Работа мечты и бесплатный кластер на 1 миллион мета-данных
Доброго времени суток!
Мы решили дать публичный доступ к архиву 1 млн насыщенных мета-данными сообщений соцмедиа (несколько сотен источников, включая посты и комментарии соцсетей, блогов, форумов, СМИ и т.п.).
Предлагаем попробовать свои силы в создании различных эвристик, закладываемых в классические SMA-системы (Social Media Analytics). Чем больше эвристик вы придумаете и сможете реализовать, тем выше ваш класс в Data Scientist. Возможно в вас живет настоящий профи: Data Scientist — одна из крутых профессий ближайшего будущего!
Для состоявшихся фанатов-профи — это возможность проверить и показать свои способности, а также, при обоюдном желании и радости, получить годовой контракт на $30.000 — $50.000.
Подробнее под катом
Стратегический ситуационный уровень:
— Ежедневно человечество генерит десятки (30–40) млрд онлайн-сообщений, из которых 5–7% публичных.
— Русскоязычные сообщения составляют 2–3% мирового потока, т.е. ~100 млн в сутки.
— В отличие от структурированных данных (чеки в магазине, информация о звонках, электронные платежи и пр.) НЕструктурированные данные требуют других инструментов для создания аналитических систем и подходов к анализу данных аналитиками: скоростная лингвистика, нечеткие мета-данные, «размазанная» геолокация, выявление и противодействие «чужому разуму» (ботам) и т.д., и т.п.
Тактический уровень:
— Человечество практически «закончилось» — темпы прироста в онлайн и генерации контента составляют естественные единицы процентов.
— Платформы сбора данных, а также первичного анализа (SMA — Social Media Analytics), включая и лингвистические модули (обычно самые медленные процессы) вышли на промышленный уровень, справляясь с текущими потоками генерации данных.
— Теперь дело за «мозгами» — какие (адаптивные) алгоритмы AI (ИИ, искусственного интеллекта или машинного самообучения) будут создаваться, развиваться и применяться для решения реальных задач человеческого социума.
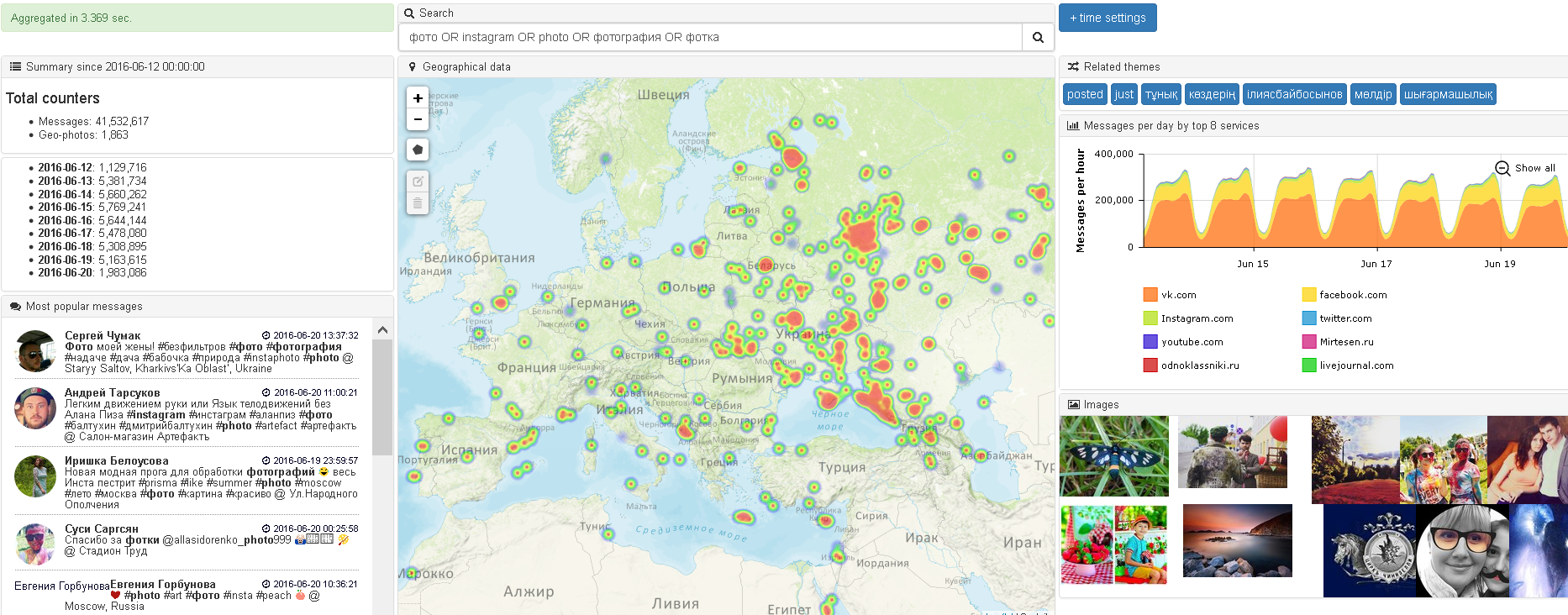
Понятийный пример (см. картинку выше):
Есть набор насыщенных мета-данными соцмедиа-сообщений, а также некий стандартный набор эвристик, выработанных аналитиками для клиентов в течение нескольких лет, например: количество сообщений (иногда с разбивкой по периоду), разблюдовка по коммуникационным каналам и т.д. Если сообщения дополнить «непрямой» информацией мета-данных, отсуствующих в исходном сообщении (т.е. задействовать «мозги и память»), то для твитов можно доопределить пол (отсутствующее поле в аккаунте), а для комментария к статье в СМИ доопределить, например, гео по фразе «Болею за наших в Париже». Тогда можно создать НОВУЮ эвристику — показать сообщения на карте, актуализируя такие аттрибуты, как концентрация и гео-динамика события.
Насыщение и расширение мета-данных — сама по себе интересная задача, которая уже частично и в разной степени успешности решается в крупных компаниях (IBM, Google, MS), и соцсетях (Facebook, Twitter, LinkedIn). Для этих процессов чаще всего задействуют появляющиеся новые технологии — например, определение людей по фотографиям, или получение доступа к данным о физических перемещениях людей (телеком-метки).
Наступает момент, когда технологии и задачи выходят на следующий уровень «мозговитости» — когда системы САМОСТОЯТЕЛЬНО находят новые закономерности и делают прогноз о развитии событий и ситуаций.
Подобные фазы развития прошли, например, автоматические финансовые роботы: на анализе прошлых данных строились различные модели и эвристики, которые далее в автоматическом режиме работают и зарабатывают (как минимум разработчики этих роботов).
Профессия Data Scientist предполагает некоего кентавра: смесь программиста с аналитиком. Чего в кентавре больше — дело важное, но вторичное, главное — результат деятельности специалиста. По прогнозам исследовательских агентств потребность DS только в США составит 180.000 человек.
Конкретика:
1. 1 млн+ публичных сообщений с мета-данными выложены в публичный доступ:
JSON, 350 мб
CSV, 55 мб
Данные представляют собой некую выборку за ~6 часов одного дня.
2. Для интересующихся и желающих попробовать свои силы и возможности — попробуйте «повторить» простейшие эвристики, закладываемые в классические SMA-системы. Чем больше эвристик вы придумаете (подсмотрите) и сможете реализовать, тем выше ваш класс в DS. В обязательном порядке найдите критерий выборки данного 1 млн сообщений. Напомню, что по статистике дневной набор русскоязычного потока ~100 млн, значит за несколько часов должно было бы быть 10–15 млн, а в выборке — только 1 млн. Что могло быть критерием выборки? Небольшая подсказка — обычно простые выборки делаются по словам («ключевикам»).
3. На Хабре периодически появляются посты по анализу неструктурированных данных, вполне возможно, что кто-то из фанатов-профи согласится участвовать в нашем новом R&D-спиноффе на постоянной основе (годовой контракт, $30–50 тыс). Не имеет значение пол, возраст, образование, место проживания, значение имеет только результат, который нужно реализовать на данном наборе данных, и желание творить и создавать НОВЫЕ эвристики.
Каким результатом может похвастаться профи:
— Стандартные статистики SMA — данных полей в мета-данных вполне хватает для понимания.
— Расширение новыми мета-данными, за счет сбора дополнительных данных по авторам набора из соцсетей, например: женат/холост, учится/работает, дети/родители.
— «Интеллектуальные» мета-данные — очень сильный плюс. Например: динамика тональности высказываний, или кластеризация интересов.
— И, конечно, НОВЫЕ эвристики, которые только придут в голову.
Если будет получаться что-то интересное — присылайте на sz@palitrumlab.ru.
Код присылать не надо! Только таблички или картинки с результатами.
P.S. К существующей Платформе данных SDS и лингвистической платформе EurekaEngine мы сейчас ведем разработку Платформы мета-данных. Надеемся, что к концу года мы сможем обеспечить доступ ко всем Платформам для разработчиков разных уровней, а также групп и команд, в целях создания сторонних новых решений и систем, для работы которых необходимо получать открытые данные из соцмедиа и публичные наборы данных.
UPD: не прошло и часа, как пришли первые «картинки» с эвристиками «А что за выборка»: 

