Вжух, и прогоны автотестов оптимизированы. Intellij IDEA плагины на службе QA Automation

Привет, Хабр. Я работаю QA Automation инженером в компании Wrike и хотел бы поговорить о том, как нам удалось оптимизировать процесс код-ревью для репозитория с 30 000+ автотестов при помощи IntelliJ IDEA плагина. Я расскажу о внутреннем устройстве плагина и о том, какие проблемы он решает в нашей компании. А еще в конце статьи будет ссылка на Github репозиторий с кодом плагина, с помощью которого вы сможете попробовать встроить плагин в ваши процессы.
Автотесты и деплой в Wrike
Мы пишем много разнообразного кода на Java в проекте автотестов. Сейчас у нас существует более тридцати тысяч тестов, которые тестируют наш продукт через Selenium, REST API, WebSocket и т.д. Все тесты разбиты на множество Maven-модулей в соответствии со структурой кода фронтенда. Проект активно меняется (релизы 1–3 раза в день), и, чтобы поддерживать качество кода, мы используем хорошо развитый механизм код-ревью. Во время ревью проверяем не только качество, но и работоспособность тестов.
Автотесты — это, конечно, важно, но без тестируемого продукта они бесполезны. В общем случае добавление новой функциональности в продукт подразумевает не только наличие веток фронтенда и бэкенда, но и ветки с тестами в проекте автотестов. Все ветки деплоятся одновременно. Ежедневно мы срезаем в мастер десятки веток в нескольких деплоях. Перед началом деплоя происходит запуск тестов. Если в результатах запуска обнаруживаются проблемы из-за ошибок в коде проекта автотестов, то это приводит к нежелательной задержке деплоя.
Чтобы избежать таких ситуаций, мы решили добавить в процесс код-ревью одно действие. Автор merge request должен приложить ссылку на «зеленый» прогон автотестов в Teamcity, а ревьюер — перейти по ней и проверить, что прогон действительно «зеленый».
Какие проблемы могут возникнуть при запуске автотестов
Но автора merge request могут поджидать неприятности даже в такой простой процедуре как добавление ссылки на прогон. Если автоматизатор меняет в проекте большое количество кода, то ему нелегко понять, какие именно тесты нужно прогонять, чтобы убедиться, что ничего не сломалось.
У нас есть два механизма запуска тестов:
- По группам — продуктовая разметка вида Epic/Feature/Story.
- По идентификаторам (id) — любой автотест помечается уникальным числом, и можно запускать прогон по набору таких чисел.
В большинстве случаев прогон бежит по продуктовой группе тестов: указать группу быстрее, чем собирать id автотестов по всему проекту. Автоматизатор пытается по изменениям в коде предположить, автотесты каких частей продукта он затронул.
Дальше события могут развиваться по нескольким сценариям.
Сценарий 1: Запущено меньше тестов, чем в действительности затронуто новым кодом.
Первая проблема — потенциальное замедление процесса деплоя. Ведь есть риск, что пропущен тест, который перестал работать из-за изменений в коде. Тогда он обнаружится в день деплоя и затормозит доставку продукта пользователям.
Сценарий 2: Запущено больше тестов, чем в действительности затронуто новым кодом.
Вторая проблема — избыточная работа инфраструктуры для запуска тестов, за которую платит компания. Это увеличивает очередь на запуск тестов в Teamcity, что заставляет дольше ждать результат прогона.
Чтобы решить эти проблемы, мы создали Find Affected Tests — IntelliJ IDEA плагин, который быстро и надежно находит список id тестов, затронутых изменениями в коде проекта автотестов.
От бизнес-проблем к реализации
«Но почему именно IntelliJ IDEA плагин?», — спросите вы. Чтобы создать инструмент, который решит наши проблемы, мне пришлось ответить на два вопроса:
- Откуда брать изменения кода?
- Как по изменениям в коде найти затронутые id?
На первый вопрос ответ был очевиден. Мы используем Git в качестве VCS и через него можем получать информацию про состояние текущей ветки.
Ответом на второй вопрос стал PSI (Program Structure Interface). Я выбрал именно этот инструмент по нескольким причинам:
- Мы используем IntelliJ IDEA в качестве IDE.
- IntelliJ Platform SDK включает в себя PSI — удобный инструмент для работы с кодом проекта, который используется и самой IntelliJ IDEA.
- Функциональность IntelliJ IDEA можно расширить за счет механизма плагинов.
Последняя причина и определила форму инструмента для поиска id автотестов — плагин, который встроен в IDE и позволяет получать список id тестов, которые были затронуты в ходе разработки.
Структура плагина
Давайте посмотрим на UI плагина, чтобы представить, что видит автоматизатор перед запуском поиска id:
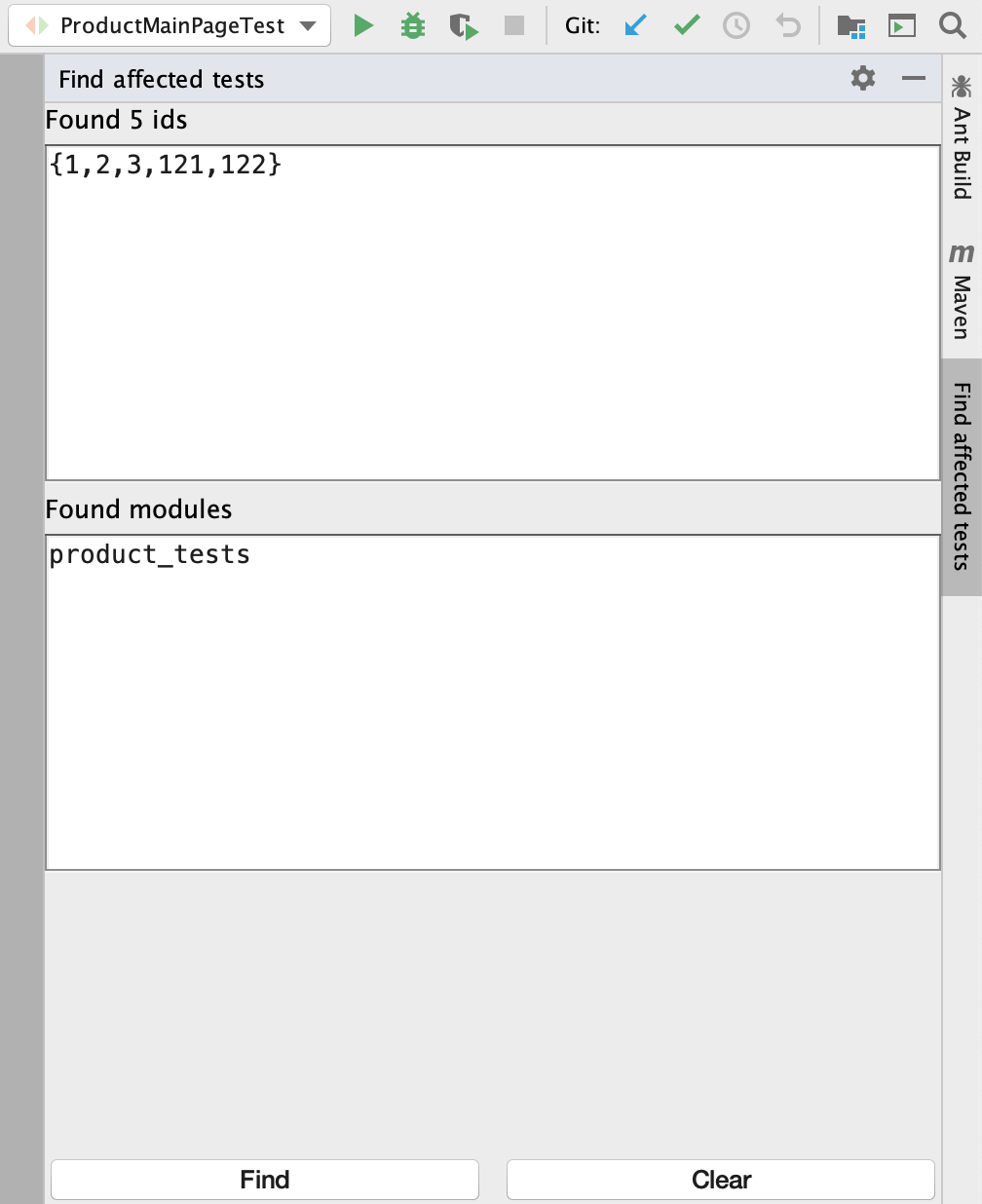
Так выглядит упрощенная версия, которая выложена на GitHub
Все интуитивно понятно: запустили поиск, посмотрели результат. Результат состоит из двух частей: id автотестов и списка Maven-модулей, в которых эти автотесты находятся (зачем нужен этот список я расскажу дальше в этой статье).
Внутренняя структура плагина состоит из двух основных модулей:
- Git модуль получает информацию о текущей ветке и преобразует ее к формату, понятному PSI.
- PSI модуль на основании данных от Git модуля ищет id тестов, которые затронуты изменениями в текущей ветке.
Взаимодействие UI-части плагина с модулями схематично выглядит так:
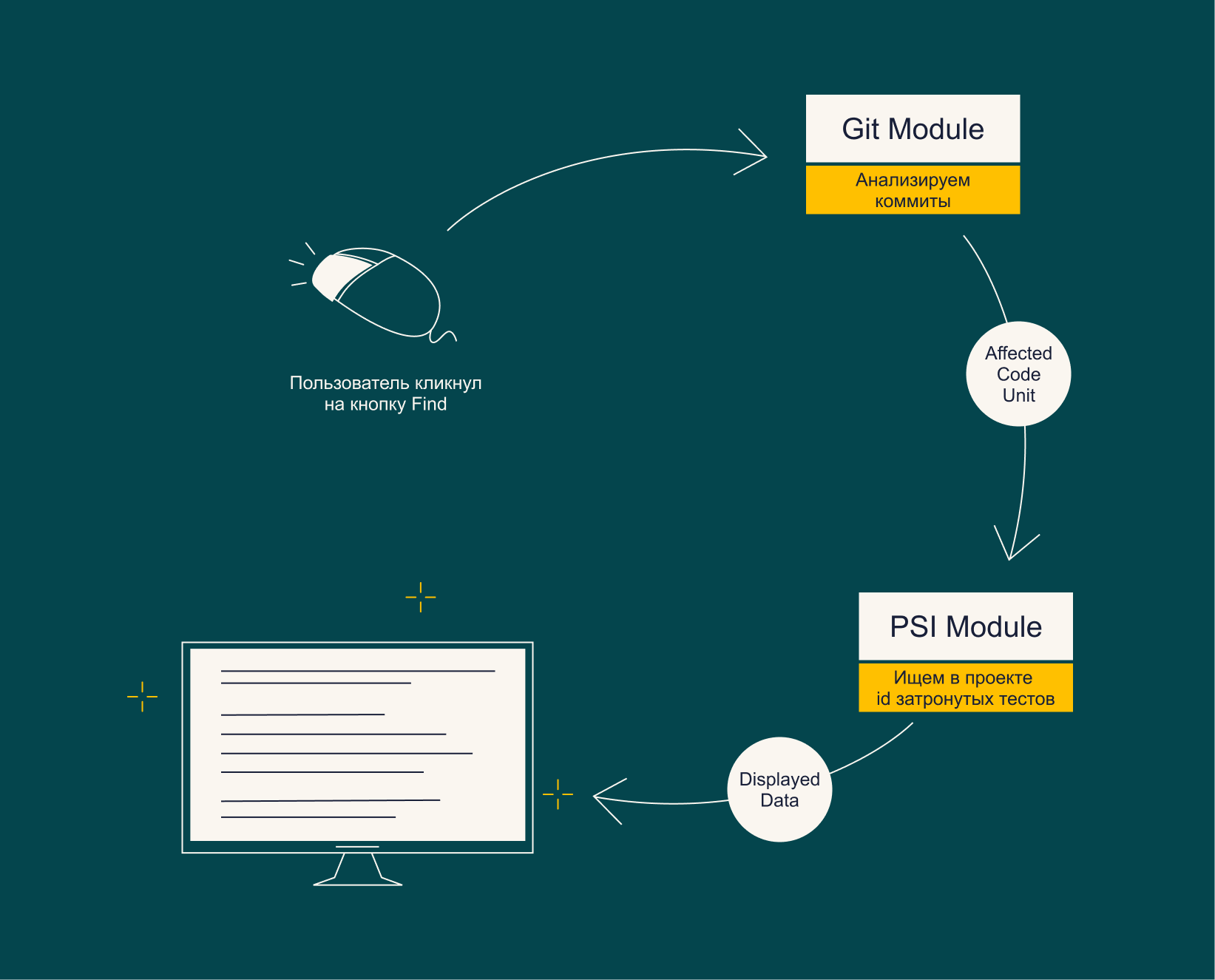
AffectedCodeUnit и DisplayedData — это классы для передачи данных между модулями
Git модуль
Нам были важны изменения в коде относительно мастера, поэтому я решил собрать все коммиты из текущей ветки, которых нет в мастере. Каждый коммит включает в себя изменения некоторых файлов.
Для каждого файла собираются следующие данные:
- Имя файла, имя модуля и путь до файла относительно корня проекта. Это позволяет в дальнейшем упростить поиск файла через механизмы PSI.
- Номера измененных строк в файле. Это позволяет понять, что именно было изменено в структуре Java-кода.
- Был ли файл удален или создан с нуля. Это помогает оптимизировать работу с ним в будущем и избежать ошибок в некоторых ситуациях (например, не обращаться к удаленному файлу через PSI).
Все эти сведения содержатся в выводе команды git diff. Пример результата выглядит так:
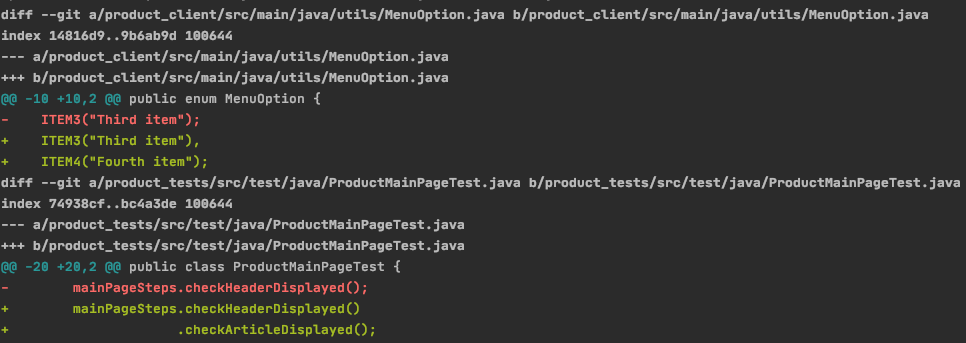
В выводе команды можно сразу заметить путь до измененного файла. Данные о номерах строк измененного кода содержаться в строках вида »@@ -10 +10,2 @@». В этой статье я не буду подробно объяснять их смысл, но примеры можете посмотреть на Stackoverflow или поискать информацию про git diff unified format
Аргументами для git diff выступают текущая локальная ветка пользователя и remote master, а ряд ключей позволяет сократить вывод команды до нужного размера.
Каким образом происходит взаимодействие с Git в коде плагина? Я попытался найти встроенные механизмы IntelliJ IDEA, чтобы не изобретать велосипед. В итоге обнаружил, что для Git в IntelliJ IDEA существует свой плагин — git4Idea. По сути это GUI для стандартных операций с проектом. Для доступа к Git в нашем плагине используются интерфейсы из кода git4Idea.
В итоге получилась такая схема:
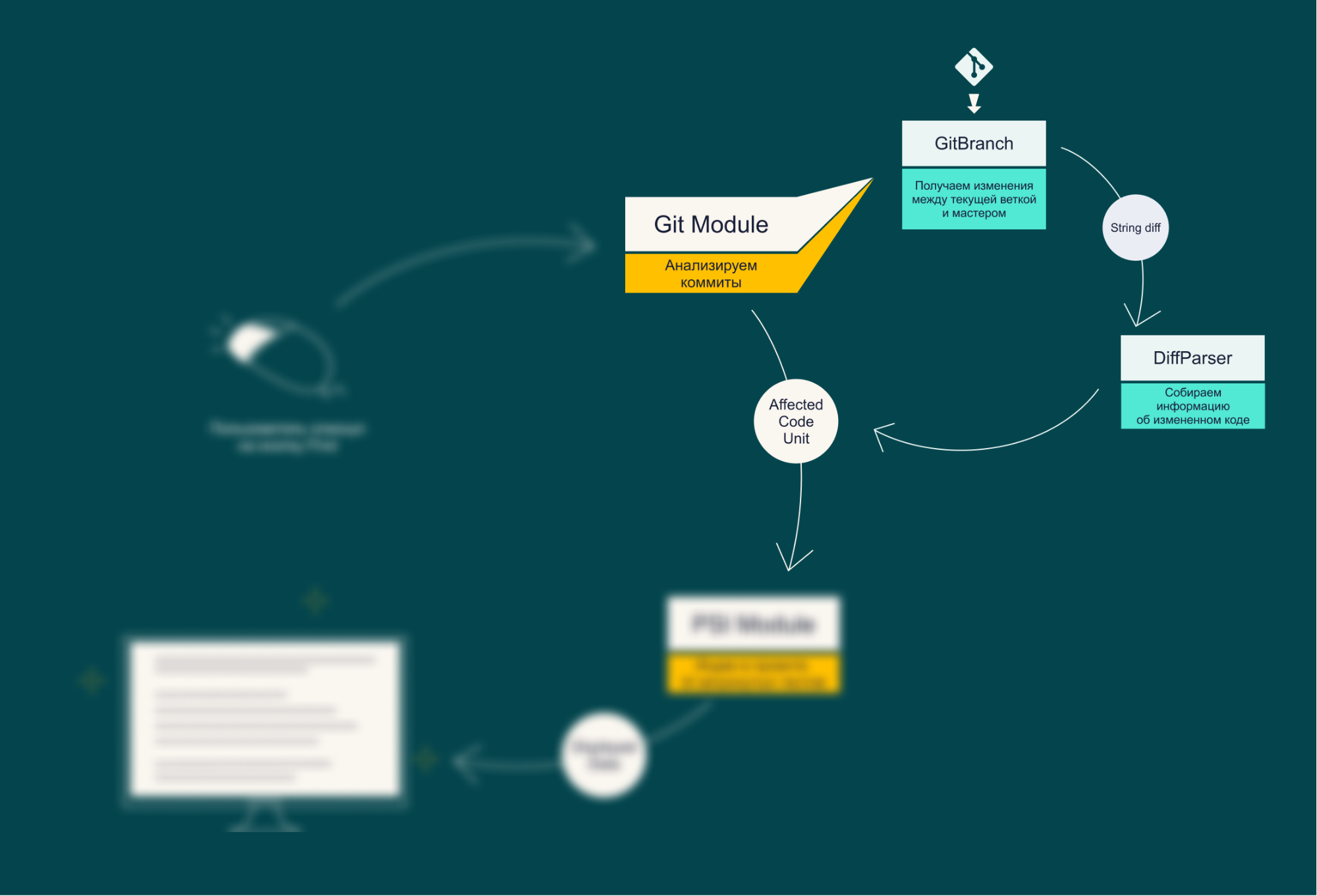
Через класс GitBranch запрашивается diff, затем diff отправляется в DiffParser. На выходе остается список объектов класса AffectedCodeUnit (в них содержится информация об измененных файлах с кодом). О судьбе этого списка я расскажу в описании PSI модуля.
PSI модуль
Теперь информацию об измененных файлах нужно применить для поиска id автотестов. Чтобы разобраться, как по номерам измененных строк найти элементы Java-кода, нужно подробнее посмотреть на устройство PSI.
Как IntelliJ IDEA работает с произвольным проектом. Для PSI любой файл преобразуется в дерево отдельных элементов. Каждый элемент реализует интерфейс PsiElement и представляет собой структурную единицу кода для конкретного языка программирования. Это может быть целый класс или метод, а может быть закрывающая скобка небольшого блока кода.
Для нашей задачи элемент Java кода и есть PsiElement-объект. Здесь мы приходим к новой формулировке вопроса. Как по номерам измененных строк кода найти PsiElement-объекты? В интерфейсе PsiFile (представление файла с кодом в виде объекта) был унаследован метод findElementAt, который по сдвигу относительно начала текстового представления файла умел находить PsiElement.
Но возникла новая проблема: каждая строка в файле потенциально содержит немало символов, и по номеру строки можно получить много разных PsiElement-объектов.
Как выбрать нужный PsiElement-объект. Дерево, в которое IntelliJ IDEA отображает Java-код, может состоять из огромного числа узлов. Конкретный узел может описывать незначительный элемент кода. Для меня важны узлы конкретных типов: PsiComment, PsiMethod, PsiField и PsiAnnotation.
И вот почему:
String parsedText = parser.parse("Text to parse");
В этом фрагменте можно изменить разные части кода: имя переменной parsedText, входной параметр метода parse, код после оператора присваивания (вместо вызова parse можно вызвать другой метод) и т.д. Видов изменений много, но для логики работы плагина важно то, что фрагмент кода может находиться внутри какого-то метода, как в этом примере:
public String parseWithPrefix(Parser parser, String prefix) {
String parsedText = parser.parse("Text to parse");
return prefix + parsedText;
}
В такой ситуации нет смысла пытаться понять, что поменялось в строчке кода с объявлением String parsedText. Нам важно, что изменился метод parseWithPrefix. Таким образом, нам не важна излишняя точность при поиске PsiElement-объектов для измененной строки кода. Поэтому я решил брать символ посередине строки как измененный и искать привязанный к нему PsiElement. Такая процедура позволила получить список затронутых PsiElement объектов и по ним искать id автотестов.
Конечно, можно придумать примеры Java-кода с диким форматированием, в котором нужно учитывать больше условий для поиска PsiElement-объекта. Как в этом примере:
public String parseWithPrefix(Parser parser, String prefix) {
String parsedText = parser.parse("Text to parse");
return prefix + parsedText; } private Parser customParser = new Parser();
Изменения в последней строке могут затрагивать как метод parseWithPrefix, так и поле customParser. Но у нас есть механизмы анализа кода, которые не допустят подобное в мастер.
Как устроен базовый алгоритм получения id автотестов по набору PsiElement-объектов. Для начала нужно уметь по PsiElement-объекту получать его использования (usages) в коде. Это можно сделать с помощью интерфейса PsiReference, который реализует связь между объявлением элемента кода и его использованием.
Теперь сформулируем краткое описание алгоритма:
- Получаем список PsiElement-объектов от Git модуля.
- Для каждого PsiElement-объекта ищем все его PsiReference объекты.
- Для каждого PsiReference объекта проверяем наличие id и сохраняем, если нашли.
- Для каждого PsiReference объекта ищем его PsiElement-объект и рекурсивно запускаем на нем описанную процедуру.
Процедуру следует повторять, пока находятся PsiReference-объекты.
Для задачи поиска абстрактной информации в коде алгоритм выглядит так:
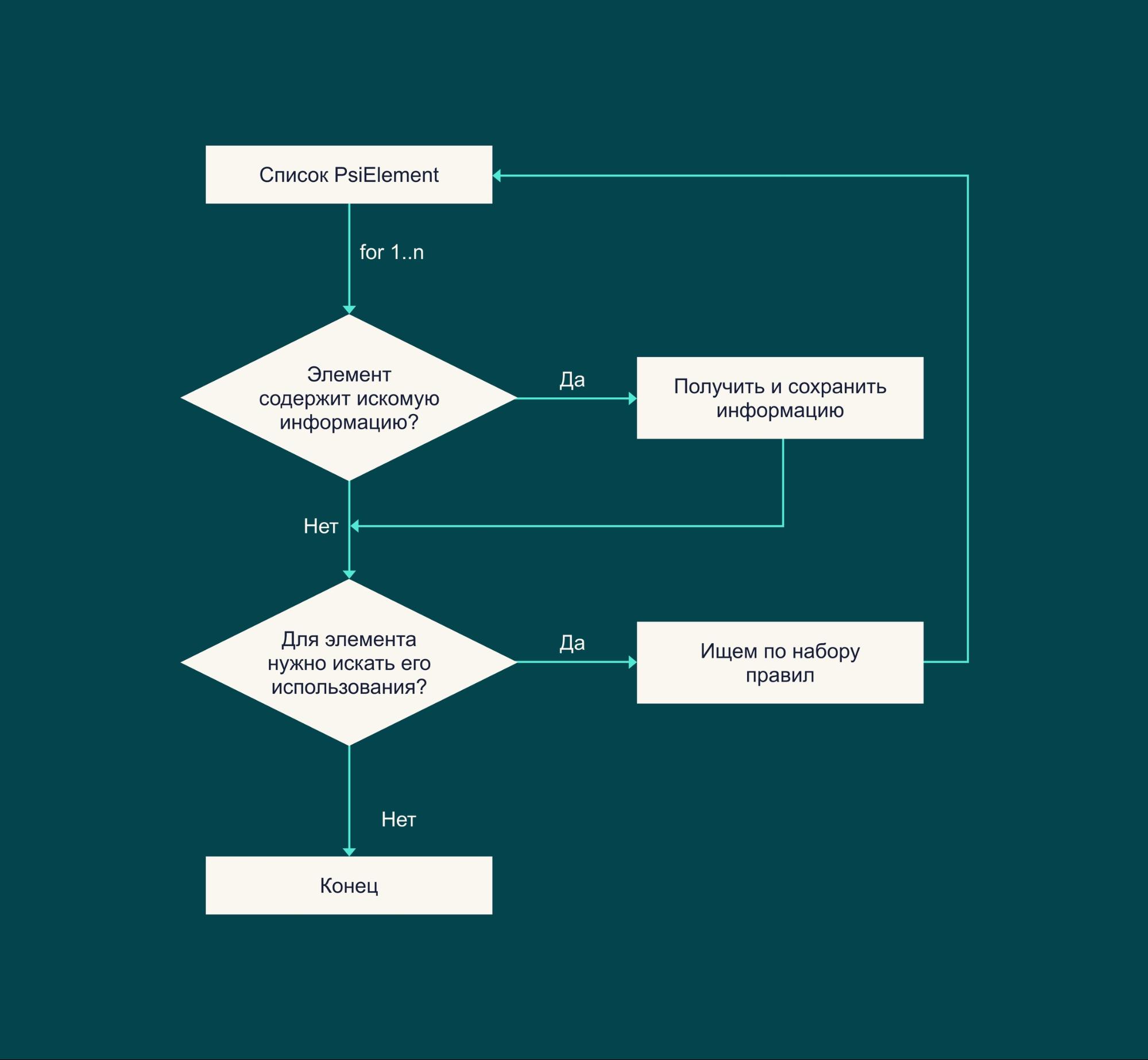
В нашей задаче нужно найти id автотестов. Вот так можно применить блок-схему для этого:

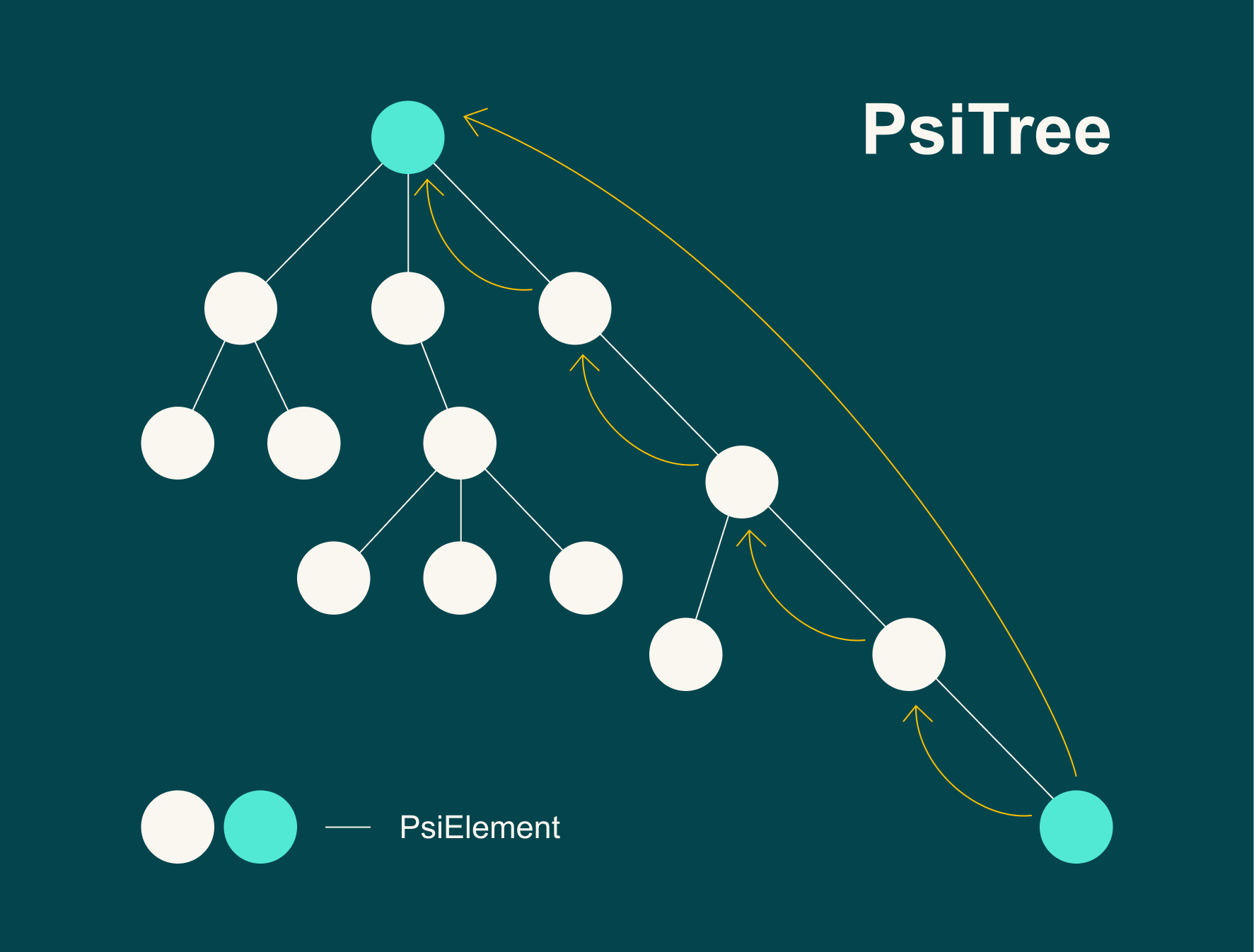
Оптимизация алгоритма. В процессе реализации алгоритма я столкнулся с одной проблемой. Алгоритм работает с PsiTree-объектом, который состоит из большого числа узлов. Каждый узел соответствует элементам Java-кода. Механизм поиска PsiReference-объектов по умолчанию может находить довольно незначительные элементы Java-кода, из-за чего алгоритм будет совершать много лишних действий в процессе движения по дереву. Это замедляет работу алгоритма на несколько минут в тех случаях, когда найдено около тысячи тестов или больше.
Пример для наглядности: предположим, что значение переменной wrikeName изменилось:
public List nonWrikeUsers(List users) {
String wrikeName = "Wrike, Inc.";
return users.stream()
.filter(user -> !wrikeName.equals(user.getCompanyName()))
.collect(Collectors.toList());
}
Тогда в поисках использования wrikeName мы сначала придем к вызову метода equals, затем — к отрицанию результата вызова equals, а после — к лямбде внутри вызова filter. Но эту длинную цепочку шагов можно заменить на поиск использований изменившегося метода nonWrikeUsers.
И тогда вместо четырех итераций алгоритма по каждому узлу дерева мы получим всего одну:
Проблему лишних операций в алгоритме удалось решить благодаря тому же ограничению типа данных PsiElement-объектов до PsiComment, PsiMethod, PsiField и PsiAnnotation. Именно эти PSI-сущности содержат всю релевантную информацию для поиска id затронутых автотестов.
Пример релевантной информации: затронуто поле какого-то класса (объект типа PsiField), оно могло использоваться в каком-то автотесте.
Пример нерелевантной информации: затронуто объявление локальной переменной (объект типа PsiLocalVariable). Здесь нам важно лишь то, где находится эта переменная (например, в теле другого метода). Само ее изменение нам ничего не дает.
В начало логики алгоритма я добавил поиск прародительского узла с нужным типом данных. Поиск осуществляется при помощи метода getParentOfType класса PsiTreeUtil. Для каждого типа PsiElement-объекта я создал реализацию логики обработки. Например, для прародителя типа PsiField отрабатывает объект класса FieldProcessing, а для PsiComment — объект класса CommentProcessing. Код плагина исполняет подходящую логику в зависимости от результата работы метода getParentOfType.
В общем виде логика работы выглядит так:
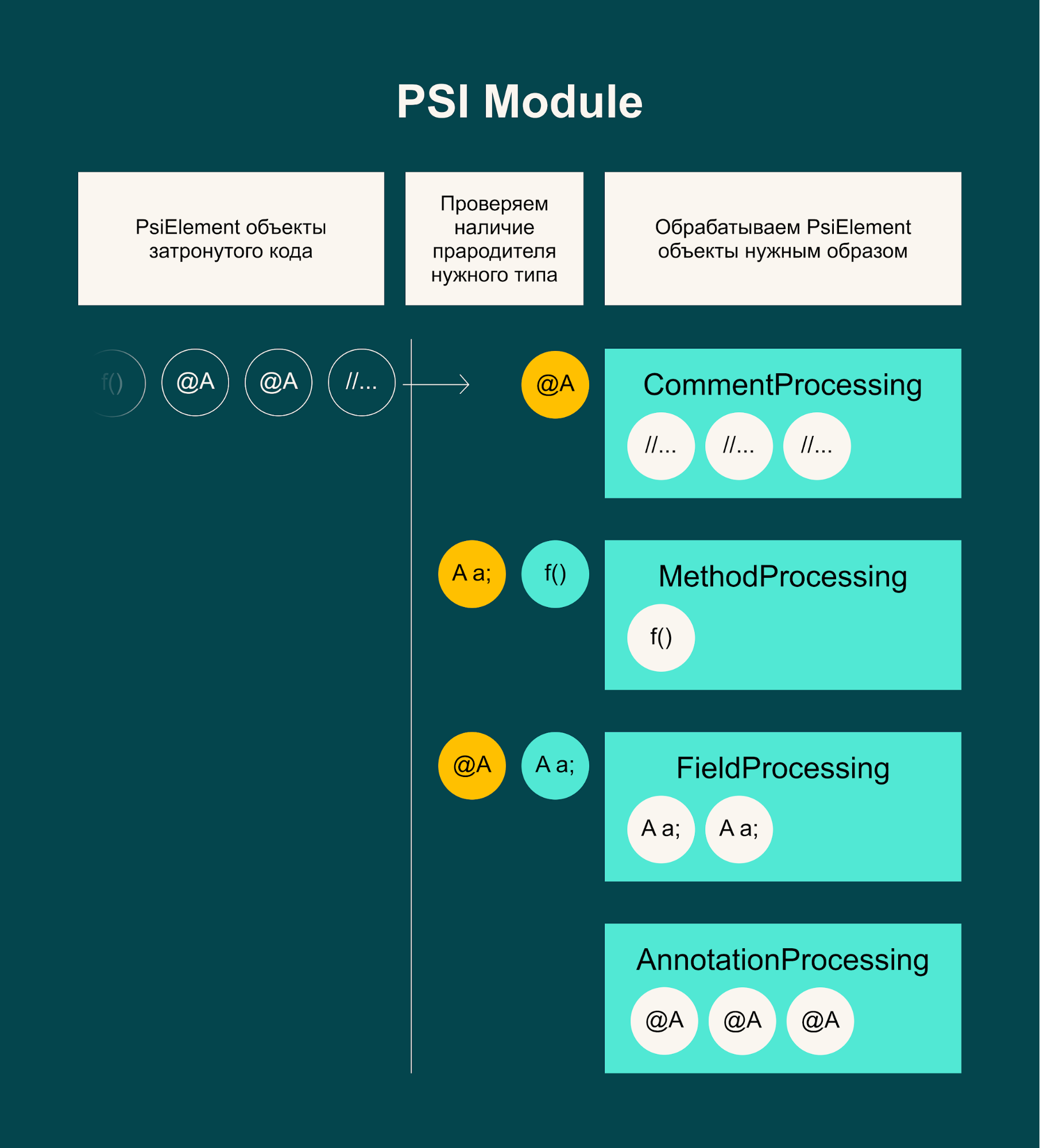
Пример реализации логики обработки одного из типов PsiElement-объектов:
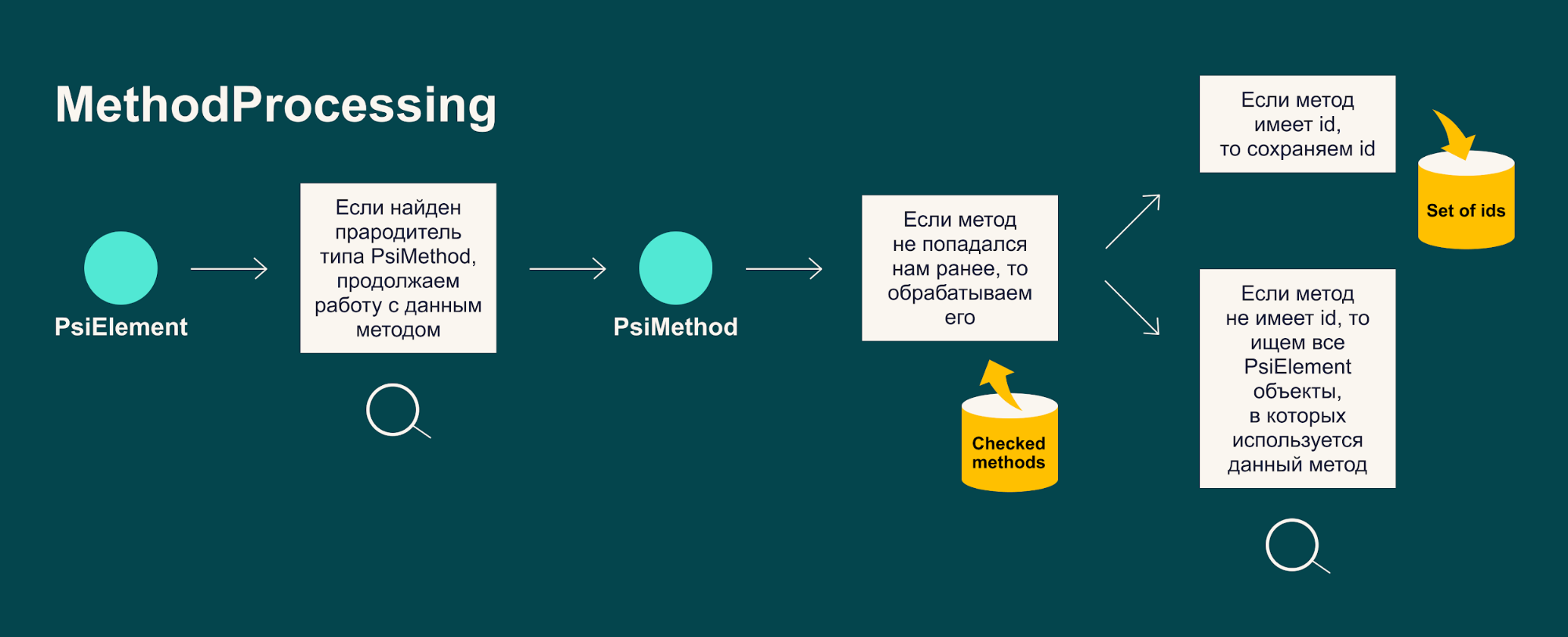
Подытожу основные основные особенности PSI модуля:
- Модуль работает по рекурсивному алгоритму поиска id автотестов. Краткая идея алгоритма заключается в поиске id для всех измененных PsiElement-объектов через механизм PsiReference.
- Алгоритм работает не со всеми узлами PsiTree-объекта, чтобы не совершать избыточные итерации.
Дополнительные возможности плагина
После того, как мы начали использовать плагин в работе, коллеги прислали несколько запросов по его улучшению. Это помогло усовершенствовать инструмент и оптимизировать прогоны автотестов.
Делаем работу с Git модулем гибче
В изначальной версии модуля можно было сравнивать текущую ветку с мастером (причем для ветки брался последний коммит). Но иногда это приводило к бесполезной работе инфраструктуры. А ведь именно с этим плагин и боролся.
Пример 1: автоматизатор создает merge request с одним коммитом. Он прогоняет 1000 тестов, которые затронуты этим коммитом. Ревьюер оставляет замечания по коду, автор merge request их исправляет. Эти правки затрагивают теперь только 200 тестов, но плагин предложит прогнать и 1000 тестов из изначального прогона, так как учтен первый коммит. Получаем лишние тесты для прогона.
Решение: я добавил возможность сравнивать локальную версию ветки с удаленной версией. Так будут учитываться только коммиты, которые еще не были запушены.
Пример 2: автоматизатор создает интеграционную ветку для того, чтобы мерджить туда другие ветки на протяжении некоторого времени (код в мастер в итоге будет добавлен из интеграционной ветки). На код-ревью ветка для мерджа в интеграционную ветку будет включать в себя коммиты оттуда. Но эти коммиты уже могли быть проверены раньше при помощи плагина. В итоге мы каждый раз получаем лишние тесты для прогона.
Решение: я реализовал функциональность для сравнения локальной версии ветки с произвольной веткой (в общем виде с любым коммитом). Это позволяет гибко учитывать коммиты при работе с несколькими ветками.
Помогаем внедрить новую оптимизацию с помощью плагина
Для понимания пользы второго улучшения нужно рассказать небольшую предысторию. Как я упоминал выше, наш проект состоит из огромного количества Maven-модулей. В какой-то момент рост числа Maven-модулей в нашем проекте привел к ожиданию при каждом запуске автотестов, так как код рекурсивно компилировался во всех модулях, даже если тесты нужны были только из одного. В этой ситуации снова возникла проблема бесполезной работы инфраструктуры.
Тогда мы решили изменить сценарий запуска. Теперь пересобираются только модули, указанные вручную. Это позволило в среднем снизить время компиляции с 20 минут до 3–4.
Чтобы узнать, в каких именно модулях находятся затронутые тесты, я добавил в плагин логику вывода затронутых модулей. Для ее реализации во время получения id автотеста нужно взять пути до файла с тестом в операционной системе и относительно корня проекта. Зная структуру директорий типичного Maven проекта, можно обрезать все лишнее и оставить часть пути с именами модулей.
В итоге удалось быстрее внедрить новую логику запуска и как результат — уменьшить время ожидания прогона тестов и КПД инфраструктуры.
Планы по развитию плагина
Плагин выходит в сеть. Мы автоматизировали сбор id затронутых тестов, но после автоматизатору все еще приходится выполнять набор однотипных действий для запуска прогона и дальнейшей работы с ним:
- Открыть нужный билд в Teamcity.
- Ввести данные для прогона.
- Сохранить ссылку на прогон для проверки его результатов.
Это отвлекает от решения других задач и приводит к возможным ошибкам: запуск в неверной сборке Teamcity, ошибки при копировании данных для прогона.
Так возникла задача: научить плагин запускать прогон в Teamcity самостоятельно. У нас есть специальный инструмент, который аккумулирует большинство данных, связанных с CI/CD процессами. Поэтому плагину проще отсылать запрос на запуск прогона этому инструменту (в нем же будет сохранена ссылка на прогон). Реализация этой логики позволит уменьшить количество рутинных действий после написания кода и сделает процесс запуска автотестов надежнее.
Многопоточность. При большом количестве изменений время работы плагина сильно возрастает, поэтому у нас есть планы по дальнейшей оптимизации, связанные с многопоточностью.
Идея состоит в том, чтобы несколько потоков одновременно занимались анализом разных узлов Psi-дерева. Для этого нужно грамотно выстроить работу с общими ресурсами (например, со множеством уже обработанных PsiElement-объектов). Одним из возможных решений может быть Java Fork/Join Framework, так как работа с деревом подразумевает рекурсивность. Но здесь есть подводные камни: у IntelliJ IDEA есть свой пул потоков, в который нужно грамотно встроить новую логику.
Несколько выводов
Как плагин повлиял на проблемы, для решения которых он создавался? Время деплоя — очень сложная величина, на которую влияет огромное количество факторов. Пожалуй, не существует метрик, отражающих прямое влияние плагина на нее. Поэтому перейдем сразу к проблеме запуска автотестов в процессе код-ревью.
У нас есть сборка в Teamcity, в которой традиционно гоняются запущенные вручную автотесты. Она позволяет запустить прогон с указанием Maven-модулей. Я выбрал эту сборку для примера, потому что ссылку именно на нее автор merge request прикладывает во время код-ревью. А еще запуски в этой сборке выполняются вручную, и автоматизатор может взять набор id для запуска только из плагина (вряд ли кто-то в здравом уме будет собирать их руками).
Так выглядит график общего количества запусков в этой сборке:
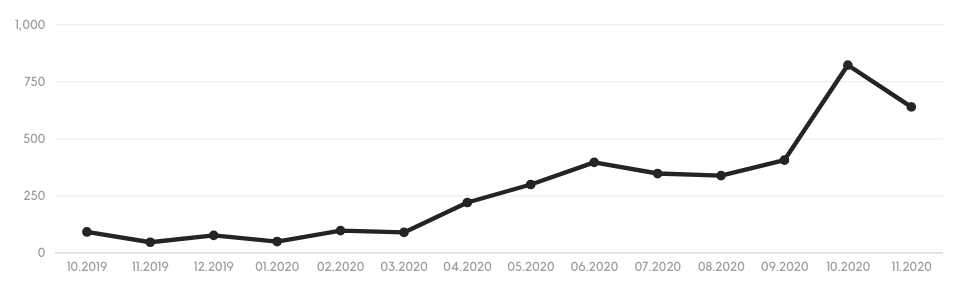
В марте этого года (точка 03.2020) мы анонсировали сборку официально, а в апреле (точка 04.2020) я добавил в плагин вывод Maven-модулей, в которых находились затронутые автотесты. После этого количество запусков возросло в несколько раз. Следующий скачок произошел в сентябре, так как эта сборка стала использоваться для перезапуска автотестов в нашей внутренней деплой туле, но это нам не так интересно.
А этот график показывает, что запуски происходят именно по id, а не по продуктовой разметке. На нем указано процентное отношение между прогонами, в которых указаны id автотестов, и всеми прогонами для данной сборки:

За последние полгода порядка 70–80% запусков автотестов происходят с указанием списка id: коллеги активно используют плагин по назначению. В апреле мы добавили в плагин вывод Maven-модулей. На графике видно, что это увеличило процент запусков с id с 50% до 75% за пару месяцев.
Действительно ли прогоны по id быстрее прогонов по продуктовой разметке? Статистика среднего времени прогона для данной сборки показывает, что да. Для id мы получаем примерно в три раза меньшее время, чем для продуктовой разметки: вместо условных 25–30 минут — 8–10 минут.
Данные на графиках доказывают, что плагин активно используют. А это значит, что нам удалось увеличить количество прогонов в Teamcity, в которых запущенные автотесты подобраны по более надежному алгоритму, чем просто запуск по продуктовой разметке.
Пишите в комментариях про ваши успешные или не очень успешные примеры автоматизации.
Если вас заинтересовала идея плагина (возможно, у вас даже появились мысли о том, где его можно применить), то можете воспользоваться упрощенным кодом его основной версии (тут же выложен проект-заглушка для тестирования плагина). С удовольствием выслушаю замечания и предложения по архитектуре кода.
Всем добра и побольше эффективных оптимизаций!
