Жизнь без регулярных выражений и без logstash при разборе логов. Публикация событий в Elasticsearch
Парсинг логов будет совсем не нужен. При изменении формата логирования и появлении новых сообщений не нужно поддерживать большой набор регулярок. Так как будем перехватывать вызовы методов error, warn, info, debug, trace логера и отправлять данные в elasticsearch. С этим нам поможет аспектно-ориентированное программирование
Скринкаст вы можете посмотреть в конце статьи.
Данная реализация носит демонстрационный характер и не предназначена для промышленной эксплуатации, лишь объясняет принцип построения подобного решения. Надеюсь, что вам будет интересно узнать как с помощью аспектов написанных в виде скрипта и конфигурации можно работать с elasticsearch клиентом, gson сериализатором и параметрами перехваченного метода в jvm.
Подопытной программой остается SonarQube, как и в статьях про hawt.io/h2, логирование jdbc и CRaSH-ssh. Подробнее про процесс установки и конфигурирования сонара и агента виртуальной машины можете почитать в публикации про hawt.io/h2.
На этот раз будем использовать параметры запуска jvm сонара:
sonar.web.javaAdditionalOpts=-javaagent:aspectj-scripting-1.0-agent.jar -Dorg.aspectj.weaver.loadtime.configuration=config:file:es.xml
И для работы примера необходимо скачать jvm агент aspectj-scripting и файл конфигурации es.xml:
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<configuration>
<aspects>
<name>com.github.igorsuhorukov.Loging</name>
<type>AROUND</type>
<pointcut>call(* org.slf4j.Logger.error(..)) || call(* org.slf4j.Logger.warn(..)) || call(* org.slf4j.Logger.info(..)) || call(* org.slf4j.Logger.debug(..)) || call(* org.slf4j.Logger.trace(..))</pointcut>
<process>
<expression>
res = joinPoint.proceed();
log = new java.util.HashMap();
log.put("level", joinPoint.getSignature().getName());
log.put("srcf", joinPoint.getSourceLocation().getFileName().substring(0, joinPoint.getSourceLocation().getFileName().length()-5));
log.put("srcl", joinPoint.getSourceLocation().getLine());
if(joinPoint.getArgs()!=null && joinPoint.getArgs().?length>0){
log.put("message", joinPoint.getArgs()[0].?toString());
if(joinPoint.getArgs().length > 1){
params = new java.util.HashMap();
for(i=1; i < joinPoint.getArgs().length;i++){
if(joinPoint.getArgs()[i]!=null){
if(joinPoint.getArgs()[i].class.getName().equals("[Ljava.lang.Object;")){
for(j=0; j < joinPoint.getArgs()[i].length;j++){
if( (joinPoint.getArgs()[i])[j] !=null){
params.put(i+"."+j,(joinPoint.getArgs()[i])[j].toString());
}
}
} else {
params.put(i,joinPoint.getArgs()[i].toString());
}
}
}
log.put("params", params);
}
}
log.put("host", reportHost); log.put("pid", pid);
log.put("@version", 1);
localDate = new java.util.Date();
lock.lock();
log.put("@timestamp", dateFormat.format(localDate));
index = "logstash-" + logstashFormat.format(localDate);
lock.unlock();
logSource = gson.toJson(log);
client.index(client.prepareIndex(index, "logs").setSource(logSource).request());
res;
</expression></process>
</aspects>
<globalContext>
<artifacts>
<artifact>com.google.code.gson:gson:2.3.1</artifact>
<classRefs>
<variable>GsonBuilder</variable>
<className>com.google.gson.GsonBuilder</className>
</classRefs>
</artifacts>
<artifacts>
<artifact>org.elasticsearch:elasticsearch:1.1.1</artifact>
<classRefs>
<variable>NodeBuilder</variable>
<className>org.elasticsearch.node.NodeBuilder</className>
</classRefs>
</artifacts>
<init>
<expression>
import java.text.SimpleDateFormat;
import java.util.TimeZone;
import java.util.concurrent.locks.ReentrantLock;
reportHost = java.net.InetAddress.getLocalHost().getHostName();
pid = java.lang.management.ManagementFactory.getRuntimeMXBean().getName().split("@")[0];
gson = new GsonBuilder().create();
dateFormat = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss.SSS'Z'");
dateFormat.setTimeZone(TimeZone.getTimeZone("UTC"));
logstashFormat = new SimpleDateFormat("yyyy.MM.dd");
logstashFormat.setTimeZone(TimeZone.getTimeZone("UTC"));
lock = new ReentrantLock();
client = NodeBuilder.nodeBuilder().clusterName("distributed_app").data(false).client(true).node().client();
</expression>
</init>
</globalContext>
</configuration>
Для всех точек вызова из программы методов error, warn, info, debug, trace интерфейса org.slf4j.Logger, вызывается аспект, в котором мы создаем HashMap log и заполняем параметрами контекста вызова: файла класса «srcf» и строки в нем «srcl», указываем уровень логирования «level», имя хоста «host», идентификатора процесса «pid», временем вызова логера "@timestamp", а так же шаблон текста сообщения и отдельно в Map «params» сохраняем его параметры. Все это синхронно с вызовом сериализуется в json и отправляется в индекс с именем «logstash-» + дата вызова. Классы для форматирования даты и времени, а также клиент для elasticsearch создаются при старте приложения в блоке глобальной инициализации аспектов globalContext.
Классы elasticsearch загружаются из maven репозитария по координатам org.elasticsearch:elasticsearch:1.1.1, а json сериализатора по координатам com.google.code.gson:gson:2.3.1.
Клиент из аспекта при старте по мультикаст протоколу пытается найти кластер elasticsearch с именем «distributed_app»
Перед запуском нашего клиента обязательно запустим кластер elasticsearch сервера, состоящий из одного процесса:
package org.github.suhorukov;
import org.elasticsearch.common.settings.ImmutableSettings;
import org.elasticsearch.node.Node;
import org.elasticsearch.node.NodeBuilder;
import java.io.InputStream;
import java.net.URL;
import java.util.concurrent.TimeUnit;
public class ElasticsearchServer {
public static void main(String[] args) throws Exception{
String template;
try(InputStream templateStream = new URL("https://raw.githubusercontent.com/logstash-plugins/logstash-output-elasticsearch/master/lib/logstash/outputs/elasticsearch/elasticsearch-template.json").openStream()){
template = new String(sun.misc.IOUtils.readFully(templateStream, -1, true));
}
Node elasticsearchServer = NodeBuilder.nodeBuilder().settings(ImmutableSettings.settingsBuilder().put("http.cors.enabled","true")).clusterName("distributed_app").data(true).build();
Node node = elasticsearchServer.start();
node.client().admin().indices().preparePutTemplate("logstash").setSource(template).get();
Thread.sleep(TimeUnit.HOURS.toMillis(5));
}
}
Для компиляции и работы этого класса необходима зависимость:
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>1.1.1</version>
</dependency>
Для просмотра логов скачаем старую сборку kibana 3.1.3, которая может работать без веб сервера. Отредактируем файл config.js
elasticsearch: "http://127.0.0.1:9200"
чтобы kibana смогла подключиться к серверу elasticsearch (именно для этого мы указали «http.cors.enabled»=true)
Запускаем сонар
./bin/linux-x86-64/sonar.sh start
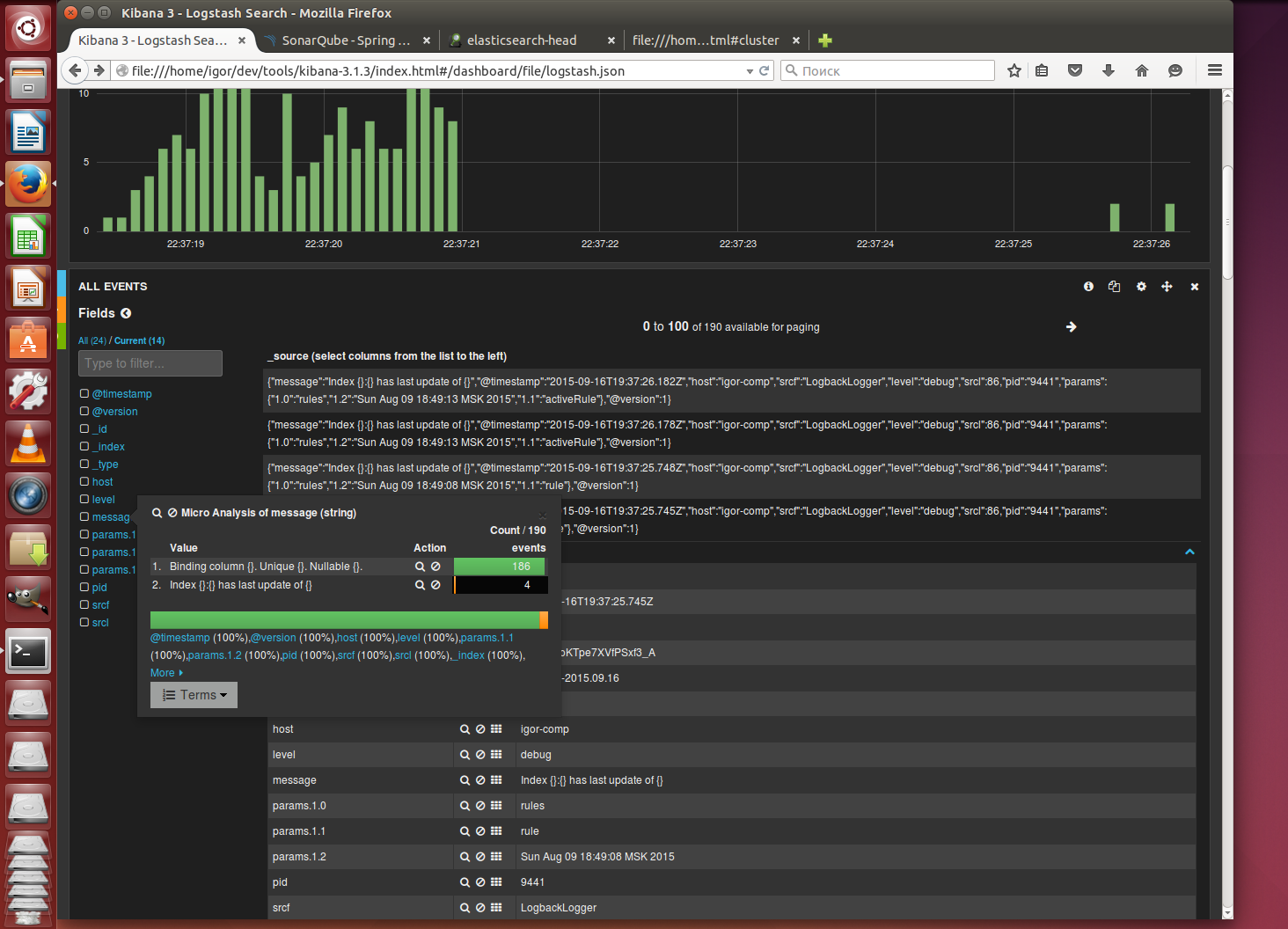
и наблюдаем в браузере как в процессе работы SonarQube в kibana отображаются события этой системы
Повторюсь — это лишь пример. В реальном решении нужно свести к минимуму накладные расходы на каждый вызов метода, минимизировать генерацию мусора, сериализовать и отправлять данные асинхронно потоку, вызвавшему метод логирования, а также обрабатывать ошибки и продолжать работу при недоступности сервера ES.
В ближайшее время оубликую на хабре видео и слайды моего доклада по аспектно-ориентированному программированию. В следующих публикациях рассмотрим пример отправки в elasticsearch метрик jvm и процессов.
Про какие примеры с применением аспектов вам было бы интересно почитать? Пожалуйста предлагайте!
