Зачем системному аналитику читать «Чистую архитектуру» Роберта Мартина
Меня зовут Сергей Марков, я системный аналитик бэковой части в Академии Инвестиций Тинькофф.
Системные аналитики работают в разных направлениях: сбор и управление требованиями, проектирование бизнес-процессов, техническое проектирование системы. Список задач можно расширять и детализировать дальше. В зависимости от сферы, размера и культуры компании обязанности системного аналитика могут быть разными. У нас в Тинькофф для системного аналитика делается довольно сильный акцент на технические знания и навыки.
В этой статье расскажу про книгу «Чистая архитектура». В кратком содержании я перечислил и постарался подсветить главы именно для системного аналитика, а еще добавил примеров из практики. Надеюсь, помогу почерпнуть самое полезное в контексте потребностей системного аналитика.
Зачем системному аналитику читать книги про архитектуру

Специальности в ИТ хоть и разделены, но пересекаются между собой. Системному аналитику может быть полезна «Чистая архитектура», если он: — проектирует верхнеуровневую архитектуру (HAL, High level architecture); — составляет контракты OpenAPI, Protobuf; -использует любой стандарт, который можно превратить в объектную модель в коде, особенно когда сложность контрактов подразумевают агрегацию, наследование; — читает код, чтобы провести обратную инженерию; — проектирует базы данных; — хочет больше понимать проблематику разработки ПО и ему интересны технические аспекты (в качестве альтернативы системный аналитик может углубляться в проектный менеджмент либо продуктовую деятельность).
«Чистая архитектура» написана для архитекторов, но архитектор архитектору рознь. Есть термин «архитектор решений» — solution architect. Книга в первую очередь предназначена для архитектора решений, но будет полезна и разработчику.
Если читать планирует системный аналитик, то итог зависит от ожиданий. В каждой компании системному аналитику нужен разный уровень погружения в техническую сторону. В нашей команде системный аналитик должен довольно хорошо знать техническую часть. Это круто и ответственно одновременно.
Для системных аналитиков, готовых погрузиться в технику, я нашел 10—12 полезных глав, о которых хочу рассказать. Если вы нашли больше — жду в комментариях :)
Книга строится так, что в последующих главах автор постоянно ссылается на предыдущие. Поэтому не стоит расстраиваться, если в начале будет не все понятно. Полезный выхлоп далеких от аналитика глав в том, что можно лучше понять проблемы проектирования ПО и говорить с разработчиками и архитекторами на одном языке. Гораздо проще, когда разработчик озвучивает на дейли-стендапе, что он «будет решать проблему циклической зависимости сборок», а вы точно понимаете, что он имеет в виду.
После прочтения принципы SOLID не перестанут быть «вездезвучащими», если было такое ощущение. СА будет понимать их значение и они станут полезными и применимыми. Если в работе часто приходится читать код, то книга поможет понять, для чего «вот тут и здесь» применили те или иные шаблоны проектирования или абстракции.
Чистая архитектура — не панацея. Все рекомендации, приведенные в книге, вытекают из опыта автора, они помогут сэкономить время, деньги и труд. Этому посвящено много примеров. Но «Чистая архитектура» скорее формирует вектор, к которому нужно стремиться. Вряд ли нужна чистая архитектура, когда вы сразу знаете, что срок использования ПО короткий (несколько месяцев), либо когда ваша задача сделать демопроект, показать его возможности заказчику и при успехе построить все с нуля. Лично я знаю несколько успешных стартапов, которые быстро поднялись, имея много архитектурных ляпов, а потом сделали крупные рефакторинги, имея стабильную выручку и известность.
Краткое содержание, переосмысленное для системного аналитика
Роберт Мартин охватывает в книге 50+ лет опыта разработки. Для меня такой срок — уже веский повод узнать о накопленном опыте.
Пожалуй, одна из главных мыслей:
«Все архитектуры подчиняются одним и тем же правилам!»
Это звучит особенно интригующе с учетом того, как поменялись компьютеры:
»…процессоры с тактовой частотой в полмегагерца, 4 Кбайт оперативной памяти, 32 Кбайт дисковой памяти и интерфейс телетайпа со скоростью передачи данных 10 символов в секунду…»
»…MacBook, оснащенный процессором i7 с четырьмя ядрами, каждое из которых действует на тактовой частоте 2,8 ГГц, имеющий 16 Гбайт оперативной памяти, 1 Тбайт дисковой памяти (на устройстве SSD) и дисплей с матрицей 2880 × 1800…»
С другой стороны, качественно мало что поменялось. Компьютеры также состоят из процессора, оперативной и постоянной памяти. Оперативная — быстрая и, как правило, энергозависимая. Постоянная — значительно медленнее оперативной, превосходит ее по размеру и энергонезависима. Думаю, именно из-за того, что компьютеры качественно не изменились, правила чистой архитектуры тоже остаются прежними. В книге 34 главы, хочу рассказать про самые релевантные для системного аналитика.
Глава 1. Что такое дизайн и архитектура
Объясняет, для чего нужна продуманная архитектура, с экономической точки зрения. Подойдет, если нужно аргументировать, зачем тратить усилия на архитектуру, человеку, который платит за ПО.
Главы с 3 по 6 рассказывают про три парадигмы программирования. Для меня знать, что есть парадигмы программирования, так же важно, как знать о наличии разных языков программирования. Парадигмы языков программирования — вещь основополагающая. Интересный факт: все три известные парадигмы были открыты в течение 10 лет — с 1958 по 1968 год — и больше парадигм придумано не было.
Глава 4. Структурное программирование
Структурное программирование избавило нас от goto, дало if/then/else и do/while. Важны даже не сами операторы, а то, что они дали возможность декомпозировать — превращать сплошные куски кода в функции.
Как известно, декомпозиция применяется не только в разработке, но и во всей инженерии в целом. На декомпозиции строится очень многое: градостроитель проектирует район, архитектор проектирует дом, дизайнер — пространство квартиры. В программировании тоже нужна возможность мыслить разными уровнями абстракции, что и дало структурное программирование.
Глава 5. Объектно-ориентированное программирование
Главное, что дает объектно-ориентированное программирование архитектору, — это управление зависимостями между модулями. Так все, что не должно влиять на бизнес-логику, можно превратить в набор плагинов. Плагины зависят от бизнес-логики, но не наоборот. Под плагинами понимается хранилище данных, графический интерфейс, интерфейс ввода-вывода и так далее. Эта мысль будет еще много раз упоминаться в книге.
Глава 6. Функциональное программирование
Когда-то мне казалось, что функциональные языки программирования нужны для того, чтобы компактнее писать код, который делает выборку данных. Но это лишь внешнее проявление и один из узких аспектов. Важно, что функциональные языки ограничивают нас в изменении переменных.
Почему это ограничение так важно? Если в программе нет изменяемых переменных, она никогда не окажется в состоянии гонки (race condition), не столкнется с проблемами одновременного изменения и не попадет в состояние взаимоблокировки (deadlocks). Роберт Мартин подчеркивает, что такая ситуация на практике достижима лишь в идеальном мире, когда:
»…у вас есть неограниченный объем памяти и процессор с неограниченной скоростью вычислений…»
К идеальному миру можно приблизиться за счет пары компромиссов:
Делить систему на неизменяемые и изменяемые компоненты. Неизменяемые решают свои задачи функциональным способом, а изменяемые работают с неизменяемыми компонентами и транзакционной памятью.
Избавить систему от изменяемых переменных за счет отказа от операций обновления (U), удаления (D) хотя бы для ряда сущностей. Так от CRUD-операций, останутся только CR-операции.
Этот подход вполне жизнеспособен, его применение скажется на модели данных в базе данных. Хотя системный аналитик у нас в команде не отвечает за модель данных, но всячески приветствуется, когда он приходит с задачей, в которой продумана структура БД.
Главы с 7 по 11 рассматривают принципы SOLID, которые часто озвучиваются разработчиками и редко обсуждаются системными аналитиками. На мой взгляд, их стоит рассмотреть. Ряд принципов полезен для составления контрактов OpenAPI, в моделировании применяемых классов и связях между ними. Многие принципы справедливы для более высокого уровня абстракции — уровня сборок и для модулей HAL.
Глава 7. Принцип единой ответственности, Single Responsibility Principle
Мне нравится интерпретация: «Класс должен иметь одну и только одну причину для изменений».
Системному аналитику этот принцип будет полезен при проектировании классов контракта OpenAPI. Допустим, нужно добавить в контракт два метода: получение заказа по идентификатору getOrder и получение списка активных заказов getActiveOrders. Может возникнуть соблазн использовать одну и ту же модель в качестве выходного типа Order.
Чтобы понять, насколько это верное решение, нужно ответить на вопросы: «При дальнейших доработках наших методов оба объекта заказа будут развиваться одинаково?» или «Ответу одного метода потребуется один набор полей, а ответу другого метода — другой набор новых полей?», «Потребители методов getOrder и getActiveOrders одинаковые или разные?».
Если правильно ответить на эти вопросы и разделить выходные модели методов, то в будущем, при доработке, например, getOrder, не потребуется переносить поля в getActiveOrders для поддержки изменения в общей модели Order. В итоге просто будут две независимые модели — Order и ActiveOrder.
Может быть и наоборот: если выходные модели живут по общим правилам, то разумно оставить одну модель.
Принцип SRP актуален и для уровня компонентов, но называется он принципом согласованного изменения — Common Closure Principle. А на архитектурном уровне — принцип оси изменения, Axis of Change.
Глава 8. Принцип открытости/закрытости, Open-Closed Principle
Звучит он так: «Программные сущности должны быть открыты для расширения и закрыты для изменения». То есть должна быть возможность дорабатывать систему, минимально изменяя существующее поведение.
Этот принцип важен для системных аналитиков, когда нужно делать обратно совместимые изменения в API. Как больно и долго нужно отказываться от старых методов API и переезжать на новые из-за того, что в текущем API не удается сделать обратно совместимые изменения. Яркий пример — API для мобильных телефонов, когда пользователи не хотят обновляться на новую версию приложения.
Предположим, что заказу Order из главы 7нужно добавить признак оплаченного. Казалось бы, достаточно добавить поле IsPaid типа bool.
// Пример того, как может выглядеть заказ
Order:
description: Заказ
type: object
required:
- id
- createdAt
- isPaid
- products
properties:
id:
description: Уникальный идентификатор
type: string
format: uuid
createdAt:
description: Дата и время создания
type: string
format: date-time
isPaid:
description: Оплачен ли заказ
type: boolean
default: false
products:
type: array
items:
$ref: '#/components/schemas/Product'
Не нарушится ли принцип OCP? Что делать, если через некоторое время продакт-менеджер захочет ввести возможность частичной оплаты для повышения продаж? Ввести признак IsPartiallyPaid? Удалить булевое поле IsPaid и добавить перечисление? Тогда это не обратно совместимое изменение и принцип OCP будет нарушен.
Order:
description: Заказ
type: object
required:
- id
- createdAt
- isPaid
- products
properties:
id:
description: Уникальный идентификатор
type: string
format: uuid
createdAt:
description: Дата и время создания
type: string
format: date-time
paymentOption:
$ref: '#/components/schemas/PaymentOption'
products:
type: array
items:
$ref: '#/components/schemas/Product'
PaymentOption:
description: Варианты оплаты
type: string
enum: [ unpaid, partially-paid, paid ]
В этом частном примере правильнее сразу использовать перечисляемый тип: тогда в новых версиях API можно будет безболезненно добавлять новые значения перечислений в существующее поле
Принцип ОСР полезен системному аналитику и на более высоких уровнях абстракции — на уровне HAL. Многие команды разработки используют итеративно-инкрементальный подход: когда каждая новая итерация несет небольшой инкремент к функциональности. Каждый такой инкремент должен по максимуму добавлять и по минимуму изменять существующую функциональность. Автор раскрывает этот принцип на примере системы финансовой отчетности.
Глава 9. Принцип подстановки Барбары Лисков, Liskov substitution principle
На мой взгляд, этот принцип мало употребим в работе СА: последствий от его нарушения явно не видно. Но понимание, как базовый класс и наследование в контракте OpenAPI способны в ряде случаев избавить программиста от множества if в коде, очень полезно.
Глава 10. Принцип разделения интерфейсов, Interface Segregation Principle
ISP применим к классам и интерфейсам, а системному аналитику он интересен на уровне архитектуры системы.
Например, команда работает над системой S и решила подключить к системе фреймворк F. Фреймворк F, в свою очередь, использует базу данных D, выстроилась связь S → F → D. S зависит от F, F зависит от D. Теперь, если потребуется сделать изменения в D, может потребоваться развернуть фреймворк F и повторно развернуть S. При этом система S вообще может не использовать изменения функциональности D.
Защитить систему от нежелательных зависимостей можно, если разделить систему S и фреймворк F на уровне кода. Система S должна вызывать фреймворк F не напрямую, а через интерфейс. Интерфейс должен включать в себя только тот набор методов, который необходим системе S, а не весь набор функциональности, который предоставляется F. Так уменьшается зависимость нашей системы от фреймворка и базы данных. Вместо фреймворка может быть просто компонент, который разрабатывает соседняя с вами команда или сторонняя организация. Случай с фреймворком будет рассмотрен еще и в 32 главе.
Глава 11. Принцип инверсии зависимости, Dependency Inversion Principle
Этот принцип утверждает, что наиболее гибкими получаются системы, в которых зависимости в исходном коде направлены на абстракции, а не на конкретные реализации. Кажется, что это не так важно для системного аналитика, потому что он реализуется в исходном коде. Но в будущих главах автор будет часто ссылаться на этот принцип, рассказывая про уровень модулей (в данном контексте — модулей архитектуры).
Поэтому системному аналитику будет полезно узнать:
Есть случаи, когда направление зависимостей между модулями важно. Пример: слой доступа к данным и слой графического интерфейса должны зависеть от бизнес-логики, а не наоборот.
За счет абстракций на уровне языка программирования любую зависимость можно развернуть в обратную сторону там, где это необходимо.
Первое утверждение будет раскрыто в главах 19, 20, 22. Второе утверждение рассмотрим на примере.
Возьмем систему управления заказами:
 В архитектуре системы есть слой доступа к данным и слой бизнес-логики
В архитектуре системы есть слой доступа к данным и слой бизнес-логики
Классу бизнес-логики OrderService нужно получить заказ через OrderRepository, чтобы затем его обработать. Чтобы создать объект сервиса, нужно передать в конструктор объект репозитория. То есть OrderService зависит от OrderRepository. Любое изменение в сигнатуре метода getOrder (type), например добавление нового поля, ломает класс, относящийся к бизнес-логике.
Применим принцип инверсии зависимости:
 Мы определили интерфейс IOrderRepository. Важно, что интерфейс определен на стороне бизнес-логики, о чем показывает двойная линия архитектурной границы
Мы определили интерфейс IOrderRepository. Важно, что интерфейс определен на стороне бизнес-логики, о чем показывает двойная линия архитектурной границы
Теперь реализация OrderRepository обязана следовать интерфейсу. Если сигнатура метода getOrder (type) будет переопределена без ведома слоя бизнес-логики, то уровень доступа к данным просто не скомпилируется.
Обратите внимание: стрелочка зависимости на верхнеуровневой архитектуре развернулась так, что теперь слой доступа к данным зависит от бизнес-логики, а не наоборот.
Глава 14. Сочетаемость компонентов
Компоненты в данном контексте — это единицы развертывания: jar-файлы для Java, dll-файлы для .NET и далее. Если уровень классов полезен системному аналитику в контексте разработки контрактов API, уровень модулей полезен в разработке верхнеуровневой архитектуры, то про уровень компонентов системному аналитику рассуждать обычно не приходится. В данном случае единицу развертывания называют компонентом в русском переводе книги. Возможно, вы, как и я, привыкли называть единицу развертывания сборкой или модулем. Будьте внимательны :)
Эти главы можно отметить как «полезно изучить». Вот некоторые тезисы:
Существуют принципы эквивалентности повторного использования, согласованности изменений и совместного повторного использования. Они объясняют, по какому принципу те или иные классы стоит объединять в сборки. Правильное разбиение классов на сборки позволяет командам разрабатывать и разворачивать сборки независимо.
Принцип ацикличности зависимостей объясняет, почему может возникнуть циклическая зависимость сборок, почему это плохо и как ее устранить.
Глава 15. Что такое архитектура
Эта глава звучит как развитие главы 1, но только технический аспект архитектуры раскладывается на составляющие. Систему с продуманной архитектурой проще дорабатывать, в нее легче вникнуть новичку, проще разворачивать, она более производительна. В общем, в ней приводятся верхнеуровневые аргументы, но с двумя хорошими примерами.
Глава 16. Независимость
Продолжение предыдущей главы с подробностями о том, на каких уровнях можно делить систему на независимые части: на уровне исходного кода, развертывания (сборок) или микрослужб. Ни один из способов не является панацеей. Что выбрать — раскрывается лишь в нескольких абзацах, потому что тема достойна отдельной книги про проектирование микросервисной архитектуры.
Пометил как «полезно изучить», потому что часто встречаются команды, в которых системный аналитик активно участвует в формировании набора сервисов системы.
Глава 17. Границы: проведение разделяющих линий
В этой главе говорится про архитектурные границы. Как их проводить, между какими частями системы и когда. Можно думать, что достаточно разделить систему на сборки либо на сервисы и все сервисы и сборки можно вкладывать независимо друг от друга. Но неправильно проведенная архитектурная граница будет проходить не между микросервисами, а внутри них. Получится, что и физически разделенные сервисы придется дорабатывать и выкладывать одновременно.
Глава 19. Политики и уровень
Несколькими главами ранее рассматривалась терминология политик и плагинов. Политики в большей мере относятся к бизнес-правилам. Плагины — к слою ввода-вывода, хранилища и API. Эта глава о том, что политики бывают разных уровней: одни реализуют бизнес-правила, другие определяют оформление отчетов, третьи валидируют входные данные. Политики, изменяющиеся по разным причинам или в разное время, должны находиться на разных уровнях.
Это отсылка к принципу единой ответственности SOLID — SRP. Чем дальше политика от ввода-вывода, тем выше ее уровень.
Глава 20. Бизнес-правила
Политикам и их уровням из главы 19 можно дать названия. Политика самого высокого уровня — это критические бизнес-правила. Часто критические бизнес-правила подразумевают самые основополагающие правила бизнеса, которые реализует система. Например, правила расчета графика платежей на основе процентной ставки и срока действия кредита. Данные, необходимые для подсчета этого правила, называют критическими бизнес-данными. Бизнес-правила и бизнес-данные образуют самый высокий уровень.
Часто отличительный признак критических бизнес-правил в том, что они существовали бы, даже если бы не было информационных систем. В случае кредита график платежей может жить на бумаге.
Политики уровнем ниже являются вариантами использования. Они зависят от бизнес-правил, но не наоборот. Пример варианта использования — шаги получения кредита через мобильное приложение. Правильно сформированный вариант использования абстрагируется от графического интерфейса или уровня доступа к данным.
В технической документации есть аналог критических бизнес-правил и вариантов использования. И часто в документации бизнес-правила выделяются в отдельный раздел, а варианты использования ссылаются на бизнес правила. Пожалуй, текущая глава только подтверждает, что подобное разделение имеет смысл как на уровне кода, так и на уровне документации.
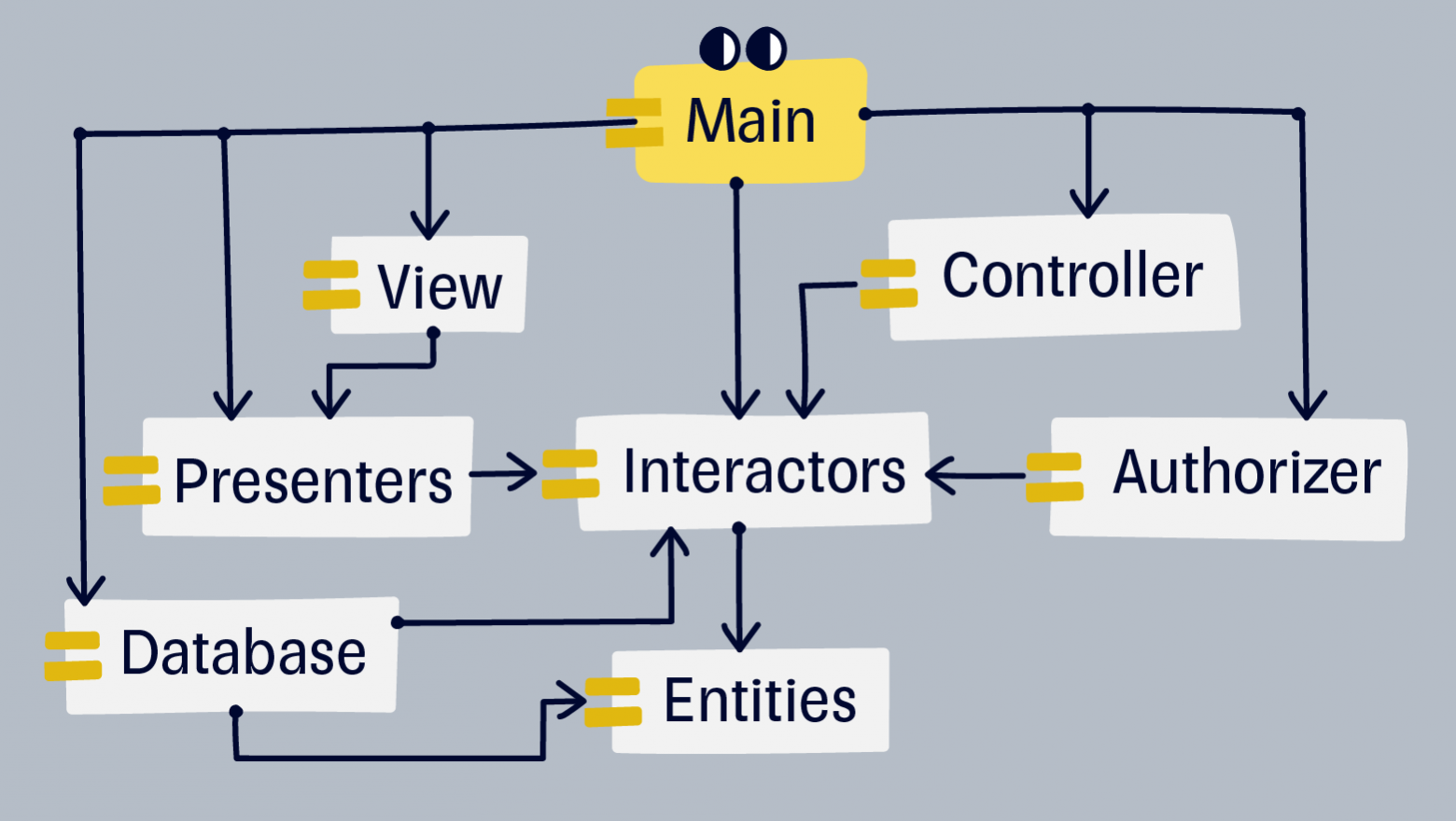
Глава 22. Чистая архитектура
Итогом 19 и 20 глав становится диаграмма описывающая чистую архитектуру. Чистая архитектура — это луковица из 3—5 слоев. Число слоев может быть разным от системы к системе. Каждый внешний слой луковицы зависит от ближайшего внутреннего. Внутренний слой не зависит ни от чего. Эта интерпретация чистой архитектуры объясняет, почему «критические бизнес-правила» иногда называют ядром системы.
 Диаграмма чистой архитектуры с примером слоев
Диаграмма чистой архитектуры с примером слоев
Глава 23. Презентаторы и скромные объекты
Глава про шаблон MVP и про то, как его применение позволяет покрыть юнит-тестами как можно больше функциональности. Основная идея в том, чтобы вынести как можно больше функциональности в Презентаторе и как можно меньше оставить в Представлении.
Покрыть юнит-тестами презентатор относительно несложно. А представление будет проверяться вручную, зато там останется минимум функциональности, что упростит ручное тестирование.
Главы с 24 по 26 слишком конкретны. Системный аналитик в состоянии в них разобраться, но непосредственно в работе это применить не удастся.
Глава 27. Службы большие и малые
В главах 16 и 17 говорилось про то, что неправильно проведенным границам не поможет даже разделение системы на независимые физические сервисы. По мнению Роберта Мартина, службы сами по себе не являются архитектурно значимыми элементами. Если проще, то неправильно проведенные архитектурные границы приведут к тому, что при каждой доработке придется дорабатывать и развертывать большую часть микросервисов.
К 27 главе прозвучит довольно банально, но спасение — в принципах SOLID. Они реализуются через паттерны разработки «Шаблонный метод», «Стратегия» и другие паттерны GoF.
Глава 30. База данных — это деталь
В этой главе Роберт Мартин называет базу данных деталью и настаивает на том, чтобы вынести ее на внешний круг архитектуры.
С одной стороны, идея правильная. В главе 17 есть пример с FitNesse, в котором слой обращения к хранилищу был абстрагирован от бизнес-логики, что позволяло авторам проекта легко перейти от файлового хранилища к MySQL.
В 30 главе делается еще более радикальное заявление: диски как способ хранения рано или поздно уйдут в историю. А вместе с ними и умрет необходимость в СУБД.
На практике заменять одну базу данных на другую приходится довольно редко. И мало кто в нашей индустрии разрабатывает промышленную систему, закладывая, что система застанет тот момент, когда от дисков откажутся.
Не воспринимаю эту главу как истину в последней инстанции, истина где-то посередине. Но знать доводы полезно в том числе системному аналитику.
Глава 31. Веб — это деталь
Глава похожа на предыдущую: веб — это деталь, и он должен находиться на внешнем слое архитектуры. В отличие от главы про базу данных, это утверждение звучит менее радикально. Приведу пример проекта на основе майкрософтовского стека.
При своем существовании его UI-слой реализовывался на ASP, затем на ASP.NET WebForms, затем на ASP.NET MVC. И это менее чем за 10-летний срок. Каждый из переходов был оправдан. ASP.NET WebForms дал богатый жизненный цикл обработки страницы на сервере. ASP.NET MVC улучшил тестируемость UI. В каждом из трех случаев клиент получал HTML+CSS. При этом бизнес-логика системы, а это была система управления кадрами, радикально не изменилась. Как и не поменялся радикально трудовой кодекс. Пожалуй, было бы гораздо сложнее, если бы слой UI веб-приложения не был отделен от бизнес-логики.
Глава 32. Фреймворки — это деталь
Может показаться, что применение фреймворка в проекте должно нести сплошные плюсы, ведь кто-то уже сделал часть работы за нас.
В чем проблема применения фреймворка?
С точки зрения архитектуры применение фреймворка чревато сильной связанностью между фреймворком и вашей системой.
Не всегда известно, в каком направлении будет развиваться функционал фреймворка. И есть вероятность, что это будет совсем не тот функционал, который нужен вашей системе.
Фреймворк может не гарантировать вам обратно совместимых изменений.
Список можно продолжить, но и этих пунктов достаточно. Чтобы избежать сложностей, нужно сделать так, чтобы фреймворк был на одном из внешних слоев вашей чистой архитектуры.
Стоит сгладить радикальные взгляды Роберта Мартина и дать менее радикальный совет: нужно проверить, что в бизнес-логику не просачивается код, специфичный для фреймворка. Главным образом решение здесь за разработчиком и архитектором и в меньшей мере — за системным аналитиком.
Вместо заключения
Книга заканчивается архитектурной археологией. Это очень познавательная глава про то какими большими были деревья, когда мы были маленькими историю развития компьютеров и про проекты, которые делал автор. После академических глав последняя глава читается легко — как художественная литература.
Системному аналитику приходится охватывать знания всего технического стека, который применяется в продукте. Но специальных книг с обзорами бэка, фронта, баз и архитектуры нет. Я нашел выход — читать книги по разработке и самостоятельно делать акценты на нужных главах. Надеюсь, для вас это было полезно и познавательно. Буду рад идеям, какие еще книги будут интересны системным аналитикам.
