Web scraping на Node.js и защита от ботов
 Это третья статья в цикле про создание и использование скриптов для веб-скрейпинга при помощи Node.js.
Это третья статья в цикле про создание и использование скриптов для веб-скрейпинга при помощи Node.js.
В первой статье разбирались базовые аспекты веб-скрейпинга, такие как получение и парсинг страниц, рекурсивный проход по ссылкам и организация очереди запросов. Во второй статье разбирались анализ сайта, работающего через Ajax, тонкая настройка очереди запросов и обработка некоторых серверных ошибок.
Также во второй статье затрагивалась тема инициализации сессий, но, там речь шла о предельно простом случае, когда достаточно выполнить один дополнительный запрос и сохранить куки.
В этой статье разбирается более сложный случай — инициализация сессий с авторизацией по логину и паролю и с преодолением довольно изощрённой защиты от ботов. Как обычно, на примере реальной (и весьма популярной среди скрейперов) задачи.
В большинстве случаев защита от ботов на сайте направлена не против скрейперов, а против таких вещей, как мошенничество, накрутки или спам в комментариях. Однако это всегда лишний повод задуматься о легальности и этичности скрейпинга именно этого сайта. В этой статье для примера выбран сайт, про который хорошо известно, что его владельцы нормально относятся к скрейпингу (хотя и предпочитают, чтобы он выполнялся через специальный API). Простые правила: если у сайта есть открытый API, значит его владельцы рады скрейперам, а если сайт большой и ультрапосещаемый, нагрузка от скрейпинга в обход API его особо не побеспокоит.
В прошлых статьях целью было показать весь процесс создания и использования скрипта от постановки задачи и до получения конечного результата. В этой статье большая часть аспектов веб-скрейпинга обходится стороной, а вместо этого показывается многообразие подходов к решению одной, довольно узкой задачи. Различные методы и инструменты, их плюсы и минусы, субъективные оценки, примеры кода, вот это вот всё.
Постановка задачи
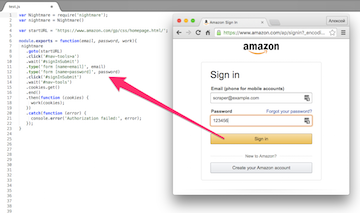 На этот раз заказчик — другой веб-скрейпер, которому понадобилась помощь коллеги. Он хочет получить (для своего заказчика) данные с известного сайта Amazon. Некоторые из нужных ему данных отдаются только авторизованным пользователям. Разумеется, у заказчика есть аккаунт на Amazon, но проблема в том, что на этом сайте реализована защита от автоматической авторизации. Заказчику нужен модуль на Node.js, который эту защиту проходит. Естественно, речь идёт об инструменте для автоматической авторизации своим аккаунтом под свою ответственность, а не о взломе чужого аккаунта, например.
На этот раз заказчик — другой веб-скрейпер, которому понадобилась помощь коллеги. Он хочет получить (для своего заказчика) данные с известного сайта Amazon. Некоторые из нужных ему данных отдаются только авторизованным пользователям. Разумеется, у заказчика есть аккаунт на Amazon, но проблема в том, что на этом сайте реализована защита от автоматической авторизации. Заказчику нужен модуль на Node.js, который эту защиту проходит. Естественно, речь идёт об инструменте для автоматической авторизации своим аккаунтом под свою ответственность, а не о взломе чужого аккаунта, например.
Заказчик уже выполнил анализ своей части задачи. Он убедился, что нужные ему данные доступны, если в http-запросе установить один заголовок и две куки (или все, если лень отделять именно эти две из авторизованной сессии). Заголовок всегда один и тот же, а куки легко можно получить в браузере со страницы авторизованного пользователя Amazon (при помощи DevTools или аналогичного инструмента). Куки устаревают далеко не сразу, так что получив их один раз можно выполнить довольно много авторизованных запросов.
Например, вот такой код должен выводить адрес электронной почты, доступный только авторизованным пользователям Amazon:
var needle = require('needle');
var testURL = 'http://www.amazon.com/gp/profile/A14ZQ17DIPJ6UB/customer_email';
var cookies = {
'session-id': '111-2222222-3333333', // подставить реальный session-id
'ubid-main': '444-5555555-6666666', // подставить реальный ubid-main
};
work(cookies);
function work(cookies){
var options = {
headers: {
'X-Requested-With': 'XMLHttpRequest'
},
cookies: cookies
};
needle.get(testURL, options, function(err, res){
if (err) throw err;
console.log(res.body.data.email);
});
}
Соответственно заказчику нужен модуль, который получает на вход логин и пароль от аккаунта, а на выходе даёт нужные куки. Что-то вроде этого:
module.exports = function(email, password, work){
// magic
work(cookies);
}
Заказчик будет использовать этот модуль в собственном скрипте для веб-скрейпинга Amazon. Может быть даже прикрутит к собственному фреймворку для скрейпинга. Нам это не принципиально.
Прежде чем переходить к анализу интерфейса авторизации на сайте Amazon стоит отметить один важный момент. Дело в том, что этот сайт работает с деньгами. Его постоянно атакуют злоумышленники, и интересует их обычно отнюдь не получение легальных данных в обход API, как нашего заказчика. Не удивительно, что защитные механизмы этого сайта постоянно совершенствуются. Я ещё помню времена, когда автоматическая авторизация на Amazon осуществлялась одним POST-запросом. Это было задолго до появления Node.js (я тогда скрейпил на Perl). Потом там постепенно добавились такие вещи, как переадресации, скрытые поля форм, одноразовые адреса и тому подобное. В сети до сих пор можно найти примеры авторизации на Amazon (при помощи, например, PHP Curl), в которых реализуется примерно следующий алгоритм:
- Получаем страницу с одноразовой ссылкой на страницу с формой логина;
- Сохраняем куки (которые подходят именно к этой одноразовой ссылке);
- Парсим страницу и получаем нужную ссылку;
- Делаем запрос по этой ссылке (используя сохранённые куки) и получаем страницу;
- Сохраняем куки (они уже другие, да);
- Парсим страницу и получаем значения всех скрытых полей формы логина;
- Добавляем поля электронной почты и пароля;
- Имитируем POST-запрос из формы (используя последние сохранённые куки);
- Получаем ответ с кодом 302 и адресом в заголовке Location;
- Сохраняем куки (третий вариант уже)
- Получаем страницу по адресу из Location (снова используя куки)
- Наконец-то получаем те куки, которые нам нужны, и используем их для авторизованных запросов.
Опытные скрейперы могут заметить, что этот алгоритм — простой. Такая задача может заставить поработать два часа там, где заплачено за один, но она вряд ли сорвёт дедлайн.
К сожалению, этот алгоритм устарел. С тех пор, как он в последний раз работал, на Amazon как минимум дважды менялась защита от автоматической авторизации. Теперь там на восьмом шаге перед отправкой формы происходит изменение её данных скриптом, так что простым анализом http-трафика и составлением запросов проблема не решается. После таких изменений тема автоматической авторизации на Amazon постепенно перемещается с любительских форумов на профессиональные биржи фриланса.
Трудно сказать, когда и как защита Amazon поменяется снова, но точно можно сказать, что это непременно произойдёт. Поэтому, при рассмотрении данной задачи конкретный рабочий код менее ценен чем понимание соответствующих подходов и инструментов.
Краткий обзор методов
Все методы решения подобных задач можно условно разделить на три категории:
- Имитация браузера: выполнение запросов на основе данных полученных хакерскими методами, такими как анализ трафика, реверс-инжиниринг скриптов и так далее.
- Автоматическое использование браузера. Сюда относится управление из скрипта настоящими браузерами (например, Chrome) через специальный API (например, с помощью Selenium WD), а также использование headless-браузеров (например PhantomJS).
- Использование браузера вручную. Это не обязательно означает полный отказ от автоматизации скрейпинга, но подразумевает, что живой оператор будет видеть реальные страницы и выполнять на них реальные действия через пользовательский интерфейс.
Выбор из этих трёх пунктов — не очевиден и как минимум субъективен. Все три категории имеют свои плюсы и минусы и любая из них позволяет решить нашу задачу, так что рассмотрим их по очереди.
Имитация браузера
Нечто подобное описано в двух предыдущих статьях. Чтобы осуществить скрейпинг мы отправляем на сервер правильные http-запросы. «Правильные» — это такие, какие отправлял бы браузер, если бы скрейпинг производился полностью вручную. Чтобы выяснить, что именно отправлять в каждом отдельном запросе, мы анализируем заголовки запросов и ответов в браузере, а также смотрим исходники страниц. Задача из этой статьи ничем принципиально не отличается от двух предыдущих за исключением одного момента: в данном случае понятие «исходники страниц» означает ещё и подключённые скрипты. Нам нужно понять, какая часть кода добавляет данные к запросам, откуда эти данные берутся и так далее. Обычный реверс-инжиниринг применительно к скриптам сайта.
Самый главный плюс такого подхода — его универсальность. Если защита проходится стандартной связкой из человека и браузера, то алгоритм её прохождения может быть найден реверс-инжинирингом. Теоретически, исключений из этого правила нет. В мире веб-скрейпинга существуют задачи, которые могут быть решены исключительно реверс-инжинирингом.
Главный минус такого подхода — его неограниченная трудоёмкость. Это путь для сильных духом и не особо ограниченных по времени. В реальной жизни реверс-инжиниринг одного сложного сайта может занять время, за которое можно написать скрипты для скрейпинга тысячи «обычных» сайтов. В теории изготовитель защиты может потратить на неё сколько угодно времени, а его квалификация может потребовать, чтобы реверс-инжинирингом занимался опытный и талантливый хакер. Проще говоря, на определённом уровне сложности заказчику становится выгоднее вместо крутого хакера нанять клерка-копипейстера. Или вообще отказаться от заказа и обойтись без этих данных.
Стоит отметить, что не каждый скрейпер вообще обладает хакерскими навыками или имеет в команде хакера. Встретившись с необходимостью разбираться в скриптах на сайте большинство отказывается от заказа или выбирает метод из другой категории. Ну, или нанимает другого профессионала.
В случае, когда алгоритм защиты не просматривается при анализе трафика и HTML — стоит начать с других подходов. Если же алгоритм может неожиданно измениться в любой момент (как на Amazon), я рекомендую реверс-инжиниринг рассматривать в последнюю очередь. К тому же мне кажется, что если код прохождения защиты Amazon, полученный реверс-инжинирингом, выложить, например, на Хабр, то можно сразу рядом написать, что этот код устарел — это быстро станет правдой.
В этой статье примеры кода будут описывать другие методы.
Автоматическое использование браузера
Этот подход популярен у начинающих скрейперов настолько, что они переходят к нему каждый раз, как сталкиваются с трудностями при анализе сайта. Профессионалы с жёсткими дедлайнами также любят этот подход.
Главный плюс такого подхода — простота прохождения скриптовой защиты, так как в скриптах сайта нет необходимости разбираться — они просто выполнятся в браузере и сделают всё то же самое, как если бы их запускал не ваш код, а пользователь с мышкой и клавиатурой. Ваш код будет напоминать инструкции для недалёкого клерка-копипастера. Он будет легко читаться и правиться при необходимости.
Главный минус этого подхода — вы запускаете чужой код у себя на компьютере. Этот код может, например, содержать дополнительную защиту от автоматизации самого разного типа от детекторов headless-браузеров и до интеллектуального анализа поведения пользователей. Конечно, можно использовать, например, proxy-сервер, подменяющий скрипт с детектором, но это потребует того же самого реверс-инжиниринга, а тогда вообще непонятно зачем возиться с браузерами.
(Примечание: пример технологии анализа поведения пользователя можно посмотреть на сайте AreYouaHuman, а про детекторы headless-браузеров можно больше узнать из отличной презентации, ссылку на которую kirill3333 оставил в комментарии к позапрошлой статье.)
Ещё один минус этого подхода — браузеры потребляют намного больше ресурсов, чем обычные скрейперские скрипты. Для скрейпинга тысяч (а тем более — миллионов) страниц это плохая идея. Наш заказчик хочет модуль, код которого будет выполняться один раз и отправлять всего несколько запросов, так что нам о ресурсах можно не беспокоиться.
Для автоматического использования браузера из скрипта на Node.JS есть много популярных инструментов. Тут я кратко прохожусь по основным (если я кого-то зря забыл — подскажите в комментариях):
Selenium WD — самый известный и популярный инструмент для автоматического использования браузера. Не нуждается в дополнительном представлении. В сети есть масса примеров и советов. Любому, кто хотя бы подумывает профессионально заняться скрейпингом, стоит попробовать Selenium WD.
К сожалению, для решения нашей задачи Selenium WD плохо подходит. Чтобы с ним работать понадобится установить и настроить Java, сам Selenium WD (приложение на Java), браузер, драйвер браузера и модуль для доступа к Selenium WD из выбранного языка программирования (в нашем случае — из Node.js). Это не самый простой путь, учитывая, что нашему заказчику нужен простой модуль на Node.js, работающий «из коробки» (ну, в крайнем случае требующий что-то вроде 'npm install').
PhantomJS — headless-браузер на движке WebKit. Он запускает сайты в реальном браузере, только не показывает пользователю страниц, а вместо пользовательского интерфейса использует скрипты на Javascript. Браузер в PhantomJS настолько полноценный, что для него даже есть драйвер для Selenium WD и эта связка отлично работает.
С точки зрения нашей задачи главное, что нужно знать о PhantomJS это то, что хоть он и использует тот же язык Javascript что и Node.js, но это НЕ Node.js. Похож, но не то. Нельзя сделать модуль на Node.js, который бы непосредственно использовал PhantomJS. Можно сделать отдельный скрипт на PhantomJS, а для него сделать модуль-обёртку, который будет запускать отдельный процесс и получать его данные через stdout. В простейшем случае это выглядит так:
var sys = require('sys'),
exec = require('child_process').exec;
module.exports = function(callback) {
exec('phantomjs script.js', function(err, stdout){
callback(err === null ? stdout : false);
});
};
Чтобы не возиться с stdout и работать через удобный интерфейс имеет смысл использовать одну из готовых (и тщательно кем-то уже протестированных) обёрток над PhantomJS.
SlimerJS — грубо говоря это тот же PhantomJS, только не на WebKit, а на Gecko. В нашем случае важно, что SlimerJS поддерживается меньшим количеством обёрток чем PhantomJS.
CasperJS — самая известная Node.js-обёртка над PhantomJS и SlimerJS. О том, почему CasperJS лучше чем голый PhantomJS хорошо написано, например, в этой статье (на английском). А вот в этой статье (тоже на английском) можно посмотреть пример прохождения авторизации на Amazon при помощи CasperJS. Вполне рабочее решение, но это не лучший вариант (оцените, хотя бы, объём кода в примере). Я рекомендую вместо CasperJS обратить внимание на следующий пункт списка:
Horseman.js — очень хорошая обёртка над PhantomJS. Идеальный вариант для написания модулей вроде нашего. Не требует никаких сложных действий по инсталляции и настройке. Достаточно в нашем модуле добавить в зависимости phantomjs-prebuilt и node-horseman и всё. Интерфейс у Horseman.js предельно лаконичный, гибкий и лёгкий для чтения. Вот так будет выглядеть рабочий код нашего модуля, написанный с использованием Horseman.js:
var Horseman = require('node-horseman');
var horseman = new Horseman();
var startURL = 'https://www.amazon.com/gp/css/homepage.html/';
module.exports = function(email, password, work){
horseman
.userAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.84 Safari/537.36')
.open(startURL)
.click('#nav-tools>a')
.waitForNextPage()
.type('form [name=email]', email)
.type('form [name=password]', password)
.click('#signInSubmit')
.waitForNextPage()
.cookies()
.then((cookies)=>{
work(cookies);
})
.close();
}
Такой код можно читать не глядя в документацию. И он работает.
NW — ещё один управляемый браузер (бывший node-webkit). Позволяет управлять движком Blink из скриптов на Node.js. Основное предназначение — создание десктопных приложений с использованием веб-технологий, но может работать и как headless. На NW можно делать полноценные приложения для скрейпинга. Например, такие, как вот в этой статье от vmb. Такие инструменты, как NW, особенно хороши, когда заказчик боится командной строки и хочет окошко с кнопочками. В нашем случае NW не лучший выбор.
Electron — ещё один инструмент для создания десктопных приложений на базе веб-технологий. По сути это молодой и перспективный конкурент NW и с его помощью также можно делать приложения для скрейпинга с отличной индикацией. Кроме того, Electron легко можно использовать в качестве headless-браузера, но подключать его в наш модуль лучше не напрямую, а через обёртку.
Nightmare — самая известная обёртка над Electron. Несмотря на название производит очень хорошее впечатление. Спроектирован настолько гладко, что некоторые начинающие скрейперы умудряются использовать Nightmare вообще ничего не зная про Electron. По интерфейсу очень похож на Horseman.js (и почти так же хорош). Вот так будет выглядеть рабочий код нашего модуля, написанный с использованием Nightmare:
var Nightmare = require('nightmare');
var nightmare = Nightmare()
var startURL = 'https://www.amazon.com/gp/css/homepage.html/';
module.exports = function(email, password, work){
nightmare
.goto(startURL)
.click('#nav-tools>a')
.wait('#signInSubmit')
.type('form [name=email]', email)
.type('form [name=password]', password)
.click('#signInSubmit')
.wait('#nav-tools')
.cookies.get()
.end()
.then(function (cookies) {
work(cookies);
})
.catch(function (error) {
console.error('Authorization failed:', error);
});
}
В принципе тут всё то же самое, что и в случае с Horseman.js. Под капотом Electron вместо PhantomJS, но это в глаза не бросается.
Chimera — обычный модуль для Node.js с минимумом зависимостей (фактически только request). Он позволяет загрузить страницу, выполнить скрипт в её контексте и обработать его результат в контексте Node.js. Среди тех, кто пришёл в скрейпинг из фронтенда, встречаются любители этого модуля, но на мой взгляд он слишком минималистичен. По крайней мере, если заказчик упрётся и потребует модуль без прилагающегося к нему браузерного движка, то можно использовать не Chimera, а следующий вариант:
ZombieJS — этот модуль часто позиционируется как аналог PhantomJS, который можно запускать прямо из Node.js. Никаких браузерных движков ZombieJS не использует, обходясь такими привычными инструментами, как request, jsdom или ws. По сравнению с Horseman.js код на ZombieJS выглядит громоздким, но после Chimera это образец удобства и лаконичности:
var Browser = require('zombie');
var browser = new Browser();
var startURL = 'https://www.amazon.com/gp/css/homepage.html/';
module.exports = function(email, password, work){
browser.visit(startURL, function(){
browser.clickLink('#nav-tools>a', function() {
browser.fill('email', email);
browser.fill('password', password);
browser.pressButton('#signInSubmit', function(){
var cookies = browser.saveCookies().split('\n');
var newCookies = {};
for (var i = 0; i < cookies.length; i++) {
var cookie = cookies[i].split(';')[0].split('=');
newCookies[cookie[0]] = cookie[1];
}
browser.tabs.closeAll();
work(cookies);
});
});
});
}
К явным минусам ZombieJS можно отнести плохую документацию. Раньше она была хорошая, но потом разработчик её сильно изменил в худшую сторону. Не буду строить конспирологических теорий о том, зачем он это сделал, но вот вам пара ссылок, по которым с ZombieJS можно разобраться: примеры и API.
Интересно, что PhantomJS, Electron и ZombieJS многими сайтами воспринимаются по-разному, так что один инструмент проходит защиту, а другой — блокируется. Это серьёзный повод быть готовым воспользоваться любым из этих трёх инструментов. Хотя, конечно, такие сложные случаи встречаются редко. С сайтом Amazon, например, работают все три скрипта. Ну… пока работают.
Использование браузера вручную
Может показаться, что этот пункт тут приводится ради прикола, однако это не так. Бывают ситуации, когда такой подход не просто оправдан, но и оптимален. Например, когда требуется один раз выполнить сложное для автоматизации действие, а потом очень много раз автоматически выполнять что-то простое. Например, авторизоваться на Amazon, а потом долго скрейпить его.
Главный минус такого подхода — необходимость в живом пользователе для каждого запуска скрипта. То есть нельзя просто стартовать скрейпинг по cron, нужно чтобы кто-то смотрел на страницы и что-то с ними делал.
Главный плюс такого подхода — наглядность процесса. Пользователь видит что происходит на странице и заметит, если что-то пойдёт не так. А возможно он сможет всё исправить. Например, если сайт внезапно начнёт спрашивать капчу (как это делает Amazon, если его долго напрягать автоматической авторизацией).
Самый простой способ добавить к своему скрипту использование браузера вручную — это написание инструкции для пользователя. Понятный текст, объясняющий, например, как взять куки из браузера и поместить в текст скрипта — это та же программа, только не для компьютера, а для человека. Многие программисты умеют писать такие программы хорошо, а многие заказчики легко идут на такой компромисс чтобы сэкономить время и деньги. К сожалению, нашему заказчику нужен модуль, не требующий пользовательских инструкций.
Ещё один способ — написать собственный браузер, который будет запускаться только ради авторизации на Amazon, а потом закрываться. Например, на основе Electron. Это не так уж и сложно сделать. Если в нашем скрипте на Nightmare внести небольшое изменение, то скрипт будет показывать страницы, с которыми работает. Пользователь будет видеть, как скрипт заполняет поля формы и отправляет её. Нужно просто инициализировать Nightmare с дополнительным параметром. Вот так:
var nightmare = Nightmare({ show: true })
Например, так можно увидеть, что сайт начал запрашивать капчу, что происходит не так уж редко. Более того, пользователь может ввести капчу прямо в окне Electron и всё будет работать. Только время ожидания в скрипте стоит поставить побольше, а то пользователь может не успеть. Вообще, можно убрать автоматическое заполнение полей формы и предоставить это пользователю. Тогда можно будет не хранить пароль в тексте скрипта. Более того, тогда можно будет в разные моменты времени скрейпить от имени разных пользователей.
С другой стороны, Nightmare можно научить распознавать запрос капчи и проходить её при помощи таких сервисов, как Death by Captcha, но у нас в задаче такого требования нет.
Заключение
Задача из этой статьи намного сложнее чем всё то, что обычно делают веб-скрейперы в реальной жизни. Однако на современных биржах фриланса часто бывает так, что битву за заказ выигрывает тот, кто первым заявляет, что способен его выполнить быстро и хорошо. В результате очень выгодно иметь способность брать заказы практически не глядя и не попадать в неприятности с сорванными дедлайнами, проваленными соглашениями, испорченной репутацией и понизившимся рейтингом. Поэтому, даже если скрейпер целыми днями делает элементарные скрипты для получения данных с простых сайтов, полезно быть готовым столкнуться со сложной защитой и не испугаться. Если хотя бы поверхностно освоить подходы, описанные в этой статье (и в двух предыдущих), то процент «нерешаемых» заказов будет пренебрежительно мал.
В ближайшее время я планирую написать о скрейпинге регулярно обновляющихся данных, скрейпинге данных больших объёмов, терминологии скрейпинга, а также о моральных и правовых аспектах скрейпинга. Советы и рекомендации по выбору тем особо приветствуются.
