Зоопарк ML-моделей или лучший справочник на Хабре
Привет, Хабр!
Меня зовут Ирина, я работаю ML инженером в Brand Analytics. Моя работа тесно связана с NLP, ведь мы ежедневно получаем огромное количество текстовых данных со всего интернета. Сегодня я хочу поговорить о теме, которая беспокоила меня еще с тех времен, когда я только начала изучать SOTA-решения в задачах обработки естественного языка.
Transformer, BERT, GPT, Т5… Наверное, уже нет ML разработчика, который хоть отдаленно не был бы знаком с этими моделями. В сети о них написано множество статей: архитектуры подробно разобраны, рассмотрены принципы обучения, приведены способы применения к разным типам задач. Бери и используй, что еще нужно. Только вот, когда начинаешь выбирать модель, которая бы идеально подошла для решения твоей задачи, глаза разбегаются от всего этого многообразия. А ведь сфера ML не стоит на месте, и каждый год появляется что-то новое.
Так как же не потеряться во всем этом? Правильно. Зоопарк моделей 2022. Когда-то статья 2016 года помогла мне разобраться в основных типах нейронных сетей, поэтому сейчас я предлагаю вместе собрать удобный справочник, где будут кратко описаны современные модели. Как для начинающих ребят, так и для опытных специалистов.
Здесь не будет большого количества текста, долгих объяснений и сложной математики (если очень хочется, оставлю ссылочки:)). Этот справочник будет собираться постепенно, и начать я хочу с моделей на основе архитектуры Transformer.
Сегодня поговорим о тех самых SOTA-решениях. Transformer — настоящая революция, которая позволила вывести обработку естественного языка на новый уровень. А формула довольно проста: хорошо масштабируемая модель + очень много данных = потрясающий результат. Трансформер был представлен в 2017 году в статье Attention is all you need. Здесь название говорит само за себя, основа архитектуры — механизм внимания. Говоря кратко, трансформер состоит из стека энкодеров, в каждом из которых есть слой Self-Attention, а за ним просто сеть прямого распространения, и стека декодеров, в которых дополнительно добавлен блок Encoder-Decoder Attention, который смотрит на результаты кодировщика.
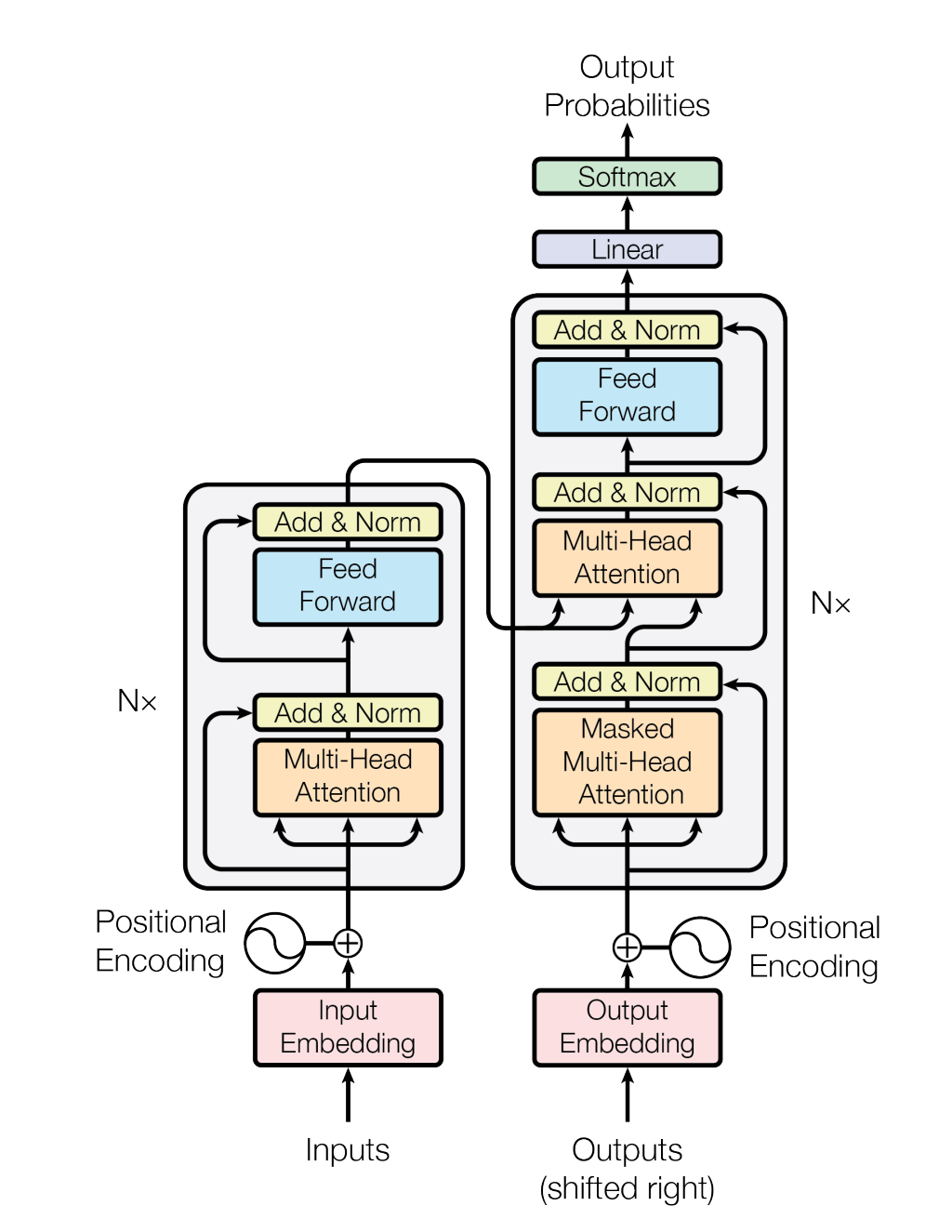 Схема из оригинальной статьи (https://arxiv.org/abs/1706.03762)
Схема из оригинальной статьи (https://arxiv.org/abs/1706.03762)
Сегодня модели на основе архитектуры трансформер хорошо работают не только с задачами NLP, в этот список так же входит и компьютерное зрение, анализ аудио и т.д. Не удивительно, что разновидностей таких моделей стало очень много. Рассказать про весь этот мир в одной статье невозможно, поэтому сегодня я затрону три классных решения, которые показывают отличные результаты в задачах seq2seq.
Text-to-Text Transfer Transformer
Прежде всего мне хочется поговорить о T5. T5 (Text-to-Text Transfer Transformer) — модель, которая призвана объединить все задачи NLP в формат преобразования текста в текст, то есть модель должна распознавать задачу, а выходные данные представляют собой просто «текстовую» версию ожидаемого результата. Для этого к исходным входным данным, которые подаются в модель, добавляется текстовый префикс для конкретной задачи. Этот текстовый префикс также рассматривается как гиперпараметр.
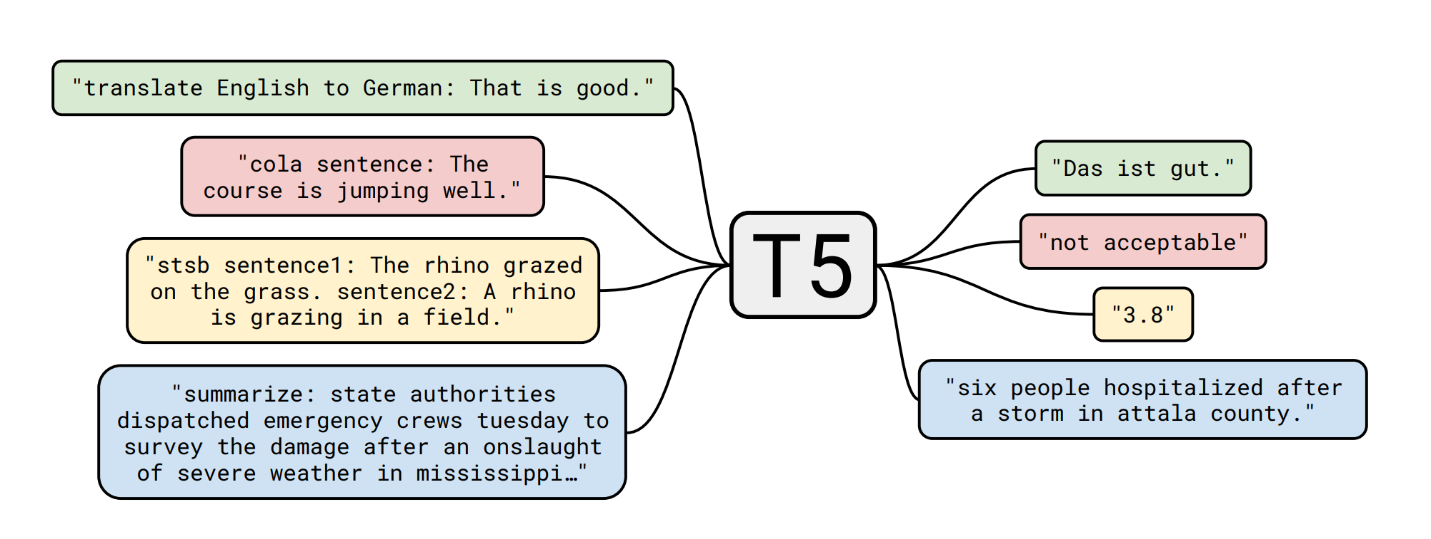 Пример использования фреймворка (https://arxiv.org/abs/1910.10683v3)
Пример использования фреймворка (https://arxiv.org/abs/1910.10683v3)
Архитектура представляет собой Encoder-Decoder Transformer с некоторыми изменениями в слоях нормализации и позиционных эмбеддингах, подробно об этом лучше всего почитать в оригинальной работе или в следующей нашей статье. Тренировалась модель на датасете C4 (Colossal Clean Crawled Corpus), он представляет собой очищенную версию набора данных Common Crawl. Т5 учится предсказывать маскированные токены, как и BERT, только здесь на токен [MASK] заменяются несколько последовательных токенов.
 (https://arxiv.org/abs/1910.10683v3)
(https://arxiv.org/abs/1910.10683v3)
T5 удобно использовать, так как она работает на большом количестве задач, умеет работать со многими языками и имеет разные вариации относительно размеров модели.
BART
BART — модель, которая стала одним из SOTA решений для задач суммаизации текстов. Архитектура представляет собой двунаправленный (BERT-подобный) кодировщик и авторегрессионный (GPT-подобный) декодер, которые объединены с помощью кросс-внимания, где каждый слой декодера смотрит на итоговое скрытое состояние из выхода энкодера.
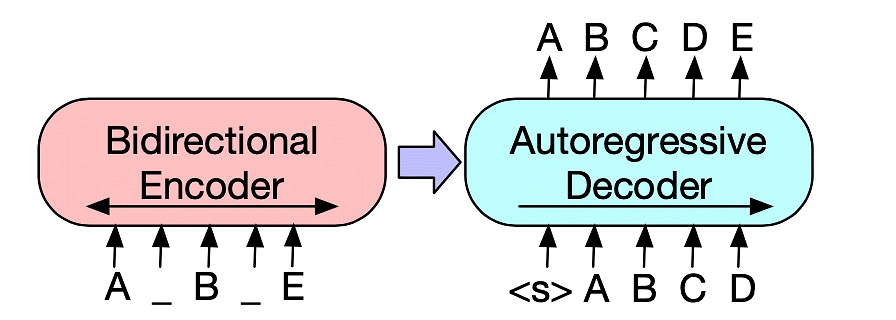 Схема модели из оригинальной статьи (https://arxiv.org/abs/1910.13461)
Схема модели из оригинальной статьи (https://arxiv.org/abs/1910.13461)
На Hugging Face есть большое количество вариаций BART разных размеров, с настройками под конкретные задачи и разные языки.
PEGASUS
PEGASUS — современная модель для обобщения абстрактного текста. Основана на модели Transformer с энкодером и декодером. В модели объединены два подхода: Gap Sentence Generation (GSG) и Masked Language Model (MLM). Если говорить кратко: изначально есть три предложения. В GSG одно предложение замаскировано с помощью [MASK1] и используется в качестве целевого текста генерации (GSG). Два других предложения остаются во входных данных, но некоторое количество слов из последовательности случайным образом маскируются [MASK2], и модель обучается предсказывать эти замаскированные слова. Таким образом, модель выучивается одновременно предсказывать замаскированные случайные токены и предложение.
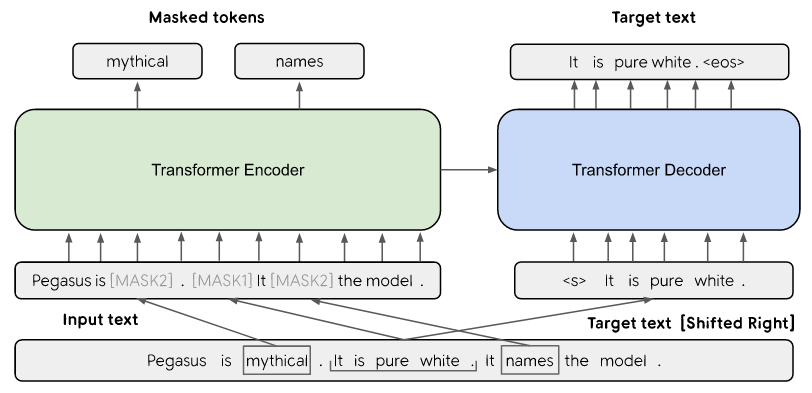 Схема модели из оригинальной статьи (https://arxiv.org/abs/1912.08777)
Схема модели из оригинальной статьи (https://arxiv.org/abs/1912.08777)
PEGASUS способен обходить ранние SOTA решения на задачах суммаризации даже при небольших наборах данных. Главная проблема в применении этой модели — она пока не адаптирована под разные языки. Если же вам нужно работать с английскими текстами — PEGASUS может очень выручить.
Вот и первые представители нашего Зоопарка ML-моделей. Конечно, это лишь капля в море современных моделей, поэтому давайте собирать и структурировать все вместе. Можно подумать, что это невозможно с такими темпами развития ML, но почему бы не попробовать?
Хабровцы, в комментариях предлагайте, какие модели разберем в следующих статьях. Ссылки и всевозможные пояснялки будут только плюсом — добавим в описание. Жду ваши идеи, обсудим?)
Что посмотреть:
Понятный и подробный разбор архитектуры Transformer на русском
Подробно о T5
Подробно о BART
Больше о PEGASUS здесь и здесь
