Открыт код системы распознавания и перевода речи Whisper
Проект OpenAI, занимающийся развитием общедоступных проектов в области искусственного интеллекта, опубликовал наработки, связанные с системой распознавания речи Whisper. В том числе открыт код эталонной реализации на базе фреймворка PyTorch и набор уже обученных моделей, готовых для использования. Код открыт под лицензией MIT. Утверждается, что для речи на английском языке система обеспечивает уровни надёжности и точности автоматического распознавания близкие к распознаванию человеком.
Для обучения модели использованы 680 тысяч часов речевых данных, собранных из различных коллекций, охватывающих разные языки и тематические области. Около ⅓ задействованных при обучении речевых данных приходятся на языки, отличные от английского. Предложенная система в том числе корректно обрабатывает такие ситуации, как произношение с акцентом, наличие фоновых шумов и применение технического жаргона. Кроме транскрипции речи в текст, система также может переводить речь с произвольного языка на английский язык и определять появление речи в звуковом потоке.
Модели сформированы в двух представлениях: модуль для английского языка и многоязычная модель, поддерживающая в том числе русский, украинский и белорусский языки. В свою очередь, каждое представление делится на 5 вариантов, отличающихся размером и числом охваченных в модели параметров. Чем больше размер, тем больше точность и качество распознавание, но и выше требования к размеру видеопамяти GPU и ниже производительность. Например, минимальный вариант включает 39 млн параметров и требует 1 ГБ видеопамяти, а максимальный включает 1550 млн параметров и требует 10 ГБ видеопамяти. Минимальный вариант быстрее максимального в 32 раза.
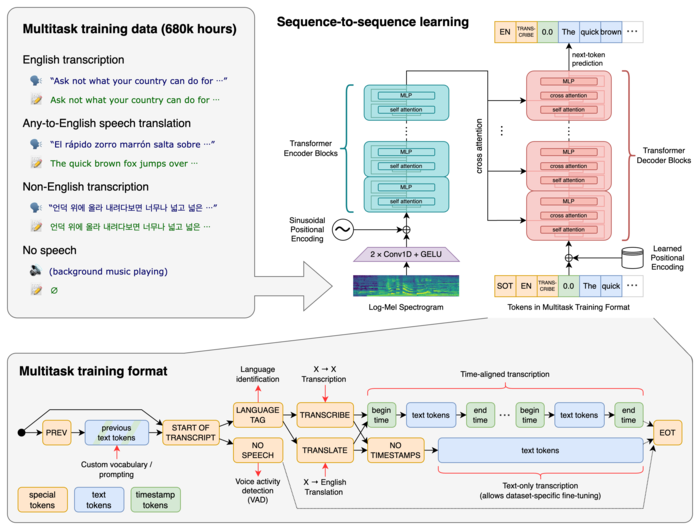
В системе используется архитектура нейронной сети «Transformer», работающей как кодировщик-декодировщик. Звук разбивается на 30-секундные отрывки, которые преобразуются в log-Mel-спектограмму и передаются кодировщику. Декодировщик обучен для предсказания текстового представления, смешанного со специальными токенами, позволяющими в одной общей модели решать такие задачи, как определение языка, разделение фраз по времени, транскрипция речи на разных языках и перевод на английский язык.
Источник: http://www.opennet.ru/opennews/art.shtml? num=57812
© OpenNet
