Зачем мы моделируем импульсные нейронные сети и с помощью чего это делаем
Привет, Хабр! На связи Михаил Киселев, руководитель направления в отделе ИИ компании «Цифрум» (Росатом) и руководитель лаборатории нейроморфных вычислений в Чувашском государственном университете. Сегодня подниму тему импульсных нейронных сетей. Общее представление о том, что такое искусственные нейронные сети, есть, наверное, у всех. Многие представляют, зачем они нужны, как устроены, как работают. Речь пойдет об одной их разновидности — импульсных нейронных сетях (ИНС). Нейросети вообще мыслились их создателями как компьютерные модели ансамблей нервных клеток мозга — это и из их названия следует. У разных типов нейросетей степень этого сходства разная. Так вот, ИНС — это самый похожий на биологический мозг тип нейронных сетей.
За счет этой похожести достигаются немалые преимущества. Прежде всего — энергоэкономичность нейропроцессоров (о них еще скажем ниже) для выполнения ИНС. Дело в том, что в ИНС нейроны посылают друг другу не числа, с которыми приходится делать довольно сложные операции — складывать, умножать, а атомарные объекты — аналоги нервных импульсов, распространяющихся по нервным связям животных и человека. Они называются спайки. Как нервный импульс в биологии, спайк имеет всегда одну и ту же амплитуду и пренебрежимо малую длительность. Поэтому обработка прихода спайка сопряжена с малым числом очень простых операций, что экономит и время, и энергию, и место на процессоре — если импульсный нейрон реализуется на специальном нейпроцессоре. Вторая особенность, отличающая ИНС от традиционных нейросетей, — это асинхронный, независимый от других процессов, характер работы каждого нейрона. Пришел на нейрон спайк — тот на него быстро прореагировал, и снова тишина: энергия зря не тратится… Это разительно отличается от работы обычных нейросеток. Они обычно слоистые, пока один слой не посчитается, следующий должен ждать. А как посчитается — начинается интенсивный поток данных от слоя к слою — надо или не надо — даже если там одни нули передаются. ИНС может непрерывно работать и дообучаться, тратя при этом меньше энергии.
Но почему же тогда мы не видим вокруг себя эти импульсные сети — в смартфонах, камерах, умных часах, умных утюгах?
Во-первых, ИНС во всем очень непохожи на обычные нейросети. Принципы их функционирования, обучения совсем другие. Обычные нейросети изучаются и развиваются уже более 70 лет — начиная с придуманных в 50-х годах прошлого века персептронов. Исследования ИНС имеют раза в три менее длинную историю. Один из основных подходов к их обучению, основанный на так называемой модели пластичности STDP (spike timing dependent plasticity — пластичность, основанная на времени спайков), стал развиваться чуть больше 20 лет назад. Как раз сейчас мы наблюдаем бурный рост исследований ИНС (и не только наблюдаем — мы в нем участвуем). Вторая причина — крайняя неэффективность реализации ИНС на обычных компьютерах. Можно сказать, что в них все наоборот по сравнению с ИНС: вместо миллионов крайне простых асинхронно работающих специализированных обработчиков спайков — десяток универсальных и потому чрезвычайно сложно устроенных процессоров, обрабатывающих числа с помощью последовательно выполняемых команд; вместо совмещения в одном месте памяти и процессора (когда приходящий спайк сразу активирует и передает для дальнейшей обработки соответствующий синаптический вес) — бесконечное перемещение по шине команд и данных из памяти в процессор и обратно. Поэтому разработка специализированных нейрочипов для ИНС крайне актуальна.
Какие задачи мы решаем сегодня
Обучение ИНС
Это ключевой вопрос. Нейронные сети огромны. Это касается и биологических сетей (например, в мозге пчелы около миллиона нейронов), и традиционных нейросеток (известная лингвистическая нейросетевая модель GPT-3 — примерно в два раза больше мозга пчелы), и ИНС. Нейросети делают свою полезную работу, в первую очередь, благодаря тому, что вес связей между их нейронами имеет некоторые оптимальные величины. Связей настолько много, а их влияние на результат работы сети настолько сложно, что установить эти оптимальные величины вручную абсолютно невозможно — это может быть только результатом процесса, который и называется обучением сети.
Как обучать традиционные нейронные сети, известно уже лет 50. Помогает здесь то, что традиционная нейронная сеть является с математической точки зрения непрерывной функцией, как от ее входов, так и от весов ее связей. Поэтому, немного изменяя вес любой ее связи, мы можем сказать, лучше стало или хуже — например, увеличилась ошибка предсказания или нет.
Функционирование импульсного нейрона носит дискретный характер. Спайк — он либо есть, либо нет. Поэтому малое изменение веса любой связи в ИНС скорее всего вообще никак не скажется на работе ИНС в целом. Поэтому принципы обучения ИНС совсем другие. В основе принцип локальности. Он гласит, что изменение веса связи (чаще говорят — синапса) может зависеть только от состояния и активности нейронов, связанных этим синапсом. Принцип этот известен давно, однако его конкретные реализации могут быть самыми разными, и вот поиск наилучшей реализации является важнейшей исследовательской задачей, решаемой нашим коллективом. Точнее говоря, оптимальных законов изменения синаптических весов в процессе обучение сети может быть несколько — в зависимости от того, какую задачу обучения мы решаем. Обычно выделяют 3 класса задач обучения:
1) Обучение без учителя (unsupervised learning). Обычно нейросети получают на вход огромное количество данных. Например, в какой-нибудь классической задаче классификации изображений (скажем, найти по поисковому запросу все картинки, где есть автомобиль) на вход подается картинка — матрица из десятков тысяч (а то и сотен тысяч или миллионов) чисел, значений яркости пикселей. Яркость отдельного пикселя не несет практически никакой информации о том, есть на картинке автомобиль или нет. А вот сочетания этих яркостей, образующие некоторые структурные признаки (например, наличие чего-то круглого на картинке), уже может быть ценным информативным признаком (например, это круглое может быть колесом). Но разных структурных признаков можно придумать великое множество… И тут помогает обучение без учителя. Если значительную долю предъявляемых фотографий будут составлять автомобили, там круглые структуры будут встречаться часто. Если будет много снимков природы (которая, как известно, не знает колеса), там будет много структур с горизонтальными границами (если это пейзажи — горизонт), либо, например, с тонкими линиями (деревья, их ветки). Выделяя информативные признаки, нейросеть не знает, с чем она работает — ей не говорят, автомобили это или природа. Она просто «видит», что данный структурный признак встречается часто и в устойчивом сочетании с другими структурными признаками, фиксирует этот факт, образуя структурный признак более высокого порядка. В этом режиме сеть не знает правильных ответов — именно поэтому его называют обучением без учителя. Однако выделенные информативные признаки будут ценным подспорьем в следующем типе задач — обучении с учителем.
2) Обучение с учителем (supervised learning). Самый известный, классический вариант обучения. Сети предъявляют много пар «входные данные, правильный ответ». После этого сеть должна по новым входным данным, ранее ей не предъявленным, дать правильный ответ. Например, как во всем известном тесте MNIST, сети дают 60000 пар «изображение рукописной цифры, изображенная цифра», после чего она по новому предъявленному ей изображению должна сказать, какая цифра изображена.
3) Обучение с подкреплением (reinforcement learning — RL). Самый реалистичный, имеющий отношение к жизни вариант обучения, то, как учимся мы сами. В этом варианте сеть взаимодействует с окружающим миром: виртуальным или реальным. Она получает непрерывный поток информации, описывающей состояние мира и ее положение в нем, и отвечает на него сигналами — командами, которые интерпретируются как действия, меняющие состояние мира и ее самой. Эти действия сети оцениваются в виде сигналов поощрения или наказания с точки зрения задачи, которую сеть должна решать. Сигналы могут поступать как сразу после действия сети, так и со значительной задержкой, что создает дополнительные трудности, так как приводит к неясности, что именно сеть сделала хорошо или плохо. В RL сеть должна сама догадаться, что от нее хотят, и выстроить так свое поведение (генерируемые ей команды), чтобы получать как можно больше поощрений и как можно меньше наказаний.
Наша группа занимается в какой-то степени всеми тремя видами обучения, но акцент делаем на RL — обучении с подкреплением.
Получаемый сетью поток данных должен быть структурирован, из него должны быть выделены информативные признаки (а это — обучение без учителя), а целевые состояния, чего сеть должна достичь, должны быть распознаны (обучение с учителем). Наша цель — создание активных интеллектуальных систем, решающих поставленные задачи не по жестко заданному запрограммированному алгоритму, а в условиях недостаточно ясной, меняющейся обстановки с учетом успехов и неудач их предыдущей деятельности. Такие системы должны непрерывно обучаться на примерах. Именно так ставятся задачи в робототехнике, системах автоматического адаптивного управления сложными системами и других важных для Росатома областях применения.
В этой связи вспомним об ИНС. Совершенно очевидно, что преимущества ИНС, о которых было сказано в начале, тут должны быть особенно актуальными. Энергоэкономичность, асинхронность, свободный обмен потоками информации (в виде спайков) с внешним миром, непрерывное обучение в виде постоянного подстраивания синаптических весов без искусственного разделения данных на обучающую и тестовую выборки — все это как нельзя более подходит к упомянутому кругу задач. С одним только НО: архитектуры ИНС, методы их обучения, эффективные с точки зрения задач RL, еще не найдены…
Разработка перспективных нейрочипов
Эта деятельность только недавно стала для нашей группы приоритетной, поэтому результатов здесь пока получено совсем немного. К тому же эта новая междисциплинарная область требует отдельного рассмотрения.
Мало кто до сих пор осознает, что совсем недавно в микроэлектронике произошло революционное событие. Была создана микросхема, нейропроцессор, эмулирующий ИНС, являющийся, с одной стороны, универсальным вычислителем (а доказано, что ИНС — это универсальный вычислитель, равномощный машине Тьюринга), а, с другой стороны, не имеющий стандартной для всех наших компьютеров фон-Неймановской архитектуры с центральным процессором, памятью, очередью команд. Речь идет о нейрочипе TrueNorth компании IBM.
Это произошло в 2014. С тех пор взгляд на такие чипы как на основу будущего технологического прорыва все расширялся, был создан еще примерно десяток аналогичных чипов, фактически сформировалась еще одна всемирная гонка технологий. Участие в ней предполагает решение разнообразных прикладных и научных проблем. И одна из них имеет прямое отношение к работе нашей группы. Эффективность реализации ИНС в специализированном нейрочипе зависит прежде всего от нахождения удачных компромиссов между функциональными возможностями нейрона, гибкостью и универсальностью правил изменения синаптических весов и жесткими ограничениями реализации всего этого «в железе» — в терминах количества транзисторов, энергопотребления, реализуемых математических операций. Этим мы и занимаемся — создаем hardware-friendly архитектуры сетей, модели импульсных нейронов, методов их обучения в расчёте на то, что когда-то это все будет оформлено в виде технологических процессов печати ASIC.
Но оставим в стороне вопросы «железа» и вернемся к теоретическим и программным аспектам.
Немного подробнее об RL с точки зрения ИНС
Когда мы решаем задачи обучения с подкреплением с помощью ИНС, мы должны учесть, что все потоки данных, с которыми приходится иметь дело, имеют вид потоков спайков. Это очень похоже на ситуацию с мозгом: он получает информацию от глаз и ушей в форме нервных импульсов, в той же форме отдает приказы мышцам рук и ног, и результат этой деятельности (что его обладатель съел или от кого убежал) тоже получается в виде активности специфических нейронов (т.е. опять же в виде спайков). Это хорошо вписывается и в картину реализации всего этого на нейрочипах, так как никакого другого взаимодействия кроме обмена спайками в нейрочипах не предполагается. Но такой сценарий решения задач RL до недавнего времени почти не изучался.
Тут надо еще сказать, что RL бывает разный, есть много вариантов, различающихся по своей сложности. Самый простой из них — это так называемый model-free RL. Предполагается формирование у нейросети поведения в стиле «стимул-реакция». Для каждой ситуации у сети имеется некоторый спектр возможных действий. Некоторые из них являются правильными («хорошими»), некоторые неправильными («плохими»), а некоторые — нейтральными. Причем оценка действия приходит практически сразу после выработки сетью соответствующей команды. Хороший пример такой задачи — сопровождение объекта камерой. Сеть должна держать хаотично движущееся пятно в центре поля зрения камеры. Она может двигать камерой сигналами определенных своих нейронов вверх, влево, вниз, вправо. Приближается центр камеры к пятну — сеть получает поощрение, удаляется — наказание. Сначала сеть вообще не знает, что от нее требуется, но быстро выясняет это на основе поощрений/наказаний. Кстати, как это происходит, можно посмотреть в реальном времени — эта задача была решена нашей ИНС и запись можно посмотреть тут.
Решается эта задача с помощью ИНС
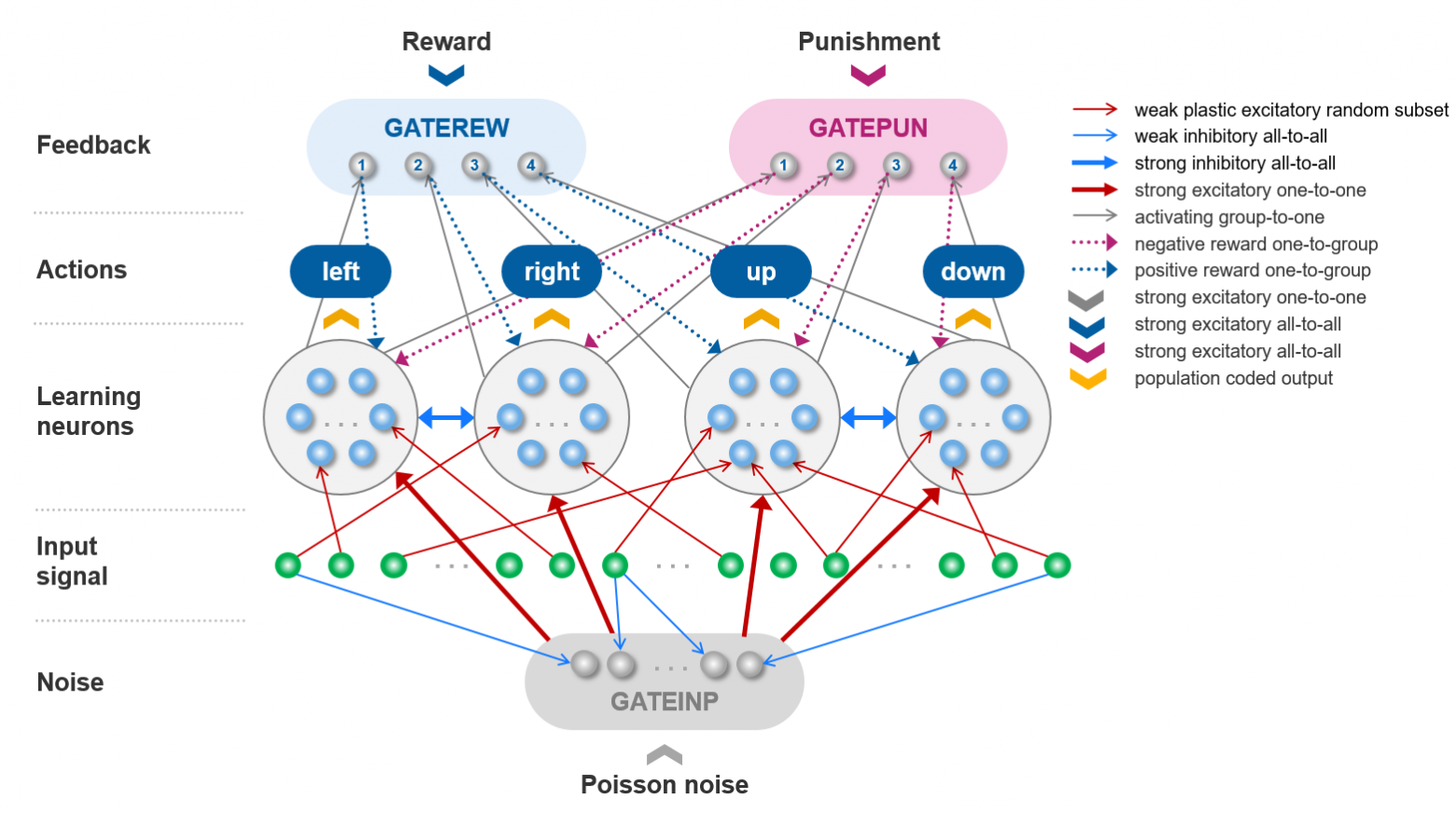 Схематичное изображение структуры ИНС
Схематичное изображение структуры ИНС
Входом здесь является сигнал с виртуальной камеры, смотрящей в квадратную область, в которой движется световое пятно. Четыре группы нейронов заставляют камеру двигаться по четырем направлениям. Сигналы оценки формируются по описанным выше правилам. Еще на вход сети подается случайный шумовой сигнал. Источником активности ИНС являются только ее входные узлы. Если в поле зрения камеры темно, сигналов нет, то сеть не выдаст никаких команд — без подпитки извне ее нейроны не сгенерируют спайков. Кстати, в этом смысле мозг человека демонстрирует схожее поведение — известны опыты по сенсорной депривации, когда человека лишали поступления сигналов от всех органов чувств, и он практически сразу засыпал. Но когда сеть ничего не делает, она и не учится. Выручает внешний шум. Он заставляет сеть делать случайные движения. Многие из них неправильные, но встречаются и удачные совпадения.
Вообще, это общий прием в RL — заставлять необученную сеть что-то делать просто для накопления опыта. Если же сигнал от камеры есть, то входной шум блокируется, чтобы не мешал. Обучение правильным действиям происходит в нейронах среднего слоя (Learning neurons) — к ним приходят оценочные сигналы, усиливающие или подавляющие связи между входными сигналами и генерируемыми командами в результате специально разработанных для этого законов изменения синаптических весов. Чтобы быть уверенным, что оценивается именно последнее действие сети, сигналы оценки пропускаются через специальные вентили, открываемые командами сети через специальные активирующие связи. Подробности можно найти в препринте нашей статьи.
Таким образом, на основе этого и некоторых других примеров можно декларировать, что задачи model-free RL с помощью ИНС мы решать умеем. Сейчас мы занимаемся более сложной задачей, решение которой позволит выйти уже на реальные приложения ИНС, — model-based RL. Представим себе компьютерный пинг-понг. По экрану летает мячик, отражаясь от стенок. В левой части экрана имеется ракетка» которую сеть может двигать вверх-вниз. Если во время удара мячика в левую стенку в месте удара оказывается ракета, считается, что сеть достигла успеха, что отмечается сигналом поощрения, если же ракетка не находится в этом месте, то сеть «проиграла» и получает сигнал наказания. Ситуация в этой игре кардинально отличается от задачи отслеживания пятна. Оценивается здесь далеко не каждое действие сети, а только их (возможно отдаленные) последствия. Для того, чтобы понять, куда сейчас двигать ракетку, сеть должна сформировать внутри себя в модель этого простейшего пинг-понга на основании своего опыта и затем применить эту модель к текущей ситуации для принятия лучшего решения. Это существенно сложнее, хотя мы уже примерно знаем, как.
Следующим шагом уже может быть выход в реальный мир — с манипуляторами, видеокамерами и практически полезными технологическими задачами. Это немного объясняет, зачем взрослые и, казалось бы, серьезные люди, напряженно смотрят в экран, где в черных окнах летают белые шарики, а рядом в окне консоли бежит отладочная выдача, чуть-чуть приоткрывающая завесу тайны — того, что происходит в недрах большой импульсной нейросети.
С помощью чего мы все это делаем
Ответ состоит из двух частей — аппаратной и программной.
С аппаратной частью ситуация следующая. Конечно, пока в нашем распоряжении нет супер-нейрокомпьютера на тех нейрочипах, о которых я говорил выше. Мы работаем с GPU кластером, который используется большинством нейросетевых исследователей. В мире обычных фон-Неймановских вычислителей есть процессоры, которые немного приближаются по своим свойствам к идеалу ИНС — это универсальные графические процессоры. Большое количество параллельно работающих вычислительных ядер, большой объем локальной регистровой памяти и некоторые другие свойства делают их удобной вычислительной основой для моделирования ИНС, тем более, когда имеется не одна такая GPU плата, а несколько на одном хосте. И уж совсем здорово, если этих хостов тоже несколько, и они объединены в кластер в рамках быстрой локальной сети. Но чтобы такая параллельность вычислений была эффективно использована, нужно специальная программная платформа, и вот о ней речь пойдет дальше.
Для того, чтобы моделировать ИНС на обычных компьютерах (отнесем к ним и GPU), нужно специальное ПО. Такого в мире уже сейчас немало. Разработано много эмуляторов ИНС. Как правило, они имеют интерфейс на Python, и с их помощью можно построить любую конфигурацию ИНС, выполнить ее эмуляцию, получить и оценить результаты. Казалось бы, что еще надо? Но:
1) Многие из них работают с ограниченным кругом моделей нейронов и, что еще хуже, моделей изменения синаптических весов (синаптической пластичности). А мы знаем, что правильный ответ в этой области еще не найден и нам вполне может потребоваться нечто, выходящее за пределы этих пары-тройки дюжин моделей (и так оно и происходит на самом деле). Учитывая это, в некоторых эмуляторах ИНС (например, в Brian2) введена возможность описывать модели с помощью текстового задания дифференциальных уравнений в специальной нотации. Это, конечно, удобно, но приводит к радикальному замедлению выполнения по сравнению с теми же моделями, заданными вручную программно. Моделирование заданных таким образом дифференциальных уравнений представляется возможным только на CPU. Моделирование на GPU возможно только в частных случаях.
2) Даже для тех моделей, которые реализованы, скорость их вычисления (особенно на GPU) обычно на порядок меньше, чем могла бы быть достигнута, если бы эта модель была бы реализована с помощью низкоуровневого языка типа CUDA. А время здесь играет существенную роль — некоторые из наших вычислительных экспериментов могут длиться более недели.
3) Python как интерфейсный язык таких пакетов является часто неудачным компромиссом. Это все же универсальный язык программирования, и поэтому гораздо менее удобен, чем декларативное описание ИНС — если используются только какие-то типовые решения и архитектуры. С другой стороны, он не позволяет эффективно использовать все ресурсы аппаратного обеспечения, что было бы возможно на низкоуровневом языке типа С++ или CUDA.
Поэтому мы используем альтернативу — единственный (на данный момент) отечественный пакет для эмуляции ИНС — ArNI-X. Этот пакет использует совсем другой подход к решению обозначенных выше проблем.
ArNI-X не имеет питоновского интерфейса. Вместо этого в большинстве типовых случаев структура ИНС может быть описана в конфигурационном файле в формате XML. Ниже мы покажем, как это делается. Если же надо создать некую совсем нестандартную конфигурацию, это можно сделать с помощью предоставляемого API на С++. Само ядро системы при этом остается неизменным. Оно может эффективно эмулировать импульсные нейроны из широкого класса моделей за счет большого количества настраиваемых параметров. Это же касается и моделей синаптической пластичности. Наконец, если гибкости настройки этих моделей окажется недостаточно, код ядра (например, написанные на CUDA компоненты, которые выполняются на GPU) может быть изменен и дополнен, для чего имеется удобный механизм условной компиляции. Но надо отметить, что делать это не приходилось уже давно.
Как же выглядит описание сети в ArNI-X? Вот один из примеров — описание достаточно нетривиальной сети:


Не вдаваясь в подробности, рассмотрим основные принципы этого описания. Оно включает два основных структурных элемента — описание популяций нейронов (в блоках Section) и совокупностей связей между ними (в блоках Link).
Популяция включает нейроны с одинаковыми свойствами и одинаковой логикой соединения с нейронами других секций (если требуется настроить эти вещи индивидуально для отдельных нейронов, придется это делать с помощью API). Название популяции, число нейронов в ней и отдельные параметры модели задаются в атрибутах XML блока и во вложенных блоках.
Проекции характеризуются парой соединяемых популяций, типом связей (возбуждающий, тормозной, модулирующий) и политикой соединения (все со всеми, один к одному, случайный и т.д.). Кроме того, устанавливаются распределения весов связей и распределения задержек распространения спайков по связям (в ИНС передача спайка от нейрона к нейрону происходит не мгновенно, и это время является существенным элементом вычислений).
Достаточно удобный и интуитивный механизм. Как уже говорилось, если его не хватает, сколь угодно сложные сети могут быть построены вызовами соответствующих методов API.
Сама эмуляция происходит следующим образом. Исполняемый модуль эмулятора (есть его варианты для CPU и GPU) читает конфигурационный файл и строит сеть в соответствии с ним. Загружает динамические библиотеки, реализующие источники спайков (входной сигнал) и реакцию на спайки выходных нейронов сети. Эти динамические библиотеки также указываются в конфигурационном файле. Источники спайков могут быть как стандартные (например, чтение спайков из файла), так и специализированные для конкретной задачи. Эмуляция может производиться в реальном времени — выполнение сети синхронизировано с получением данных на каждом шаге эмуляции, так что модуль входных данных может использовать часы для синхронизации посылки данных с внешним миром. Модуль считывателя получает на каждом шаге эмуляции спайки от нейронов, объявленных выходными, интерпретирует их как команды, реализуя таким образом взаимодействие сети с внешним миром. Он может отсутствовать, если интересна только динамика самой сети. В этом случае может быть включен режим мониторинга, сохраняющий полный протокол активности сети и, через определенные промежутки времени, мгновенные «снимки» полного состояния сети. Если требуется дополнительное конфигурирование сети, поверх ее структуры, описанной в конфигурационном файле, это делается в специально указанной динамической библиотеке, которой предоставляется соответствующий API. Когда все это загружено и построено, начинается собственно эмуляция, состоящая из повторения одних и тех же шагов. Каждый шаг эмуляции включает:
1) получение входного сигнала;
2) маршрутизацию спайков — как входных, так и сгенерированных нейронами на предыдущем шаге (при этом синаптические задержки достигаются за счет очередей, приходящих спайков на синапсах);
3) перевычисление состояния всех нейронов (и, возможно, их синаптических весов);
4) посылку спайков выходных нейронов модулю-считывателю.
Эмуляция завершается либо по прошествии нужного числа шагов, либо по команде от модуля входных сигналов или считывателя.
Кроме собственно эмулятора пакет ArNI-X включает еще большое количество вспомогательных средств для анализа результатов мониторинга сети, подготовки входных данных и т.д. Отдельно надо отметить систему оптимизации гиперпараметров сети на основе комбинации генетического алгоритма и координатного спуска. Вот здесь как раз проявляется удобство декларативного описания сети — какие-то ее параметры можно вставить в конфигурационный файл в виде макросов, заменяемых модулем оптимизации на конкретные значения. Кроме того, модуль оптимизации умеет работать с кластером GPU машин, оптимальным образом распределяя вычислительную нагрузку по оптимизации по кластеру.
Хотя многие из описанных свойств нашего эмулятора ИНС сильно отличают его от аналогов, их удобство и практичность проверены временем. Эмулятор ArNI-X существует уже более трех лет и с успехом применялся в самых разных исследованиях, связанных с ИНС. На мой взгляд, было бы вполне оправдано, если бы он стал базовым средством Росатома не только в исследовательских программах по ИНС, но и при создании практически полезных коммерческих приложений.
