
Рейтинг открытости генеративных AI-моделей
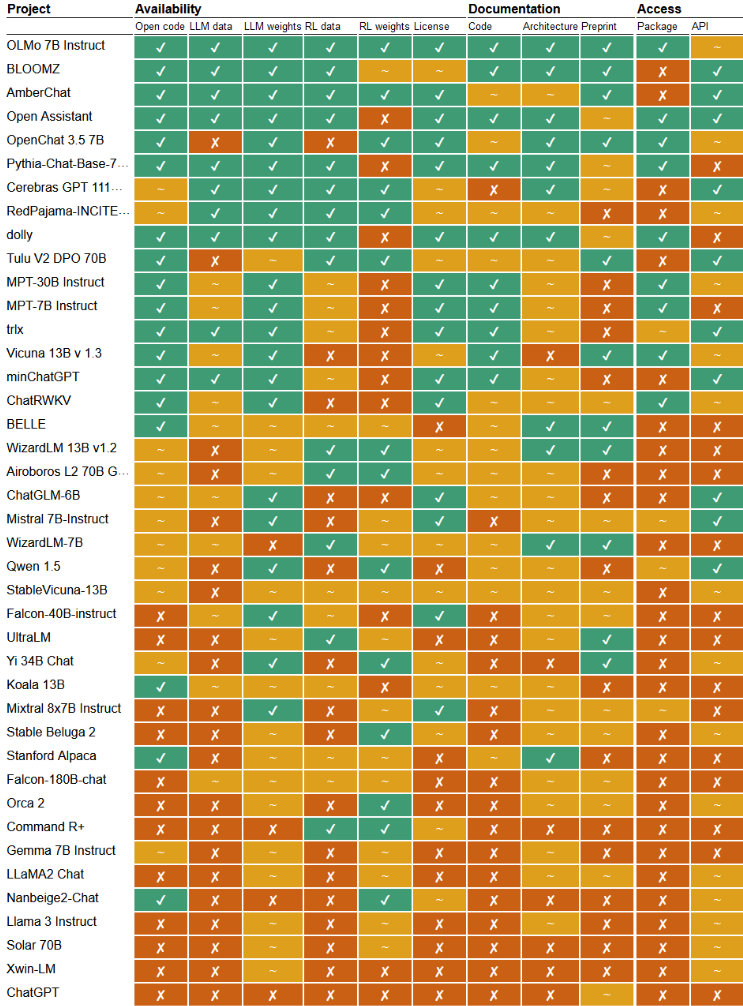
Исследователи из Университета Неймегена (Нидерланды) подготовили рейтинг открытости 40 больших языковых моделей и 7 моделей для генерации изображений по текстовому описанию, которые заявлены производителями как открытые. Из-за того, что критерии открытости моделей машинного обучения ещё только формируются, в настоящее время сложилась ситуация, когда под видом открытых распространяются модели, имеющие лицензию, ограничивающую область использования (например, многие модели запрещают применение в коммерческих проектах). Также часто производители не предоставляют доступ к используемым при обучении данным, не раскрывают детали реализации или не открывают полностью сопутствующий код.
Большинство моделей, позиционируемых как «открытые», на деле следует воспринимать как «открытые весовые коэффициенты» или точнее «доступные весовые коэффициенты», так как они распространяются под ограничивающими лицензиями, запрещающими использование в коммерческих продуктах. Сторонние исследователи могут экспериментировать с подобными моделями, но не имеют возможность адаптировать модель под свои нужды или проинспектировать реализацию. Более половины моделей не предоставляют детальные сведения о данных, используемых для обучения, а также не публикуют информацию о внутреннем устройстве и архитектуре.
Наиболее открытыми признаны модели BloomZ, AmberChat, OLMo, Open Assistant и Stable Diffusion, которые опубликованы под открытыми лицензиями вместе с исходными данными, кодом и реализацией API. Модели от Google (Gemma 7B), Microsоft (Orca 2) и Meta (Llama 3), позиционируемые производителями как открытые, оказались ближе к концу рейтинга, так как они не предоставляют доступ к исходным данным, не раскрывают технические детали реализации, а весовые коэффициенты модели распространяют под лицензиями, ограничивающими область использования. Популярная модель Mistral 7B оказалась примерно в середине рейтинга, так как поставляется под открытой лицензией, но лишь частично документирована, не раскрывает используемые при обучении данные и имеет не полностью открытый сопутствующий код.
Исследователями предложены 14 критериев открытости AI-моделей, охватывающих условия распространения кода, данных для обучения, весовых коэффициентов, вариантов данных и коэффициентов, оптимизированных при помощи обучения с подкреплением (RL), а также наличие готовых к использованию пакетов, API, документации и детального описания реализации.

Источник: http://www.opennet.ru/opennews/art.shtml? num=61448
Полный текст статьи читайте на OpenNet прочитано 66973 раза
