Zabbix + Iostat: мониторинг дисковой подсистемы
Zabbix + Iostat: мониторинг дисковой подсистемы. Зачем? Дисковая подсистема одна из важных подсистем сервера и от уровня нагрузки на дисковую подсистему зачастую зависит очень многое, например скорость отдачи контента или то как быстро будет отвечать база данных. Это в большей степени относится к почтовым или файловым серверам, серверам БД. Вобщем, показатели дисковой производительности отслеживать нужно. На основании графиков производительности дисковой подсистемы мы можем принять решение о необходимости наращивания мощностей задолго до того как петух клюнет. Да и вобще полезно поглядывать от релиза к релизу как работа разработчиков сказывается на уровне нагрузки.Под катом, о мониторинге и о том как настроить.Зависимости: Мониторинг реализован через zabbix агента и две утилиты: awk и iostat (пакет sysstat). Если awk идет в дистрибутивах по умолчанию, то iostat требуется установить с пакетом sysstat (тут отдельное спасибо Sebastien Godard и сотоварищи).
Зачем? Дисковая подсистема одна из важных подсистем сервера и от уровня нагрузки на дисковую подсистему зачастую зависит очень многое, например скорость отдачи контента или то как быстро будет отвечать база данных. Это в большей степени относится к почтовым или файловым серверам, серверам БД. Вобщем, показатели дисковой производительности отслеживать нужно. На основании графиков производительности дисковой подсистемы мы можем принять решение о необходимости наращивания мощностей задолго до того как петух клюнет. Да и вобще полезно поглядывать от релиза к релизу как работа разработчиков сказывается на уровне нагрузки.Под катом, о мониторинге и о том как настроить.Зависимости: Мониторинг реализован через zabbix агента и две утилиты: awk и iostat (пакет sysstat). Если awk идет в дистрибутивах по умолчанию, то iostat требуется установить с пакетом sysstat (тут отдельное спасибо Sebastien Godard и сотоварищи).
Известные ограничения: Для мониторинга нужен sysstat начиная с версии 9.1.2, т.к. там есть очень важное изменение: «Added r_await and w_await fields to iostat’s extended statistics». Так что следует быть внимательным, в некоторых дистрибутивах, например в CentOS немного «стабильная» и менее фичастая версия sysstat.Если же отталкиваться от версии zabbix (2.0 или 2.2) то тут вопрос не принципиален, работает на обоих версиях. На 1.8 не заработает т.к. используется Low level discovery.
Возможности (чисто субъективно, по мере убывания полезности):
Low level discovery (далее просто LLD) для автоматического обнаружения блочных устройств на наблюдаемом узле; утилизация блочного устройства в % — удобная метрика для отслеживания общей нагрузки на устройстве; latency или отзывчивость — доступна как общая отзывчивость, так и отзывчивость на операциях чтения/записи; величина очереди (в запросах) и средний размер запроса (в секторах) — позволяет оценить характер нагрузки и степень загруженности устройства; текущая скорость чтения/записи на устройство в человекопонятных килобайтах; количество запросов чтения/записи (в секунду) объединенных при постановке в очередь на выполнение; iops — величина операций чтения/записи в секунду; усредненное время обслуживания запросов (svctm). Вообще она deprecated, разработчики обещают ее давно спилить, но все никак руки не доходят. Вобщем как видно, здесь доступны все те метрики которые есть в iostat (кто незнаком с этой утилитой настоятельно рекомендую заглянуть в man iostat).Доступные графики: Графики рисуются per-device, LLD обнаруживает устройства которые попадают под регулярное выражение »(xvd|sd|hd|vd)[a-z]», так что если ваши диски имеют другие имена, можно легко внести соответствующие изменения. Такая регулярка сделана чтобы обнаруживать устройства которые будут родительскими по отношению к прочим разделам, LVM томам, MDRAID массивам и т.п. Вобщем чтобы не собирать лишнего. Немного отвлеклись, итак список графиков:
Disk await — отзывчивость устройства (r_await, w_await); Disk merges — операции слияния в очереди (rrqm/s, wrqm/s); Disk queue — состояние очереди (avgrq-sz, avgqu-sz); Disk read and write — текущие значения чтения/записи на устройство (rkB/s, wkB/s); Disk utilization — утилизация диска и значение IOPS (%util, r/s, w/s) — позволяет неплохо отслеживать скачки в утилизации и чем, чтением или записью они были вызваны. Аналоги и отличия: В заббиксе есть коробочные варианты для похожего мониторинга, это ключи vfs.dev.read и vfs.dev.write. Они хороши и прекрасно работают, но менее информативны чем iostat. Например в iostat есть такие метрики как latency и utilization.Также есть аналогичный шаблон от Michael Noman на мой взгляд отличие только одно, она заточена на старые версии iostat, ну и + небольшие синтаксические изменения.Где взять: Итак, мониторинг состоит из файла конфигурации для агента, двух скриптов для сбора/получения данных и шаблон для веб-интерфейса. Все это доступно в репозитории на Github, поэтому любым доступным способом (git clone, wget, curl, etc…) скачиваем их на машины которые хотим замониторить и переходим к следующему пункту.
Как настроить:
iostat.conf — содержимое этого файла следует поместить в файл конфигурации zabbix агента, либо положить в каталог конфигурации который указан в Include опции основной конфигурации агента. Вобщем зависит от политики партии. Я использую второй вариант, для кастомных конфигов у меня отдельная директория. scripts/iostat-collect.sh и scripts/iostat-parse.sh — эта два рабочих скрипта следует скопировать в /usr/libexec/zabbix-extensions/scripts/. Тут также можно использовать удобное вам размещение, однако в таком случае не забудьте поправить пути в параметрах определенных в iostat.conf. Не забудьте проверить что они исполняемы (mode=755). Теперь все готово, запускаем агента и переходим на сервер мониторинга и выполняем команду (не забываем подменить agent_ip): # zabbix_get -s agent_ip -k iostat.discovery Таким образом, проверяем с сервера мониторинга что iostat.conf подгрузился и отдает информацию, заодно смотрим что LLD работает. В качестве ответа вернется JSON с именами обнаруженных устройств. Если ответа не пришло, значит что-то сделали не так.Как настроить в web интейрфейс: Теперь остался шаблон iostat-disk-utilization-template.xml. Через веб интерфейс импортируем его в раздел шаблонов и назначем на наш хост. Тут все просто. Теперь остается ждать примерно один час, такое время установлено в LLD правиле (тоже настраивается). Или можно поглядывать в Latest Data наблюдаемого хоста, в раздел Iostat. Как только там появились значения, можно перейти в раздел графиков и понаблюдать за первыми данными.
И напоследок тройка скринов графиков c локалхоста))): Непосредственно данные в Latest Data: 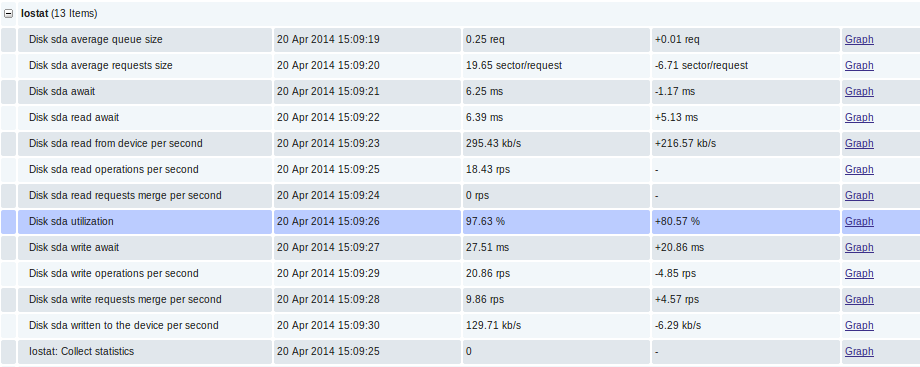
Графики отзывчивости (Latency): 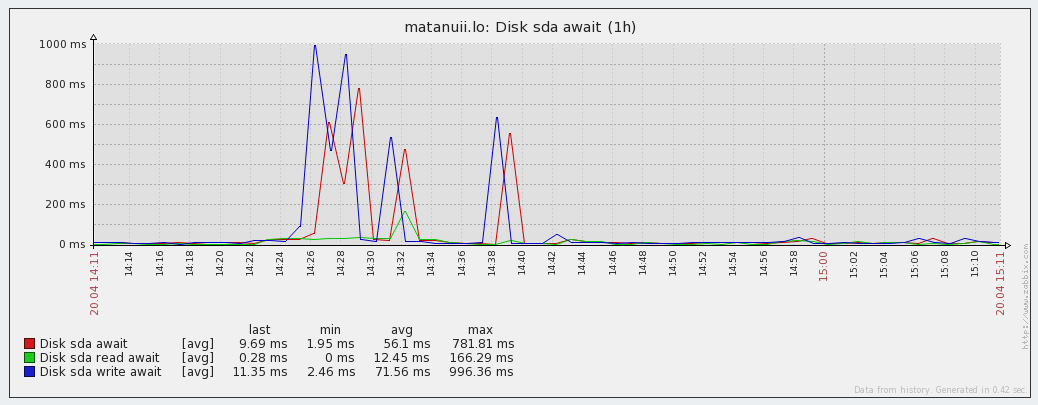
График утилизации и IOPS: 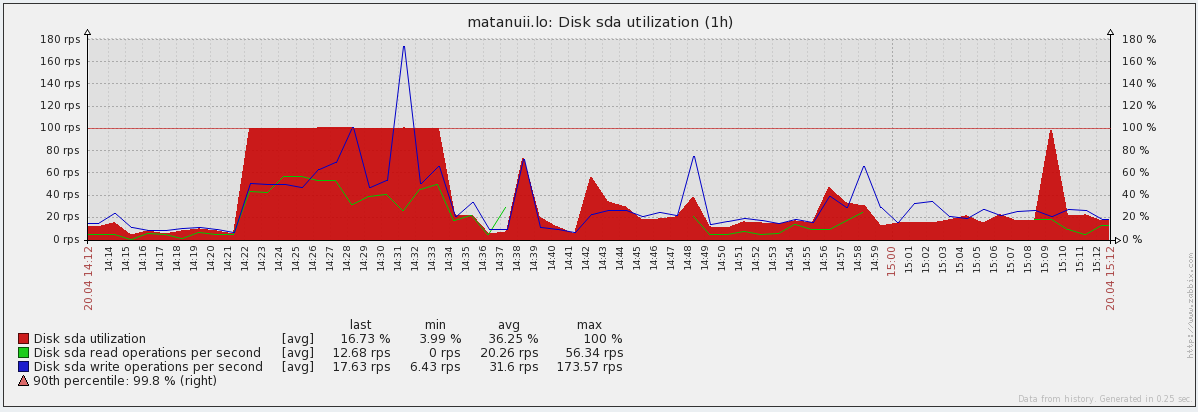
Вот и собственно и все, спасибо за внимание.Ну и по традиции, пользуясь случаем передаю привет Федорову Сергею (Алексеевичу) :)
