Web файловый менеджер Sprut.IO в OpenSource
В Бегете мы долго и успешно занимаемся виртуальным хостингом, используем много OpenSource-решений, и теперь настало время поделиться с сообществом нашей разработкой: файловым менеджером Sprut.IO, который мы разрабатывали для наших пользователей и который используется у нас в панели управления. Приглашаем всех желающих присоединиться к его разработке. О том, как он разрабатывался и почему нас не устроили существующие аналоги, какие костыли технологии мы использовали и кому он может пригодиться, расскажем в этой статье.
Сайт проекта: https://sprut.io
Демо доступно по ссылке: https://demo.sprut.io:9443
Исходный код: https://github.com/LTD-Beget/sprutio

Зачем изобретать свой файловый менеджер
В 2010 году мы использовали NetFTP, который вполне сносно решал задачи открыть/загрузить/подправить несколько файлов.
Однако, пользователям иногда хотелось научиться переносить сайты между хостингами или у нас между аккаунтами, но сайт был большой, а интернет у пользователей не самый хороший. В итоге, или мы делали это сами (что явно было быстрее), или объясняли, что такое SSH, MC, SCP и прочие страшные вещи.
Тогда у нас и появилась идея сделать WEB двух-панельный файловый менеджер, который работает на стороне сервера и может копировать между разными источниками на скорости сервера, а также, в котором будут: поиск по файлам и директориям, анализ занятого места (аналог ncdu), простая загрузка файлов, ну и много всего интересного. В общем, все то, что облегчило бы жизнь нашим пользователям и нам.
В мае 2013 мы выложили его в продакшн на нашем хостинге. В некоторых моментах получилось даже лучше, чем мы хотели изначально — для загрузки файлов и доступа к локальной файловой системе написали Java апплет, позволяющий выбрать файлы и все сразу скопировать на хостинг или наоборот с хостинга (куда копировать не так важно, он умел работать и с удаленным FTP и с домашней директорией пользователя, но, к сожалению, скоро браузеры не будут его поддерживать).
Прочитав на Хабре про аналог, мы решили выложить в OpenSource наш продукт, который получился, как нам кажется, отличным работающим и может принести пользу. На отделение его от нашей инфраструктуры и приведение к подобающему виду ушло еще девять месяцев. Перед новым 2016 годом мы выпустили Sprut.IO.
Как он работает
Делали для себя и использовали самые, по нашему мнению, новые, стильные, молодежные инструменты и технологии. Часто использовали то, что было уже для чего-то сделано.
Есть некоторая разница в реализации Sprut.IO и версии для нашего хостинга, обусловленная взаимодействием с нашей панелью. Для себя мы используем: полноценные очереди, MySQL, дополнительный сервер авторизации, который отвечает и за выбора конечного сервера, на котором располагается клиент, транспорт между нашими серверами по внутренней сети и так далее.
Sprut.IO состоит из нескольких логических компонентов:
1) web-морда,
2) nginx+tornado, принимающие все обращения из web,
3) конечные агенты, которые могут быть размещены как на одном, так и на многих серверах.
Фактически, добавив отдельный слой с авторизацией и выбором сервера, можно сделать мультисерверный файловый менеджер (как в нашей реализации). Все элементы логически можно поделить на две части: Frontend (ExtJS, nginx, tornado) и Backend (MessagePack Server, Sqlite, Redis).
Схема взаимодействия представлена ниже:

Frontend
Web интерфейс — все достаточно просто, ExtJS и много-много кода. Код писали на CoffeeScript. В первых версиях использовали LocalStorage для кеширования, но в итоге отказались, так как количество багов превышало пользу. Nginx используется для отдачи статики, JS кода и файлов через X-Accel-Redirect (подробно ниже). Остальное он просто проксирует в Tornado, который, в свою очередь, является своеобразным роутером, перенаправляя запросы в нужный Backend. Tornado хорошо масштабируется и, надеемся, мы выпилили все блокировки, которые сами же и наделали.
Backend
Backend состоит из нескольких демонов, которые, как водится, умеют принимать запросы из Frontend. Демоны располагаются на каждом конечном сервере и работают с локальной файловой системой, загружают файлы по FTP, выполняют аутентификацию и авторизацию, работают с SQLite (настройки редактора, доступы к FTP серверам пользователя).
Запросы в Backend отправляются двух видов: синхронные, которые выполняются относительно быстро (например, листинг файлов, чтение файла), и запросы на выполнение каких-либо долгих задач (загрузка файла на удаленный сервер, удаление файлов/директорий и т.п.).
Синхронные запросы — обычный RPC. В качестве способа сериализации данных используется msgpack, который хорошо зарекомендовал себя в плане скорости сериализации/десериализации данных и поддержки среди других языков. Также рассматривали python-специфичный rfoo и гугловский protobuf, но первый не подошел из-за привязки к python (и к его версиям), а protobuf, с его генераторами кода, нам показался избыточным, т.к. число удаленных процедур не измеряется десятками и сотнями и необходимости в выносе API в отдельные proto-файлы не было.
Запросы на выполнение долгих операций мы решили реализовать максимально просто: между Frontend и Backend есть общий Redis, в котором хранится выполняемый таск, его статус и любые другие данные. Для запуска задачи используется обычный синхронный RPC-запрос. Flow получается такой:
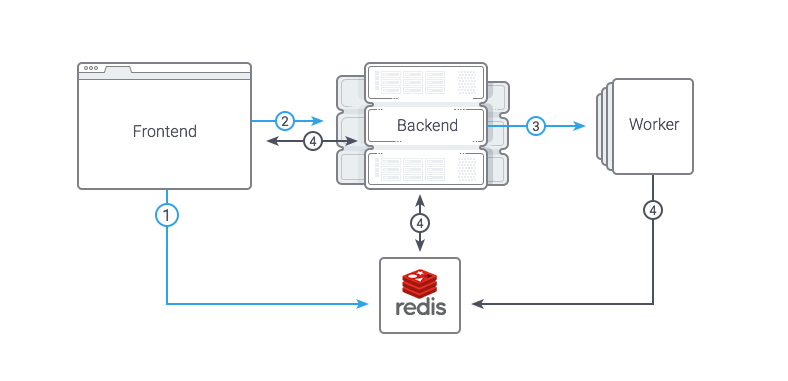
- Frontend кладет в редис задачу со статусом «wait»
- Frontend делает синхронный запрос в backend, передавая туда id задачи
- Backend принимает задачу, ставит статус «running», делает fork и выполняет задачу в дочернем процессе, сразу возвращая ответ на backend
- Frontend просматривает статус задачи или отслеживает изменение каких-либо данных (например, количество скопированных файлов, которое периодически обновляется с Backend).
Интересные кейсы, которые стоит упомянуть
-
Загрузка файлов с Frontend
Задача:
Загрузить файл на конечный сервер, при этом Frontend не имеет доступа к файловой системе конечного сервера.Решение:
Для передачи файлов msgpack-server не подходил, основная причина была в том, что пакет не мог быть передан побайтово, а только целиком (его надо сначала полностью загрузить в память и только потом уже сериализовывать и передавать, при большом размере файла будет OOM), в итоге решено было использовать отдельного демона для этого.
Процесс операции получился следующий:
Мы получаем файл от nginx, пишем его в сокет нашего демона с заголовком, где указано временное расположение файла. И после того, как файл полностью передан, отправляем запрос в RPC на перемещение файла в конечное расположение (уже к пользователю). Для работы с сокетом используем пакет pysendfile, сам сервер самописный на базе стандартной питоновской библиотеки asyncore -
Определение кодировки
Задача:
Открыть файл на редактирование с определением кодировки, записать с учетом исходной кодировки.Проблемы:
Если у пользователя некорректно распознавалась кодировка, то при внесении изменений в файл c последующей записью мы можем получить UnicodeDecodeError и изменения не будут записаны.Все «костыли», которые в итоге были внесены, являются итогом работы по тикетам с файлами, полученными от пользователей, все «проблемные» файлы мы также используем для тестирования после внесенний изменений в код.
Решение:
Исследовав интернет в поисках данного решения, нашли библиотеку chardet. Данная библиотека, в свою очередь, является портом библиотеки uchardet от Mozilla. Она, например, используется в известном редакторе https://notepad-plus-plus.orgПротестировав ее на реальных примерах, мы поняли, что в реальности она может ошибаться. Вместо CP-1251 может выдаваться, например, «MacCyrillic» или «ISO-8859–7», а вместо UTF-8 может быть «ISO-8859–2» или частный случай «ascii».
Кроме этого, некоторые файлы на хостинге были utf-8, но содержали странные символы, то ли от редакторов, которые не умеют корректно работать с UTF, то ли еще откуда, специально для таких случаев также пришлось добавлять «костыли».
Пример распознавания кодировки и чтения файлов, с комментариями# Для определения кодировки используем порт uchardet от Mozilla - python chardet # https://github.com/chardet/chardet # # Используем dev версию, там все самое свежее. # Данный код постоянно улучшается благодаря обратной связи с пользователями # чем больше - тем точнее определяется кодировка, но медленнее. 50000 - выбрано опытным путем self.charset_detect_buffer = 50000 # Берем часть файла part_content = content[0:self.charset_detect_buffer] + content[-self.charset_detect_buffer:] chardet_result = chardet.detect(part_content) detected = chardet_result["encoding"] confidence = chardet_result["confidence"] # костыль для тех, кто использует кривые редакторы в windows # из-за этого в файлах utf-8 имеем cp-1251 из-за чего библиотека ведет себя непредсказуемо при детектировании re_utf8 = re.compile('.*charset\s*=\s*utf\-8.*', re.UNICODE | re.IGNORECASE | re.MULTILINE) html_ext = ['htm', 'html', 'phtml', 'php', 'inc', 'tpl', 'xml'] # Все вероятности выбраны опытным путем, на основе набора файлов для тестирования if confidence > 0.75 and detected != 'windows-1251' and detected != FM.DEFAULT_ENCODING: if detected == "ISO-8859-7": detected = "windows-1251" if detected == "ISO-8859-2": detected = "utf-8" if detected == "ascii": detected = "utf-8" if detected == "MacCyrillic": detected = "windows-1251" # если все же ошиблись - костыль на указанный в файле charset if detected != FM.DEFAULT_ENCODING and file_ext in html_ext: result_of_search = re_utf8.search(part_content) self.logger.debug(result_of_search) if result_of_search is not None: self.logger.debug("matched utf-8 charset") detected = FM.DEFAULT_ENCODING else: self.logger.debug("not matched utf-8 charset") elif confidence > 0.60 and detected != 'windows-1251' and detected != FM.DEFAULT_ENCODING: # Тут отдельная логика # Код убран для краткости из примера elif detected == 'windows-1251' or detected == FM.DEFAULT_ENCODING: pass # Если определилось не очень верно, то тогда, скорее всего, это ошибка и берем UTF-8 )) else: detected = FM.DEFAULT_ENCODING encoding = detected if (detected or "").lower() in FM.encodings else FM.DEFAULT_ENCODING answer = { "item": self._make_file_info(abs_path), "content": content, "encoding": encoding } -
Параллельный поиск текста в файлах с учетом кодировки файла
Задача:
Организовать поиск текста в файлах с возможностью использования в имени «shell-style wildcards», то есть, например, 'pupkin@*.com' '$* = 42;' и т.д.Проблемы:
Пользователь вводит слово «Контакты» — поиск показывает, что нет файлов с данным текстом, а в реальности они есть, но на хостинге у нас встречается множество кодировок даже в рамках одного проекта. Поэтому поиск также должен учитывать это.Несколько раз столкнулись с тем, что пользователи по ошибке могли вводить любые строки и выполнять несколько операций поиска на большом количестве папок, в дальнейшем это приводило к возрастанию нагрузки на серверах.
Решение:
Многозадачность организовали достаточно стандартно, используя модуль multiprocessing и две очереди (список всех файлов, список найденных файлов с искомыми вхождениями). Один воркер строит список файлов, а остальные, работая параллельно, разбирают его и осуществляют непосредственно поиск.Искомую строку можно представить в виде регулярного выражения, используя пакет fnmatch. Ссылка на итоговую реализацию поиска.
Для решения проблемы с кодировками приведен пример кода с комментариями, там используется уже знакомый нам пакет chardet.
Пример реализации воркера# Приведен пример воркера self.re_text = re.compile('.*' + fnmatch.translate(self.text)[:-7] + '.*', re.UNICODE | re.IGNORECASE) # remove \Z(?ms) from end of result expression def worker(re_text, file_queue, result_queue, logger, timeout): while int(time.time()) < timeout: if file_queue.empty(): continue f_path = file_queue.get() try: if is_binary(f_path): continue mime = mimetypes.guess_type(f_path)[0] # исключаем некоторые mime типы из поиска if mime in ['application/pdf', 'application/rar']: continue with open(f_path, 'rb') as fp: for line in fp: try: # преобразуем в unicode line = as_unicode(line) except UnicodeDecodeError: # видимо, файл не unicode, определим кодировку charset = chardet.detect(line) # бывает не всегда правильно if charset.get('encoding') in ['MacCyrillic']: detected = 'windows-1251' else: detected = charset.get('encoding') if detected is None: # не получилось ( break try: # будем искать в нужной кодировке line = str(line, detected, "replace") except LookupError: pass if re_text.match(line) is not None: result_queue.put(f_path) logger.debug("matched file = %s " % f_path) break except UnicodeDecodeError as unicode_e: logger.error( "UnicodeDecodeError %s, %s" % (str(unicode_e), traceback.format_exc())) except IOError as io_e: logger.error("IOError %s, %s" % (str(io_e), traceback.format_exc()))
В итоговой реализации добавлена возможность выставить время выполнения в секундах (таймаут) — по умолчанию выбран 1 час. В самих процессах воркеров понижен приоритет выполнения для снижения нагрузки на диск и на процессор. -
Распаковка и создание файловых архивов
Задача:
Дать пользователям возможность создавать архивы (доступны zip, tar.gz, bz2, tar) и распаковывать их (gz, tar.gz, tar, rar, zip, 7z)Проблемы:
Мы встретили множество проблем с «реальными» архивами, это и имена файлов в кодировке cp866 (DOS), и обратные слеши в именах файлов (windows). Некоторые библиотеки (стандартная ZipFile python3, python-libarchive) не работали с русскими именами внутри архива. Некоторые реализации библиотек, в частности SevenZip, RarFile не умеют распаковывать пустые папки и файлы (в архивах с CMS они встречаются постоянно). Также пользователи всегда хотят видеть процесс выполнения операции, а как это сделать если не позволяет библиотека (например просто делается вызов extractall ())?Решение:
Библиотеки ZipFile, а также libarchive-python пришлось исправлять и подключать как отдельные пакеты к проекту. Для libarchive-python пришлось сделать форк библиотеки и адаптировать ее под python 3.Создание файлов и папок с нулевым размером (баг замечен в библиотеках SevenZip и RarFile) пришлось делать отдельным циклом в самом начале по заголовкам файлов в архиве. По всем багам разработчикам отписали, как найдем время то отправим pull request им, судя по всему, исправлять они это сами не собираются.
Отдельно сделана обработка gzip сжатых файлов (для дампов sql и проч.), тут обошлось без костылей с помощью стандартной библиотеки.
Прогресс операции отслеживается с помощью вотчера на системный вызов IN_CREATE, используя библиотеку pyinotify. Работает, конечно, не очень точно (не всегда вотчер срабатывает, когда большая вложенность файлов, поэтому добавлен магический коэффициент 1.5), но задачу отобразить хоть что-то похожее для пользователей выполняет. Неплохое решение, учитывая, что нет возможности отследить это, не переписывая все библиотеки для архивов.
Код распаковки и создания архивов.
Пример кода с комментариями# Пример работы скрипта для распаковки ахивов # Мы не ожидали, что везде придется вносить костыли, работа с русскими буквами, архивы windows и т.д # Сами библиотеки также нуждались в доработке, в том числе и стандартная ZipFile из python 3 from lib.FileManager.ZipFile import ZipFile, is_zipfile from lib.FileManager.LibArchiveEntry import Entry if is_zipfile(abs_archive_path): self.logger.info("Archive ZIP type, using zipfile (beget)") a = ZipFile(abs_archive_path) elif rarfile.is_rarfile(abs_archive_path): self.logger.info("Archive RAR type, using rarfile") a = rarfile.RarFile(abs_archive_path) else: self.logger.info("Archive 7Zip type, using py7zlib") a = SevenZFile(abs_archive_path) # Бибилиотека не распаковывает файлы, если они пусты (не создает пустые файлы и папки) for fileinfo in a.archive.header.files.files: if not fileinfo['emptystream']: continue name = fileinfo['filename'] # Костыли для windows - архивов try: unicode_name = name.encode('UTF-8').decode('UTF-8') except UnicodeDecodeError: unicode_name = name.encode('cp866').decode('UTF-8') unicode_name = unicode_name.replace('\\', '/') # For windows name in rar etc. file_name = os.path.join(abs_extract_path, unicode_name) dir_name = os.path.dirname(file_name) if not os.path.exists(dir_name): os.makedirs(dir_name) if os.path.exists(dir_name) and not os.path.isdir(dir_name): os.remove(dir_name) os.makedirs(dir_name) if os.path.isdir(file_name): continue f = open(file_name, 'w') f.close() infolist = a.infolist() # Далее алгоритм отличается по скорости. В зависимости от того есть ли # not-ascii имена файлов - выполним по файлам, а если нет вызовем extractall() # Классическая проверка not_ascii = False try: abs_extract_path.encode('utf-8').decode('ascii') for name in a.namelist(): name.encode('utf-8').decode('ascii') except UnicodeDecodeError: not_ascii = True except UnicodeEncodeError: not_ascii = True # ========== # Алгоритм по распаковке скрыт для краткости - там ничего интересного # ========== t = threading.Thread(target=self.progress, args=(infolist, self.extracted_files, abs_extract_path)) t.daemon = True t.start() # Прогресс операции отслеживается с помошью вотчера на системный вызов IN_CREATE # Неплохое решение, учитывая, что нет возможности отследить это, не переписывая все библиотеки для архивов def progress(self, infolist, progress, extract_path): self.logger.debug("extract thread progress() start") next_tick = time.time() + REQUEST_DELAY # print pprint.pformat("Clock = %s , tick = %s" % (str(time.time()), str(next_tick))) progress["count"] = 0 class Identity(pyinotify.ProcessEvent): def process_default(self, event): progress["count"] += 1 # print("Has event %s progress %s" % (repr(event), pprint.pformat(progress))) wm1 = pyinotify.WatchManager() wm1.add_watch(extract_path, pyinotify.IN_CREATE, rec=True, auto_add=True) s1 = pyinotify.Stats() # Stats is a subclass of ProcessEvent notifier1 = pyinotify.ThreadedNotifier(wm1, default_proc_fun=Identity(s1)) notifier1.start() total = float(len(infolist)) while not progress["done"]: if time.time() > next_tick: count = float(progress["count"]) * 1.5 if count <= total: op_progress = { 'percent': round(count / total, 2), 'text': str(int(round(count / total, 2) * 100)) + '%' } else: op_progress = { 'percent': round(99, 2), 'text': '99%' } self.on_running(self.status_id, progress=op_progress, pid=self.pid, pname=self.name) next_tick = time.time() + REQUEST_DELAY time.sleep(REQUEST_DELAY) # иначе пользователям кажется, что распаковалось не полностью op_progress = { 'percent': round(99, 2), 'text': '99%' } self.on_running(self.status_id, progress=op_progress, pid=self.pid, pname=self.name) time.sleep(REQUEST_DELAY) notifier1.stop() -
Повышенные требования к безопасности
Задача:
Не дать пользователю возможности получить доступ к конечному серверуПроблемы:
Все знают, что на хостинговом сервере одновременно могут находиться сотни сайтов и пользователей. В первых версиях нашего продукта воркеры могли выполнять некоторые операции с root-привилегиями, в некоторых случаях теоретически (наверное) можно было получить доступ к чужим файлам, папкам, прочитать лишнее или что-то сломать.Конкретные примеры, к сожалению, привести не можем, баги были, но сервер в целом они не затрагивали, да и являлись больше нашими ошибками, нежели дырой в безопасности. В любом случае, в рамках инфраструктуры хостинга есть средства снижения нагрузки и мониторинга, а в версии для OpenSource мы решили серьезно улучшить безопасность.
Решение:
Все операции были вынесены, в так называемые, workers (createFile, extractArchive, findText) и т.д. Каждый worker, прежде чем начать работать, выполняет PAM аутентификацию, а также setuid пользователя.При этом все воркеры работают каждый в отдельном процессе и различаются лишь обертками (ждем или не ждем ответа). Поэтому, даже если сам алгоритм выполнения той или иной операции может содержать уязвимость, будет изоляция на уровне прав системы.
Архитектура приложения также не позволяет получить прямой доступ к файловой системе, например, через web-сервер. Данное решение позволяет достаточно эффективно учитывать нагрузку и мониторить активность пользователей на сервере любыми сторонними средствами.
Установка
Мы пошли по пути наименьшего сопротивления и вместо ручной установки подготовили образы Docker. Установка по сути выполняется несколькими командами:
user@host:~$ wget https://raw.githubusercontent.com/LTD-Beget/sprutio/master/run.sh
user@host:~$ chmod +x run.sh
user@host:~$ ./run.sh
run.sh проверит наличие образов, в случае если их нет скачает, и запустит 5 контейнеров с компонентами системы. Для обновления образов необходимо выполнить
user@host:~$ ./run.sh pull
Остановка и удаление образов соответственно выполняются через параметры stop и rm. Dockerfile сборки есть в коде проекта, сборка занимает 10–20 минут.
Как поднять окружение для разработки в ближайшее время напишем на сайте и в wiki на github.
Помогите нам сделать Sprut.IO лучше
Очевидных возможностей для дальнейшего улучшения файлового менеджера достаточно много.
Как наиболее полезные для пользователей, нам видятся:
- Добавить поддержку SSH/SFTP
- Добавить поддержку WebDav
- Добавить терминал
- Добавить возможность работы с Git
- Добавить возможность расшаривания файлов
- Добавить переключение тем оформление и создание различных тем
- Сделать универсальный интерфейс работы с модулями
Если у вас есть дополнения, что может быть полезно пользователям, расскажите нам о них в комментариях или в списке рассылки sprutio-ru@groups.google.com.
Мы начнем их реализовывать, но не побоюсь этого сказать: своими силами на это уйдут годы если не десятилетия. Поэтому, если вы хотите научиться умеете программировать, знаете Python и ExtJS и хотите получить опыт разработки в открытом проекте — приглашаем вас присоединиться к разработке Sprut.IO. Тем более, что за каждую реализованную фичу мы будем выплачивать вознаграждение, так как нам не придется реализовывать ее самим.
Список TODO и статус выполнения задач можно увидеть на сайте проекта в разделе TODO.
Спасибо за внимание! Если будет интересно, то с радостью напишем еще больше деталий про организацию проекта и ответим на ваши вопросы в комментариях.
Сайт проекта: https://sprut.io
Демо доступно по ссылке: https://demo.sprut.io:9443
Исходный код: https://github.com/LTD-Beget/sprutio
Русский список рассылки: sprutio-ru@groups.google.com
Английский список рассылки: sprutio@groups.google.com
