Записки оптимизатора 1С (Часть 4). Параллелизм в 1С, настройки, ожидания CXPACKET

Немного о параллелизме
Параллелизм — это возможность выполнения запросов сервером СУБД в нескольких потоков. Если MS SQL Server работает на многопроцессорной машине, то »компонент Database Engine определяет оптимальную степень параллелизма, то есть количество процессоров, задействованных для выполнения одной инструкции, для каждого из планов параллельного выполнения. MS SQL Server определяет уровень параллелизма до начала выполнения запроса без необходимости перекомпиляции плана его выполнения, и один и тот же запрос в разное время в зависимости от условий на момент начала его выполнения может быть выполнен с разным уровнем параллелизма или вообще последовательно» (из документации к MS SQL Server).
По умолчанию в настройках SQL Server параллелизм не ограничен и потенциально для выполнения запроса могут использоваться все ядра всех процессоров (max degree of parallelism= 0). Соответственно, чтобы ограничить количество потоков, на которые будет распараллеливаться запрос настройка max degree of parallelism должна быть отличной от нуля. А верхний предел диапазона значений — это количество всех ядер CPU.
Кроме MaxDOP (max degree of parallelism) есть вторая важная настройка — cost threshold for parallelism, которая отвечает за порог срабатывания параллелизма. Или, по-другому, стоимостная оценка, при которой оптимизатор запросов начинает анализировать предварительный план в случае последовательного запуска и параллелизма, и выбирает, что ему выгоднее использовать. Чем выше значение этого параметра, тем меньшее количество запросов будет параллелиться или, правильнее сказать, тем большему количеству запросов будет запрещено параллелиться. Это нужно для того, чтобы найти некий баланс, золотую середину между количеством запросов без параллелизма и с параллелизмом, иначе на некоторых системах можно легко вогнать процессор «в банку» и/или словить огромное количество блокировок на параллелизме.
Что дает параллелизм?
Это фактически линейное ускорение запроса. Например, если в один поток, на одном ядре запрос выполняется за 10 сек., то в десять потоков, на десяти ядрах он выполнится за 1 секунду. Получить десятикратное увеличение, не прибегая к рефакторингу кода — это очень круто. Это самый простой, наименее затратный способ ускорения некоторых (!) запросов. Нет рисков, как при переписывании кода, получить функциональные ошибки, не нужно задействовать ресурсы на тестирование и исправление ошибок.
Ниже приведен скриншот из программы мониторинга Perfeхpert, на котором видно как разные запросы в один и тот же момент времени распараллеливаются на разное количество потоков.

Если в колонке «CPU Загрузка» больше 100%, то значит запрос использует более одного логического ядра процессора.
Кроме того, для серверов СУБД имеет важное значение качественная утилизация ресурсов процессора. Мы встречались неоднократно с ситуациями, когда процессор сервера СУБД «простаивает», недозагружен.

При этом жалобы на производительность есть. Такая система явно имеет потенциал для улучшения производительности за счет правильной утилизации CPU.
Параллелизм. Dark side
Понятно, что не всё так просто и радужно. Во-первых, далеко не все запросы будут хорошо параллелиться. Вообще, в принципе. И таких запросов большинство. А, во-вторых, есть обратная сторона медали, о которой и поговорим дальше.
Первый негативный фактор, о котором вскользь уже упоминал выше — это неконтролируемый рост потребления CPU. То есть, в настройках сервера оставляют maxdop = 0, и некоторые хорошо параллелящиеся запросы отъедают в моменте все доступные ядра процессора. Если процессорных ресурсов с избытком, то возможные эпизодические инциденты не доставляют серьезных неприятностей. Но может статься и так, что ресурсы ограничены и это приводит к значительной загрузке CPU и большим очередям на нём. На рисунке ниже приведены счетчики потребления CPU и очереди для 16-ти ядерного сервера СУБД. По современным меркам это совсем немного для многопользовательской системы, CPU нагружен значительно, очереди к процессору перманентные и часто большие.
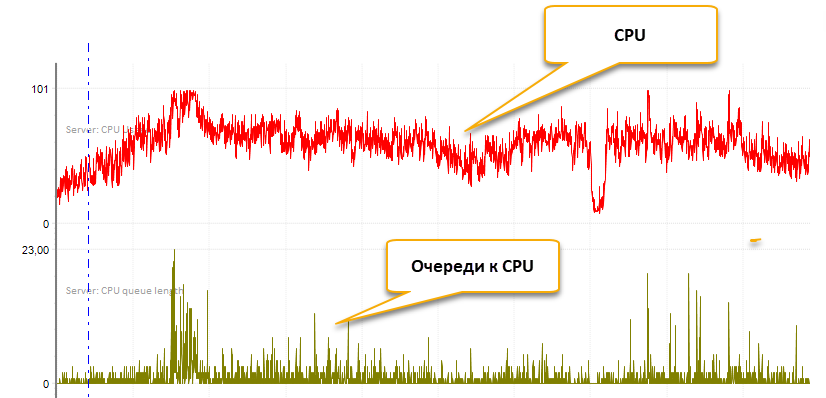
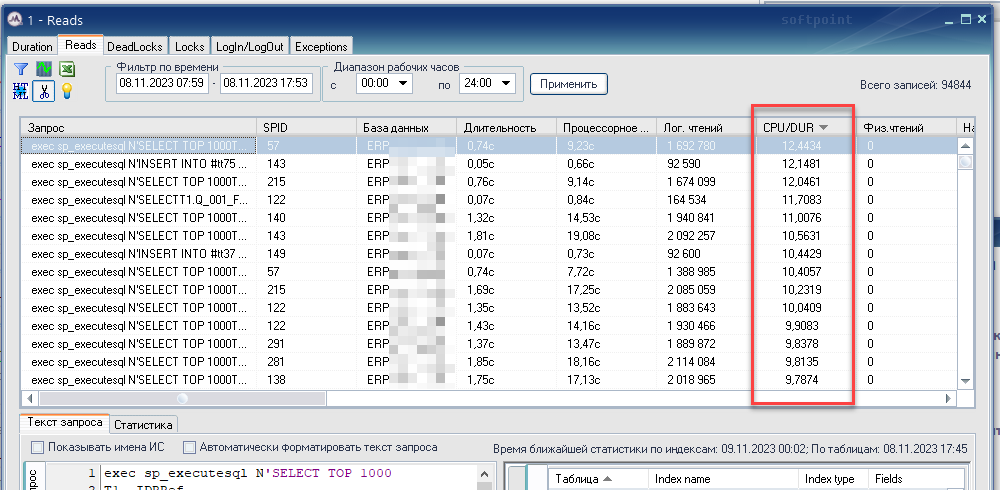
Если посмотреть трассу READS, то видно, сколько ядер потреблял тот или иной запрос в моменте (выделено красным в колонке CPU/DUR). Для CPU всего с 16-ю ядрами — это непозволительная роскошь.
Второй негативный фактор — ожидания на параллелизме CXPACET.
Например, в системах 1С вендор настоятельно рекомендует установить max degree of parallelism = 1. Вот что он сам пишет по этому поводу:

Хочу особо отметить последний абзац, где рекомендуется включать параллелизм осознанно и после дополнительного анализа. Инструментов, чтобы провести качественный анализ, связанный с ожиданиями на параллелизме почти нет. Тот запрос к представлению sys.dm_os_wait_stats, что приведен на скрине, покажет статистику по ожиданиям в среднем по больнице — по всему серверу, по всем базам за период с момента последней перезагрузки сервера. Например, вы получите цифры «Время ожидания = 6 215 998 сек»,»Количество = 974 635 030». Ну дальше можно рассчитать »Среднее ожидание = 0,0064 сек». Какие правильные выводы из этого следуют? Риторический вопрос.
Поэтому в отсутствие качественного анализа, действительно, самым простым способом избежать просадки производительности в части длительности выполнения некоторых запросов и блокировочной картины — это выставить уровень параллелизма в »1».
Методика работы с параллелизмом на MS SQL Server
Мы давно анализируем ИТ-системы, проводим аудиты производительности, встречали множество ситуаций. Поэтому с высоты этого опыта хотим поделиться нашим подходом к анализу и работе с параллелизмом.
Дальше буду использовать возможности мониторинга Perfexpert.
Посмотрим какую информацию отдает SQL Server по ожиданиям CXPACKET. В Perfexpert в окне SQL-сессий видны разные данные по SPID на конкретный момент времени.
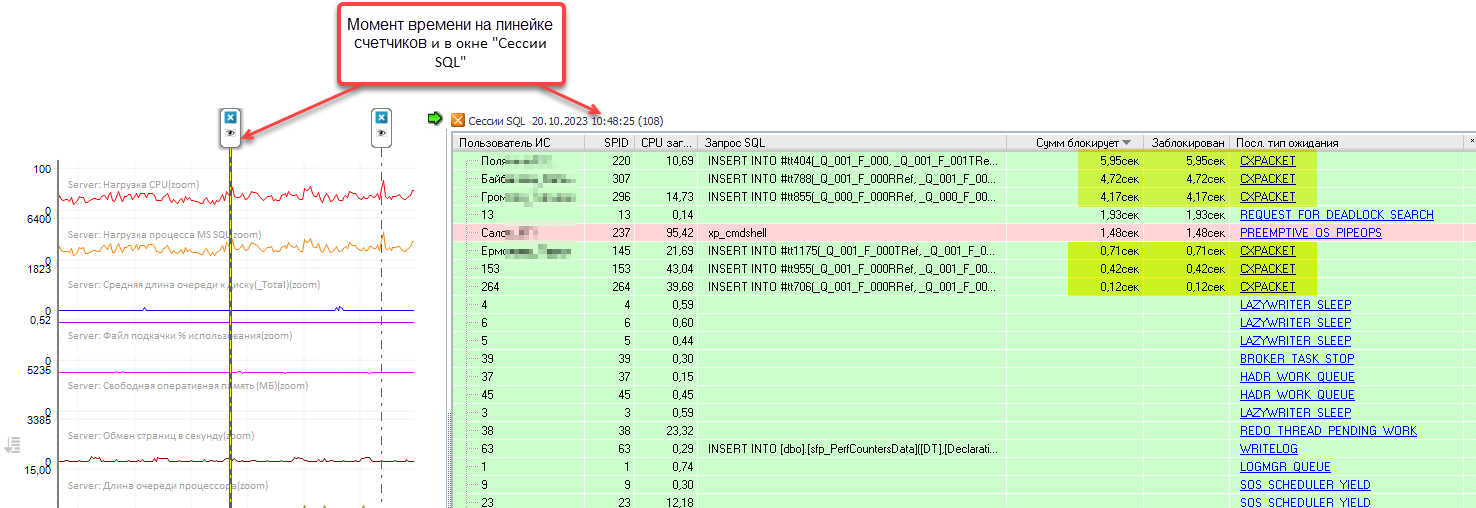
Нас интересуют строки, где в колонке «Последний тип ожиданий» значение CXPACKET. В колонке «Сумм. блокирует» видно сколько секунд эти запросы ожидают на параллелизме на выбранный момент времени (10:48:25). Например, SPID 220 уже ждет почти 6 секунд.
Теперь посмотрим в трассе DURATION за сколько этот запрос реально выполнился, и сколько времени ожидал.
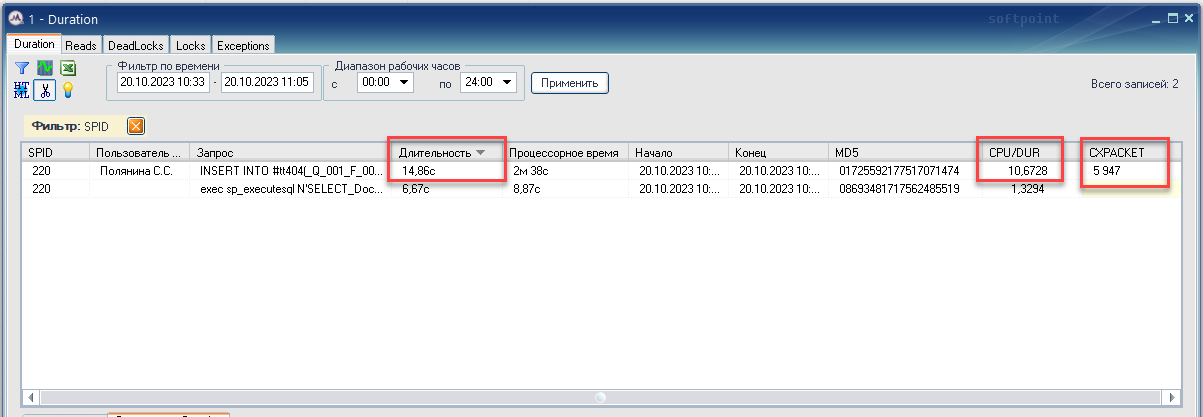
Видно, что запрос распараллелился в среднем на 11 ядер (колонка CPU/DUR показывает отношение суммарного процессорного времени к длительности запроса), выполнялся 14,86 сек и висел на ожиданиях всё те же 5,95 сек.
Теперь построим статистику по этому виду запросов (MD5 01725592177517071474) за весь день и увидим как этот запрос себя ведет в другие периоды.
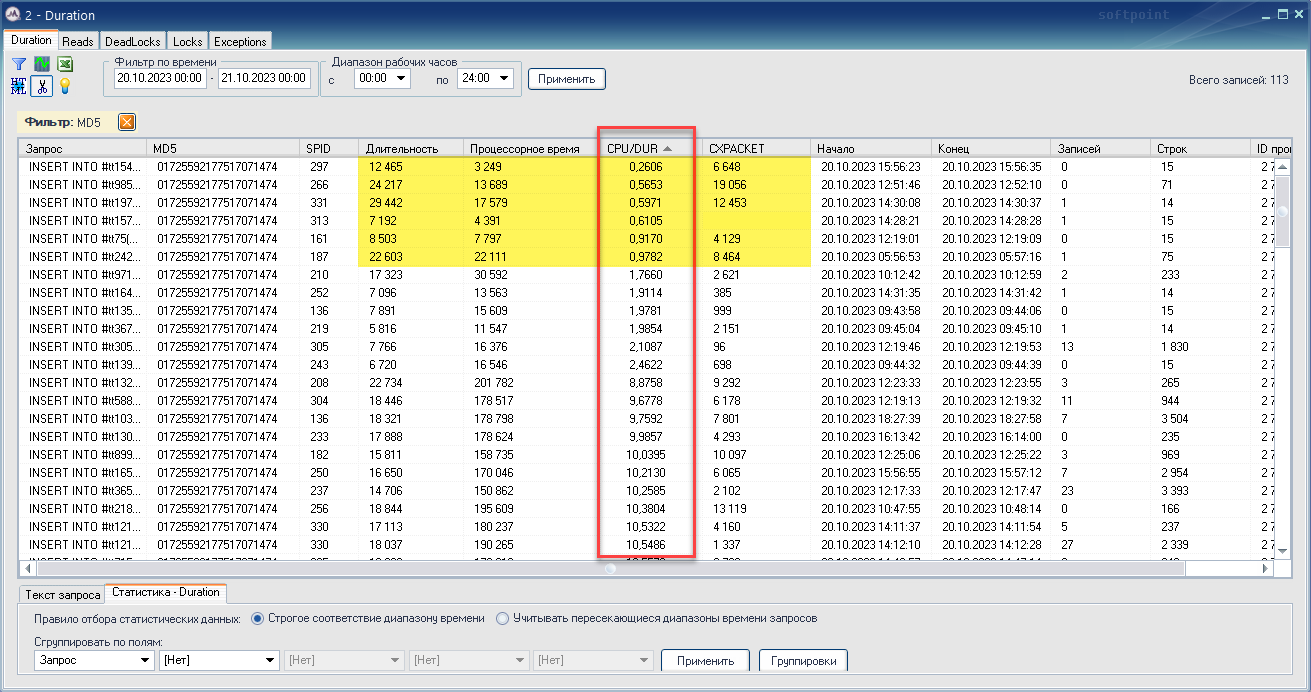
Статистика отсортирована по колонке CPU/DUR. За исключением первых шести строк, где CPU/DUR < 1, видно, что выгода от параллелизма есть, даже с учетом CXPACKET. Но этот вывод не является 100% достоверным. Т.к. мы не знаем, как бы повел себя тот же самый запрос при выключенном параллелизме, выполняясь на одном ядре. Поэтому подход по работе с параллелизмом должен носить итерационный характер с постоянным мониторингом.
Описание методики выставления параметров параллелизма
Хочу сразу отметить, что параметр «max degree of parallelism» можно выставить в настройках сервера, в настройках БД, а также в виде хинта в запросе. При этом 1С: Предприятие не дает возможности выставить хинт в тексте запроса, поэтому для всего семейства приложений 1С остаются настройки только на уровне базы данных или всего сервера СУБД. Настройку «cost threshold for parallelism» можно выполнить только для всего сервера.
Предположим, есть такая вводная: первоначальный уровень параллелизма в БД неограничен (либо просто больше 1), есть дедлоки на параллелизме, жалобы пользователей.
1. В трассе DURATION, где мониторинг собирает все запросы длительностью более 5 сек, группируем все запросы по их виду (MD5) и сортируем по колонке »% Доля CXPACKET». Так мы получаем ТОП10 — ТОП20 запросов, которые ожидают на параллелизме наиболее долго. По нашей практике, если кроме этого, проанализировать взаимоблокировки за тот же период, то более 80% дедлоков будут именно на запросах из отобранного ТОП«а.

,
2. Следующим шагом убираем параллелизм в базе данных в »1» и наблюдаем как изменилась трасса по отобранным запросам.
На рисунке ниже показаны две трассы DURATION по одним и тем же запросам (из п.1) за два периода. Верхняя трасса — с неограниченным параллелизмом, нижняя трасса — параллелизм выключен. Интересует колонка со средней длительностью.

Часть запросов во второй трассе уже отсутствует (хронологически она собиралась позже), значит они стали выполняться либо быстрее и их длительность стала менее 5 сек., либо просто не выполнялись. На рисунке они отмечены красным в колонке MD5. Те, которые были в количестве 1–2 шт., скорее всего просто не выполнялись, а вот остальные — кандидаты на то, что для них параллелизм как раз не нужен и оказывает, скорее, негативное влияние, в один поток они выполняются быстрее.
Есть еще последняя фиолетовая строчка с запросом, который выполняется в один поток однозначно быстрее (6 секунд против 4 минут). Но таких запросов меньше десятка и тут нужно понаблюдать дальше.
Зато остальные запросы, наоборот, стали выполняться дольше. По ним получили просадку производительности. Некоторые из них я отметил цветами в колонке «Средняя длительность».
Конечно, сравнивать глазами две трассы не очень удобно. Для этого есть специальный отчет по сравнению данных из разных трасс, по разным фильтрам, разным периодам и разным показателям. Здесь на вход отчета я подал список MD5, периоды и указал в каких трассах анализировать данные.

Итак, мы получили картину при крайних позициях параллелизма, теперь нужно с этим что-то сделать.
Большинство запросов, которые хорошо параллелятся, несмотря на большую долю ожидания CXPACKET в общей длительности запроса, все равно имеют выигрыш перед их выполнением в один поток. Поэтому, закрутив, как советует 1С, краник параллелизма (MAXDOP = 1) мы получили в целом просадку производительности всей системы и выигрыш лишь у малого количества запросов. И так будет почти во всех системах, в которых присутствует буквально десяток запросов, которые при параллелизме могут внести негатив в систему.
Стратегия 1
Самое простое, с чего стоит начать — подобрать оптимальную комбинацию «max degree of parallelism» и «cost threshold for parallelism». Первым мы ограничим в принципе возможность использования ядер больше, чем укажем. А стоимостью параллелизма можно запретить параллелиться многим запросам, если у них стоимость того или иного оператора в плане запроса будет ниже указанного порога. Не самая тонкая настройка. Но других вариантов у штатных инструментов для работы с параллелизмом в 1С-системах нет.
Это итерационный подбор баланса: меняем MAXDOP, смотрим результат, опять меняем MAXDOP, смотрим результат. Пробуем поднять или опустить COST, опять смотрим результат. И т.д.
Какие запросы обычно хорошо распараллеливаются в 1С? В первую очередь, что-то внетранзакционное, например, многие отчеты. И когда пользователь формирует отчет за 2 минуты при работающем параллелизме вместо 20 минут при выключенном параллелизме он, несомненно, радуется. И расстраивается, если наоборот. Поэтому баланс здесь нужно искать еще в пользовательской плоскости. Кто может подождать, а для кого простои в работе не приемлемы.
В конечном итоге можно подобрать достаточно удачную комбинацию. Но не всегда.
Стратегия 2
Эта стратегия более тонкая и предполагает использование внешнего инструмента Softpoint QProcessing. В других статьях я уже приводил несколько практических кейсов работы с ним. Кому интересно, посмотрите .
Основная идея — ограничение или, наоборот, увеличение значение MAXDOP для конкретного запроса. Кратко напомню, что QProcessing представляет собой программный прокси-сервер, который устанавливается между приложением (сервером приложений) и сервером баз данных SQL Server.

Соответственно, он по определенному правилу (ам) может перехватить любой запрос и модифицировать его, установив ему хинт. На рисунке выше как раз есть пример, где Запросу 3 добавляется хинт MAXDOP 10.
Таким образом, возвращаясь к нашему примеру, не обязательно сбрасывать MAXDOP в 1 для всех запросов. Можно всего лишь нескольким запросам указать хинт MAXDOP 1, а остальные будут выполняться с большой степенью параллелизма, как и ранее.
То есть QProcessing позволяет «хирургическим образом», выборочно устанавливать запросу максимальную степень параллелизма, с которой он может выполняться. А для остальных запросов будет действовать ограничение из глобальных настроек БД или сервера.
ИТОГО
Я показал две стратегии, по которым можно управлять параллелизмом в базе данных. Первая подразумевает использование только штатных настроек SQL Server. А во второй, в дополнение к первой, используется программа QProcessing для тонкой настройки параллелизма не на уровне всей БД, а на уровне отдельных запросов. Это стратегии, не алгоритмы! Так как вариаций может быть множество.
Больше чем в половине ИТ-систем 1С, с которыми к нам приходят на аудиты или на поддержку MAXDOP выставлен в »1». Вендор рекомендовал ставить единицу, значит единица. Иногда параллелизм, действительно вреден системе и никакими комбинациями «max degree of parallelism» + «cost threshold for parallelism» не получается добиться улучшения производительности. Но в основном, как раз наоборот, в системе есть хороший задел для линейного ускорения части запросов.
Основная мысль, которую хотелось донести — это то, что не нужно бояться параллелизма. Нужно лишь качественно провести анализ и системно менять параметры параллелизма. Самое трудозатратное в этом процессе — это отслеживание динамики поведения ИТ-системы после каждой итерации. Не хватает терпения, не хватает инструментария для удобного анализа. Мы используем в своей повседневной работе мониторинг Perfexpert. Если интересно ознакомиться с его возможностями, то милости прошу на наш сайт https://softpoint.ru/solutions/perfexpert/. А практические кейсы с ним мы описываем почти во всех наших статьях: https://habr.com/ru/companies/softpoint/articles/.
Ссылки на остальные части Записок оптимизатора1С:
Записки оптимизатора 1С (часть 1). Странное поведение MS SQL Server 2019: длительные операции TRUNCATE
Записки оптимизатора 1С (часть 2). Полнотекстовый индекс или как быстро искать по подстроке
Записки оптимизатора 1С (Часть 3). Распределенные взаимоблокировки в 1С системах
