала — 1: 4 в пользу NighTurs (после финала — снова 2: 0 в мою пользу).
После финала радостного чувства победителя не было: казалось, что стратегия далека от идеала, а отрыв от второго и третьего места настолько мал, что победа досталась во многом благодаря везению.
И последняя «киллер-фича»: в годы обучения в университете я очень много играл в доту и был в ней неплох :) Конечно, про фичу я пошутил, так как навыки игры дали только повышенный интерес в начале соревнования.
@m0rtido — Александр Киселев, 12-е место в финале
Основа алгоритма — потенциальные поля: смотрим 32 точки вокруг + под собой, идём в лучшем направлении. Изначально точки брал не на одинаковое расстояние, а на максимальный шаг, но поворачивал я в том же направлении (а не направлении градиента), и бот очень неохотно ходил по диагонали. В итоге стал всегда ходить в сторону антиградиента, хотя сейчас уже думаю, что надо было туда только поворачиваться, а идти в лучшую доступную на максимальный шаг точку.
Чтобы не попадать в локальный минимум при ходьбе (в бою отключал), добавлял «холмы» своим прошлым позициям. Идея взята из видео:
В принципе, всего у меня было четыре вида полей: текущая «цель» (вейпоинт, бонус), «препятствия» — поле росло быстро около них, но почти не росло на расстоянии, «опасность» и «мишень». Последнее поле отключало поле «цель» и представляло собой хитрую формулу, учитывающую положение цели и точки отступления (чтобы не забегать в лес).
Опасность вычислялась для всех юнитов по-разному, но учитывала мою скорость, их кд, дальность атаки, текущие таргеты миньонов, текущие таргеты башен, магов и время поворота на меня.
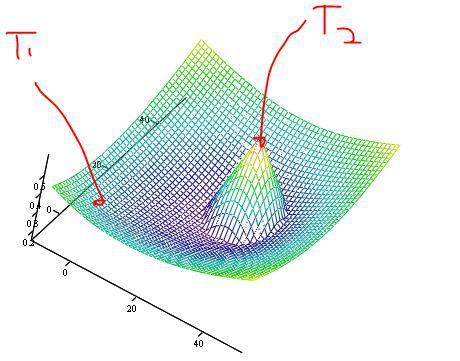
Т1 — точка отступления, Т2 — цель, к которой тянется, плюс её опасность
Как многие, для оптимизации я «обрубал» мир, оставляя только существенные препятствия и объекты.
Ходил по вейпоинтам + алгоритм Дейкстры, но проапгрейдил их до точек, которые имели «влияние» команд и «владельца». Чтобы захватить точку, нужно было удерживать влияние над ней определённое время с определённой силой.
Увороты: самое интересное и проблемное. У меня было три версии.
Первая версия. На потенциальных полях добавлял отталкивающее поле опасности в каждое будущее положение прожектайла. Основная проблема: если в тебя летит два прожектайла, то маг встаёт посередине и ловит оба.
Вторая версия. Моделировал отход в 32 направления + стоять на месте, пока не увернусь/подставлюсь/упрусь, брал то, где меньше дамага получаю (для ледышек дамаг завышал). Оставшиеся направления подавал в функцию хождения по потенциальным полям — и жил так радостно до конца второго раунда.
Основная проблема: не оценивает ещё не выпущенные прожектайлы. Ещё поля опасности от магов учитывали каст ренж, но не учитывали, что если я очень быстрый, то могу подойти ближе и всё ещё уворачиваться от всего. Эту версию уворотов я потом использовал для оценки, стрелять во врага или нет. Если дамаг по нему до добавления «вероятностной» ММ в мир меньше, чем после, то я стрелял.
Потом стал добавлять туда еще прожектайлы от союзных визардов, готовых выстрелить в ближайшие 5 тиков. Это слегка повысило кучность и хитрость стрельбы в группах. Стрелял не в центр, а в точку, от которой бежать во всех направлениях одинаковое время:
public static V2d getShootPoint(V2d aimPos, V2d aimAngle, double projectileRadius) {
return aimAngle.copy().mul((projectileRadius + 35.0d) / 7.0d).add(aimPos);
}Третья версия. В коллекцию прожектайлов добавлял те, что могут быть выпущены магами в ближайшие 50 тиков. Для каждого направления они генерировались свои, чтобы маг всегда стрелял в самую неудобную точку.
Перебиралось примерно так:
- сначала пытался увернуться от всех реальных снарядов в 32 (+1) направлениях, при этом создавая снаряды, «вероятностные» по мере движения;
- если снаряд попадал в меня в этом направлении — добавлял его дамаг;
- если попадал в поле вышки, и я был там таргетом, и кд = 0 — то добавлял ещё дамаг от вышки;
- если ни один снаряд в меня больше не попадал, то из этого направления я начинал новый перебор опять в 32 (+1) направлениях уже «вероятностных» снарядов до тех пор, пока не увернусь от всех них или не столкнусь с препятствием.
Урон от «вероятностных» снарядов я добавлял с экспоненциальным затуханием по расстоянию, которое пролетит снаряд, чтобы со временем маг убегал от слишком приблизившихся магов, а не считал: «Какая разница — что тут попадут, что на границе в один пиксель от безопасной зоны».
Это самая сложная и самая костыльная часть проекта, так как приходилось много чего править, допиливать, убирать лишнюю пугливость, проверять, когда можно поворачиваться для выстрела, а когда надо 100% уворачиваться (если не мог увернуться от реальных прожектайлов, то я даже не рыпался). Делать костыли на то, что маг может слегка подбежать.

Вот третья версия позволила убрать поле опасности визарда, подходить к нему гораздо ближе и всё ещё уворачиваться от выстрелов (даже тех, что ещё не сделаны).
Наверное, это основа алгоритма. Разумеется, была куча тиков, я падал по времени с третьими уворотами, куча ошибок и багов в константах, некоторые баги в константах заставляли меня подниматься буквально мгновенно мест на 10—20 выше (в топ-100).
@ivlevAstef — Александр Ивлев, прошел во второй раунд
Условно я разделю алгоритм на две части.
Первая часть алгоритма — обход препятствий. Вторая часть использует первую, но решает проблемы с вырубкой деревьев и оцениванием длины пути (первый умел обходить, но не умел оценивать расстояние до точки).
Первая:
По факту это не поиск пути — это качественный обход препятствий. Алгоритм строится вокруг групп связанных объектов и касательных к ним.
Если посмотреть видео, то можно заметить, что между деревьями очень много фиолетовых линий. Эти линии в алгоритме не присутствуют, но они были созданы для визуализации групп. В самом начале видео и на 40-й секунде, где маг уходит в лес, очень хорошо видно, что у нас в «левых» лесах есть две большие группы, между ними маг и проходит на 40-й секунде.
Алгоритм построения групп
Имеем множество объектов и множество групп, которое вначале пустое.
Берём объект из множества объектов и проверяем, если он попадает в одну группу (находится близко к одному из объектов группы) — то добавляем его туда. Если более чем в одну — то объединяем эти группы и добавляем в новую группу новый объект.
Далее определяем, куда двигаться в текущем тике. На входе имеем множество групп, мага и точку, куда хотим прийти. Я бы этот алгоритм назвал так — бросание лучей, хотя на самом деле всё же это не лучи, а отрезки: у них есть максимальная длина.
Вначале бросаем луч в точку, куда хотим прийти. Находим пересечение с группой (объектом из группы), которое ближе всего к нам. Проходим по всем объектам группы, считаем обе внутренние касательные к каждому объекту группы и находим такие, которые дадут максимальный угол отклонения от текущего луча — их будет две (одна влево, другая вправо).
Дальше по магической логике (в первом варианте алгоритма функция выбора из двух касательных была сложной, ибо выбирать ту, которая даст наименьший угол отклонения, очень плохо: когда подходишь близко к краю группы, то этот угол зачастую становится максимальным) выбираем одну из двух. Точка касания (с учётом, правда, радиуса мага) будет нашей новой точкой, куда надо двигаться. После чего снова бросаем луч, но в новую точку, предварительно удалив ту группу, с которой мы уже пересекались.
Первый алгоритм имел несколько недостатков. Мне не нравилась функция, какую касательную брать из двух; я не мог оценить дистанцию до точки; не рубил деревья.
Второй алгоритм использовал ту же функцию для обхода препятствий, но перед этим он считал приблизительный путь и удалял из него деревья.
Вначале брал алгоритм Ли (волновой) и строил от себя волну на всю карту (карта представляется сеткой 125 × 125). Здания и миньоны считались непроходимыми, а вот деревья просто имели завышенную цену прохода в зависимости от их хп и расстояния от центра (дерево может попадать на несколько клеток одновременно, и было бы нелогично все эти клетки помечать одним весом).
Те, кто знаком с алгоритмом Ли, возмутятся: этот алгоритм умеет искать путь, но не учитывать цену перехода, и будут правы. По этой причине:
а) я считал волну на всю карту;
б) алгоритм был немного скрещён с Дейкстрой. По факту это можно даже назвать Дейкстрой, а не Ли, где граф представлен в виде 2д-массива.
Вообще сложно сказать, что это — Ли или Дейкстра, ибо обход я использовал из Дейкстры, но с оптимизацией, а хранил данные, как для Ли.
В итоге у нас есть карта, мы можем найти из любой точки оптимальный путь до мага. Так как нам нужно за тик иногда просматривать несколько путей, это ещё и имело преимущество по сравнению с a*, которому для каждого пути нужно заново всё пересчитывать. А для полной оптимизации я ещё и саму карту обновляю раз в 60 тиков. Если за 60 тиков менялась клетка (что происходило всегда и по несколько раз), то использовал быстрое обновление: у предыдущей клетки завышал вес, а у новой занижал.
Следующий этап — скрестить это с частью один… Тут всё просто, берём наш путь, пересекаем его с окружностью радиусом 300 (не помню уже, почему такой выбрал, вначале был 600); точка пересечения — и есть та точка, до которой мы будем считать обход препятствий. Решение помогло упростить старый алгоритм обхода, так как теперь можно было брать минимальный угол смещения от вектора направления: сам вектор был коротким и уже указывал, куда нужно идти.
Последний этап — рубка леса. На входе имеется путь, представленный в виде отрезка небольшой длины (построен на основании сетки 125 × 125), и множество деревьев. Задача: найти деревья, которые можно быстро срубить, которые нельзя обойти и рядом с которыми (или через которые) проходит путь. Алгоритм простой, но в нём есть баг — иногда рубит лишнее. Когда его делал, уже понял всю бессмысленность написанного и не стал его догонять до идеала.
Алгоритм: идём по пути и находим дерево, которое ближе всего к нашему текущему сегменту. Убеждаемся, что это дерево нам на самом деле подходит (его нельзя обойти). Для этого образно делим игровое поле на две части: по одну сторону пути и по другую. Если есть такое дерево, которое принадлежит другой стороне пути, и если между этими двумя деревьями нельзя пройти, значит, текущее дерево надо снести.
Есть проблема: в местах, когда путь проходит близко к середине дерева, дерево в итоге оказывается не в той половине пути, в которой бы стоило. В итоге просто не решал эту проблему, ибо не фатальная.
Почему всё это работает? Когда строится путь, то он проходит так, что радиус дерева влияет на цену нелинейно. Поэтому деревья, которые легко срубить, оцениваются так, словно их там почти и нет (очень маленькая цена), а большие деревья сравнимы с почти непроходимыми точками. И так как вес дерева затухает со временем, то в большинстве случаев путь идёт между деревьями, но ближе к маленьким. Благодаря этому выбирается под сруб маленькое дерево. Обход теперь идёт не глобально, а локально (радиус 300), и те деревья, которые нужно срубить, я удаляю при поиске групп (дабы обход препятствий просчитывался без них), так что первая часть алгоритма показывает себя ещё в большей красе: ей не нужно огибать препятствия за километры, она их обходит здесь и сейчас.
Почти финальный вариант движения можно посмотреть на видео:
Но в реальной жизни не всё так хорошо. Иногда точка, куда бежать, меняется прямо в середине леса, иногда крипы за тобой гонятся и надо выбирать: или лес рубить, или крипа бить… и ещё много мелких факторов.
→ Ссылка на код
Поиск пути находится в файлах Algorithms/A_PathFinder. Обход препятствий — в Algorithms/A_Move. Построение групп — в Environment/E_World.
Различная 2д математика — в Common/C_Math.
И ещё пара слов о другой стороне олимпиады — о времени:
- первая неделя — 26 часов;
- вторая неделя — 26 часов;
- третья неделя — 27 часов;
- четвёртая неделя — 34,5 часа;
- пятая неделя — 38,5 часа;
- на шестой неделе я забил, там очень мало — 10 часов;
- на последней неделе — 8 часов.
Итого: 170 часов.
На поиск пути я убил: 49 часов.
На поддержание своей архитектуры в более-менее нормальном состоянии (около 70 классов — 140 файлов на С++): 28 часов.
На увороты: 26 часов.
Всё остальное: 67 часов — правки багов, подгонки коэффициентов и другие более скучные вещи (выбор линии, карта опасности, понимание, когда атаковать, а когда убегать).
ALEXks — Александр Колганов, прошел во второй раунд
Концепция: в основе лежал набор состояний, в которые стратегия может перейти в зависимости от условий и текущей ситуации. Такими состояниями могут быть: движение к бонусу, атака, добивание башней, уворот от атаки и т. д. Каждое состояние может влиять на другие состояние — в большинстве случаев перекрывать (отменять) действие состояния. Так как код фактически линейный, то все состояния просто проверяются каждый раз и активируются те, у которых выполнены условия. Например, если мы стоим на лайне и подходит время брать бонус, то в дополнение к времени проверяются разного рода условия: идёт ли наступающий фронт, есть ли у нас преимущества, находимся ли мы в пределах зоны, где можно отойти за бонусом, или же надо проносить базу.
Некоторые ошибки: возможно, из-за такого объёма свойств времени на детальную реализацию действительно не хватало, поэтому почти до последнего момента передвижение было очень топорным: ключевые точки из стратегии быстрого старта + возможность отходить назад, но потом это было исправлено.
Также я почему-то не подумал, что можно наносить урон дальше дистанции каста, причём сильно дальше. Почти до начала второго раунда многие этот факт не учли, и было всё ОК, но потом моя страта начала проигрывать, и я стал замечать, что можно атаковать с большего расстояния, а также где-то на форуме это тоже звучало.
Передвижение: основной момент — рекурсивная функция, которая позволила просчитывать на глубину 6 тиков по сетке в 7 × 6 и порогом 25%. Суть такова: перебираем все шаги на максимальное расстояние вокруг себя по сетке семь шагов по длинной стороне (вперёд-назад) и шесть по короткой (влево-вправо) и оцениваем эту позицию: можно ли на неё встать, и если да, то накладываем разные штрафы и бонусы — как раз то место, где есть использование ПП. Далее по порогу отсеиваем этот набор точек по функции оценки и повторяем рекурсию для оставшихся. Функции оценки линейны в зависимости от расстояния, а также учитывалась атака противников, кулдаун до начала атаки, радиус деревьев — и даже была попытка учесть союзных миньонов, чтобы не застрять. Также передвижения всех остальных юнитов тоже симулируются на 6 тиков, но в том направлении и с теми же скоростями, что были зафиксированы до запуска рекурсивной процедуры. Деревья также давали штраф. Если вокруг не было вражеских юнитов, то просчёт упрощался, чтобы сэкономить время.
Некоторые выше писали, что рекурсия — это долгий процесс из-за вложенности и многократного вычисления расстояния. Через профилировщик я увидел, что всё время в этой процедуре занимает функция hypot (x, y) и, погуглив в нете, обнаружил, что она работает намного дольше (примерно в 40 раз), чем простое sqrt (xx+yy). В данном случае, где координаты лежат в диапазоне 0…5000, функция hypot вообще не нужна (предлагаю читателю самим поискать, почему hypot лучше sqrt). И в итоге я решил отказаться от извлечения корня, где это возможно, и тем самым перевёл всё на сумму квадратов. Ведь даже расстояние между юнитами можно оценить, не вычисляя корень: достаточно суммы квадратов. Умножения и сложения выполняются быстрее, чем извлечение корня, в итоге стало возможным считать на глубину 6—7 тиков с достаточно подробной сеткой (или деревом), причём на последнем уровне могло быть 3—6 точек.
Единственный минус — я мог оказаться в локальном минимуме между деревьями и частенько застревал. Причина — слишком близкая допустимая дистанция до самих деревьев, а также маленькое количество тиков рекурсивной функции. С этим я так и не поборолся, но решил сделать так, чтобы мой маг уничтожал деревья, которые могут ему помешать в будущем.
После изменения баланса после первого раунда я держался в районе топ-30—50. Для боев 5 × 5 я тоже пробовал много тактик, но остановился на пяти по центру, так получалось и лучше, и быстрее. Но опять же — не хватало более точной оценки соперника. Функции штрафов были слишком грубыми для топ-20.
Как ни странно, я почему-то решил, что огонь — не самый лучший вариант, потому что если не дать прокачать огонь противнику на лайне и быстрее прокачать дальность и скорость атаки, то ты становишься в плюсе. Я пробовал разные тактики, и через скорость + фриз, и через огонь + дальность. Все они есть в коде. Для 5 × 5 я одного мага качал на дальность + скорость, остальных — на огонь.
Ссылка на код (почему-то в этом проекте и только в этом решил писать русские комменты; там прокомменчено достаточно много, и, я думаю, разобраться можно очень легко, писал на С++).
Russian AI Cup закончился. Что дальше?
Сейчас мы проводим серию чемпионатов по ML на нашей платформе ML Boot Camp. В нём найдётся место всем: от новичка до профессионала. Начин
