Google начал открытие реализации модели потоков M:N
Компания Google предложила для включения в состав ядра Linux первый набор патчей с реализацией компонентов, необходимых для обеспечения работы модели потоков M: N. Инициатива Google связана с открытием развивавшегося за закрытыми дверями API SwitchTo для ядра Linux, обеспечивающего работу реализованной в пространстве пользователя многопоточной подсистемы, применяющей модель потоков M: N. Подсистема используется в Google для обеспечения работы сервисов, требующих минимальных задержек. Планирование и управление распределением потоков производится целиком в пространстве пользователя, что позволяет существенно снизить число операций переключения контекста за счёт минимизации выполнения системных вызовов.
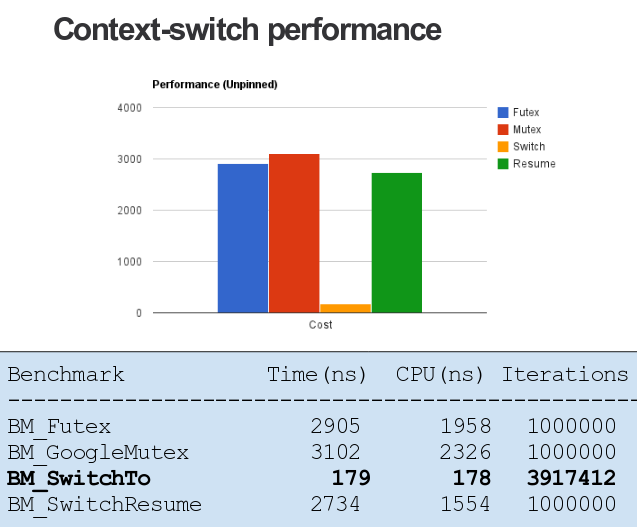
Для обеспечения работы указанной подсистемы на уровне ядра Linux был реализован API SwitchTo, предлагающий три базовых операции — wait, resume и swap (переключение). Для включения в состав ядра предложен код новой операции FUTEX_SWAP, дополняющей FUTEX_WAIT и FUTEX_WAKE, и предоставляющей основу для создания многопоточных библиотек в пространстве пользователя. FUTEX_SWAP также может применяться для передачи сообщений между задачами, по аналогии с RPC. Например, в настоящее время для передачи сообщения между задачами требуется выполнить как минимум четыре вызова FUTEX_WAIT и FUTEX_WAKE, использование же FUTEX_SWAP позволит обойтись одной операцией, которая будет выполнена в 5–10 раз быстрее.
В настоящее время на практике применяются в основном модели потоков 1:1 и N:1. Модель 1:1 используется в NPTL (POSIX потоки) и LinuxThreads, и подразумевает прямое сопоставление потока в пространстве пользователя с потоком (единицей планирования выполнения) на уровне ядра. Модель N:1 реализована в GNU Pth, выносит диспетчеризацию потоков в пространство пользователя и позволяет N потоков в пространстве пользователя привязать к одному потоку в ядре, при это ядро не имеет информации о пользовательских потоках.
Основным недостатком модели 1:1 являются большие накладные расходы на переключение контекста между ядром и пространством пользователя. Модель N:1 решает эту проблему, но создаёт новую — так как поток в ядре является неделимой единицей планирования выполнения, то пользовательские потоки, привязанные к одному потоку в ядре операционной системы, не могут масштабироваться по ядрам CPU и оказываются привязанными к одному ядру CPU.
Модель M: N является гибридной и устраняет все вышеописанные недостатки благодаря сопоставлению N потоков в пространстве пользователя с M потоками в ядре ОС, что позволяет как снизить накладные расходы на переключение контекста, так и обеспечить масштабирование по ядрам CPU. Ценой данного варианта является большое усложнение реализации планировщика потоков в пространстве пользователя и необходимость в механизмах согласования действий с планировщиком ядра.
Источник: http://www.opennet.ru/opennews/art.shtml? num=53443
© OpenNet
