За гранью A/B: Синтетический контроль
Привет! Я Настя — лид A/B Платформы в Wildberries. На протяжении всего карьерного пути меня интересует тема оценки эффектов. Для этого существуют различные инструменты, в числе которых как A/B‑тестирование, так и альтернативные способы, например, различные вариации Causal Inference.
В этой статье я хочу поделиться примером проведения двух квази‑экспериментов в Wildberries с использованием Синтетического контроля (Synthetic Control).
Почему не А/B-тестирование?
Для большинства онлайн‑продуктов A/B‑тесты являются основным способом определить профитность и «хорошесть» фичи. Так, в Wildberries они составляют порядка 99% всех экспериментов. Метод классный, удобный, и у него есть очевидные преимущества:
Простая интерпретация: бизнесу понятно, что сравнивается и как происходит сравнение
Экспертиза A/B на рынке растет вширь: много аналитиков, которые в этом разбираются, а значит, A/B проще внедрять в новые продукты и развивать в зрелых
Экспертиза A/B на рынке растет вглубь: много способов «усилить/ускорить A/B‑тест» (CUPED, пост‑стратификация и др.)
Однако, y классического A/B‑теста есть один большой недостаток — не каждое нововведение можно оценить с его помощью. На своем опыте я выделила ряд ограничений, из‑за которых абешка не всегда возможна:
Технические ограничения
Нет необходимых технологий на бэке/фронте, а разработка стоит слишком дорого или длится слишком долго. Такое чаще всего встречается в молодых продуктахМетодологические ограничения
Пользователи тестируемой фичи знакомы или тесно связаны друг с другом. Например, продавцы Wildberries в общем чатеИдейные ограничения
Например, топ‑менеджмент не хочет, чтобы часть пользователей видела старый дизайнЮридические ограничения
К примеру, ряд банковских продуктов, условия по которым должны быть одинаковыми для всех клиентов по закону
Но при этом, как аналитику, мне всегда хочется попытаться измерить эффект от какого‑либо нововведения, даже если оно произошло без A/B‑теста. И здесь на помощь приходит Синтетический контроль.

Синтетический контроль
Синтетический контроль — это метод оценки эффектов от фичи с использованием классического ML. Он заключается в том, чтобы при помощи ML обучить модель «альтернативной реальности» и ответить на вопрос «Как вела бы себя тестовая группа в альтернативной реальности, если бы теста не случилось?»

На своей практике я сталкивалась с двумя вариантами использования Синтетика:
Синтетик в офлайне. Обычно в этом случае контрольных групп несколько и они не сопоставимы с тестовой группой по объему/динамике целевой метрики.Например, тест проводится только на одном складе, а на остальных складах все остается по‑старому. При этом склады имеют разный дневной оборот и не пригодны для сравнения в лоб (офлайн‑эксперимент «Новые транзитные тарифы»)
Синтетик в онлайне. В данном случае контрольной группы часто нет.
Например, фичу сразу раскатили на 100% без A/B‑теста (онлайн‑эксперимент «Рекламный баннер»)
Синтетик в офлайне. Тест «Новые транзитные тарифы»
В Wildberries есть команда Транзита, которая занимается поставками товаров продавцов с транзитных складов (складов временного хранения) до складов назначения, с которых уже товар поедет в пункты выдачи заказов (ПВЗ).
У ребят появилась идея ввести и протестировать новые транзитные тарифы:
А что, если теперь продавцы будут платить только за объем товара, при том, что раньше платили за каждую перевозимую палету?

Гипотеза
Ожидалось, что снижение ценовых тарифов сделает услугу транзита более доступной, селлеры станут чаще ей пользоваться, вырастет колличество поставок, и, как следствие, выручка от транзита.
А/B‑тест был невозможен, так как:
Не было реализовано сплитование в личном кабинете продавца (техническое ограничение)
Селлеры общались друг с другом в общем чате, и точно бы заметили разные ценовые предложения в рамках одного направления (методологическое ограничение)
Поэтому тест решено было делать на всем направлении целиком. В нашем случае «направление» — это пара складов: транзитный склад (откуда везут) — склад назначения (куда везут).
Стоит отметить, что у офлайн‑экспериментов есть еще одна особенность — сложность согласования, поэтому владельцы продукта очень просили обойтись лишь одним тестовым направлением, для которого согласование было самым простым.
Теперь мне предстояла самая важная задача — подобрать [синтетическую] контрольную группу к выбранному тестовому направлению.
Дизайн теста
Я проанализировала транзитные направления по выручке с транзита и по количеству поставок в день и отобрала только действующие направления. Как я и предполагала, у направлений была разная динамика, дисперсия и шоки: попарно они очень трудно сравнимы или вообще не сравнимы.

Если все напрвления такие разные, то как подобрать контрольную группу со старыми тарифами для сравнения?
Обучение синтетика
При невозможности подобрать контрольную группу собирается синтетическая контрольная группа. По корреляции подбираются самые близкие по значению временные ряды, которые потом пойдут на обучение синтетика. Сам синтетик затем строится как взвешенная сумма из нескольких самых похожих на тестовое направление контрольных групп.

В мою модель были выбраны самые тесно коррелирующие направления по динамике целевой метрики. Я выбрала порог для коэффициента корреляции 0.2 и, таким образом, на обучение синтетика отправилось 6 направлений, которые больше всего были похожи на тестовое.
Берем временные ряды, один из них — тестовое направление, остальные — потенциальные контрольные группы
У каждой пары (тест, контроль-1), (тест, контроль-2), … подсчитываем коэффициент корреляции — меру схожести рядов
Строим корреляционную матрицу и сортируем ее по убыванию коэффициента корреляции
Выбираем порог — чем выше тем лучше. Я балансировала между силой корреляции и количеством направлений, отсекаемых порогом. Чем ближе порог к 1, тем меньше точек пойдет на обучение. Чем слабее порог, тем менее похожие ряды пойдут на обучение синтетика
Отсекаем по порогу направления, которые затем отправляем в трейн
Синтетик. Спецификация модели
Синтетическая контрольная группа строится следующим образом:

Где:
 — значение синтетика
— значение синтетика
 — значения в контрольных юнитах (без теста)
— значения в контрольных юнитах (без теста)
 — веса для синтетика
— веса для синтетика
Для простоты восприятия, в формуле опущен индекс t, отвечающий за гранулярность временного ряда и знаки статистических оценок.
Более аккуратной записью формулы будет:

Где:
 — предсказанное значения синтетика в день t
— предсказанное значения синтетика в день t
 — значения в контрольных юнитах (без теста) в день t
— значения в контрольных юнитах (без теста) в день t
 — оценки весов для синтетика (результат фита модели)
— оценки весов для синтетика (результат фита модели)
А обучается синтетическая контрольная группа на пред‑тестовом периоде, где в качестве таргета выступают значения целевой метрики в тестовой группе, а качестве ковариат — значения в контрольных юнитах.

Задача сводится к тому, чтобы обучить веса модели w1, w2, …, wn в зависимости от числа контрольных направлений (n), чтобы аппроксимировать тестовую группу. Контрольные направления умножаются на веса и суммируются. Полученная взвешенная сумма является синтетиком и [по построению] ведет себя приближенно к тестовой группе.
Для тренировки весов я использовала простую линейную регрессию. Единожды натренированные веса w1, …, wn во время теста не изменяются, а значения y1, …, yn подставляются для каждого нового наблюдения (в моем случае — для каждого нового дня). Таким образом синтетик можно использовать для предсказаний в режиме реального времени по мере поступления новых данных для контрольных направлений.
Обучаем веса при помощи модели линейной регрессии, где в качестве таргета выступает тестовая группа на пред‑периоде, а в качестве ковариат — контрольные направления [тоже на пред‑периоде], отобранные по коэффициенту корреляции
После старта теста каждый день считаем значение синтетической контрольной группы, на основе реальных наблюдений — направлений без теста (контрольных групп)
Тест и оценка результата
После того, как мы обучили модель, можно запускать тест. Имея в арсенале натренированный синтетик и выждав 3 недели после начала теста, я приступила к анализу полученных результатов.
Для оценки эффектов я использовала обычный t‑test. Иными словами, я провела A/B‑тестирование. В качестве контрольной группы выступил синтетик, в качестве теста — тестовое направление. В качестве наблюдений использовались дни.

Синяя линия на графике — Синтетический контроль,
Оранжевая — наблюдаемая метрика тестового направления,
Тестовый период — светло‑зеленая область,
Пред‑тестовый период — серая область.
Обучив синтетик на пред‑периоде и сравнив его значения с тестовыми в период эксперимента, я увидела заметное падение целевой метрики относительно синтетика на 19% в тотале, однако это падение не было статистически значимым. Небольшое количество наблюдений в тесте могло стать одной из причин отсутствия стат. значимых изменений.
Еще одна возможная причина отсутствия стат. значимого результата — высокая дисперсия исходных рядов. По графику выше видно, что иногда синтетик сильно отличается от реальных значений, однако он почти всегда сонаправлен с ними. В силу построения синтетик будет менее дисперсионным, чем настоящие ряды. И это нормально.

При этом, рассматривая накопленные метрики за период, мы получаем очень приятную total ошибку модели порядка 5–15% (в зависимости от метрики).
Но что же делать, когда хочется получить заветные стат. значимые изменения?
Есть лайфхак, как улучшить качество модели: можно построить модель на сглаженных рядах, например, на скользящих средних. В данном случае я взяла ma7 — скользящее среднее на недельном окне. Такое сглаживание помогает сгладить внутринедельную сезонность и выделить тренд. На моем опыте, модели на трендах в целом обучаются лучше, так как имеют меньшую дисперсию.

Синяя линия на графике — Синтетический контроль,
Оранжевая — наблюдаемая метрика тестового направления,
Тестовый период — светло‑зеленая область,
Пред‑тестовый период — серая область.
И — о, чудо! На сглаженных рядах мы наблюдаем, что в тестовой группе целевая метрика просела почти на треть, и этот результат значим на уровне alpha = 1%.
Получается, поставщики были готовы платить за всю палету целиком, и уменьшение цен для них не являлось значимым изменением (частота поставок не изменилась, но теперь продавцы тратят на перевозку меньше денег).
Как оценить качество модели
Наверное, многие из вас уже задались вопросами:
Как можно оценить качество модели?
Насколько точно работает синтетик?
Можно ли доверять синтетику?
На самом деле, оценить перфоманс синтетика можно [и нужно]! Я использовала ряд проверок «на адекватность».
1. Проверка качества модели — прогноз в будущее
По своей сути синтетическая контрольная группа — это ML‑модель. Она тренируется на пред‑тестовом периоде и предсказывает в тестовом окне. В таком случае, еще во время трейна можно оценить точность модели и ошибку прогноза на пред‑тестовом периоде, а для оценки качества можно использовать любую стандартную ML‑метрику качества модели, которая подходит под конкретную бизнес‑задачу. Я ориентировалась на MAE, MAPE, MSE.
2. Проверка качества модели — A/A тесты
А как проверить, что синтетик не показывает эффекты там, где их на самом деле нет? Для этого можно брать направления, в которых теста не было, строить синтетики, наблюдать за результатами и проверять, что синтетик не отклоняется от тестовой группы.

Синяя линия на графике — Синтетический контроль,
Оранжевая — наблюдаемая метрика тестового направления,
Тестовый период — светло‑зеленая область,
Пред‑тестовый период — серая область.
В примере выше получилось, что стат. значимых отличий у синтетика на тестовом периоде от тестовой группы нет. Значит, метод работает правильно.
Синтетик как A/B. Как еще проверить, что тест работает?
Для проверки качества работы синтетика, мы также, как и с A/B‑тестами можем:
Провести A/A‑тесты, и убедиться, что синтетик не отличается от теста, там где отличий нет
Провести искусственные A/B‑тесты с эмуляцией эффекта и проверить, что синтетик отличается от теста, в случае когда эффект действительно есть. (Чаще всего эмуляция эффекта делается путем прибавления случайной величины к одной из групп)
Выводы для синтетика в офлайне
Синтетик в офлайне позволил нам:
Провести эксперимент всего на одной точке (склад/пиццерия/город/ПВЗ и тд) и подобрать группу для сравнения из точек, не участвующих в эксперименте
Отделить чистое влияние фичи от сезонности и иных внешних факторов
Добыть ценную информацию для принятия решений бизнесом
Также без построения синтетической контрольной группы, опираясь только на дашбординг, практически невозможно оценить эффект от нововведения. Например, график может идти вверх за счет подросшего сезонного спроса, однако без теста, возможно, график шел бы еще выше.
Синтетик в онлайне. Рекламный кликаут-баннер
Онлайн‑пример из моей практики — это раскатка фичи на 100% без A/B‑теста. Здесь уже не получится выбрать контрольные группы и веса — их попросту нет. Все, что есть для обучения — это дата раскатки новой фичи и непрерывный временной ряд. Но этого нам достаточно!
В чем же заключался эксперимент? В мобильной и десктоп‑версии маркетплейса размещался внешний кликаут‑баннер. Это было первое рекламное размещение такого рода в Wildberries, и были переживания о том, что основные пользовательские метрики просядут (покупатели будут чаще уходить с Wildberries и реже совершать покупки).
Сплитование не было готово, но тест уже горел по срокам. Поэтому я выбрала в качестве инструмента оценки эффектов [легендарный] Синтетический контроль.
Ниже я привела алгоритм проведения теста с синтетиком при раскатке фичи на 100%:
Собираем исторические данные
Обучаем ML‑модель прогноза (как бы это было, если бы все осталось как раньше)
Проверяем модель на адекватность: ML‑метрики и A/A‑тесты
Раскатываем фичу на 100%
Проводим анализ: сравниваем прогнозные значения (синтетик) с реальными данными
Контрольных групп, на которых можно было бы строить синтетик при помощи весов, у нас больше нет. Для обучения модели мы имеем только прошлое. Поэтому в качестве синтетической контрольной группы я использовала прогнозную модель, которая обучалась на пред‑периоде, а во время теста предсказывала, как бы вела себя метрика, если бы теста не случилось.
Чем лучше мы обучим прогнозную модель, тем надежнее и точнее мы получим синтетическую контрольную группу.
Prophet. Спецификация модели
Для построения прогноза я выбрала Prophet — простой тул для прогнозирования «из коробки». Сравнив его с моделями класса ARIMA (авторегрессионные модели), я получила лучшие результаты у Prophet.
Prophet позволяет учесть влияние праздников, которые можно дополнительно передать в модель. Так, моя модель учитывала периоды Чёрных Пятниц, праздников и других дат, влияющих на прогноз. Особенно сильно на прогноз влиял Новый Год.
def set_holidays():
# Setting holidays
black_fridays = pd.DataFrame({
'holiday': 'black_friday',
'ds': pd.to_datetime(['2022-11-26', '2022-11-25', '2023-11-24',]),
'lower_window': -14,
'upper_window': 14,
})
new_years = pd.DataFrame({
'holiday': 'new_year',
'ds': pd.to_datetime(['2021-12-31', '2022-12-31', '2023-12-31']),
'lower_window': -2,
'upper_window': 7,
})
febs_23 = pd.DataFrame({
'holiday': '23_feb',
'ds': pd.to_datetime(['2021-02-23', '2022-02-23', '2023-02-23']),
'lower_window': -4,
'upper_window': 3,
})
mays_1 = pd.DataFrame({
'holiday': '1_may',
'ds': pd.to_datetime(['2021-05-01', '2022-05-01', '2023-05-01']),
'lower_window': -2,
'upper_window': 2,
})
holidays = pd.concat((black_fridays, new_years, febs_23, mays_1))
return holidays
holidays = set_holidays() Также Prophet имеет замечательную возможность моделировать несколько видов сезонности. Модель декомпозирует временной ряд на тренд, недельную и годичную сезонности и влияние праздников.
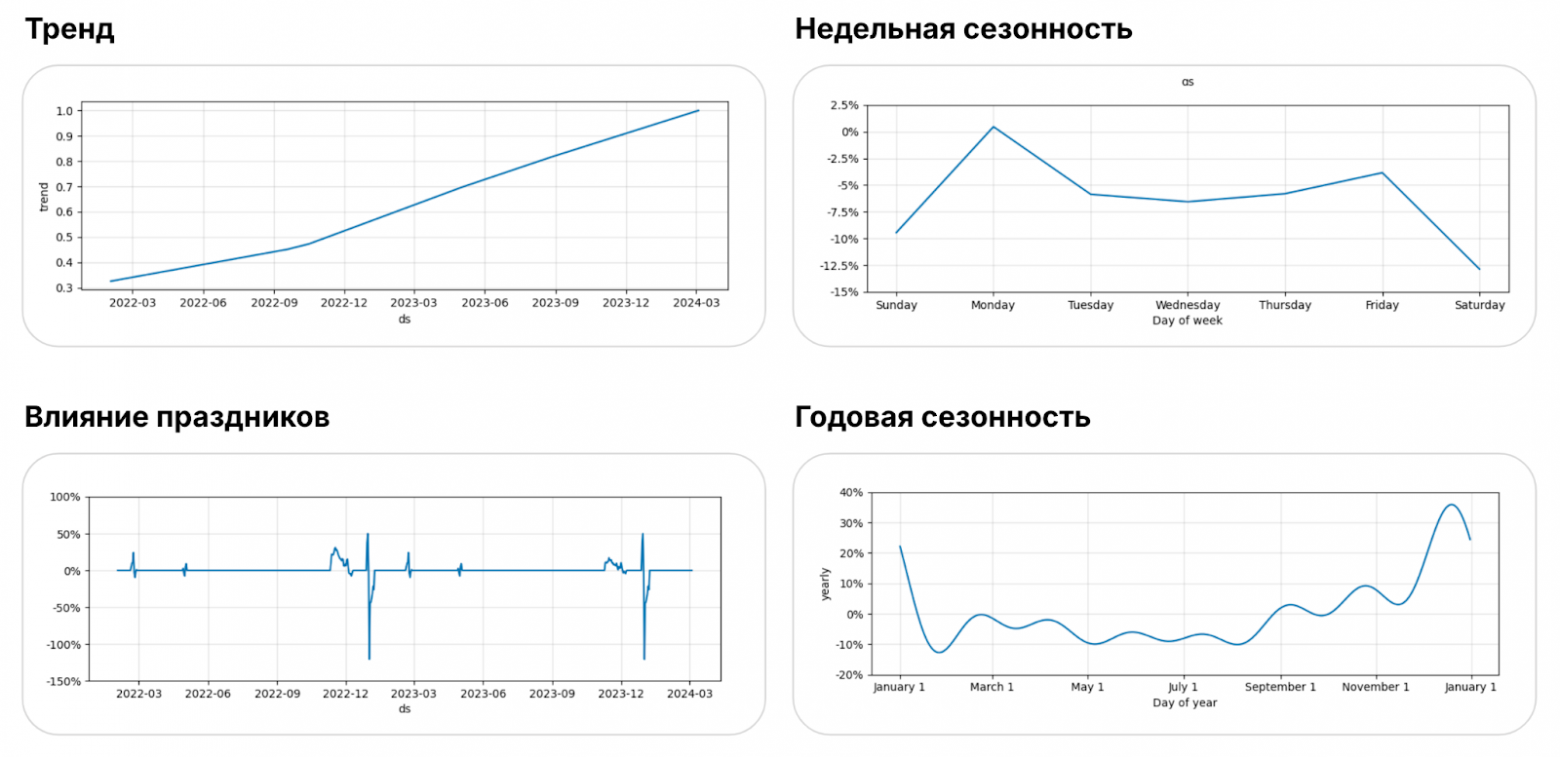
В спецификации можно настроить выраженность сезонности, тип тренда, тип сезонной декомпозиции, добавить дополнительные регрессоры и праздники.
# Setting Prophet model
model = Prophet(yearly_seasonality=7,
weekly_seasonality=10,
holidays=holidays,
growth = "linear",
holidays_prior_scale = 10,
n_changepoints = 20,
seasonality_mode='multiplicative'
)
model.fit(train)Результат фита
По итогам фита, у меня получилась следующая модель:

Можно заметить, что модель достаточно хорошо отловила влияние праздников, особенно сильно влияет на метрику Новый Год (всплески перед Новым Годом и сильные просадки первого января, так как в этот день почти никто не совершает покупки).
Результаты теста
После старта, тест длился 2 недели.

Проверив с помощью t‑теста ряд целевых метрик при плейсменте рекламного баннера, стат. значимые изменения не обнаружились.
Таким образом, я сделала вывод, что плейсмент внешнего рекламного баннера не повлиял на пользовательский опыт.
Выводы для онлайн-синтетика
Синтетик в онлайне менее надежен, чем в офлайне, потому что не учитывает влияние шоков или структурных сдвигов, произошедших во время теста, но не учтенных в модели на пред‑периоде. Однако, при качественном трейне модели и мониторинге целевых метрик во время теста, на синтетик в онлайне можно положиться.
Заключение
Синтетический контроль позволяет оценить эффект от фичи, там где провести A/B‑тест не представляется возможным.
Качество и точность синтетика ниже, чем A/B — меньше мощность, больше MDE. Есть шанс не заметить минимальные изменения, которые могут быть критичны для бизнеса.
Тем не менее, синтетик способен отловить умеренные и большие отклонения в целевых метриках (> 5–15%). А в офлайн экспериментах с крупными единицами рандомизации Синтетик будет, пожалуй, одним из самых эффективных решений. В онлайне он так же станет палочкой‑выручалочкой, если фича уже раскатилась на 100% и требуется пост‑анализ.
Синтетический контроль — мой самый любимый в Causal Inference метод, потому что он работает даже при полном отсутствии контрольной группы и достаточно прост в обучении и интерпретации.
А больше о том, как при помощи ML и других технологий мы делаем маркетплейс лучше для продавцов и покупателей, рассказываем в Telegram‑канале @wb_space. Там же делимся анонсами и полезными материалами от экспертов.
