Выявление техдолга и оценка его процентов
Как оценить технический долг и получить разрешение на его починку, прежде чем он поглотит вас и вашу команду? Этот вопрос рано или поздно встает перед всеми лид-разработчиками. Но его решение требует большой экспертизы и грамотного анализа. Поэтому давайте вместе разбираться, как лучше искать, извлекать и обеспечивать техдолг, а заодно выясним причём тут слоны.

Выявление технического долга — это тоже самое, что «увидеть слона в помещении». Есть такая английская метафора, которая означает признание крайне некомфортного, но всем известного факта. Могут быть разные пути, по которым к вам прокрался слон. Возможно, вы новый тимлид, которого только наняли на проект или старый тимлид, который решил взять себе новый компонент с техдолгом непонятного масштаба. А может быть другая ситуация, когда мы «неожиданно» обнаруживаем, что в спринт входит все меньше и меньше фичей — и значит, пора что-то менять. Но даже в такой ситуации, мы не спешим встречаться со слоном (техдолгом), потому что, чаще всего, он выглядит так:

Он бывает разрушительным и уничтожает все сразу. А иногда медленно подтачивает своими острыми бивнями ваши микросервисы или монолит. Но в любом случае вам надо быть стойким, чтобы оценить размер техдолга и объем потенциальных разрушений. Потому что не всё так однозначно, как кажется в начале.
Как вы, наверное, знаете, аналогия техдолга берет свое начало от кредитов, поэтому уместно обсуждать ее в этом ключе:
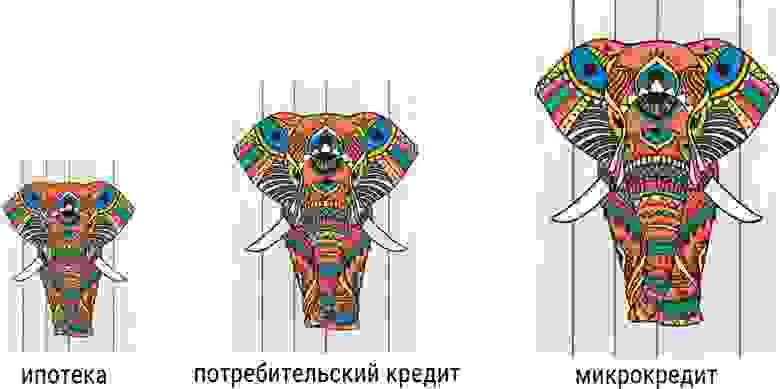
Бывает ипотечный слон/техдолг. Он не слишком сильно мешает, если его планомерно и регулярно поддерживать. Но когда вы сложите проценты всех выплат, то получите внушительную сумму. А бывает микрокредитный долг, маленький, но приносящий кучу проблем, потому что «костыль», встроенный по-быстрому перед релизом, ломается при любой попытке модификации и оттягивает на себя значительный объем разработки. Так выглядит график, когда ваша команда не может делать фичи, а практически всё время бьется со сложностью, порожденной техдолгом:
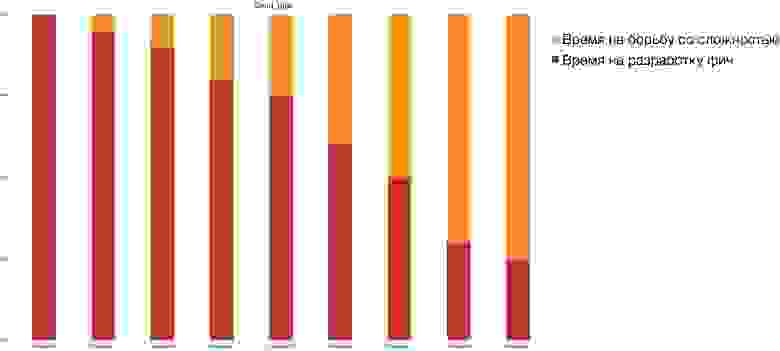
Я не стала драматизировать и доводить до того, что желтые столбики съедают красные вообще до нуля, но иногда бывает и так. И в этот момент руководство говорит: «Сделай с этим что-нибудь!». И ты обещаешь разобраться. Но что надо делать? Какие будут ближайшие 5 шагов, сколько будут стоить фичи и когда мы увидим результат?
Чтобы понять насколько инвестирование в технический долг и в сопровождение облегчит ситуацию в будущем, создается план, при котором инвестиции должны окупиться. Цель — получить примерно такой график:
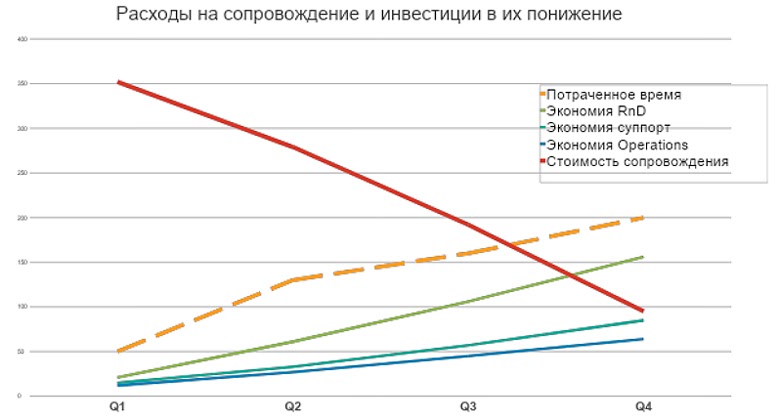
Стоимость сопровождения (бордовая линия) падает, а время, которое мы тратим на улучшение качества сопровождения не сильно растёт. Это то, что нам нужно посчитать, что позволит нам аргументировать. Но как получить эти цифры и где найти аргументы?
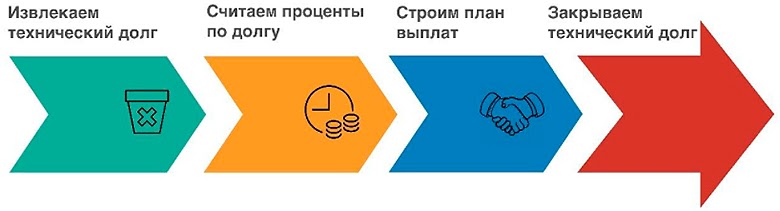
Извлекаем долги
Техдолг из разработчиков
Прежде всего, техдолг извлекается из умов разработчиков. Практически у каждого инженера есть ToDo лист, в котором можно найти много полезного. Например, из саппорта пришли с запросом на утилиту, или неправильно построили какой-то бизнес-сценарий, который может рухнуть при определённых обстоятельствах, или сам инженер читал код и увидел что-то подозрительное, с чем нужно разобраться. У плохого разработчика такого списка просто нет. У хорошего заметок собирается много. А у отличного весь Todo лист оформлен в багтрекере. Но положим, что у нас хороший. Основная проблема списков разработчиков — их неупорядоченность.
Когда у нас уходил один из лид-разработчиков, мы с ним провели много часов по сессиям, извлекая его технический долг, и составили 50 dev-тасок, которые потом объединяли в эпики по принципу близости. Важные вопросы, которые помогают такие списки упорядочивать: «Что будет, когда мы это починим?», «Что будет, когда у суппорта будет утилита?», «Что будет, когда костыль уберем?». Это некомфортные вопросы, но без ответов на них, техдолг превращается в перфекционизм, на который бизнес едва ли даст средства.
Техдолг из расследования инцидента
Следующий сценарий, в котором обитают самые жирные слоны — это расследование инцидентов. Чтобы выделить техдолг из расследования инцидента, нужно при каждом разборе задавать правильные вопросы. Про каждый инцидент вам нужно понимать, что стало первопричиной проблемы, как можно с ней справиться и сколько будет «стоить» каждый из вариантов?
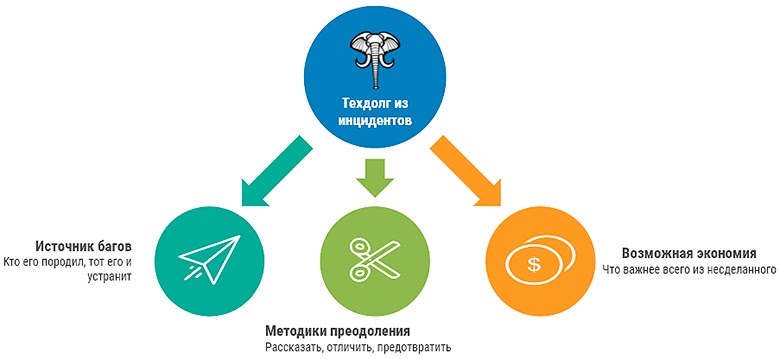
В качестве источника багов не обязательно выступает ваш компонент, но инцидент прилетел в вашу команду и значит время именно вашей команды будет потрачено.
В качестве методик преодоления выступает не столько устранение проблем и физическая починка, сколько расширение диагностического инструментария, позволяющего вам предотвратить такие случаи в будущем или снизить расходы на расследование инцидентов.

Рассмотрим на примере. Некая компания Х занимается разработкой системы резервного копирования. Один из заказчиков информирует её о двух поврежденных архивах. Трое суток десяток специалистов расследует этот инцидент, пока из строя не выходит третий архив того же заказчика в том же дата-центре. Тогда и выясняется, что это баг в оборудовании. На одной из физических нод, которая участвовала в этом кластере, стояла карточка Mellanox. Эти карточки при работе виртуализации имеют баг в работе памяти, поэтому запись данных шла не на ту физическую страницу. А поскольку это распределенная система, данные успели уйти за пределы поврежденной ноды. Это была не ошибка бэкапа, и компания Х не может починить карты Mellanox, но ведь компания отвечает за работу системы в целом.
Значит, должна быть диагностика «железа», тем более, что о таких проблемах с Mellanox уже было известно. В данном примере отсутствие self-test-а системы и тестирования при раскатке и есть тот технический долг, который мы можем вынести из расследования инцидента. И вот уже мы сравниваем стоимость разработки простейшего hw-test-а мидлом и часы потраченные синьорами в этом кейсе.
Этот пример показывает только один источник инцидентов, но обобщив можно назвать следующие источники:
Ошибки компонента — все мечтают писать идеальный код, но его не существует и ошибки случаются. Поэтому в методики преодоления таких проблем включаем high cohesion, low coupling, SOLID принципы и все, что мы учили из «clean code uncle bob-а» и «refactoring-а Фаулера».
Ошибки «соседей», когда ваши разработчики расследуют и устраняют проблемы пришедшие из соседней команды.
Сторонние проблемы: связанные с сетью, СХД, багами в библиотеках и сторонними сервисами.
Ошибки конфигурации: версии, стыковка компонентов, ошибки deployment.
Последняя категория, как мне кажется, особенно коварна. Стыковку компонентов должен проверять суппорт или же при раскатке должны быть явные ошибки с явными откатами. Тихие ошибки и отсутствие проверок — это очередные потенциальные проблемы и очередной техдолг.
Для различных источников проблем применимы разные источники преодоления. Обратите внимание, я говорю о преодолении, а не об устранении. Устранение бага не всегда наша задача — мы не можем починить Mellanox.
Есть два подхода к сокращению времени работы над инцидентами.
Развернутая диагностика: метрики, логи, развернутый код ошибки, kb’шки, self-test.
Заданные алгоритмы Troubleshooting’а: набор инструментов и описание шагов, как различать похожие инциденты.
И тут встает вопрос, какие средства диагностики есть и какие использовать в данный момент. Помимо вашего непосредственного опыта и совета коллег поможет Software architecture: tactics.
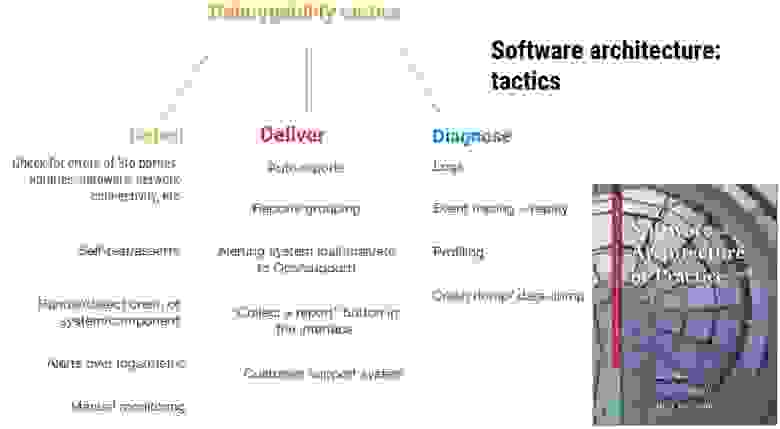
Debuggability — это характеристика качества ПО, non-functional requirement, quality attribute. В Software architecture предполагается, что независимо от паттерна системы есть микротактики, которые позволяют прокачать систему в нужном направлении. В частности, об этом много пишет CMU (Carnegie Mellon University) в таких книгах, как «Software architecture in practice».
Так обычно выглядит troubleshooting-алгоритм:
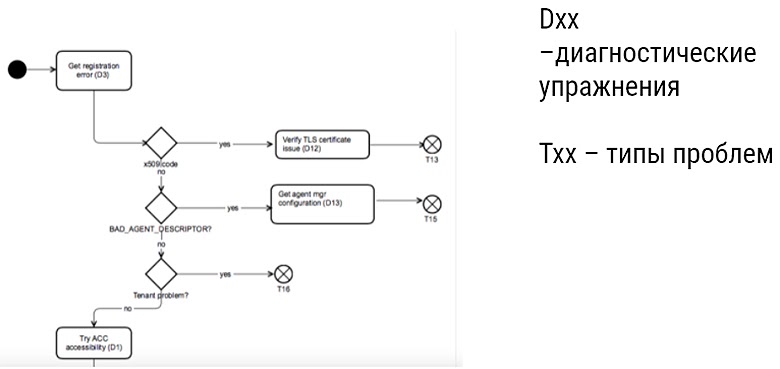
Мы начинаем с какой-то точки, выполняем диагностическое упражнение (проверить соединение, спросить у пользователя, использовать специальные инструменты), которое позволяет дифференцировать разные проблемы. Миссия: дойти от «симптома» до проблемы.
Без явно известного алгоритма troubleshooting больше багов от саппорта приходит к разработчикам, тогда вместо инструментов и автоматизации предлагаются ad hoc решения, но редко получается продвинуться и предотвратить подобные эпизоды. При этом саппорт демотивируется, хорошие люди уходят, и то же самое происходит в разработке. А вот техдолг, в образе ненаписанных инструментов — остается.
Техдолг из кода
Хотя, на мой взгляд, сценарии расследования инцидентов самые наваристые, многие считают, что техдолг надо искать в коде. И все же техдолг не столько в коде, а прежде всего в том, чего в коде нет. Конечно, есть метрики и оценки от статических анализаторов типа SQALE. Я же предпочитаю эмпирику всем формальным методам и отнесла бы к техдолгу:
Fixme/ToDo без заведения бага в багтрекере;
Patterns — нарушенные паттерны там, где ожидаешь синглтон или фабрику;
Code coverage — недостаточное покрытие тестами;
Components version — просроченные версии компонентов, библиотек, прошивок, языков, зачастую вносят путаницу и снижают скорость разработки (уже не говоря о security проблемах);
Style/idioms — не идиоматические конструкции, нарушение coding style;
Build practices — длительное время сборки и настройки dev-окружения.
Помню, в одной компании сборка компонента занимала пару часов. Очевидно, что такая длительная сборка — это технический долг, который стоит компании несколько десятков человеко-часов ежедневно и сильнейшую демотивацию команды.
Техдолг от operations
Ещё слоны (техдолг) у нас водятся вокруг всего того, что называется operations excellence. Я обозначу несколько популярных пунктов, но при желании их можно продолжить:
Ручные манипуляции или отсутствие проверок работоспособности при апдейте системы.
Ручные манипуляции или отсутствие проверок при свежей раскатке (как пример, ситуация с Mellanox).
Неслучившиеся алерты, когда о потенциально опасной или опасной ситуации не успевают/не умеют оповестить.
Отсутствие гранулярного деплоя: per node, per cluster/sub-cluster, per feature.
Есть практики: gradual update или gradual-feature delivery, когда можно включать фичу не для всех, а для части, и смотреть у всех ли она реализована. Не для всех фич нужна гранулярность. Не все флоу нужно автоматизировать. И вообще-то не все технические долги рационально выплачивать. Но мы пока их проясняем, а оценивать уже будем отдельно.
Техдолг из RCA инцидентов
Второй мой любимый источник упитанных слонов — это RCA (Root Cause Analysis). В RCA мы анализируем первопричины инцидента: идем не до дефекта, а глубже, в анализ процессов, которые не устранили дефект или в системы, которые не смогли быстро донести фикс дефекта. Среди возможных первопричин:
Неполный список сценариев в тестировании;
Неполный набор интеграционных тестов;
Неполный набор конфигов и «железа»;
Невозможность откатить версию в продакшен.
Почти всегда root cause инцидента — это техдолг.
Считаем долг
Мы нашли слонов и встретились с ними лицом к лицу, но весь ли технический долг нужно устранять? Однозначно нет и однозначно не сразу. Поэтому второй шаг — это оценка техдолга. Причем оценивать мы его будем с двух позиций: сколько ежемесячных процентов набегает и сколько стоит закрытие кредита.
Стоит оговориться, что технический долг не только тратит ресурсы компании, но и выматывает эмоционально. Поэтому, если ваши процессы нестабильны, если ваша команда чинит чужие баги, а коммит в ваш компонент занимает непредсказуемо много времени из-за флакающих тестов, вы просто потеряете людей. Из-за этого увеличится нагрузка на оставшихся, итак придавленных процентами. Причем в проектах с большим техническим долгом высокий процент ручного труда зачастую на всех этапах разработки, а значит уход человека — это ещё и потеря экспертизы. А это уже не просто демотивация, а риск закрытия проекта или даже потери бизнеса.
Оставим драмы в стороне и попробуем оценить долг для менее запущенных случаев. Выплаты по долгу в различных сценариях описываются по-разному, но это всегда снижение темпа (взять хотя бы TDR метрику). При разработке мы выплачиваем долг, ожидая сборки или валидации, или дотачивая код под старые «костыли». В инцидент-менеджменте затраты на расследование инцидента и стоимость выпуска лишних hotfix-ов — это выплаты по техдолгу. Стоимость ручных усилий у operations — тоже самое.
Рассмотрим расчет стоимости техдолга для продакшн инцидентов на примере (все данные абстрактной компании, но они дают представление о том, как все бывает):
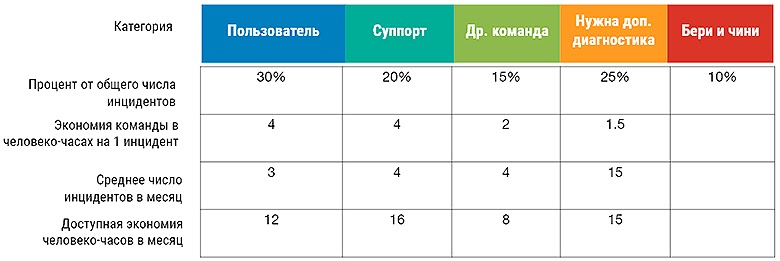
»1 столбец, пользователь» — это инциденты при которых пользователь что-то неправильно сконфигурировал, имел нестабильный интернет или другие проблемы на своей стороне.
»2 столбец, суппорт» — это инциденты, где пользователю сложно или невозможно справится, но служба поддержки могла все решить без передачи инцидента в разработку.
«Др. команда» — это инциденты вызванные поломками в других компонентах, отнявшие у команды время на расследование.
«Нужна доп. диагностика» — это инциденты, где причина неясна и требуются дополнительные действия, иногда, даже воспроизведения.
«Бери и чини» — это самые правильные инциденты, когда ваша команда действительно ошиблась, суппорт передает ей баг и кто-то из членов команды рождает фикс.
По данным таблицы видно, что 30% инцидентов пользовательские. Команда и суппорт потратили на них время, а было нужно сделать более информативное сообщение. И, если учитывать, что таких инцидентов, допустим, 3 штуки в месяц и тратится на них в среднем около 4 часов, то более информативные сообщения могут сэкономить команде 12 часов в месяц.
Обеспечиваем долг
Следующая таблица демонстрирует способы автоматизации техдолга при различных сценариях расследования инцидентов с учетом их окупаемости (md = man-day, m=month, y=year):
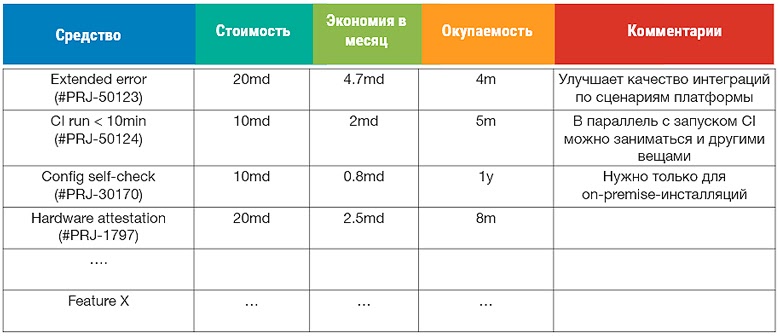
Например, мы проанализировали инциденты за месяц и увидели, что отсутствие тестирования конфигурации дало нам 5 проблем за месяц, а отсутствие расширенной диагностической информации затруднило расследование практически всех инцидентов.
Рассмотрим расчет окупаемости на примере расширенной диагностической информации. Есть gateway-компонент, связующий два деплоя. В случае ошибки он выдает ее код, без лишних строк и подробностей. Поэтому TIMEOUT будет и для случая нехватки связи между двумя деплоями, и при любом нарушении связи компонентами внутри деплоя, и при падении компонентов внутри деплоя.
Первое, что нужно предпринять при расследовании инцидента в gateway-е — это получить логи с деплоя, потому что ошибка не информативна практически никогда. А теперь предположим, что система развернута у пользователя и доступ к логам нужно предварительно запрашивать. Тогда отсутствие расширенного описания ошибки добавляет траты при каждом расследовании. Например, при стоимости разработки в 20 человеко-дней, она будет экономить по 35 часов ежемесячно и окупится за 4 месяца.
Резюме — такой фиче назначим приоритет 1 из пула фич для закрытия техдолга (1 строка в таблице):

Выбрав 5–6 самых значимых фич, можно построить план. В этом спринте (или какие у вас циклы разработки) мы закроем эти фичи и получим ожидаемое снижение стоимости сопровождения на Y, где наша команда «получит» Y1 дополнительных часов, а у суппорта высвободится Y2 часов. Так постепенно у нас будет снижаться стоимость сопровождения.
Подчеркну наш прогресс, ведь мы уже не просто говорим, что у нас техдолг и его нужно закрывать. Мы рассказываем конкретный план и знаем, сколько денег нужно вложить для того, чтобы получить конкретное улучшение сопровождаемости проекта.
Стратегии выплаты техдолга
План составили, допустим, даже получили подтверждение от CEO/CTO, но руководство готово вкладываться в техдолг теоретически, а практически есть сроки поставки ПО и согласованные ранее планы. Поэтому возникают разные стратегии стратегии выплат техдолга:
Квота на техдолг, например, 20%, но реально это редко работает и зависит от честности договоренностей.
Выделенные люди, которые занимаются только техдолгом, но это сложно психологически.
Выделенный спринт, когда мы только закрываем техдолг и не разрабатываем никаких фич от бизнеса.
Подполье — мой любимый вариант.
В подпольной деятельности могут быть интересные артефакты. Например, был многопоточный бэкенд на Python-е. Команда хотела переписать все на Golang или Rust. Но кто согласится дать время на то, чтобы всё переписывать с нуля? Поэтому приняли решение все новые фичи делать только в новом компоненте. А если для фичи требуется логика старого компонента, то в стоимость разработки включать перенесение логики из старого компонента в новый.
Но прежде чем идти с планом и стратегиями к CEO/CTO, я предлагаю критически рассмотреть проект на предмет частых ошибок.
Частые ошибки
Под частыми ошибками я подразумеваю те, с которыми сталкивалась и которые делала сама (у вас они могут быть другие и мне тоже интересно будет узнать о них в комментариях):
«Кодоводчество» — это упирать на чисто разработческие проблемы. Например, рассказывать, что мы переименуем константы. У нас сейчас с подчеркиванием, а мы сделаем без подчеркивания! Или унифицируем комментарии. Но после этого CTO или CEO (в зависимости от того, кто у вас принимает решения), потеряет интерес к разговору.
Сверх-планирование — это пытаться всё детально проработать и в итоге застрять на стадии планирования, растрачивая слишком много ресурсов.
Стремительность — пытаться сразу сделать все самые важные пункты, не продемонстрировав положительный результат руководству. Последнее — это про меня. Я часто пыталась включить в работу топ-3 пункта, а лучше топ-10, вместо того чтобы сделать одну фичу, показать позитивный результат и сначала выполнить важные пункты.
Но помимо ошибок, возникающих во время приоритизации работы с техдолгом, встречаются и человеческие проблемы. Разработчики выгорают от стресса при звонках в 3 часа ночи и непрерывно полыхающих продакшенах. Но далеко не все из них любят закрывать технический долг. Есть люди, которые называют это «вылизыванием». В этот момент они готовы уволиться, лишь бы этим не заниматься.
Часто негативное отношение к техдолгу идет от неправильного восприятия процесса разработки. Наш дофаминовый мозг считает, что фича готова, когда тест прошел. Ну самое позднее после завершения команды «git push». И мало кто готов терпеливо ждать и радоваться, когда фича разлилась по всем ДЦ и нашла позитивный отклик у operations и пользователей.
Поэтому продавать технический долг нужно не только вверх, но еще и вниз. Фокусироваться не на закрытых багах в трекере, а на разлитых по продакшну фичах. Объяснять сотрудникам, насколько им станет лучше и как они повысят свою стоимость на рынке за счет знакомства с лучшими практиками. Подсовывать им книги про Google. Звать на подходящие конференции и тренинги. Или давать им это как налог: «Вот здесь ты делаешь фичу, а здесь дополнительное упражнение на благо компании». Можно приводить их к пользователям. Вариантов много.
Заключение
В заключении хочется дать несколько советов от лучших слонозаводчиков. Есть разные источники долга, и они не только в коде. И не столь важно, сколько этого долга, важнее какого он качества и сколько затрат по нему ежемесячно набегает. Но даже если вы проведете расследование, извлечете и обеспечите долг, сможете всё это презентовать и объяснить, не факт, что вам пойдут навстречу. Есть вероятность, что вы не всегда сможете найти поддержку. И тогда нужно быть очень честным с собой и принять решение: стать последним героем, либо уйти. Честно говоря, я выбрала уйти… Но я желаю вам сил, чтобы встретить ваш техдолг с чистой совестью.
А еще у меня есть Телеграм-канал, где я пытаюсь писать про архитектуру. Буду рада вас видеть!
Видео моего выступления на TechLead Conf 2021:
В 2022 году конференция TechLead пройдет на одной площадке с конференцией DevOps Conf 2022 — 9 и 10 июня в Москве, в Крокус-Экспо. Подать заявку на выступление для техлидов вы можете здесь, а для devops-коммьюнити — здесь.
